话说大模型出来后,大部分工作都是围绕调用展开,像微调等工作不是我等爱好者可以用的,那么时至今日,aisutdio上有有免费使用A800 80GB的机会,你会用吗?话不多说,现在开始。
1.ERNIEKit v2.0介绍
- ErnieKit 是专为Ernie模型设计的,可以对模型进行微调,也提供各类快捷部署。
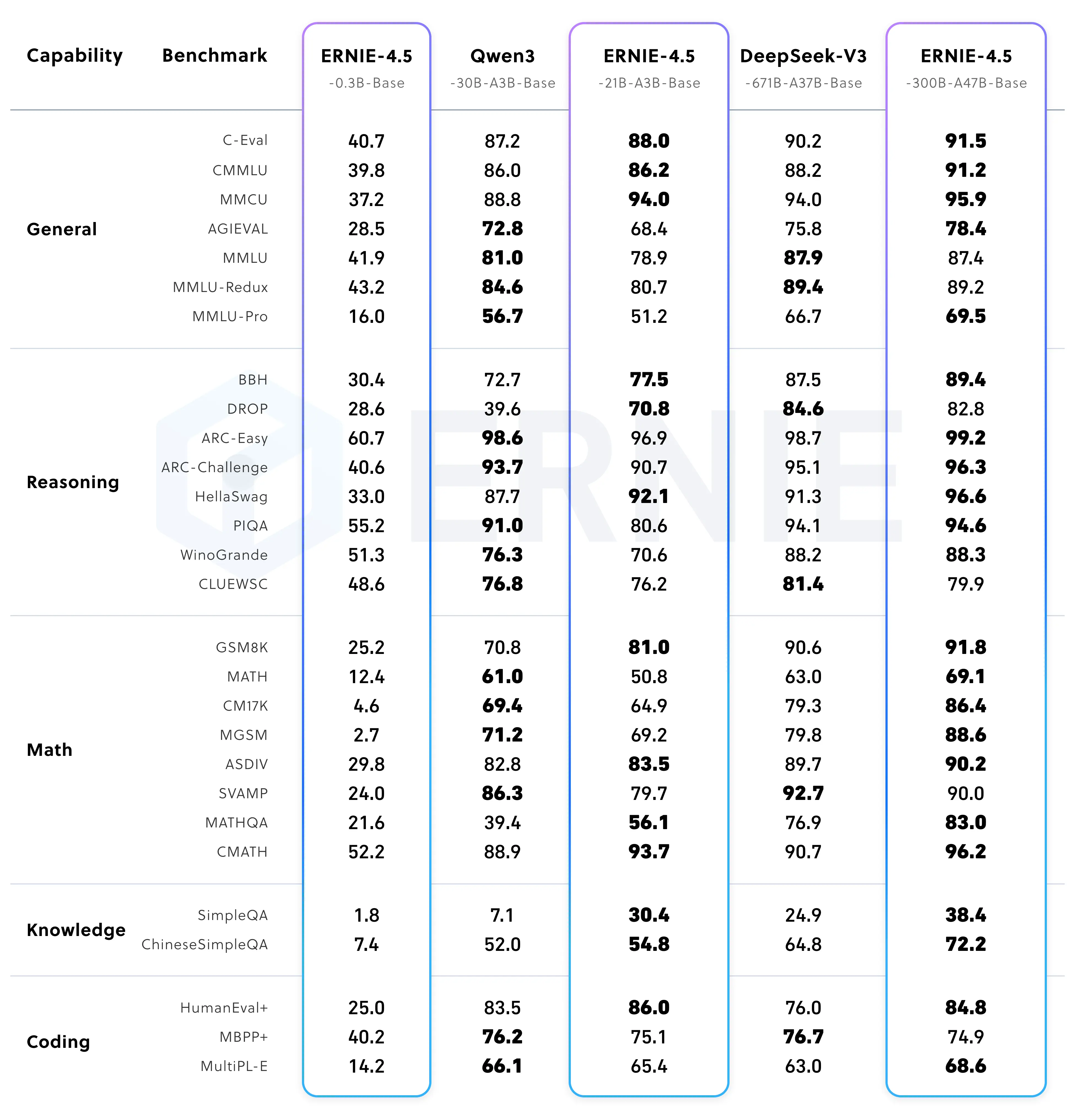
- Ernie性能
- 下载地址 https://github.com/PaddlePaddle/ERNIE - 安装
bash
# !git clone https://gitclone.com/github.com/PaddlePaddle/ERNIE
%cd ERNIE
!python -m pip install -r requirements/gpu/requirements.txt
!python -m pip install -e . # 推荐使用可编辑模式安装2.aistudio介绍
aistudio是paddlepaddle框架的开源社区,可以进行各类学习。
-
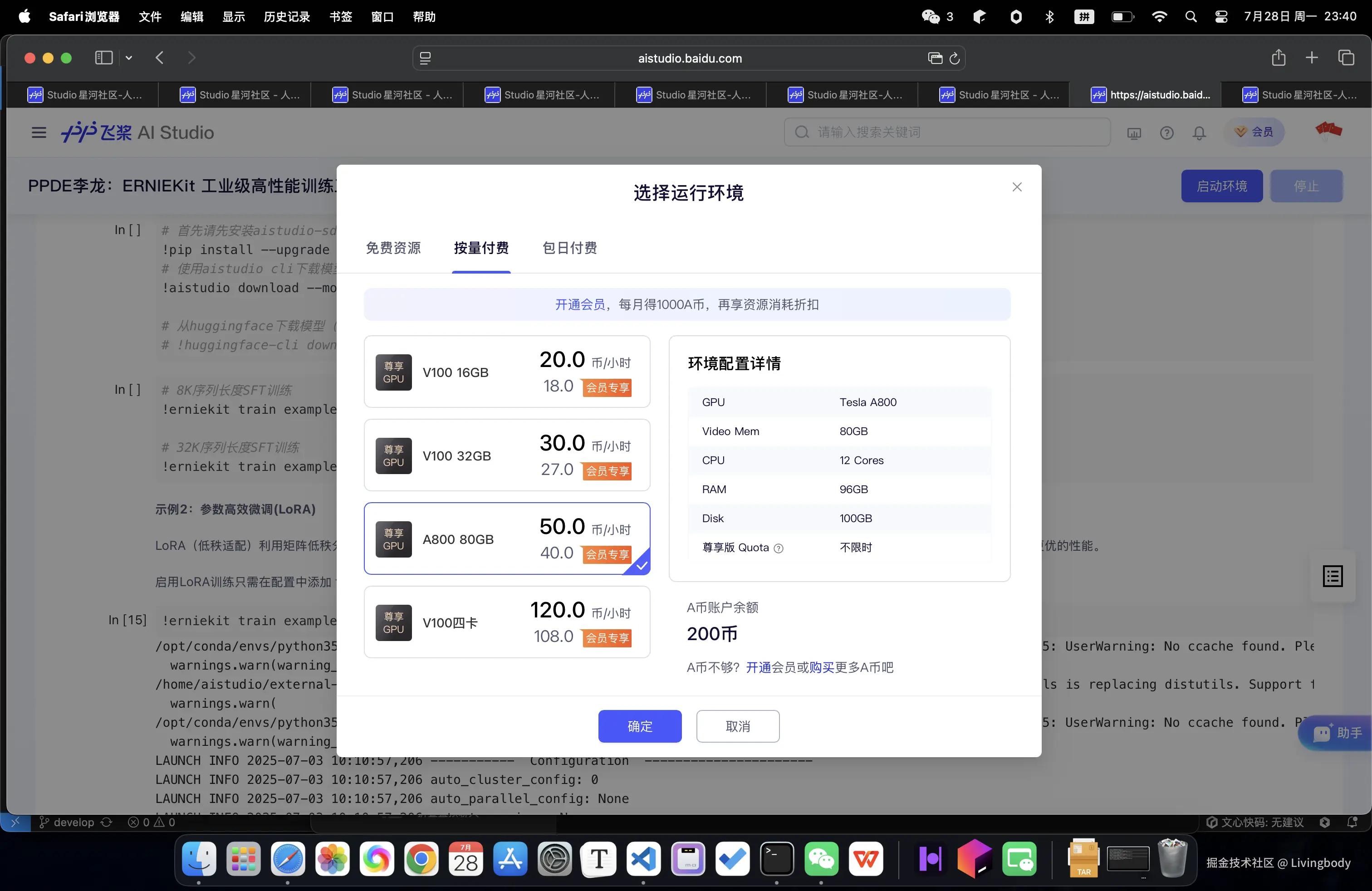
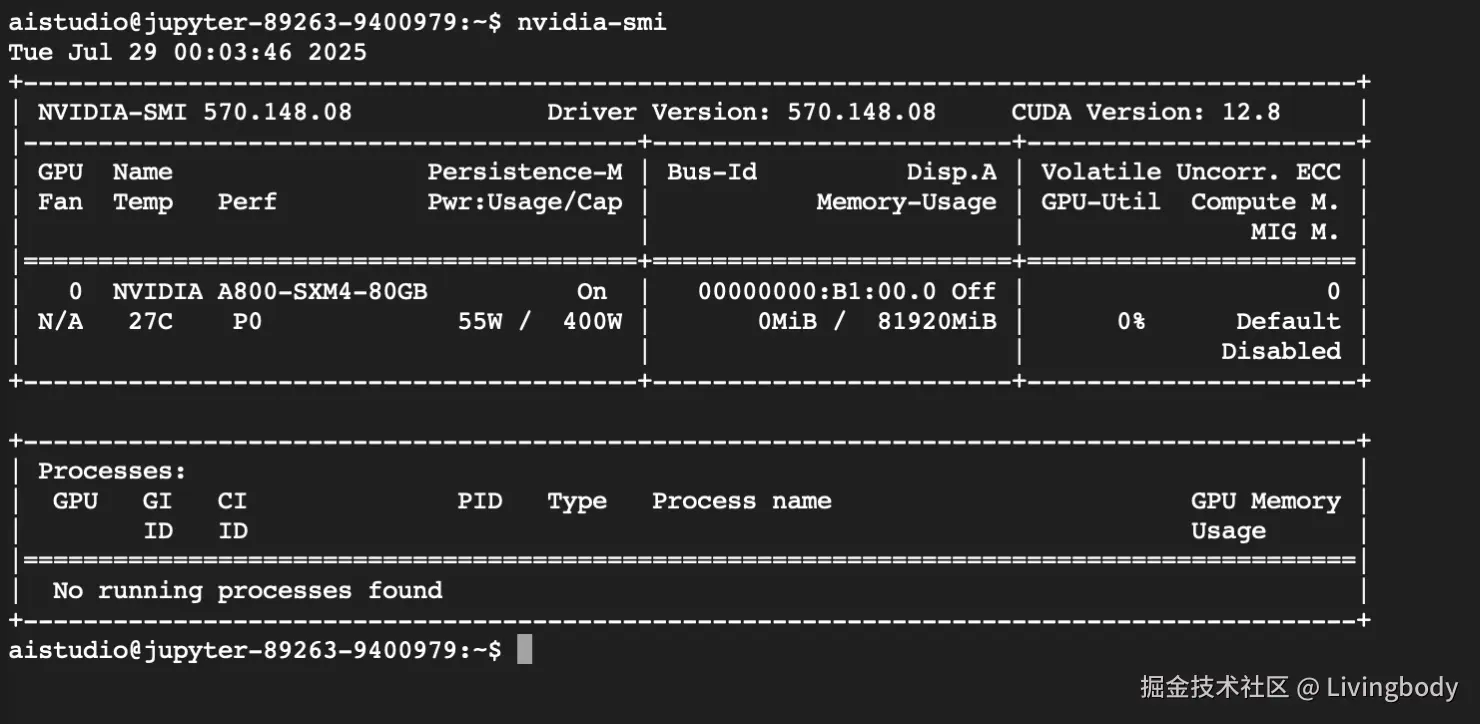
近期有活动,免费送算力,可以支持大模型微调,如下图所示,直接选择A800显卡,80GB显存到手,即可使用。
-
选择80GB显存环境,如下图。
3.下载模型
下载有下面2个路径:
- aistudio-sdk下载
- huggingface下载
bash
# 首先请先安装aistudio-sdk库
!pip install --upgrade aistudio-sdk
# 使用aistudio cli下载模型(推荐)
!aistudio download --model PaddlePaddle/ERNIE-4.5-0.3B-Paddle --local_dir baidu/ERNIE-4.5-0.3B-Paddle
# 从huggingface下载模型(需换源)
# !huggingface-cli download baidu/ERNIE-4.5-0.3B-Paddle --local-dir baidu/ERNIE-4.5-0.3B-Paddle4.模型介绍及训练脚本
ERNIEKit支持以下模型的训练。开始训练前请确保:环境配置完成和硬件资源满足最低要求
| Model | Post-Training Method | Seq Length | Min Resources | Recommended Config |
|---|---|---|---|---|
| ERNIE-4.5-300B-A47B-Base/ERNIE-4.5-300B-A47B | SFT | 8K | 96x80G A/H GPUs | run_sft_8k.sh |
| ERNIE-4.5-300B-A47B-Base/ERNIE-4.5-300B-A47B | SFT | 32K | 112x80G A/H GPUs | run_sft_32k.sh |
| ERNIE-4.5-300B-A47B-Base/ERNIE-4.5-300B-A47B | SFT(FP8) | 8K | 16x80G H GPUs + 2TB CPU RAM | run_sft_fp8_8k.sh |
| ERNIE-4.5-300B-A47B-Base/ERNIE-4.5-300B-A47B | SFT(FP8) | 32K | 16x80G H GPUs + 2TB CPU RAM | run_sft_fp8_32k.sh |
| ERNIE-4.5-300B-A47B-Base/ERNIE-4.5-300B-A47B | SFT-LoRA(wint4/8) | 8K | 4x80G A/H GPUs | run_sft_wint8mix_lora_8k.sh |
| ERNIE-4.5-300B-A47B-Base/ERNIE-4.5-300B-A47B | SFT-LoRA(wint4/8) | 32K | 8x80G A/H GPUs | run_sft_wint8mix_lora_32k.sh |
| ERNIE-4.5-300B-A47B-Base/ERNIE-4.5-300B-A47B | DPO | 8K | 112x80G A/H GPUs | run_dpo_8k.sh |
| ERNIE-4.5-300B-A47B-Base/ERNIE-4.5-300B-A47B | DPO | 32K | 112x80G A/H GPUs | run_dpo_32k.sh |
| ERNIE-4.5-300B-A47B-Base/ERNIE-4.5-300B-A47B | DPO-LoRA | 8K | 16x80G A/H GPUs | run_dpo_lora_8k.sh |
| ERNIE-4.5-300B-A47B-Base/ERNIE-4.5-300B-A47B | DPO-LoRA | 32K | 16x80G A/H GPUs | run_dpo_lora_32k.sh |
| ERNIE-4.5-21B-A3B-Base/ERNIE-4.5-21B-A3B | SFT | 8K | 8x80G A/H GPUs | run_sft_8k.sh |
| ERNIE-4.5-21B-A3B-Base/ERNIE-4.5-21B-A3B | SFT | 32K | 8x80G A/H GPUs | run_sft_32k.sh |
| ERNIE-4.5-21B-A3B-B base/ERNIE-4.5-21B-A3B | SFT | 128K | 8x80G A/H GPUs | run_sft_128k.sh |
| ERNIE-4.5-21B-A3B-Base/ERNIE-4.5-21B-A3B | SFT-LoRA(wint4/8) | 8K | 2x80G A/H GPUs | run_sft_wint8mix_lora_8k.sh |
| ERNIE-4.5-21B-A3B-Base/ERNIE-4.5-21B-A3B | SFT-LoRA(wint4/8) | 32K | 2x80G A/H GPUs | run_sft_wint8mix_lora_32k.sh |
| ERNIE-4.5-21B-A3B-Base/ERNIE-4.5-21B-A3B | DPO | 8K | 8x80G A/H GPUs | run_dpo_8k.sh |
| ERNIE-4.5-21B-A3B-Base/ERNIE-4.5-21B-A3B | DPO | 32K | 8x80G A/H GPUs | run_dpo_32k.sh |
| ERNIE-4.5-21B-A3B-Base/ERNIE-4.5-21B-A3B | DPO | 128K | 8x80G A/H GPUs | run_dpo_128k.sh |
| ERNIE-4.5-21B-A3B-Base/ERNIE-4.5-21B-A3B | DPO-LoRA | 8K | 2x80G A/H GPUs | run_dpo_lora_8k.sh |
| ERNIE-4.5-21B-A3B-Base/ERNIE-4.5-21B-A3B | DPO-LoRA | 32K | 2x80G A/H GPUs | run_dpo_lora_32k.sh |
| ERNIE-4.5-0.3B-Base/ERNIE-4.5-0.3B | SFT | 8K | 1x80G A/H GPU | run_sft_8k.sh |
| ERNIE-4.5-0.3B-Base/ERNIE-4.5-0.3B | SFT | 32K | 1x80G A/H GPU | run_sft_32k.sh |
| ERNIE-4.5-0.3B-Base/ERNIE-4.5-0.3B | SFT | 128K | 1x80G A/H GPU | run_sft_128k.sh |
| ERNIE-4.5-0.3B-Base/ERNIE-4.5-0.3B | SFT-LoRA(wint4/8) | 8K | 1x80G A/H GPU | run_sft_wint8mix_lora_8k.sh |
| ERNIE-4.5-0.3B-Base/ERNIE-4.5-0.3B | SFT-LoRA(wint4/8) | 32K | 1x80G A/H GPU | run_sft_wint8mix_lora_32k.sh |
| ERNIE-4.5-0.3B-Base/ERNIE-4.5-0.3B | DPO | 8K | 1x80G A/H GPU | run_dpo_8k.sh |
| ERNIE-4.5-0.3B-Base/ERNIE-4.5-0.3B | DPO | 32K | 1x80G A/H GPU | run_dpo_32k.sh |
| ERNIE-4.5-0.3B-Base/ERNIE-4.5-0.3B | DPO | 128K | 1x80G A/H GPU | run_dpo_128k.sh |
| ERNIE-4.5-0.3B-Base/ERNIE-4.5-0.3B | DPO-LoRA | 8K | 1x80G A/H GPU | run_dpo_lora_8k.sh |
| ERNIE-4.5-0.3B-Base/ERNIE-4.5-0.3B | DPO-LoRA | 32K | 1x80G A/H GPU | run_dpo_lora_32k.sh |
4.数据准备

ERNIEKit支持 alpaca 和 erniekit 两种数据集格式。详细格式规范请参考:数据集指南。提供了 erniekit 格式的示例数据集(sft-train.jsonl)用于快速上手。
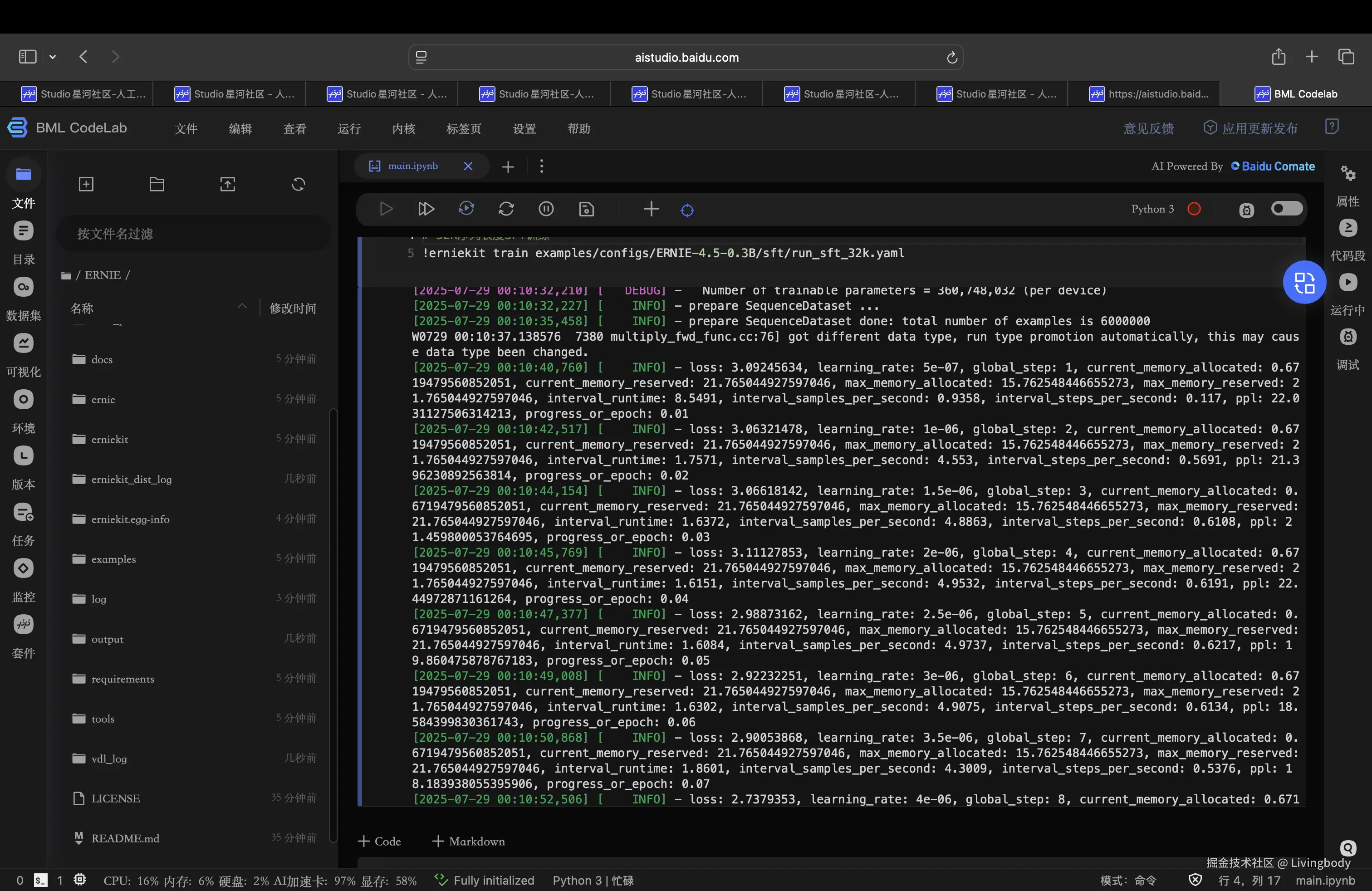
5.监督史微调SFT
监督式微调通过标注数据集优化预训练语言模型,提升任务特定性能和指令遵循能力。这种参数更新方法具有以下特点:
- 需要高质量标注数据
- 调整所有模型参数
- 适用于精度要求较高的专业化任务
6.直接偏好优化(DPO)
对齐训练是确保大语言模型行为与人类意图、价值观或特定目标一致的关键技术。其核心目标是解决预训练模型"强大但难以控制"的问题,使模型输出更安全、可靠,更符合人类期望。
直接偏好优化(DPO)是实现人类偏好对齐的代表性方法,直接在标注偏好数据上微调模型参数。相比RLHF,DPO训练稳定性更高、计算开销更低,已成为主流的偏好对齐方法。 示例1:全参数直接偏好优化
bash
# 首先请先安装aistudio-sdk库
# !pip install --upgrade aistudio-sdk
# 使用aistudio cli下载模型(推荐)
# !aistudio download --model PaddlePaddle/ERNIE-4.5-0.3B-Paddle --local_dir baidu/ERNIE-4.5-0.3B-Paddle
# 从huggingface下载模型(需换源)
# !huggingface-cli download baidu/ERNIE-4.5-0.3B-Paddle --local-dir baidu/ERNIE-4.5-0.3B-Paddle
# 8K序列长度DPO训练
# !erniekit train examples/configs/ERNIE-4.5-0.3B/dpo/run_dpo_8k.yaml
# 32K序列长度DPO训练
# !erniekit train examples/configs/ERNIE-4.5-0.3B/dpo/run_dpo_32k.yaml7.权重合并
LoRA微调完成后,需要将LoRA权重与主模型权重合并。多机训练场景下需要注意:⚠️每台机器存储部分模型参数(检查点)⚠️必须同步所有机器的参数文件 后再进行LoRA权重合并或部署
训练完成后合并LoRA参数到基座模型:
bash
# 权重合并
%cd ~/ERNIE
!erniekit export examples/configs/ERNIE-4.5-0.3B/run_export.yaml lora=True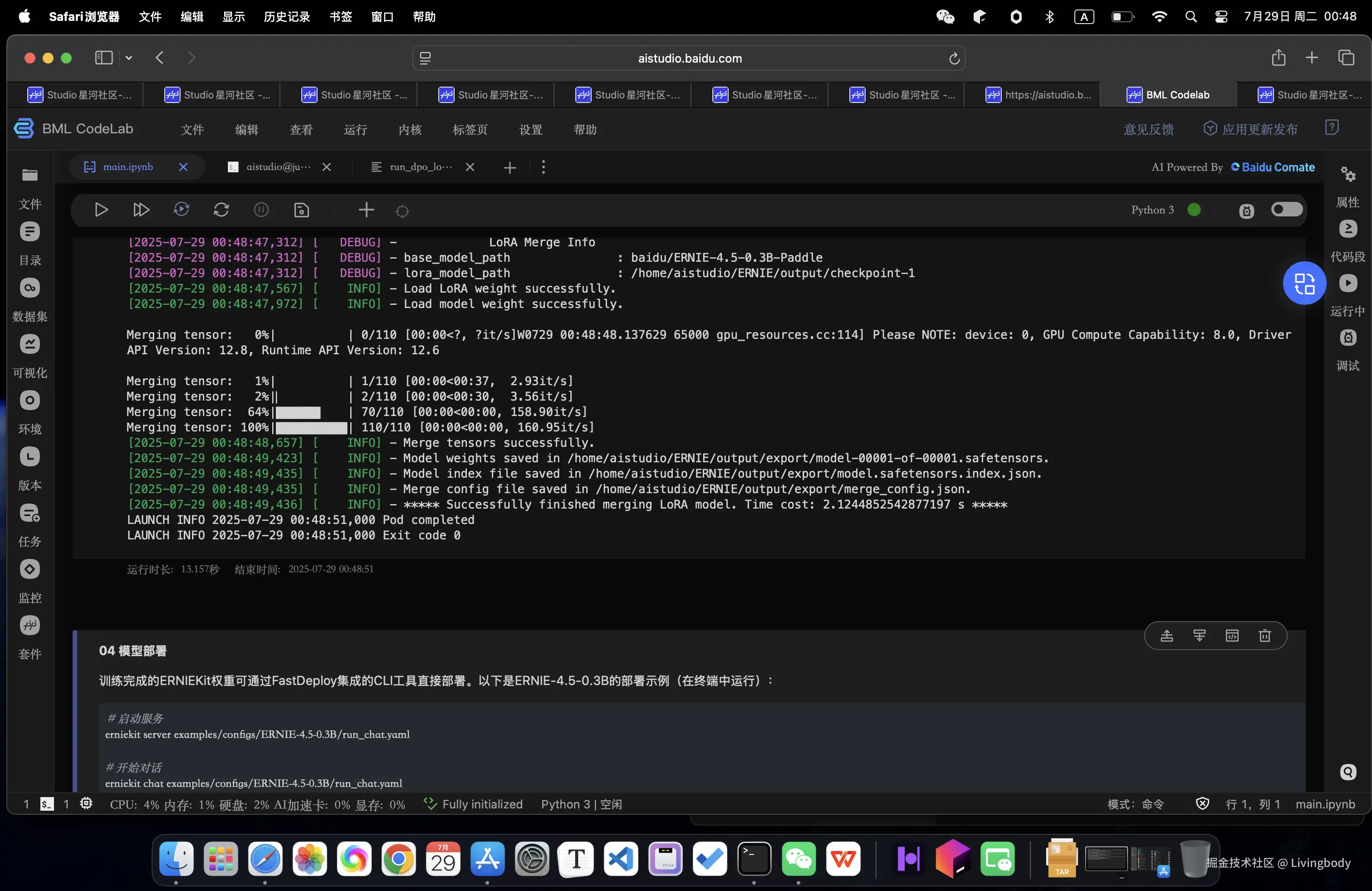
8.模型部署
训练完成的ERNIEKit权重可通过FastDeploy集成的CLI工具直接部署。以下是ERNIE-4.5-0.3B的部署示例(在终端中运行):
- erniekit启动部署
bash
# 启动服务
erniekit server examples/configs/ERNIE-4.5-0.3B/run_chat.yaml
# 开始对话
erniekit chat examples/configs/ERNIE-4.5-0.3B/run_chat.yaml- fastdeploy启动部署
python
# 1: FastDeploy完整启动代码
import subprocess
import time
import requests
import threading
def start_fastdeploy():
cmd = [
"python", "-m", "fastdeploy.entrypoints.openai.api_server",
"--model", "output/export",
"--port", "8180",
"--metrics-port", "8181",
"--engine-worker-queue-port", "8182",
"--max-model-len", "32768",
"--max-num-seqs", "32"
]
print("🚀 启动FastDeploy服务...")
print("-" * 50)
process = subprocess.Popen(
cmd,
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT,
universal_newlines=True,
bufsize=1
)
print(f"📝 PID: {process.pid}")
service_ready = False
def monitor_logs():
nonlocal service_ready
try:
while True:
output = process.stdout.readline()
if output == '' and process.poll() is not None:
break
if output:
line = output.strip()
print(f"[日志] {line}")
if "Loading Weights:" in line and "100%" in line:
print("✅ 权重加载完成")
elif "Loading Layers:" in line and "100%" in line:
print("✅ 层加载完成")
elif "Worker processes are launched" in line:
print("✅ 工作进程启动")
elif "Uvicorn running on" in line:
print("🎉 服务启动完成!")
service_ready = True
break
except Exception as e:
print(f"日志监控错误: {e}")
log_thread = threading.Thread(target=monitor_logs, daemon=True)
log_thread.start()
start_time = time.time()
while time.time() - start_time < 120:
if service_ready:
break
if process.poll() is not None:
print("❌ 进程退出")
return None
time.sleep(1)
if not service_ready:
print("❌ 启动超时")
process.terminate()
return None
print("-" * 50)
return process
def test_model():
try:
import openai
print("🔌 测试模型连接...")
client = openai.Client(base_url="http://localhost:8180/v1", api_key="null")
response = client.chat.completions.create(
model="null",
messages=[
{"role": "system", "content": "你是一个有用的AI助手。"},
{"role": "user", "content": "你好"}
],
max_tokens=50,
stream=False
)
print("✅ 模型测试成功!")
print(f"🤖 回复: {response.choices[0].message.content}")
return True
except Exception as e:
print(f"❌ 测试失败: {e}")
return False
def check_service():
try:
response = requests.get("http://localhost:8180/v1/models", timeout=3)
return response.status_code == 200
except:
return False
def setup_service():
print("=== ERNIE-4.5-0.3B-Paddle 服务启动 ===")
if check_service():
print("✅ 发现运行中的服务")
if test_model():
print("🎉 服务已就绪!")
return True
print("⚠️ 服务异常,重新启动")
process = start_fastdeploy()
if process is None:
print("❌ 启动失败")
return False
if test_model():
print("🎊 启动成功!现在可以运行知识图谱代码")
return True
else:
print("❌ 启动但连接失败")
return False
if __name__ == "__main__" or True:
setup_service()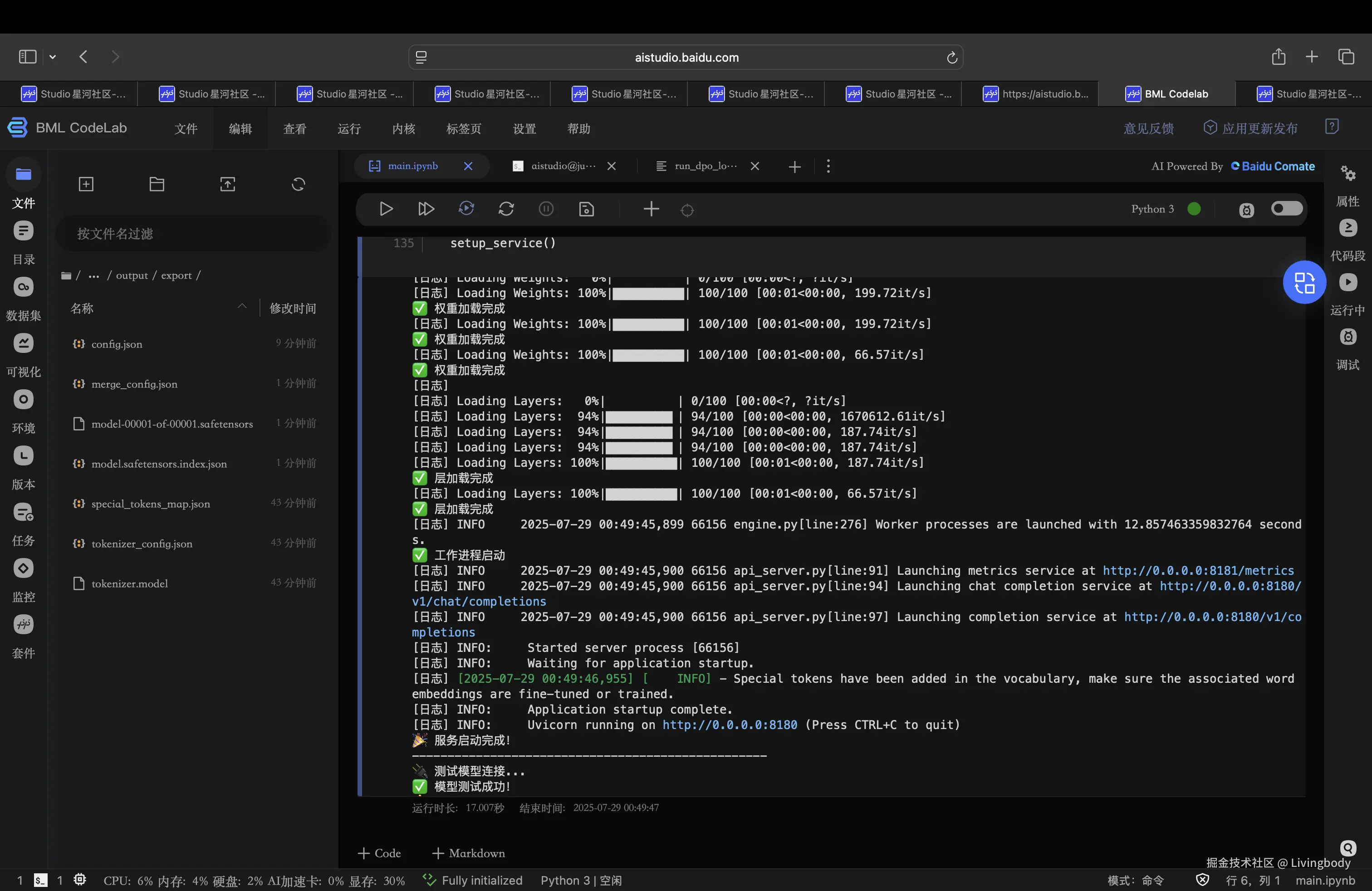
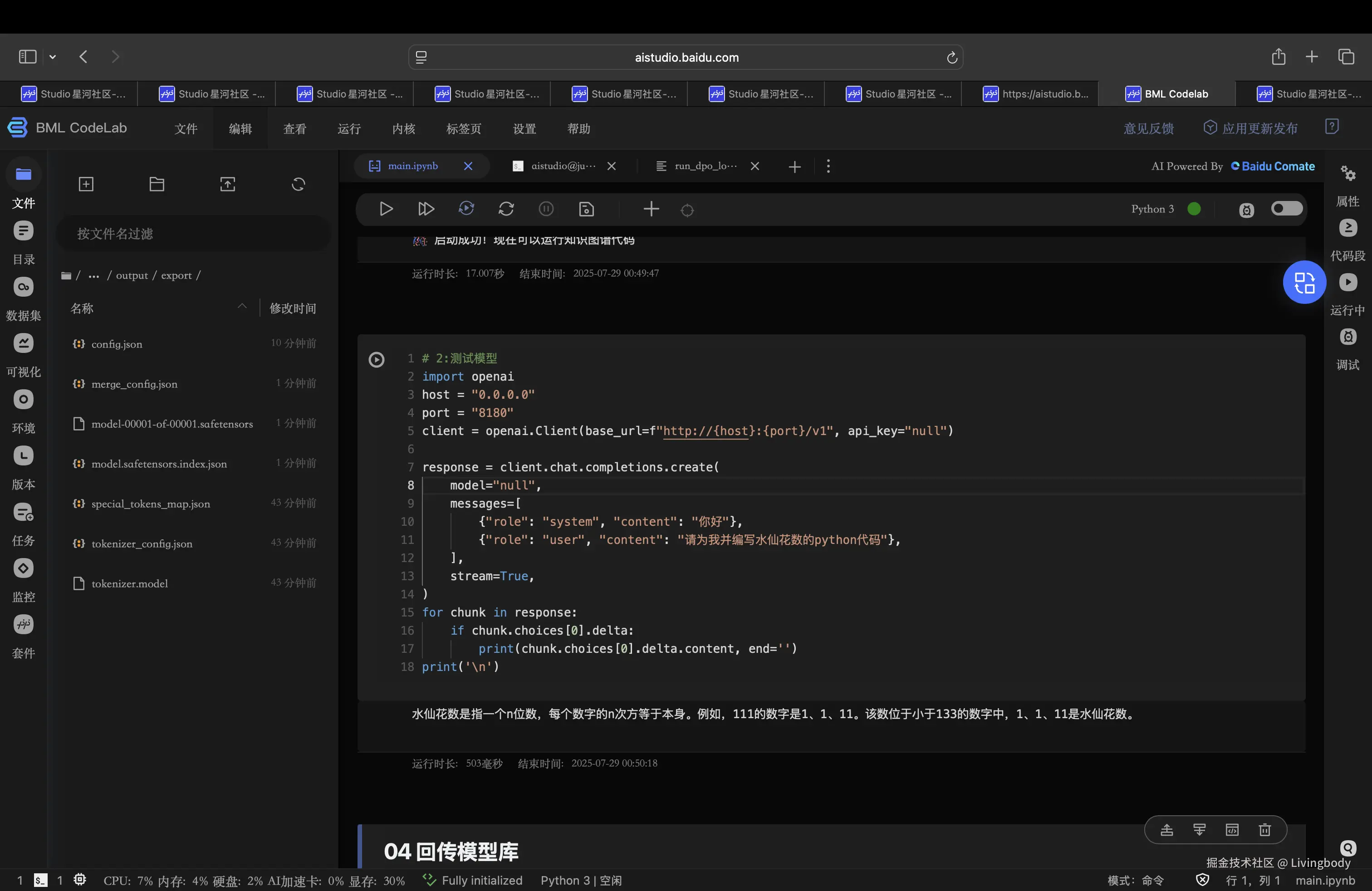
9.测试
python
# 2:测试模型
import openai
host = "0.0.0.0"
port = "8180"
client = openai.Client(base_url=f"http://{host}:{port}/v1", api_key="null")
response = client.chat.completions.create(
model="null",
messages=[
{"role": "system", "content": "你好"},
{"role": "user", "content": "请为我并编写水仙花数的python代码"},
],
stream=True,
)
for chunk in response:
if chunk.choices[0].delta:
print(chunk.choices[0].delta.content, end='')
print('\n')