在深度学习尚未普及的年代,自然语言处理(NLP)领域面临一个普遍难题:大多数模型都严重依赖大量人工标注的数据,这不仅耗费人力物力,还限制了模型在低资源场景下的表现。而与此形成鲜明对比的是,互联网上存在海量未标注的文本数据。如果能利用这些无标签语料学习语言的深层联系,我们是否能训练出通用、强大、具备迁移能力的语言模型?
2018 年,OpenAI 发布了里程碑式论文《Improving Language Understanding by Generative Pre-Training》,也就是 GPT的起点。这篇论文首次提出了一种有效的生成式预训练+判别式微调(Generative Pre-Training + Discriminative Fine-Tuning)的框架,为大语言模型的发展奠定了基础。
论文指出了两大核心挑战:
- 如何设计有效的无监督优化目标?
不同目标(如语言建模、机器翻译、话语连贯性)在不同任务上表现各异,尚无统一标准。 - 如何将无监督学习到的知识迁移到下游任务?
早期方法通常需要为每个任务单独设计模型结构,缺乏统一性与可扩展性。
为了解决这两个问题,GPT-1 提出了一个通用的框架。
希望大家带着下面的问题来学习,我会在文末给出答案。
- GPT-1 如何利用海量未标注文本来提升有监督任务的效果?和传统 NLP 方法有何本质区别?
- GPT-1 是如何将不同类型的任务(如文本蕴含、问答、句子相似度)统一输入格式、用同一个模型处理的?
- 相比传统 LSTM 或 CNN 等架构,GPT-1 为什么选择使用 Transformer Decoder?这种架构在迁移学习中有什么优势?
一、无监督预训练
预训练阶段的目标是训练一个通用语言模型,从大量未标注文本中捕捉语言的统计结构与语义知识。使用了BooksCorpus(包含 7000 多本小说)作为训练数据,连续文本结构有助于模型学习上下文联系。
模型结构
使用了一个 12 层的 Transformer Decoder(注意,是解码器而非完整的 Encoder-Decoder),具备自注意力机制,能有效捕捉长距离依赖。

其中
- h0:输入嵌入向量,由词嵌入We和位置嵌入Wp相加得到
- We:token 的词向量矩阵
- Wp:位置编码矩阵(learned)
- hl:第 L层 Transformer 的输出向量
- TransformerBlock:一个标准 Transformer 解码器块,包含多头自注意力和前馈网络
- P(u):对所有词进行 softmax 得到的概率分布(即当前 token 的预测结果)
训练目标
标准的语言建模任务,预测下一个单词
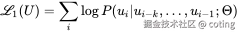
其中
- L1(U):语言建模的损失函数,对整个未标注文本语料 U 的损失值
- U = {u_1, u_2, ..., u_n}:未标注的文本序列,每个 ui 是一个 token(词或子词)
- k:上下文窗口大小(表示当前词是基于前多少个词预测的)
- P:当前 token ui 在给定前 k 个 token 的条件下的预测概率,参数由模型 Θ 控制
- Θ:模型的全部参数,包括词向量、Transformer 层等
二、有监督微调
在完成通用预训练之后,作者将模型迁移到具体的 NLP 任务中进行微调,例如情感分类、自然语言推理、问答等。
任务适配技巧
GPT-1 模型的核心优势之一,是其使用了统一的 Transformer 解码器结构。这要求所有下游任务的输入都必须以相同的格式传入模型,即:一个连续的 token 序列。
由于不同任务的输入形式各不相同(如单句、句对、问答三元组),GPT-1 引入了任务特定的输入转换方法(Input Transformations),借助一些简单规则将复杂结构转化为统一格式,使预训练模型能直接读取并处理。
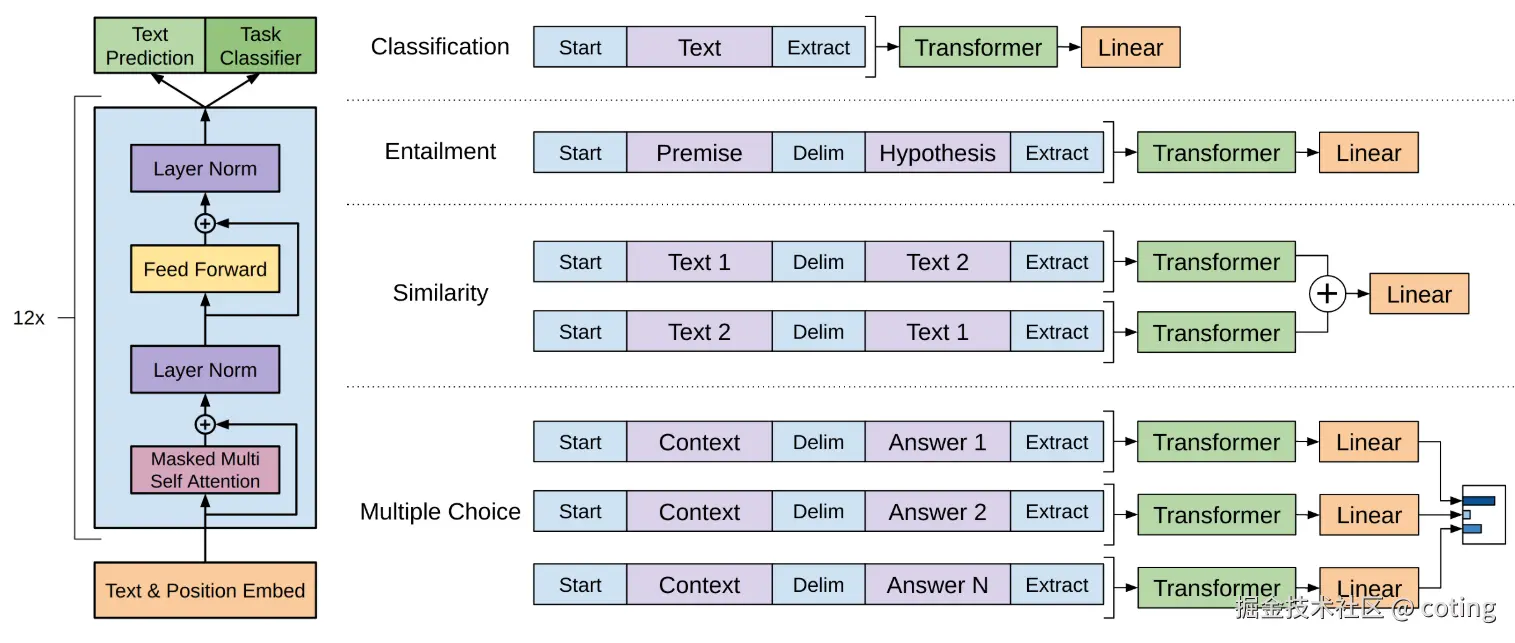
下面我们分任务简要说明其处理方式:
1. 文本蕴含任务(Textual Entailment)
任务形式:给定一个前提句(Premise)p 和一个假设句(Hypothesis)h ,判断二者是否存在蕴含、矛盾或中性关系。
转换方式:
将前提句和假设句拼接为一个 token 序列,中间使用分隔符 token(例如 $)连接:
plain
输入格式:[p; $; h]然后将整个序列送入预训练模型,最终通过 softmax 分类为三类之一。
2. 语义相似度任务(Sentence Similarity)
任务形式:判断两个句子是否语义相近。
挑战:句子没有固定顺序,即A, B和B, A应该等价。
转换方式:
对每一对句子s1、s2,构造两种顺序的输入:
plain
输入1:[s1; $; s2]
输入2:[s2; $; s1]分别通过预训练模型,获得两个最终表示h1,h2,然后做元素级加和后送入输出层进行分类或打分。
3. 问答与常识推理任务(Question Answering & Commonsense Reasoning)
任务形式:给定一段上下文z,一个问题q,和多个候选答案 {a_k},选出正确答案。
转换方式:
对于每个候选答案 a_k,构造如下序列:
plain
[z; q; $; a_k]将每个候选答案序列分别输入模型,得到每个的 logit(打分),最后使用 softmax 归一化,选出得分最高的答案。
通过上述策略,GPT-1 将所有任务的输入标准化为线性 token 序列,不需要为每个任务重新设计模型结构或分支网络,大大简化了模型部署与迁移的难度。
模型结构
- 输入变换:将任务输入(如句子对、问答三元组)转换为连续的 token 序列,使其适配预训练模型结构。
- 输出层:在 Transformer 顶部加一层全连接 softmax 层进行分类或预测。
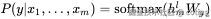
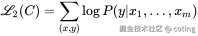
其中
- x1......xm:输入序列(如问题、句子对等)
- h_ml:Transformer 最后一层中最后一个 token 的表示向量(可以视为整个序列的特征)
- Wy:任务特定的输出层参数
- P(y | x):预测的标签概率(如类别)
- L2(C):有监督训练的交叉熵损失,C 是带标签的训练集
训练目标
在微调时,作者发现保留语言建模任务作为辅助目标有助于泛化能力和收敛速度。最终优化目标为:
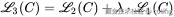
- L3:联合损失函数(最终用于训练)
- λ:权重系数,用于平衡主任务和语言建模任务的影响(论文中设置为 0.5)
- L1(C):在带标签数据 C 上继续使用语言建模目标(辅助任务)
- L2(C):主任务的监督损失
三、任务适配:通用模型的统一接口
GPT-1 在多个任务上取得了惊人的迁移效果:
- 自然语言推理(NLI):在 MNLI、SNLI、SciTail 等任务上超越当时 SOTA 方法。
- 问答与常识推理:在 RACE 和 Story Cloze 上取得了最高准确率(如 Story Cloze 提升 8.9%)。
- 语义相似度:在 STS-B 上比前人提升 1 个百分点。
- 文本分类:在 CoLA 任务中准确率从 35% 提升至 45%,展现出对语言可接受性的强理解能力。
论文最终展示出一个单一的、任务无关的 Transformer 模型,通过预训练和微调的方式,可以统一处理各种自然语言理解任务,并在多个任务上刷新了 SOTA 成绩。
四、总结
尽管 GPT-1 相比后续版本参数量相对较小(117M),它却开创了**"预训练 + 微调"**的大模型范式。
- 抛弃任务定制模型架构,实现统一的 Transformer 结构。
- 显著提升少样本甚至零样本(Zero-shot)任务的性能。
- 为后续的 GPT-2、GPT-3 等大规模模型提供了验证思路和实验基础。
GPT-1 让我们看到了语言模型不仅能生成文本,还能"理解"文本。当预训练模型掌握了语言规律,它可以快速适应下游任务,甚至在数据极少的情况下仍表现强劲。
如今,语言模型早已不再局限于单一任务。GPT-1 是这一切的起点,它开启了一种新的范式,也引领我们走入了大模型时代。
最后,我们回答一下文章开头提出的问题。
- GPT-1 如何利用海量未标注文本来提升有监督任务的效果?和传统 NLP 方法有何本质区别?
GPT-1 首先通过语言建模目标,在大规模未标注语料(如 BooksCorpus)上进行无监督预训练,从中学习语言结构与知识表示,然后在具体任务上通过少量标注数据进行微调(fine-tuning)。与传统方法相比,它不再依赖为每个任务训练独立模型,而是训练一个具有通用语言理解能力的"预训练模型"。
- GPT-1 是如何将不同类型的任务(如文本蕴含、问答、句子相似度)统一输入格式、用同一个模型处理的?
GPT-1 引入了任务特定的输入转换(Input Transformations)策略,将不同任务的结构化输入(如句对、问答三元组)转化为统一的 token 序列,例如 [前提; $; 假设] 或 [上下文; 问题; $; 答案]。这样预训练模型就无需修改结构,就能适配各种任务。
- 相比传统 LSTM 或 CNN 等架构,GPT-1 为什么选择使用 Transformer Decoder?这种架构在迁移学习中有什么优势?
Transformer Decoder 结构具备更强的建模长距离依赖的能力,适合处理长文本语料,同时其自注意力机制能够并行训练、语义感知能力强。相比 LSTM,Transformer 更易于迁移、泛化能力更好,在多个下游任务上都能实现显著性能提升。
关于深度学习和大模型相关的知识和前沿技术更新,请关注公众号算法coting!
所有相关源码示例、流程图、模型配置与知识库构建技巧,我也将持续更新在Github:LLMHub,欢迎关注收藏!