

在软件开发的整个生命周期中,需求变更无处不在。特别是在敏捷与DevOps环境下,迭代频繁、需求多变,给测试团队带来了巨大挑战:
-
如何第一时间感知需求的变化?
-
如何判断变更影响哪些已有测试用例?
-
如何避免冗余测试与遗漏测试?
-
如何在变更中保持测试覆盖与质量?
传统测试流程往往依赖人工比对、经验判断,这在复杂项目中效率低、风险高。而随着自然语言处理(NLP)与深度学习的发展,语义相似度模型正日益成为应对需求变更挑战的关键利器。
本文将系统阐述语义相似度模型在测试需求变更中的核心应用逻辑、技术路径与落地实践,帮助企业构建更具韧性与智能感知能力的测试体系。
一、测试需求变更带来的挑战
1. 变更频繁但粒度多样
-
有的变更是术语调整、说明优化;
-
有的是逻辑扩展、新功能添加;
-
更严重的如角色变更、边界条件变化。
传统处理方式:
-
以需求版本为维度手动比对 → 费时费力
-
依赖业务专家判断变更影响 → 结果不一致
2. 测试用例响应机制滞后
-
无法自动识别哪些用例受影响;
-
可能对未变化的部分重新测试,浪费资源;
-
也可能遗漏关键路径,造成回归风险。
二、什么是语义相似度模型?
1. 基本定义
语义相似度模型旨在衡量两个文本之间"语义上有多接近",而非表面关键词是否一致。
举例:
A: 用户登录时应验证用户名和密码是否匹配。
B: 系统需校验登录凭据的有效性。尽管字面不同,但语义非常接近。传统匹配方法难以判断,而语义模型可以精准捕捉到这种"深层相似性"。
2. 主流技术路线
| 模型类型 | 特点 |
|---|---|
| TF-IDF/词袋模型 | 快速但仅捕捉词级相似性,语义弱 |
| Word2Vec、GloVe | 词向量级别的语义理解 |
| BERT、RoBERTa | 基于Transformer的预训练语言模型,句子级理解 |
| SimCSE、SBERT | 专门优化句子相似度的模型,性能领先 |
| 中文语义模型 | 如Langboat, Chinese-BERT, C-BERT-wwm-ext,适用于中文测试场景 |
✅ 建议使用适合测试领域语料微调过的模型(如使用企业历史需求-用例对数据)
三、语义相似度模型在需求变更中的核心应用场景
场景1:需求变更影响测试用例识别
输入:新版需求项
目标:找出与之语义接近的旧测试用例 → 判断是否需要更新/删除/重写
示例:
旧需求: "管理员可以通过后台重置用户密码"
变更后: "管理员仅在用户身份验证通过后才能重置密码"
模型输出最相似用例(Top 5):
`
`
* 用例1:测试管理员如何在控制台操作密码重置(得分0.93)
* `用例2:测试用户身份验证模块(得分0.88)`
`
...`➡ 得分 > 0.85 的用例标记为"可能受影响",纳入回归验证范围。
场景2:辅助用例自动生成与对齐
新需求变更后,可基于高相似历史需求-用例对,借助LLM模板+语义检索快速生成草案。
语义模型检索 → LLM生成用例草案 → 测试人员验证修改
场景3:需求覆盖追踪中的智能对齐
测试覆盖分析时,将测试用例与变更后的需求进行语义比对:
-
若覆盖度下降,提示用例缺失;
-
若多用例高相似同一需求,提示合并优化。
四、系统设计
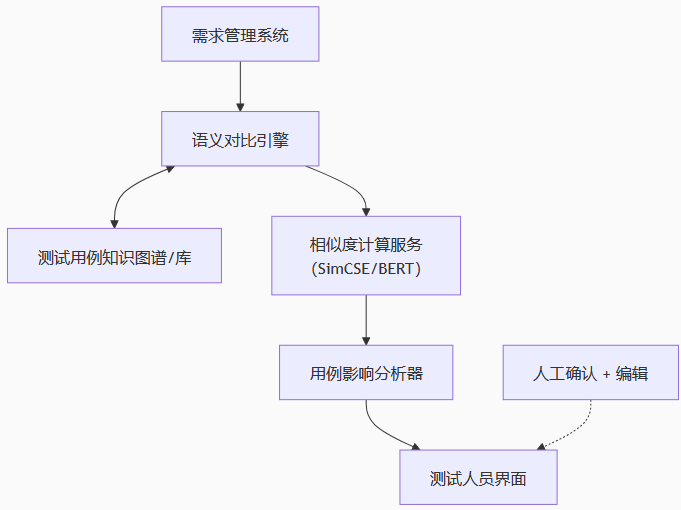
1. 系统架构图
编辑
2. 核心模块说明
| 模块 | 功能 |
|---|---|
| 语义对比引擎 | 输入新旧需求/用例,调用模型输出相似度 |
| 相似度模型 | 支持句向量提取(SimCSE/BERT),支持fine-tune |
| 用例图谱 | 结构化存储历史用例、模块归属、执行记录等 |
| 影响分析器 | 设定阈值判断影响范围,生成推荐清单 |
| 人机协同界面 | 展示Top-N相似用例,支持人工确认 |
五、实践案例
技术选型
-
模型:
hfl/chinese-roberta-wwm-ext + SimCSE -
相似度计算库:
SentenceTransformers -
后端服务:
FastAPI -
图谱库:
Neo4j(存放用例关系)
示例代码片段
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('shibing624/text2vec-base-chinese')
`def compute_similarity(query, candidates):`
`
query_emb = model.encode(query, convert_to_tensor=True)`
`
cand_emb = model.encode(candidates, convert_to_tensor=True)`
`
scores = util.cos_sim(query_emb, cand_emb)`
`
return scores`效果展示
| 新需求变更 | 最相似测试用例 | 相似度 |
|---|---|---|
| 登录增加手机验证码验证 | 测试登录验证码输入正确跳转流程 | 0.92 |
| 文件上传限制调整 | 测试上传大小限制逻辑 | 0.89 |
结合评分阈值(如0.85),可生成"测试用例变更清单"供测试负责人审核。
六、优势与挑战分析
优势
-
快速识别需求变更对测试的潜在影响
-
降低冗余回归测试成本
-
保障变更后需求的测试覆盖完整性
-
可与知识图谱、RAG等技术协同增强智能度
面临挑战
-
中文测试语料有限,模型微调数据缺乏
-
不同项目术语不一致,需归一化预处理
-
语义相似 ≠ 完全匹配,仍需人工参与
七、未来展望
-
构建测试智能体,实时监听需求变化 → 自动判断影响范围 → 触发用例推荐与执行计划调整
-
在CI/CD流程中集成语义感知模块,实现测试资源动态调度
-
结合RAG和知识图谱,提升"用例生成+变更响应+缺陷定位"的自动化闭环能力
结语
语义相似度模型在测试需求变更场景中展现出巨大潜力,正在成为现代测试流程中"感知变更、判断影响、优化测试"的关键驱动因素。通过引入该技术,企业能够构建更智能、更敏捷、更具洞察力的测试体系,为软件质量提供强有力的保障。
"让测试不再被动响应变更,而是主动感知、精准应对,这是智能测试的未来方向。"