Intersect Over Union (IoU)
我们考虑一下分类图像然后在对象周围画边框的任务。在图 6-3, 你可以看到我们的期望输出的例子 (这里的分类是猫)。

图 6-3. 目标分类和定位的例子
这是完全监督的任务。这意味着我们需要学习在哪里画边框并与真的进行比较。我们需要量度确定预测边框与实际边框重合的好坏。这通常使用 IOU (Intersect Over Union)。在图 6-4, 你可以看到关于它的可视化解释。
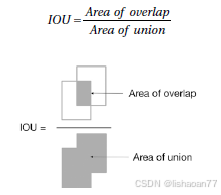
图 6-4. IOU量度的可视化解释
重合很好的理想情况下,我们有 IOU = 1,而没有重合的情况下,IOU = 0。你可以在博客或书上看到这个术语,所以知道如何用真实图片测量边框是很好的想法。
解决目标定位的朴素的方法(滑动窗口方法)
解决定位的朴素方法如下 (提示:这不是好的办法但是很直观):
-
你从图像的左上角切一小部分。假如你的图片的维为 x , y, 而你的小部分为w x , wy, 其中 wx < x**和 wy < y*。*
-
你使用预训练的网络 (如何训练或如何获得关不关注)你让它分类你的小部分。
-
你向右然后向下移动窗口一小部分,称为 s tride 并记为 s 。你用网络来分类第二部分。
-
当移动窗口滑过整张图像时,你选择分类概率最高的窗口位置。这个位置给出对像的边框。 (记住你的窗口的大小为 wx , wy).
在图6-5,你可以看到算法的图形展示(我们取 wx = wy = s).
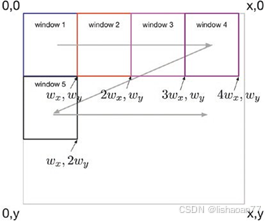
图6-5. 用滑动窗口解决目标定位的图形展示
如你所见,在图 6-5, 我们开始从左上解开始向右滑动。当到达右边界时我们不能再向右移,我们向下移再从左边开始向右移S个像素。我们继续这种模式直到到达图像的右下角。
你立即可以发现这种方法的问题:
-
- 取决于 wx , wy,和 s ,我们不一定能覆盖整个图像 (你看到图 6-5里有小部分没有被 分析吗?)
- 你如何选择 wx , wy,和 s ?这是个很讨厌的问题。因为我们的对象的边框的维为 wx , wy*。要是对象更大或更小呢* ? 我们不能预先知道它的维,这是个大问题,如果我们要精确的边框。
- 如果我们的对象跨了两个窗口呢?在图 6-5,你可以想像对于一半在窗口2 另一半在窗口 3。而你的边框不正确, 如果你按描述的算法进行。
我们可以使用s = 1来解决第三个问题,确保覆盖所有可能的情况,但是前两个问题不太好解决。要解决窗口大小问题,我们可以使用所有可能的大小和所在可能的比例。这里在问题吗?数量无法控制,计算很快变得不可能。
滑动窗口的问题和局限
为了让事情简单,我使用 MNIST数据集,因为你非常了解它而且它很容易使用。第一步我用MMIST数据集训练CNN,准确率为99.3% 。然后我保存模型和权重于磁盘。我使用的CNN 的结构如下:
Layer (type) Output Shape Param #
===============================================================
|------------------------------|--------|---------|-----|---------|
| conv2d_1 (Conv2D) | (None, | 26, 26, | 32) | 320 |
| conv2d_2 (Conv2D) | (None, | 24, 24, | 64) | 18496 |
| max_pooling2d_1 (MaxPooling2 | (None, | 12, 12, | 64) | 0 |
| dropout_1 (Dropout) | (None, | 12, 12, | 64) | 0 |
| flatten_1 (Flatten) | (None, | 9216) | | 0 |
| dense_1 (Dense) | (None, | 128) | | 1179776 |
| dropout_2 (Dropout) | (None, | 128) | | 0 |
| dense_2 (Dense) | (None, | 10) | | 1290 |
===============================================================
Total params: 1,199,882
Trainable params: 1,199,882
Non-trainable params: 0
我用下面的代码保存模型和权重 (我们已经讨论过):
model_json = model.to_json()
with open("model_mnist.json", "w") as json_file: json_file.write(model_json)
model.save_weights("model_mnist.h5")
在图6-6你可以看到网络的训练和准确率的变化。
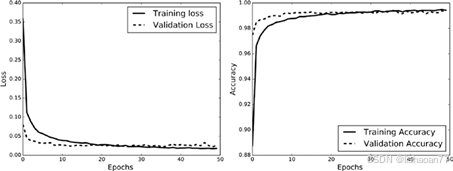
图 6-6. 训练集和验证集里损失和准确率的变化
这样做是为了避免每次都复新训练模型。我可以重复的使用模型,通过重新加载。你可以用这个代码:
model_path = '/content/drive/My Drive/pretrained-models/model_ mnist.json'
weights_path = '/content/drive/My Drive/pretrained-models/ model_mnist.h5'
json_file = open(model_path, 'r') loaded_model_json = json_file.read() json_file.close()
loaded_model = model_from_json(loaded_model_json) loaded_model.load_weights(weights_path)
为了让事情简单。我决定创建大的图像,中间有一个数字,我们在它周围画边框的效率有多高。我用下面的代码创建图像:
model_path = '/content/drive/My Drive/pretrained-models/model_ mnist.json'
weights_path = '/content/drive/My Drive/pretrained-models/ model_mnist.h5'
json_file = open(model_path, 'r') loaded_model_json = json_file.read() json_file.close()
loaded_model = model_from_json(loaded_model_json) loaded_model.load_weights(weights_path)
为了让事情简单。我决定创建大的图像,中间有一个数字,我们在它周围画边框的效率有多高。我用下面的代码创建图像:
from PIL import Image, ImageOps
src_img = Image.fromarray(x_test5.reshape(28,28))
newimg = ImageOps.expand(src_img,border=56,fill='black')

结果图像是 140x140 像素。你可以在图 6-7里看到。
图 6-7. 在 MNIST 数据集的图像周围增加 56 个像素创建新的图像
现在我们用28x28像素的窗口滑动。我们可以写一个函数来定位数字,并输入图像, stride s,以及w x 和 wy 的值 :
def localize_digit(bigimg, stride, wx, wy): slidx, slidy = wx, wy
digit_found = -1
max_prob= -1
bbx = -1 # Bounding box x upper left bby = -1 # Bounding box y upper left max_prob_ = 0.0
bbx_ = -1
bby_ = -1
most_prob_digit = -1
maxloopx = (bigimg.shape0 -wx) // stride maxloopy = (bigimg.shape1 -wy) // stride print((maxloopx, maxloopy))
for slicey in range (0, maxloopx*stride, stride): for slicex in range (0, maxloopy*stride, stride):
slice_ = bigimgslicex:slicex+wx, slicey:slicey+wx img_ = Image.
fromarray(slice_).resize((28, 28), Image. NEAREST)
probs = loaded_model.predict(np.array(img_). reshape(1,28,28,1))
if (np.max(probs > 0.2)): most_prob_digit = np.argmax(probs) max_prob_ = np.max(probs)
bbx_ = slicex bby_= slicey
if (max_prob_ > max_prob): max_prob = max_prob_
bbx = bbx_ bby
= bby_
digit_found = most_prob_digit
print("Digit "+str(digit_found)+ " found, with probability "+str(max_prob)+" at coordinates "+str(bbx)+" "+str(bby))
return (max_prob, bbx, bby, digit_found)
Running on our image as so:
localize_digit(np.array(newimg), 28, 28, 28)
Returns this code:
Digit 1 found, with probability 1.0 at coordinates 56 56
(1.0, 56, 56, 1)
结果边框可以见图 6-8。

图 6-8. 滑动窗口 wx = 28, wy = 28, 和 s = 28找到的边框
这工作得很好。但是你可能注意到我们命名用的w x , wy,和 s 的值都是 28, 刚好的图像的大小。如果我们改变它呢?例如图 6-9的例子。你可以看这这个方法停止工作,只要值不是28。

图 6-9. 用不同的wx, wy,和 s值 滑动窗口
检查一下图6-9里左下的分类的置信度。它很低,例如40x40和 stride为10的窗口,分类准确但概率为 (a 1) 21%。这是很低的值。在右下框,分类完全错。记住你需要改变窗口的大小,它看来与训练数据不同。在这个例子里,看来很容易选择窗口的大小,因为你已经知道图像的样子了,但是实际上你通常是不知道哪个值是有用的。你要检查不同的值来确定最好的一个。这样很快就变得不可行了,实际的图像里有多个不同的对象,它们的大小都不确定。
分类和定位
我们看到滑动窗口不是好的办法。更好的办法是使用多任务学习。这个思想是我们可以构建网络同时进行分类和画边框。我们可以在CNN后面增加两个全链接层。一层有 N c 个神经元 (分 N c
个类)用交叉熵损失函数预测分类 (记为 Jclassification ), 一层有4个神经元用来学习画边框使用 ℓ 2 损失函数 (我们记为 JB B )。你可以在图 6-10看到图示。
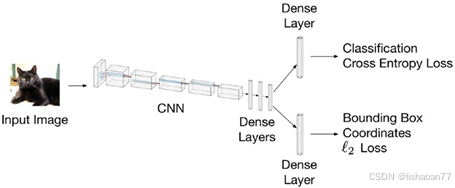
图 6-10. 图形说明可以同时预测分类和画边框的神经网络
因为这是多任务学习问题,我们要最小化二个损失的线性组合:
J classification + a J BB
当然, α**是另一个需要微调的超参数。作为参考, ℓ 2 损失正比以 MSE
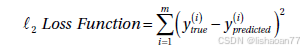
我们记m 为观察数。这在人类姿态预测里很成功,它找到人体的特定点 (如关节),见图 6-11.
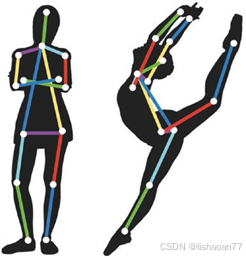
图 6-11. 姿态预测的例子。可以训练 CNN来找到人体的关键点,例如关节。
这个领域有很多的研究,下一节我们看一下这种方法是如何工作的。实现很复杂很费时。如果你要实现这种算法,最好看一下原始论文并研究它们。 这一章我们看一下目标定位CNNs 变种和快速 R-CNN。下一章我们看一下YOLO (You Only Look Once)算法。