ai 文生图
- 前言:从"静止画卷"到"动态电影"的转变
- 第一章:文生视频的挑战:时间维度上的"一致性地狱"
-
- [1.1 核心难题:每一帧的"生老病死"与"连贯性"](#1.1 核心难题:每一帧的“生老病死”与“连贯性”)
- [1.2 为什么简单的图像扩散堆叠行不通?](#1.2 为什么简单的图像扩散堆叠行不通?)
- [第二章:Video Latent的诞生:将视频压缩为"时空精华"](#第二章:Video Latent的诞生:将视频压缩为“时空精华”)
-
- [2.1 概念:视频潜在表示------时间与空间的融合](#2.1 概念:视频潜在表示——时间与空间的融合)
- [2.2 VAE的"时空压缩机":如何将视频编码为Latent?](#2.2 VAE的“时空压缩机”:如何将视频编码为Latent?)
- [第三章:Video Latent的扩散结构:时空U-Net的"双重魔法"](#第三章:Video Latent的扩散结构:时空U-Net的“双重魔法”)
-
- [3.1 U-Net的"时空魔改":同时理解空间与时间](#3.1 U-Net的“时空魔改”:同时理解空间与时间)
- [3.2 空间注意力层与时间注意力层:AI的"多维视角"](#3.2 空间注意力层与时间注意力层:AI的“多维视角”)
- [3.3 简化的视频U-Net Block实现](#3.3 简化的视频U-Net Block实现)
- 第四章:文生视频的完整工作流:从Prompt到动态视觉
-
- [4.1 数据输入:Prompt与多帧噪声Latent](#4.1 数据输入:Prompt与多帧噪声Latent)
- [4.2 核心循环:时空U-Net的去噪舞蹈](#4.2 核心循环:时空U-Net的去噪舞蹈)
- [4.3 最终解码:VAE Decoder的"电影还原术"](#4.3 最终解码:VAE Decoder的“电影还原术”)
- [Video Latent扩散模型的完整架构](#Video Latent扩散模型的完整架构)
- 帧率、分辨率与视频时长:视频生成中的"魔法刻度"
- 总结与展望:AI视频生成,理解动态世界的新范式
前言:从"静止画卷"到"动态电影"的转变
我们已经学会了如何用Stable Diffusion生成精美的图片,甚至用AnimateDiff让它们动起来。但那更像是在静态画卷上"注入"运动,每一帧依然由图像模型负责。
而真正的文生视频,追求的是从零开始,直接生成一段具有内在时空连贯性、符合物理逻辑的电影。这就像AI从一个只会画静止风景的画家,变身成一个能掌控"魔法时间轴"的导演。
视频生成比图像生成复杂得多。核心挑战在于时间维度上的"一致性地狱"。物体在不同帧的形态、光影、运动轨迹都必须完美连贯,否则就会出现闪烁、跳帧、鬼影等问题。

今天,我们将深入文生视频的核心------Video Latent的扩散结构。我们将理解视频如何被编码为低维的"时空精华",以及扩散模型如何在这"时空精华"中施展魔法,生成连贯的动态世界。
第一章:文生视频的挑战:时间维度上的"一致性地狱"
分析视频生成的本质难题,即如何在时间维度上保持高度一致性。
1.1 核心难题:每一帧的"生老病死"与"连贯性"
视频生成不仅是多张图片的生成,更在于:
对象永生:一个物体在第一帧出现,在后续帧必须保持其身份、形状、颜色的一致性。
轨迹连贯:物体的运动轨迹必须平滑、符合物理规律。
光影流动:光照、阴影必须随时间自然变化。
细节一致:毛发、纹理、背景等微观细节在不同帧之间也需保持合理一致。
任何一帧的微小不一致,都会导致视频出现"闪烁"、"跳帧"、"鬼影"等问题,严重影响观看体验。
1.2 为什么简单的图像扩散堆叠行不通?
如果我们直接用图像扩散模型(如Stable Diffusion),每帧单独生成,然后拼接起来,会发生什么?
结果往往是:每一帧本身可能很漂亮,但整个视频会像"PPT"一样跳跃,人物在前后帧会"换脸",背景会"闪烁",完全没有连贯性。
这是因为图像扩散模型只学习了空间维度上的特征,对时间维度一无所知。它无法理解帧与帧之间的动态关系。
第二章:Video Latent的诞生:将视频压缩为"时空精华"
介绍视频潜在表示(Video Latent)的概念,以及如何通过VAE将高维视频数据压缩为低维的时空精华。

2.1 概念:视频潜在表示------时间与空间的融合
就像图像被压缩为C, H_latent, W_latent的潜在表示一样,视频也被压缩为一种**"时空潜在表示"(Video Latent)**。
它的形状通常是B, C_latent, F_latent, H_latent, W_latent。
B: Batch Size
C_latent: 潜在空间的通道数(通常比原始视频通道多)。
F_latent: 潜在空间中的"时间长度"(例如原始视频帧数F的1/4或1/8)。
H_latent, W_latent: 潜在空间中的"空间分辨率"(例如原始H, W的1/8或1/16)。
Video Latent是视频的"高维精缩版",它同时编码了视频的空间信息和时间信息,是视频扩散模型进行去噪的核心工作区域。
2.2 VAE的"时空压缩机":如何将视频编码为Latent?
就像我们用VAE Encoder将图像编码到潜在空间一样,视频扩散模型会使用一个**专门的"视频VAE"(Video VAE)**来处理视频。
这个Video VAE的Encoder能够理解并压缩视频的3D信息(时间、高度、宽度),将其高效地编码成Video Latent。
优势:在低维的Video Latent上进行扩散去噪,比在原始高维像素视频上操作,计算成本大幅降低。
第三章:Video Latent的扩散结构:时空U-Net的"双重魔法"
深入视频扩散模型的核心------"时空U-Net",理解它如何同时处理空间和时间维度,并提供其代码骨架。
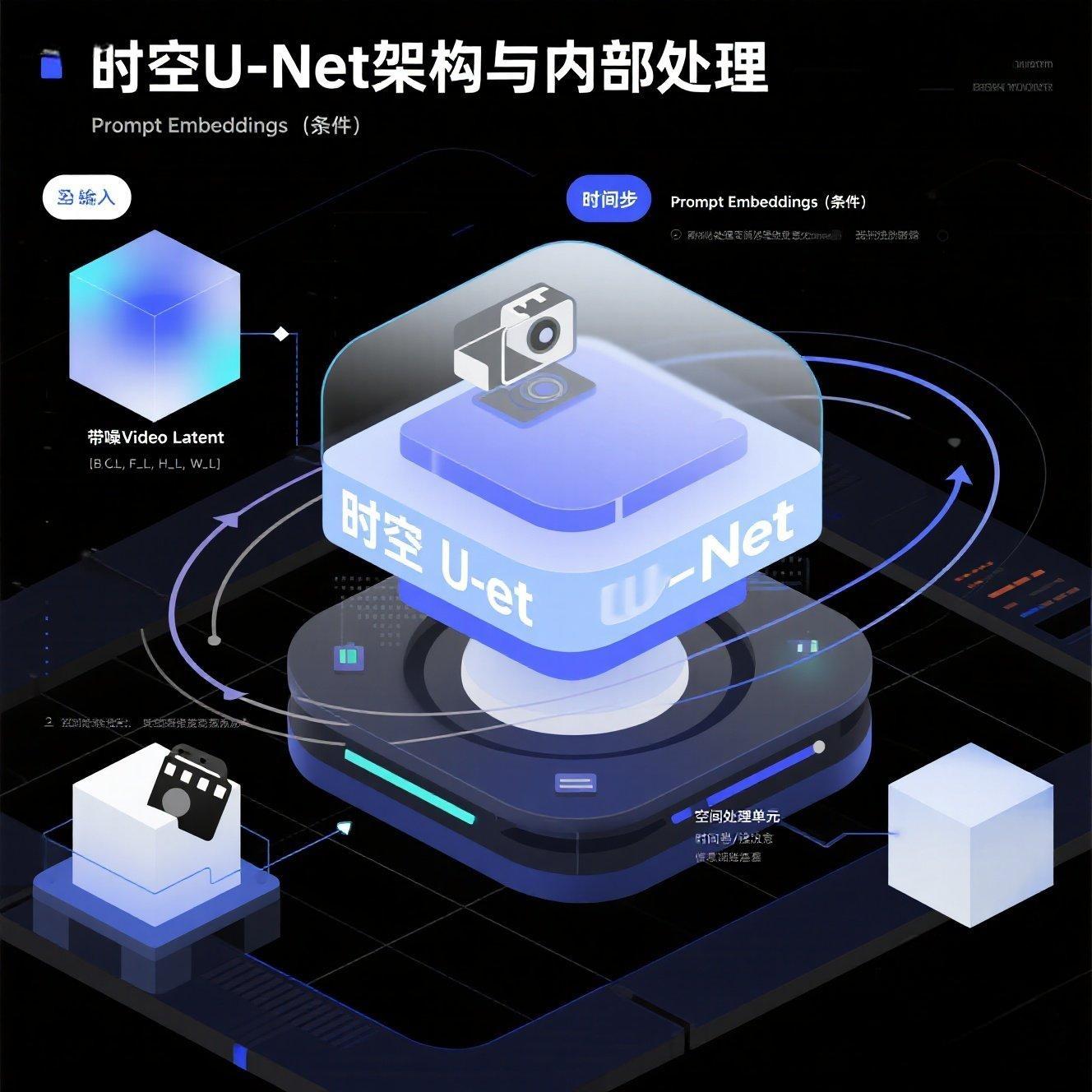
3.1 U-Net的"时空魔改":同时理解空间与时间
视频扩散模型的核心是时空U-Net(Spacetime U-Net)。它是在标准U-Net的基础上,为每一层注入了处理时间维度的能力。
这种U-Net的核心设计理念是:交替或并行地处理空间信息和时间信息。
3.2 空间注意力层与时间注意力层:AI的"多维视角"
时空U-Net的每个块中,通常会包含两种注意力层或卷积层:
空间注意力层/卷积层:和图像U-Net一样,处理单帧内部的像素关系。它负责"画好每一张图片"。
时间注意力层/卷积层:专门处理跨帧的关系。它让模型在预测某一帧的噪声时,能够"看"到前一帧、后一帧,甚至更远帧的信息,从而保证视频的连贯性。
3.3 简化的视频U-Net Block实现
目标:实现一个简化的VideoUNetBlock,它能接收Video Latent,并同时包含空间卷积和时间卷积(或注意力)的逻辑。
前置:需要torch.nn。
dart
# video_unet_block_skeleton.py
import torch
import torch.nn as nn
import torch.nn.functional as F
class SpatioTemporalConvBlock(nn.Module):
"""
简化的时空卷积块,用于Video U-Net。
它包含一个空间卷积层和一个时间卷积层。
"""
def __init__(self, in_channels, out_channels, num_frames_per_batch, kernel_size=3, padding=1):
super().__init__()
self.num_frames_per_batch = num_frames_per_batch
# 空间卷积层 (处理 H, W 维度)
self.spatial_conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, padding=padding)
self.spatial_norm = nn.GroupNorm(32, out_channels)
self.spatial_act = nn.SiLU()
# 时间卷积层 (处理 F 维度)
# 注意: Conv3d的输入是 [B, C, D, H, W],这里D代表时间F
self.temporal_conv = nn.Conv3d(out_channels, out_channels,
kernel_size=(3, 1, 1), padding=(1, 0, 0)) # 只在时间维度上卷
self.temporal_norm = nn.GroupNorm(32, out_channels)
self.temporal_act = nn.SiLU()
def forward(self, x: torch.Tensor):
# x的输入形状: [B * F, C, H, W] (U-Net内部的展平特征图)
batch_size_flat, channels, height, width = x.shape
# 1. 空间卷积
spatial_out = self.spatial_act(self.spatial_norm(self.spatial_conv(x)))
# 形状依然是 [B * F, C, H, W]
# 2. 重塑为 [B, C, F, H, W] 适应时间卷积
# -1 对应原始 Batch Size,self.num_frames_per_batch 对应 F
x_reshaped_for_temporal = spatial_out.view(-1, self.num_frames_per_batch, channels, height, width)
x_reshaped_for_temporal = x_reshaped_for_temporal.permute(0, 2, 1, 3, 4) # [B, C, F, H, W]
# 3. 时间卷积
temporal_out = self.temporal_act(self.temporal_norm(self.temporal_conv(x_reshaped_for_temporal)))
# 形状: [B, C, F, H, W]
# 4. 恢复形状回 [B * F, C, H, W] 以便与U-Net的后续层兼容
out = temporal_out.permute(0, 2, 1, 3, 4).reshape(batch_size_flat, channels, height, width)
return out
# --- 简化的视频U-Net骨架 ---
class SimpleVideoUNet(nn.Module):
def __init__(self, in_channels=4, out_channels=4, features=[64, 128], num_frames=16):
super().__init__()
self.num_frames = num_frames
# 初始层
self.conv_in = SpatioTemporalConvBlock(in_channels, features[0], num_frames)
# 下采样层
self.down1 = SpatioTemporalConvBlock(features[0], features[1], num_frames)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
# 瓶颈层 (U型底部)
self.bottleneck = SpatioTemporalConvBlock(features[1], features[1], num_frames)
# 上采样层 (这里简化,没有跳跃连接)
self.up1 = SpatioTemporalConvBlock(features[1], features[0], num_frames)
self.upsample1 = nn.Upsample(scale_factor=2, mode='nearest') # 上采样操作
# 最终输出层
self.conv_out = nn.Conv2d(features[0], out_channels, kernel_size=1)
def forward(self, x):
# x的形状: [B * F, C, H, W] (原始输入视频的展平特征)
# 例如: [2*16, 4, 64, 64] -> [32, 4, 64, 64]
# 初始处理
x = self.conv_in(x) # 形状: [B * F, features[0], H, W]
# 下采样
d1 = self.pool1(x) # 形状: [B * F, features[0], H/2, W/2]
d1 = self.down1(d1) # 形状: [B * F, features[1], H/2, W/2]
# 瓶颈
b = self.bottleneck(d1) # 形状: [B * F, features[1], H/2, W/2]
# 上采样 (这里简化,没有跳跃连接)
u1 = self.upsample1(b) # 形状: [B * F, features[1], H, W]
u1 = self.up1(u1) # 形状: [B * F, features[0], H, W]
# 最终输出
out = self.conv_out(u1) # 形状: [B * F, out_channels, H, W]
return out
# --- 测试 简化的Video U-Net骨架 ---
if __name__ == '__main__':
print("--- 测试 SimpleVideoUNet ---")
batch_size = 2
num_frames = 16
in_channels = 4 # 模拟潜在空间的通道数
out_channels = 4 # 模拟预测噪声的通道数
H, W = 64, 64 # 潜在空间分辨率
# 模拟Video Latent输入 (Batch个视频序列,每个序列有F帧)
# 形状: [B * F, C, H, W]
dummy_video_latent_flat = torch.randn(batch_size * num_frames, in_channels, H, W)
video_unet = SimpleVideoUNet(in_channels, out_channels, features=[32, 64], num_frames=num_frames)
output_noise_pred = video_unet(dummy_video_latent_flat)
print(f"输入Video Latent形状: {dummy_video_latent_flat.shape}")
print(f"Video U-Net骨架输出形状: {output_noise_pred.shape}")
assert output_noise_pred.shape == dummy_video_latent_flat.shape, "输入输出形状应一致!"
print("\n✅ 简化版Video U-Net骨架验证通过!")【代码解读】
这个SimpleVideoUNet骨架展示了视频U-Net如何通过SpatioTemporalConvBlock同时处理空间和时间信息:
SpatioTemporalConvBlock:这个自定义块内部先进行Conv2d(空间卷积),然后将数据view和permute成B, C, F, H, W形状,再进行Conv3d(时间卷积),最后permute和reshape回B\*F, C, H, W。这是处理时空数据的核心策略。
SimpleVideoUNet:将这些时空卷积块堆叠起来,形成一个U-Net结构。虽然这里为了简化没有实现跳跃连接,但它的输入输出形状一致性,证明了其作为视频去噪核心网络的潜力。
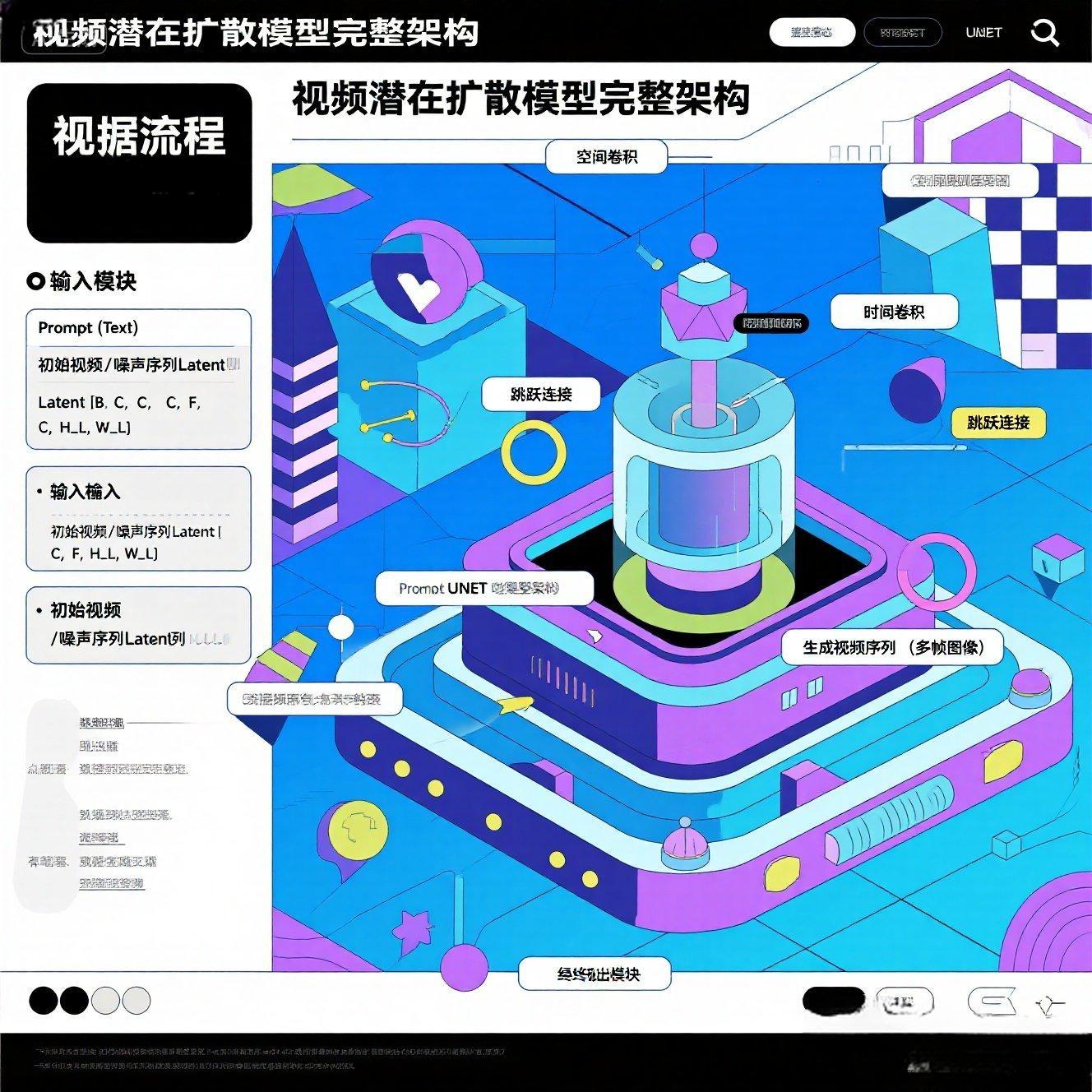
第四章:文生视频的完整工作流:从Prompt到动态视觉
宏观描述视频扩散模型从文本Prompt到生成视频的完整流程,整合前面所有组件的作用。
4.1 数据输入:Prompt与多帧噪声Latent
Prompt:用户输入的文本描述("一只可爱的狗在公园里奔跑")。
多帧噪声Latent:生成一个形状为B, C_latent, F_latent, H_latent, W_latent的随机噪声张量作为生成过程的"初始画布"。
4.2 核心循环:时空U-Net的去噪舞蹈
Prompt编码:Prompt被CLIP Text Encoder编码为prompt_embeds。
Video VAE编码:如果从图片开始生成视频,起始图片会被Video VAE编码为Video Latent。
迭代去噪循环:
-
在每个时间步t,时空U-Net接收当前的带噪Video Latent、时间步t和prompt_embeds。
-
时空U-Net内部的时间卷积层和注意力层会处理Video Latent的时间和空间维度,预测出噪声。
-
调度器根据预测的噪声,计算下一个更干净的Video Latent序列。
【CFG】:与图像扩散类似,视频扩散模型也使用CFG来平衡Prompt的贴合度与生成的多样性。
4.3 最终解码:VAE Decoder的"电影还原术"
去噪完成后,干净的Video Latent序列被送入Video VAE Decoder,逐帧解码成最终的像素视频帧。
Video Latent扩散模型的完整架构
帧率、分辨率与视频时长:视频生成中的"魔法刻度"
探讨视频生成中的关键参数,以及它们对生成结果的影响。
在视频生成中,除了常见的Prompt和引导强度,还有一些独特的参数:
帧率 (FPS):每秒生成的帧数。更高的FPS意味着更流畅的视频,但数据量更大。
分辨率 (Resolution):每帧图像的像素尺寸(如1024x576)。
视频时长 (Duration/Length):总共生成的帧数。这是视频生成最难控制的维度,因为它直接关系到时空连贯性。
这些参数共同决定了Video Latent的最终形状和处理复杂性。模型需要学会如何理解并生成不同这些参数组合的视频。
总结与展望:AI视频生成,理解动态世界的新范式
总结与展望:AI视频生成,理解动态世界的新范式
恭喜你!今天你已经深入解剖了文生视频的核心------Video Latent扩散结构。
✨ 本章惊喜概括 ✨
| 你掌握了什么? | 对应的核心概念/技术 |
|---|---|
| 文生视频的核心挑战 | ✅ 时间维度的一致性地狱 |
| Video Latent的概念 | ✅ 视频的"时空精华"表示 |
| 时空U-Net架构 | ✅ 空间与时间注意力/卷积层的协同 |
| 实现时空卷积骨架 | ✅ 亲手编写了SpatioTemporalConvBlock代码 |
| 文生视频完整工作流 | ✅ 从Prompt到动态视频的全流程 |
| 关键参数 | ✅ 帧率、分辨率与视频时长的影响 |
| 你现在不仅理解了扩散模型是如何一步步去噪的,更深刻地理解了视频扩散模型如何同时处理时间与空间,从而生成连贯的动态世界。这标志着AI在理解和生成动态场景方面迈出了重要一步。 |