Python抖音关键词视频爬取实战:批量下载与分析热门视频数据
无需复杂API,轻松获取抖音视频数据!本文将教你如何用Python实现关键词搜索、视频下载与数据分析的一站式解决方案。
功能亮点
- ✅ 关键词搜索抖音热门视频
- ✅ 自动批量下载高清无水印视频
- ✅ 采集用户信息与视频互动数据
- ✅ 数据导出为Excel表格
- ✅ 智能分页爬取与错误处理
环境准备
安装所需库:
bash
pip install DrissionPage pandas requests核心代码解析
1. 初始化设置与浏览器配置
python
# 创建视频保存目录
video_dir = f"../douyin_videos/{keyword}"
if not os.path.exists(video_dir):
os.makedirs(video_dir)
# 配置Chrome浏览器路径
path = r'C:\Program Files (x86)\Google\Chrome\Application\Chrome.exe'
co = ChromiumOptions().set_browser_path(path)
driver = ChromiumPage(co)2. 视频下载功能
python
def save_video(video_url, aweme_id):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36...',
'Referer': 'https://www.douyin.com/'
}
response = requests.get(video_url, headers=headers, stream=True, timeout=30)
if response.status_code == 200:
video_path = os.path.join(video_dir, f'{aweme_id}.mp4')
with open(video_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=1024*1024):
if chunk:
f.write(chunk)
return True
except Exception as e:
print(f"下载视频时出错: {str(e)}")
return False3. 数据解析与处理
python
def save_video_info(video_data):
# 提取关键数据
minutes = video_data['video']['duration'] // 1000 // 60
seconds = video_data['video']['duration'] // 1000 % 60
# 获取无水印视频地址
video_url = video_data['video']['play_addr']['url_list'][0].replace('playwm', 'play')
# 构建数据字典
video_dict = {
'用户名': video_data['author']['nickname'].strip(),
'用户uid': 'a' + str(video_data['author']['uid']),
'粉丝数量': video_data['author']['follower_count'],
'视频描述': video_data['desc'].strip().replace('\n', ''),
'点赞数量': video_data['statistics']['digg_count'],
# 更多字段...
}
# 下载视频
save_video(video_url, video_dict['视频awemeid'])
return video_dict4. 主爬虫流程
python
# 监听抖音数据接口
driver.listen.start('www.douyin.com/aweme/v1/web/search/item', method='GET')
# 访问搜索页面
url = f'https://www.douyin.com/search/{keyword}?type=video'
driver.get(url)
# 分页爬取
data_list = []
for page in range(10):
driver.scroll.to_bottom()
resp = driver.listen.wait()
json_data = resp.response.body
for json_aweme_info in json_data['data']:
data = save_video_info(json_aweme_info['aweme_info'])
data_list.append(data)
if not json_data['has_more']:
break数据展示效果
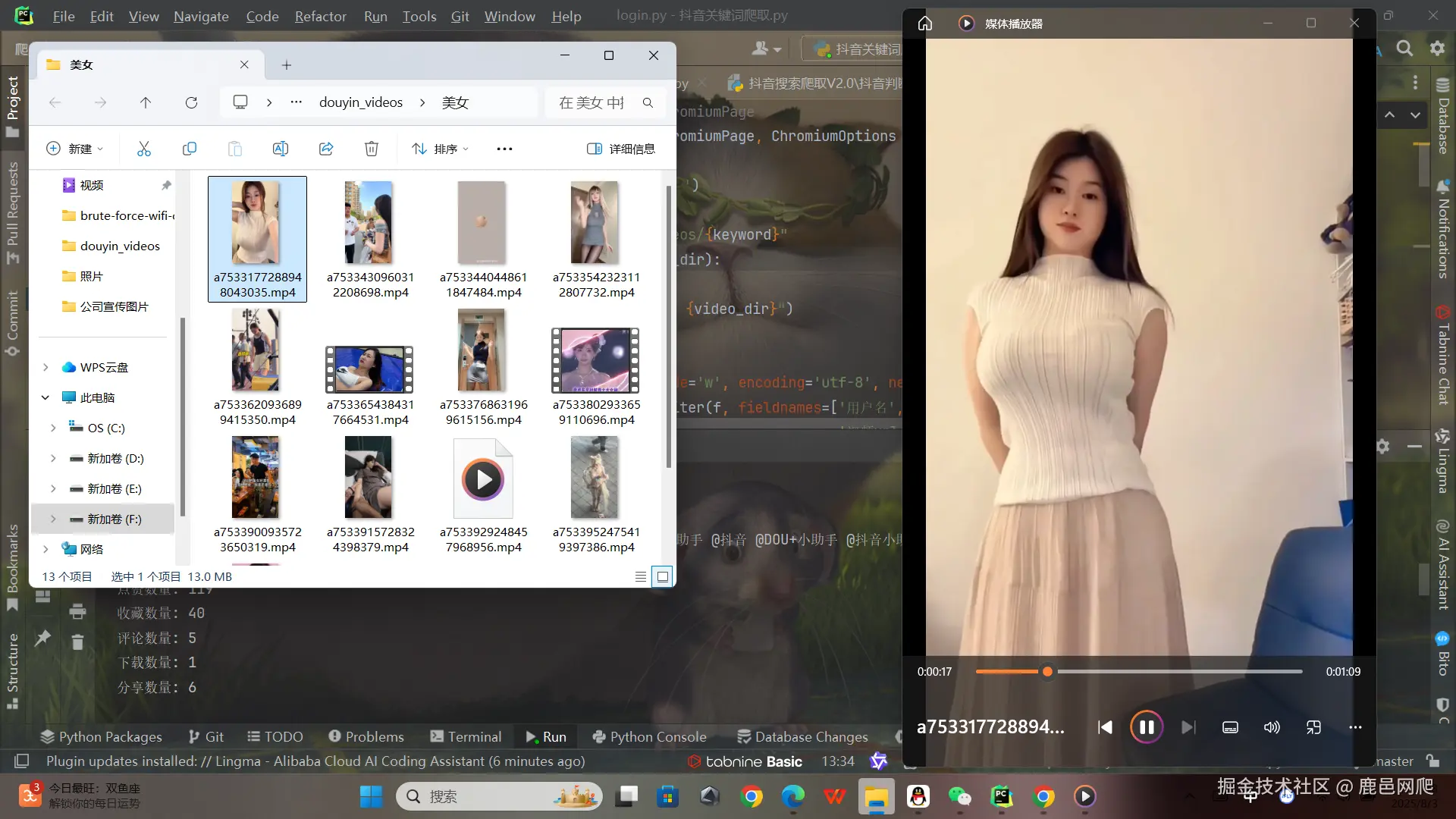
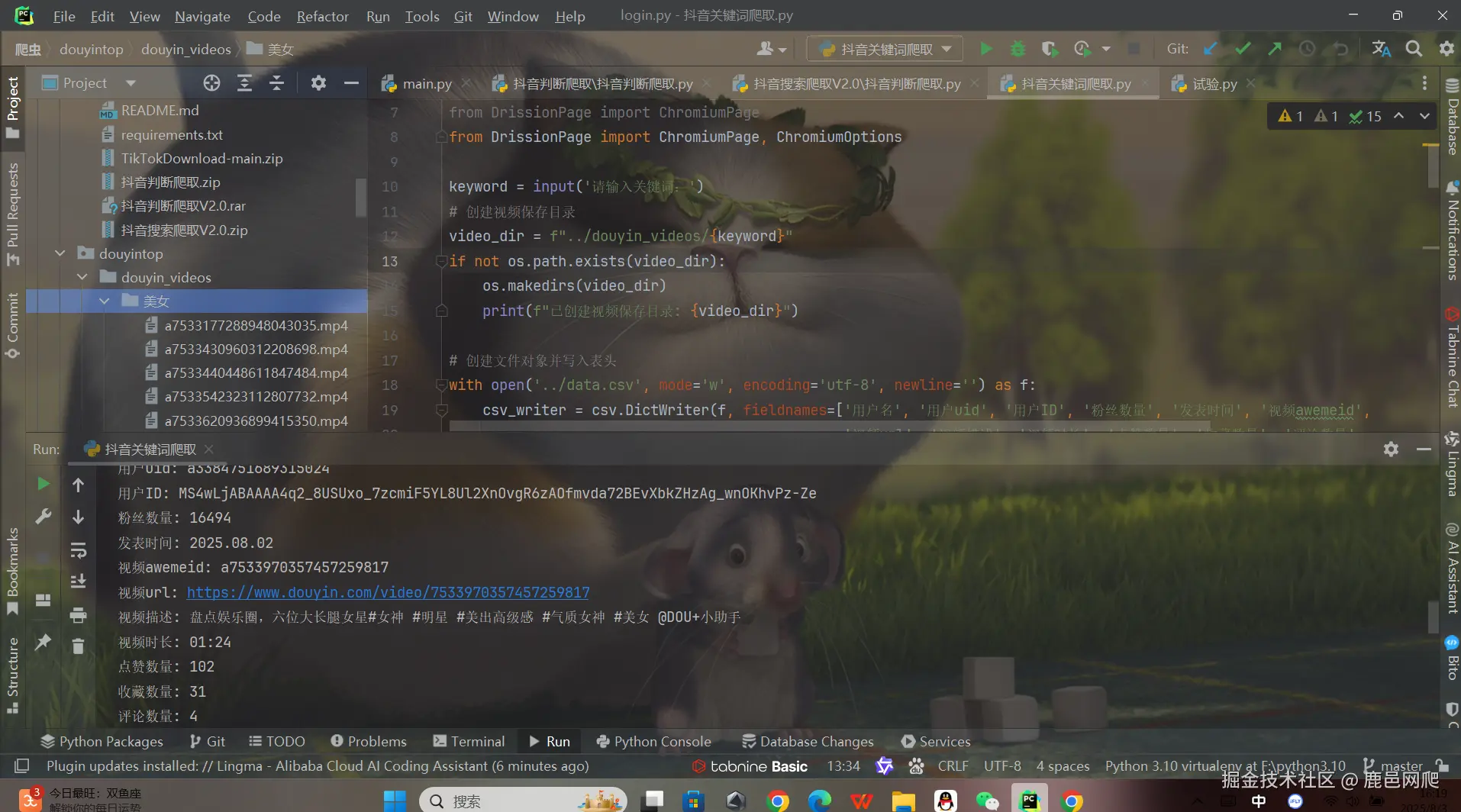

常见问题解决
-
浏览器路径错误
python# 修改为你的Chrome安装路径 path = r'你的Chrome路径' -
视频下载失败
- 检查网络连接
- 更新请求头User-Agent
- 添加代理IP
-
反爬虫限制
- 降低爬取频率
- 随机化操作间隔
- 使用IP代理池
完整代码获取
为保护平台规则,本文仅展示核心代码片段
👉 关注公众号【Python数据分析】回复"抖音爬虫"获取完整可运行代码 👈
应用场景
- 竞品分析:监控行业相关视频动态
- 热点追踪:实时捕捉热门话题
- 达人筛选:寻找优质内容创作者
- 内容研究:分析爆款视频特征
注意事项
- 本工具仅用于学习交流
- 合理控制爬取频率
- 尊重版权与用户隐私
- 遵守抖音平台使用条款
技术交流群已开放!扫码加入获取更多爬虫技巧和源码分享 ↓↓↓
完整代码已打包(含示例图片),👉点击关注+私信"爬虫"获取👈 更多爬虫实战技巧+ :an1544167879持续更新中!
原创不易,转载请注明出处!更多实用Python技巧欢迎访问我的博客:鹿邑网爬-CSDN博客
⚠️声明:本教程仅供技术交流,请勿用于非法用途!