一、引言:为什么要做知识库
在构建博客、知识系统或 AI 搜索助手时,一个核心需求是------让 AI 能理解你的业务知识,并能准确检索。
很多同学第一反应是直接让 AI 读数据库、查 ES,但这样做有明显弊端:
- ES/Mysql 查询的是结构化内容,无法表达语义相似度(匹配不上用户模糊问题)
- agent 直连数据库,成本高、速度慢、维护复杂
如果是服务端项目,用 Java 最自然不过:统一技术栈、维护省心、性能稳定。
而 Pinecone 则是当前最轻量、最稳定、费用可控的向量数据库,尤其它自带的 embedding 服务,省去了 OpenAI 的 Token 花费,适合个人开发者或中小项目。于是便有了这篇踩坑总结,希望你能少走弯路。
二、环境与前置条件
1. Pinecone 账号 & API Key
注册完成后,你会获得一个 API Key。请务必注意以下几点:
- 不要将 API Key 以明文形式写入仓库
- 生产环境请使用 Vault 或环境变量进行管理
在 Pinecone 免费计划中,你可以获得以下资源:
- 2 GB 存储空间(对博客内容完全够用)
- 每月 100 万读取单元、200 万写入单元
- 最多 5 个 serverless index
- 每个 index 最多 100 个 namespace
- 无限成员权限
2. 创建 Index
这里有一个关键点:如果创建 Index 时 embedding 选择了 OpenAI 或 Custom,你将无法使用 Pinecone 的免费 embedding 服务。
正确做法是:在创建 Index 时选择内置embedding 模式。
Pinecone 当前提供三种 embedding 模型:
- llama-text-embed-v2(推荐,支持的 token为2048)
- multilingual-e5-large(支持507token)
- pinecone-sparse-english-v0(512 tokens,而且只支持英文文本)
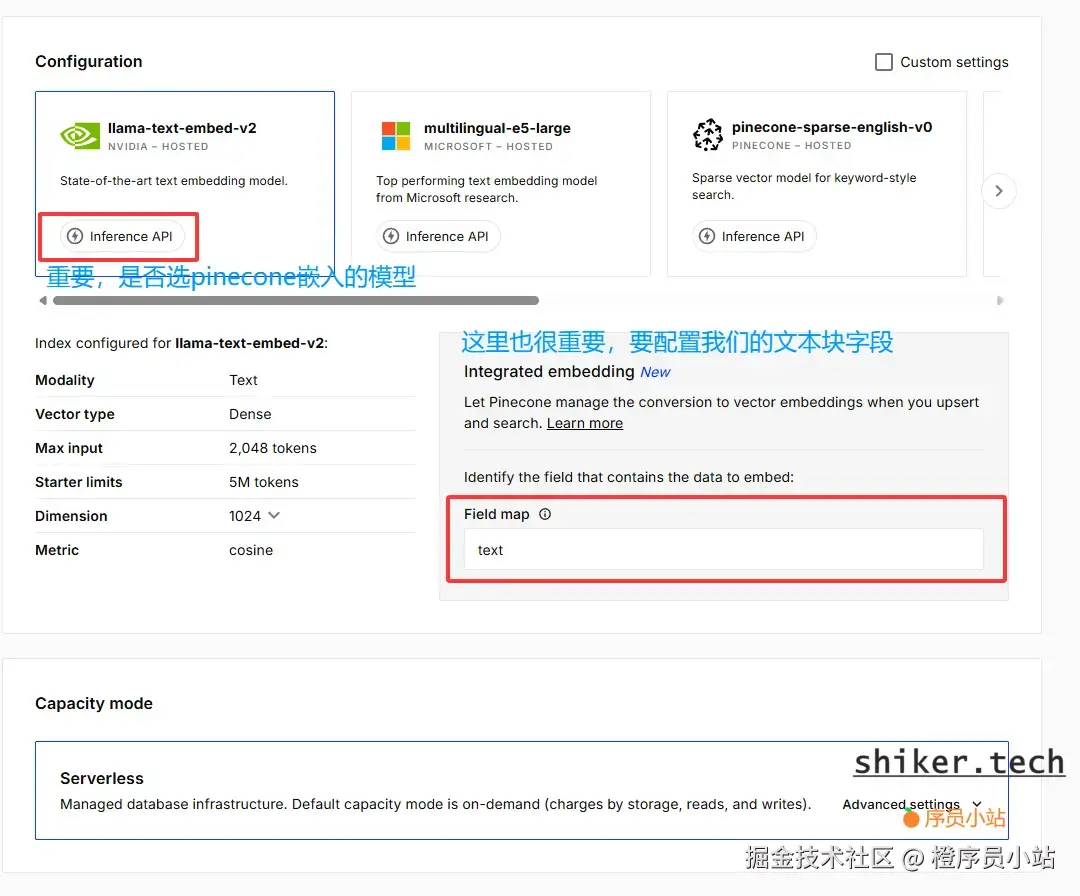
我选择 llama-text-embed-v2,因为它能够处理更长的文本,特别适合博客类内容的向量化。
三、Java 项目依赖(Maven/Gradle)
Pinecone 虽然提供了官方 Java SDK,但实际踩下来,非常不推荐在生产环境中使用,尤其是对中小型项目或老版本 Spring Boot 项目来说坑点不少。
为什么这么说?主要问题有以下几个:
1. Spring Boot Starter 最低要求 3.x
官方 Pinecone SDK 的依赖链基于 Spring WebFlux,并且内部依赖的 HttpClient、reactor 体系都是 Spring Boot 3.x 才能兼容的。
如果你使用的是:
- Spring Boot 2.7.X
- Spring Boot 2.6.X 或更老
那么结果通常是:
- 启动直接报错,即编译无法通过
- json 或 HttpClient 版本冲突,官方依赖版本可以在github.com/pinecone-io... 中看到
- 还可能出现运行时 NoSuchMethodError异常
如果添加官方SDK出现以下错误:
shorg.springframework.web.util.NestedServletException: Handler dispatch failed; nested exception is java.lang.NoSuchMethodError at org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:1087) ~[spring-webmvc-5.3.31.jar:5.3.31] at org.springframework.web.servlet.DispatcherServlet.doService(DispatcherServlet.java:965) ~[spring-webmvc-5.3.31.jar:5.3.31] at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:1006) ~[spring-webmvc-5.3.31.jar:5.3.31] at org.springframework.web.servlet.FrameworkServlet.doPost(FrameworkServlet.java:909) ~[spring-webmvc-5.3.31.jar:5.3.31] at javax.servlet.http.HttpServlet.service(HttpServlet.java:517) ~[jakarta.servlet-api-4.0.4.jar:4.0.4] at org.springframework.web.servlet.FrameworkServlet.service(FrameworkServlet.java:883) ~[spring-webmvc-5.3.31.jar:5.3.31]那版本就是不一致导致
结论:Spring Boot 2.x 基本无法无痛集成官方 SDK。
2. SDK 内部 HttpClient 与 Spring 2.x 存在冲突
Pinecone SDK 默认使用 Java HttpClient + Reactor 进行请求封装。 但是 Spring Boot 2.x 使用的 Tomcat/Netty 版本较老,导致冲突问题一堆,比如:
java.lang.NoSuchMethodError: HttpClient.create()reactor.netty.http.client.HttpClientConfig版本不兼容- WebClient 底层行为异常
你如果硬接 SDK,很可能会陷入无休止的"升级一堆库 → 另一个库又冲突"的死循环。
3. Java 8 项目很难使用 SDK
Pinecone SDK 要求的最低 Java 版本通常在:
- Java 11
- 或甚至 Java 17
如果你的公司项目还停在 Java 8,那么两个字:
别用。
不仅启动不了,还会遇到 ClassFile major version 不兼容的问题。
4. 推荐做法:完全放弃 SDK,直接用 HTTP 接口
这是踩坑后总结出来最稳定、最通用的方案:
- 兼容所有 Spring Boot 版本(2.x、3.x 都能用)
- 兼容 Java 8 ~ Java 21
- 依赖可控,不会引入重型的 Reactor/Netty
- 易于调试和扩展
- 性能也完全够用
你只需要两个工具:
- RestTemplate(Spring Boot 2.x)
- WebClient(Spring Boot 3.x 推荐)
四、Embedding:模型选择与速率限制
在接入 Pinecone 构建知识库时,Embedding 是整个流程中最容易踩坑、却又最关键的一环。Embedding 的选择会直接影响:
- 向量维度(影响存储成本 & 查询速度)
- 召回效果(决定检索是否精准)
- 写入速率限制(RL)
- Token 限制(能不能塞下大段文章)
为了避免反复试错,这里总结我在实战中踩过的坑和最终的最佳实践。
1. Pinecone 提供的 Embedding 类型
Pinecone 目前主要提供以下类型的向量化模型:
- 文本模型(text embedding)
- 多模态模型(image + text embedding)
- 稀疏/混合模型(sparse + dense 组合,如检索网页更强)
不同模型对应不同维度,例如:
llama-text-embed-v2: 1024 维multilingual-e5-large: 1024 维(支持多语言)pinecone-sparse-english-v0: 稀疏向量,适合网页类检索
如果你只做"博客内容知识库""技术文档检索""RAG 问答",文本模型完全足够。
2. 为什么强烈推荐使用 Pinecone 内置 Embedding
很多人喜欢用 OpenAI、Gemini 或自训练 embedding,但真正踩过坑后就会发现:
(1)省钱(极其关键)
- OpenAI embedding 按 Token 计费
- Gemini embedding 按字符/API 调用计费
- Pinecone 内置 embedding 免费(在免费额度内完全够用)
如果你的知识库有:
- 200 篇博客
- 每篇几千字
用 OpenAI/DeepSeek 生成 embedding 费用可能要几块甚至几十块,而 Pinecone 内置则是:
0 元
RAG 小项目完全没必要花这笔钱。
(2)避免跨服务延迟 & 复杂度
如果你分两步做:
- 文本 → 外部 embedding 服务
- embedding → Pinecone 写入
你会遇到:
- 多一次网络请求(更慢)
- 多一层报错(更难 debug)
- 多一层安全配置(API Key、超时、Token 限制)
内置 embedding 则是:
一次请求 → 直接生成 embedding → 自动写入 Pinecone
整体链路简单到没法再简单。
(3)适配度高,不会踩维度错误
使用外部 embedding 时最容易踩坑:
- 写入时你的向量维度为 1536
- 索引创建时维度设置为 1024
- → Pinecone 直接报错:dimension mismatch
但使用 Pinecone 内置 embedding 时:
- 维度自动匹配
- 你根本不需要手动指定 dim
保证 100% 正确。
3. 速率限制(Rate Limit)注意事项
Pinecone 的免费额度虽然足够用,但速率限制(RL)依然需要特别注意:
- 每分钟 数百到数千 embedding 限制(视模型而定)
- 写入向量(upsert)也有 RL
- 批量写入过大时会出现 429 Too Many Requests
实战建议:
- 批量写入 50 ~ 100 条为最佳
- 遇到 429 自动重试(带指数退避)
- 长文本先切 chunk(200~500 字一段)
后续章节我会提供一个:
Java 版 批量写入 + RL 自动退避 的完整可运行代码
这是我验证过的最稳定方案,能确保写入稳定且不被限流。
4. 最佳结论
如果你想快速搭建 Pinecone 知识库
直接使用 Pinecone 的内置 embedding
原因很简单:
- 便宜(甚至免费)
- 效果足够好
- 维度不会踩坑
- 大大简化工程复杂度
- 更适合博客类内容检索
五、Pinecone 核心概念
Pinecone 看起来简单 ------ 存向量、查相似。但要把它用稳定、可维护,还要理解几个核心概念及它们之间的相互关系。下面把每个概念拆开讲,并列出常见坑与建议。
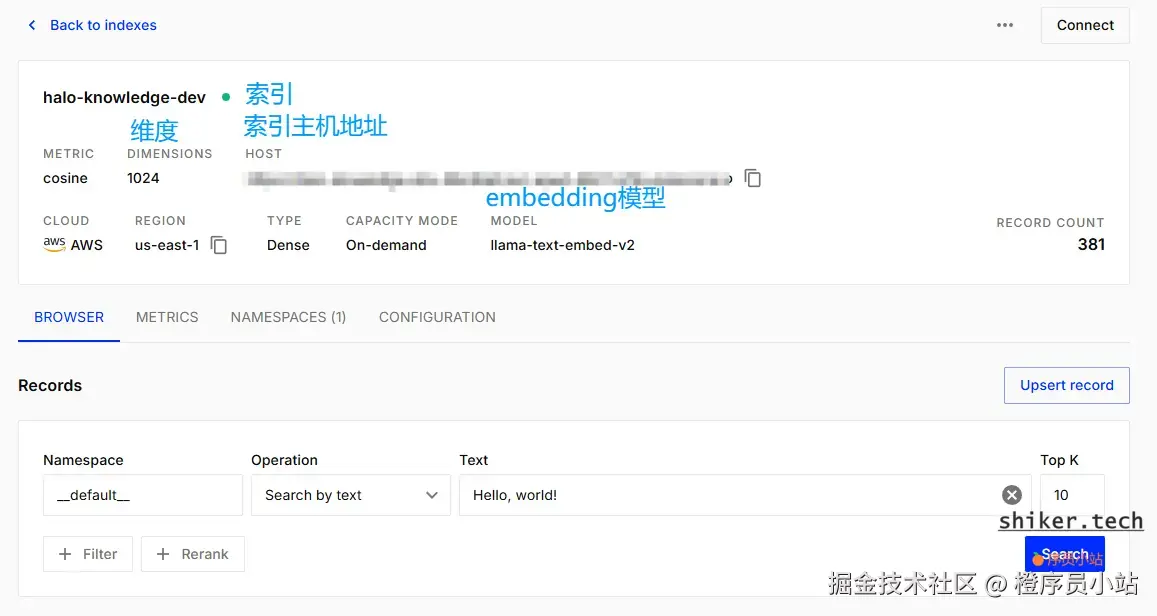
1. index(索引)
定义:Pinecone 中最顶层的存储单元,类似关系型数据库中的一张表。一个 index 存储一类向量,创建时需要指定索引类型(serverless / provisioned)、metric、dimension(如果不是内置 embedding 则需要)等属性。
建议:
- 小型项目优先使用 serverless index,免运维、按量付费、开箱即用。
- 生产级别且有明确 QPS 需求,可考虑 provisioned index(pods) 以获得稳定的吞吐。
常见坑:
- 在创建 index 时指定了错误的 metric(比如距离度量你想用余弦但选了欧氏),会影响检索结果质量。
2. dimension(向量维度)
定义:每个向量的长度(例如 1024、1536 等),必须与 embedding 服务输出的维度完全一致。
建议:
- 如果使用 Pinecone 内置 embedding ,维度通常由服务决定,不需要手动设置,创建 index 时选好内置模型对应的配置即可。
- 如果你用 外部 embedding(OpenAI/其他),创建 index 时必须手动设置与 embedding 输出相同的 dimension。
常见坑:
- 最常见的错误就是 dimension mismatch :写入向量报错,提示维度不一致。排查步骤:
- 打印 embedding 输出的向量长度(
vector.length) - 确认 index 的 dimension(控制台或 API 查看)
- 若不一致,重建 index 或调整 embedding。
- 打印 embedding 输出的向量长度(
示例错误信息:
400 Bad Request: Upsert failed: dimension mismatch (expected 1024, got 1536)
3. namespace(命名空间)
定义 :逻辑分区,用来把同一 index 下的数据按业务或类型分组(例如 articles、images、attachments)。namespace 在查询时可以作为过滤范围,从而避免跨业务污染召回。
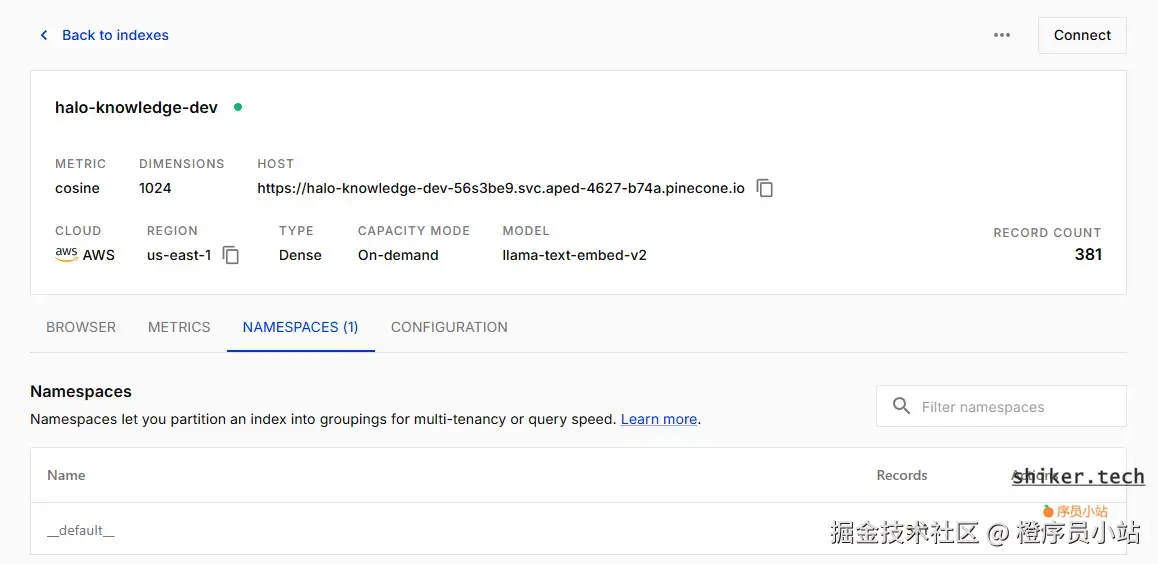
建议:
- 使用 namespace 做语义/业务隔离,便于做多租户或多用途检索。
- 不要把完全不同用途的数据(比如用户对话与静态文档)混放在同一 namespace 下。
常见坑:
- 忘记在查询时指定 namespace,导致召回结果里混入其他业务的数据。
- namespace 名称不要随意更改;如果改名,旧数据不会自动迁移。
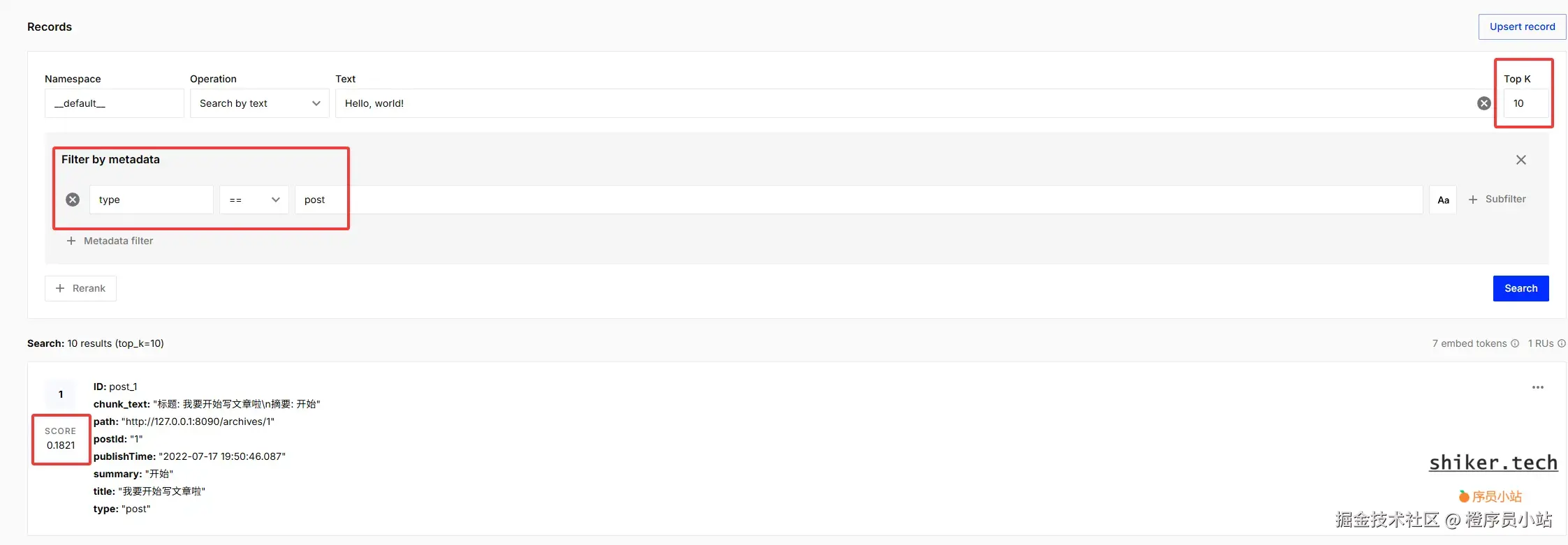
4. topK(返回数量)与过滤(filter)
topK :检索时返回的相似向量数量,通常配合 score_threshold 或后处理过滤使用。
建议:
- 初始建议
topK=5~10,用于快速验证检索质量。 - 生产查询可以先用较大的
topK(如 50),再在服务侧基于metadata做二次过滤/重排序。
Filtering(基于 metadata 的过滤):
- Pinecone 支持在查询时传入
filter条件(等同于 SQL 的 WHERE),可以按source,lang,docType等字段筛选召回结果。 - 使用 filter 可以在保证相似度召回的同时,剔除不相关的业务数据。
我们在pinecone的索引管理面板可以对我们索引中已有数据进行搜索测试:
5. metric(相似度/距离度量)
常见选项 :cosine(余弦相似度)、dotproduct、euclidean(欧氏距离)。
建议:
- 文本语义检索常用
cosine或dotproduct。 - 不要盲目切换,切换后需要重新评估召回效果并可能需要重建索引。
6. replication、sharding(副本与分片)
作用:提升可用性与吞吐。对于 serverless 模式,Pinecone 隐式管理;对于 provisioned 模式,你可以配置 pods/replicas 来获得更高的性能与容错。
一些实战建议与排查技巧
- 现场验证 embedding 维度 :在把向量写入前,在代码里打印
vector.size(),并在控制台确认 index dimension 是否一致。- 从小批量开始 :开发和测试阶段用
batchSize=50或更小,确认链路后再扩容到 100/200。- 使用 metadata 做第二次过滤:即便 topK 返回结果很多,也在服务端用 metadata 做重排序,避免把不相关文档展示给用户。
- 命名规范:index 名称、namespace、metadata 字段都使用统一命名规范,便于运维和查询。
常见报错与如何定位
dimension mismatch→ 查看 embedding 输出长度与 index dimension 是否一致。429 Too Many Requests→ 降低批量写入量、增加重试与退避。403 Forbidden/401 Unauthorized→ API Key 异常或权限问题。- 查询结果命中率低 → 检查 embedding 模型是否适配你的文本长度和语言,是否需要做文本预处理(去 stopwords、抽取重点句)。
总结:理解并正确配置 index、dimension、namespace、metric 与 topK,是搭建稳定向量检索系统的基础。很多神秘问题,其实都来自这几个参数之一配置错误或不匹配
六、Java 接入方式(HTTP 实现)
一个简单的示例如下,这里我们只是用到jackson和httpclient:
java
@Slf4j
@Service
public class PineconeRestService {
private final RestTemplate restTemplate;
private final ObjectMapper objectMapper;
@Value("${pinecone.api.key:}")
private String apiKey;
@Value("${pinecone.index.host:}")
private String indexHost;
@Value("${pinecone.namespace:}")
private String namespace;
public PineconeRestService() {
this.restTemplate = new RestTemplate();
restTemplate.getMessageConverters().removeIf(c -> c instanceof StringHttpMessageConverter);
restTemplate.getMessageConverters().add(new StringHttpMessageConverter(StandardCharsets.UTF_8));
this.objectMapper = new ObjectMapper();
}
/**
* Upsert文本数据到Pinecone (让Pinecone自动处理文本到向量的转换)
*
* @param id 记录ID
* @param text 文本内容
* @param metadata 元数据
*/
public void upsertText(String id, String text, Map<String, String> metadata) {
try {
// 使用正确的URL格式
String url = String.format("https://%s/records/namespaces/%s/upsert", indexHost, namespace);
// 构造记录对象,符合指定的结构
Map<String, Object> record = new HashMap<>();
record.put("_id", id);
record.put("chunk_text", text);
// 添加元数据字段到记录中
if (metadata != null && !metadata.isEmpty()) {
for (Map.Entry<String, String> entry : metadata.entrySet()) {
record.put(entry.getKey(), entry.getValue());
}
}
// 发送请求
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.valueOf("application/x-ndjson"));
headers.set("Api-Key", apiKey);
// 添加API版本头
headers.set("X-Pinecone-Api-Version", "2025-10");
HttpEntity<String> requestEntity = new HttpEntity<>(JsonUtils.objectToJson(record), headers);
ResponseEntity<String> response = restTemplate.exchange(url, HttpMethod.POST, requestEntity, String.class);
if (response.getStatusCode().is2xxSuccessful()) {
log.info("Successfully upserted text with id: {}", id);
} else {
log.error("Failed to upsert text with id: {}, status: {}", id, response.getStatusCode());
throw new RuntimeException("Failed to upsert text to Pinecone, status: " + response.getStatusCode());
}
} catch (Exception e) {
log.error("Failed to upsert text with id: {}", id, e);
throw new RuntimeException("Failed to upsert text to Pinecone", e);
}
}
/**
* 使用文本进行查询 (让Pinecone自动处理文本到向量的转换)
*
* @param queryText 查询文本
* @param topK 返回结果数量
* @return 相似记录的元数据列表
*/
public List<Map<String, Object>> queryByText(String queryText, int topK) {
try {
// 使用正确的搜索URL
String url = String.format("https://%s/records/namespaces/%s/search", indexHost, namespace);
// 构造请求体
Map<String, Object> query = new HashMap<>();
query.put("inputs", Collections.singletonMap("text", queryText));
query.put("top_k", topK);
Map<String, Object> requestBody = new HashMap<>();
requestBody.put("query", query);
List<String> fields = Lists.newArrayList("type", "path");
fields.addAll(Lists.newArrayList("summary", "publishTime", "title"));
fields.addAll(Lists.newArrayList("description", "name", "takeTime"));
fields.addAll(Lists.newArrayList("label", "name", "mediaType"));
requestBody.put("fields", fields);
// 发送请求
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
headers.setAccept(List.of(MediaType.APPLICATION_JSON));
headers.set("Api-Key", apiKey);
// 添加API版本头
headers.set("X-Pinecone-Api-Version", "2025-10");
HttpEntity<Map<String, Object>> requestEntity =
new HttpEntity<>(requestBody, headers);
log.info("Sending query to Pinecone: {}", objectMapper.writeValueAsString(requestBody));
ResponseEntity<PineconeQueryResponse> response = restTemplate.exchange(url, HttpMethod.POST, requestEntity, PineconeQueryResponse.class);
if (response.getStatusCode().is2xxSuccessful()) {
// 解析响应
PineconeQueryResponse responseBody = response.getBody();
assert responseBody != null;
List<Map<String, Object>> results = responseBody.getResult().getHits().stream().map(PineconeQueryResponse.Match::getFields).collect(Collectors.toList());
log.info("Successfully searched {} records from Pinecone", results.size());
return results;
} else {
log.error("Failed to search records from Pinecone, status: {}", response.getStatusCode());
throw new RuntimeException("Failed to search records from Pinecone, status: " + response.getStatusCode());
}
} catch (Exception e) {
log.error("Failed to search records from Pinecone", e);
throw new RuntimeException("Failed to search records from Pinecone", e);
}
}
}当然除了这个之外,我们还需要实现我们的langchain调用链。
1. 知识库问答(RAG)实现方式
当 AI 判断需要检索知识库时(如返回 [VECTOR_SEARCH:xxx]),Java 进入 RAG 流程。
主要流程
- AiResponseParser 从 LLM 返回的文本中解析出搜索指令
- 触发 Pinecone 检索
- 返回向量召回的内容给 LLM,让其生成最终总结
关键组件
| 组件 | 作用 |
|---|---|
| AiResponseParser | 检测是否包含 [VECTOR_SEARCH:keyword] 指令 |
| AiSearchService | 负责调用 PineconeRestService 执行语义检索 |
| PineconeRestService | Java 直接调用 Pinecone REST API |
| AdvancedAiSearchChain | 封装关键词提取 → 检索 → 再总结整套流程 |
支持的检索类型
[RECENT_POSTS]最近文章[POPULAR_POSTS]热门文章[LIKED_POSTS]点赞最多文章[VECTOR_SEARCH:keyword]语义搜索(核心 RAG 功能)- 支持分页:
[TYPE,PAGE_SIZE:x,PAGE_NUM:y]
知识库内容类型
- 文章:标题、简介、时间
- 附件:名称、媒体类型
- 图片:名称、描述、拍摄时间
所有内容都自动同步进 Pinecone(文章/附件/照片三种事件监听器 + 定时任务)。
2. Java 端完整调用链总结
下面是集成后的统一调用链(已去掉细节,只保留关键节点):
- 用户请求进入 Controller
- AdvancedAiSearchChain 构建系统提示词
- OpenAiAdapterService → 拼接历史 → 调 OpenAI Chat
- AiResponseParser 判断是否需要检索
- 如需要 → PineconeRestService 执行向量搜索
- 得到搜索结果后再次调用 OpenAI 生成总结
- Controller 以 SSE 流形式返回最终答案
完整的调用流程如下:
3. 如何触发知识库搜索(示例)
用户问:
"你能介绍一下机器学习吗?"
LLM 可能回应:
csharp
[VECTOR_SEARCH:机器学习]Java 收到后解析指令 → Pinecone 检索 → 将召回内容再次发给 LLM → 生成最终回答。
七、数据建模:如何设计 metadata
在构建知识库(特别是面向博客系统的 RAG 管道)时,数据建模是最容易被忽视却最关键的部分。良好的数据模型不仅影响向量召回的准确性,也直接决定了后续提示词工程(Prompt Engineering)的灵活度和可控性。
对于博客来说,主要的知识来源一般包括三类:文章、附件、图片。不同资源类型在拆分、表征(embedding)和索引时都会采用不同的策略,因此需要设计一套统一且可扩展的 metadata 结构来描述每个 chunk 的来源与属性。
1. 文本块chunk-text设计
1. 文本内容(文章)的 chunk-text 设计
博客文章通常是结构化的长文本,因此需要通过分段拆分策略,将文章拆成多个可检索的内容片段。常用拆分方式包括:
- 按段落拆分:根据 Markdown 或 HTML 的段落结构进行切片,保持语义完整性。
- 按标题层级拆分:例如按照 h1/h2/h3 作为边界,将文章自然分块。
- 按固定长度拆分:例如每 300~500 字一段,并加入重叠(overlap)以避免语义断裂。
这样做的优点是提高向量检索的召回质量,让 RAG 能在更细粒度的片段中找到问题对应的知识点。这里我们可以直接按段落拆分,这样我们能够更好控制文本大小,但是要注意输入的token限制,如果我们选用的embedding是内嵌的模型,那么段落大小就不能超过1024,如果超过我们就要做截断或者提前预处理再写入
2. 附件(PDF/文档等)的 chunk-text 设计
附件是博客知识库常见但容易忽视的部分,它们通常包含额外的技术图表、文档或外链资料。附件文本的 chunk-text 一般来自:
- 对文件内容的 摘要提取(如 PDF→文本→摘要)
- 对非文本文件进行 OCR 提取(如截图类文档)
- 或者直接保留部分关键页作为 embedding 内容
由于附件通常较长,但用户提问时很少直接引用附件原文,因此使用摘要作为 chunk-text 能大幅减少索引噪音。
3. 图片的 chunk-text 设计:AI 生成 alt 描述
为了让 RAG 能真正理解图片,需要将图片转化为可用于向量模型的文字描述。通常的做法是:
- 使用视觉模型(如 GPT-4o、Gemini Vision 等)生成 alt 描述
- 可补充检测:图片主题、场景、物体、标签
- 对技术类图片,还可以自动识别代码段、架构图模块等
这样,图片也能像文本一样参与检索,并在回答中引用来源。
2. Metadata 的字段设计
为了让所有 chunk 能被统一索引并在提示词中引用,需要为每一条向量数据设计 metadata。常见字段包括:
1. 基础来源信息
- sourceUrl:内容的原始来源,例如博客文章链接,用于回答时引用。
- articleId:文章唯一 ID,便于对文章做批量更新/重建索引。
- fileType :类型标识,如
"article" | "attachment" | "image"。 - chunkIndex:当前 chunk 在整篇文章中的分段序号(便于上下文拼接)。
2. 资源相关信息
- title:对应的文章标题。
- fileName:如果是附件则记录文件名。
- imageCategory :对图片进行自动分类,如
"diagram","photo","screenshot","code-snippet"。
3. 内容维度信息
- createdTime / updatedTime:用于版本控制和自动重建。
- tags / categories:与博客标签体系一致,提升检索相关性。
- language:对多语言博客特别有用。
4.metadata 在 RAG 中的作用
这些 metadata 字段的意义体现在后续的提示词工程中,例如:
- 用
sourceUrl在回答末尾提供参考来源 - 用
imageCategory判断是否需要附带图片描述 - 用
fileType控制回答引用的范围(只引用文章,不引用图片或附件) - 用
chunkIndex让 LLM 自动拼接相邻段落,降低断裂感
最终效果是让 RAG 不只是"搜索最相似的段落",而是真正作为一个"结构化的知识库"参与回答。
八、踩坑实记(重点)
1. JSON 解析错误(Jackson)
Pinecone 官方文档的 Curl 示例里:
- Upsert 请求需要 String 转义(否则 400)
- Query 请求返回 JSON 对象,不能用 String 接收
否则会报:
typescript
Cannot deserialize value of type `java.lang.String` from Object value2. SpringBoot 2.7 的 UTF-8 编码问题
一定要确保:
- HttpMessageConverter 用 UTF-8
- 日志输出不要乱码
3. 本地/生产网络差异
服务器不通 Pinecone 域名会踩大坑:
- 要开防火墙出站
- 有些服务器需要绑定 DNS
4. httpclient 版本冲突
Spring Boot 2.x 自带 HttpClient 太老,Pinecone SDK 内部版本太新,导致:
- NoSuchMethodError
- Method not found
- ClassCastException
最终结论:不要用 SDK!
九、性能优化与成本控制
- 免费额度有限,embedding 很贵,请保守调用
- 不要把全文写入向量库,要遵循:"摘要为主,全文为辅"
- 控制 chunk 大小,一般 200-300 token 最好,
十、测试与监控
- 先写入几十条数据:建议使用本地或预发布环境,通过脚本或简单的循环写入,将文章、图片描述、附件说明等多类型数据各准备一些。这样可以提前验证 metadata 结构、向量维度、编码、请求体格式是否正确。
- 增量链路测试写入 :实际项目中,历史数据一次性写入只是第一步,更关键的是后续的"新增或更新数据"是否能被正常同步到 Pinecone。因此可以通过模拟真实业务链路进行测试,例如:
- 新增文章 → 触发事件 → 生成 embedding → 写入 Pinecone
- 修改文章 → 对比差异 → 更新 metadata 与向量
- 删除文章 → 清理对应 namespace 或删除向量 通过完整走一次业务链路,可以验证向量生成、写入、更新、查询的完整闭环。
- 构建简单测试:根据关键词搜索是否能命中:准备多个语义接近但字面不同的关键词(例如:"部署"、"发布"、"上线")。如果 Pinecone 能命中文章,则说明 embedding + retrieval 是有效的。
十一、部署与运维
1. 历史数据迁移
建议批量写入,但必须控制 QPS,否则 Pinecone 会返回 429。
2. 增量同步
-
JPA → 可以通过 save/update 事件监听同步
例如:
java@Override public Photo create(Photo photo) { Photo createdPhoto = super.create(photo); // Publish photo updated event eventPublisher.publishEvent(new PhotoUpdatedEvent(this, createdPhoto)); return createdPhoto; } @Override public Photo update(Photo photo) { Photo updatedPhoto = super.update(photo); // Publish photo updated event eventPublisher.publishEvent(new PhotoUpdatedEvent(this, updatedPhoto)); return updatedPhoto; } -
MyBatis → AOP 拦截修改操作
十二、结论:最佳实践汇总
最后我们实现的效果如下:

总结:
- Spring Boot 2.x 不要用 SDK,全部用 HTTP
- Pinecone embedding 很香且便宜
- 不要全文同步,保证 chunk 精简
- 遇到 JSON 错误时优先排查:序列化格式 + UTF-8