很多初级甚至中级开发会滥用atomic,因为在他们的世界观里atomic比mutex轻量,性能总是优于锁的。
这话不能算错,但有个很重要的前提,那就是原子操作竞争不激烈的时候。
"竞争激烈"是指什么呢,指的是有很多线程在同一个资源上大量执行原子操作的情况。
落在这种情况下原子操作反而会成为性能拖油瓶。我们来看一个经典的原子计数器:
golang
func AddAtomic() uint64 {
var count atomic.Uint64
var wg sync.WaitGroup
for range 10 {
wg.Add(1)
go func() {
for range 100000000 {
count.Add(1)
}
wg.Done()
}()
}
wg.Wait()
return count.Load()
}代码模拟了10个线程频繁操作计数器的场景。论并发安全这段代码是既简洁又安全的。很多人可能还会觉得这段代码是很高效的,毕竟用了原子操作嘛。
不过别着急,测试性能之前我们再想想还有没有其他做法。考虑到这是一个单向递增的计数器,我们只需要保证每次的加操作最终都能完成,并且因为加法的交换律和结合律,这些操作的相对顺序也可以打乱。换句话说,我们可以不关心counter的中间状态,每个线程自己聚合所有的加操作,最后再一次性加给counter。代码就会变成下面这样:
golang
func AddAtomicLocal() uint64 {
var count atomic.Uint64
var wg sync.WaitGroup
for range 10 {
wg.Add(1)
go func() {
cc := uint64(0)
for range 100000000 {
cc++
}
count.Add(cc)
wg.Done()
}()
}
wg.Wait()
return count.Load()
}现在每个线程维护自己的计数器,在运行结束统一操作counter。熟悉Java的读者应该能看出来这是LongAdder,唯一的区别是我们没用threadlocal。
两种方法累加的次数都是一样的,而且大部分人都认为原子操作很轻量,那么它们的性能理论上应该不会差太多,方法1稍微慢一点。我们写点性能测试看下:
golang
func BenchmarkAtomic(b *testing.B) {
for b.Loop() {
result := AddAtomic()
if result != 1000000000 {
b.Fatal("error")
}
}
}
func BenchmarkAtomicLocal(b *testing.B) {
for b.Loop() {
result := AddAtomicLocal()
if result != 1000000000 {
b.Fatal("error")
}
}
}下面是测试结果,分别用go1.24.5在Intel和Apple的机器上进行测试:
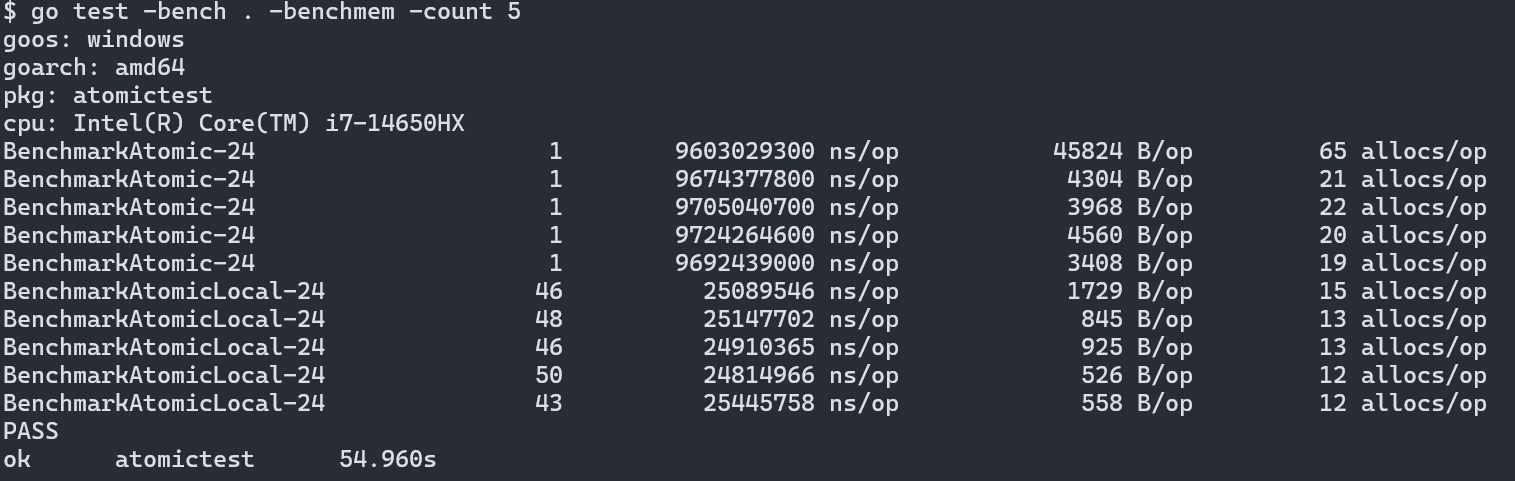
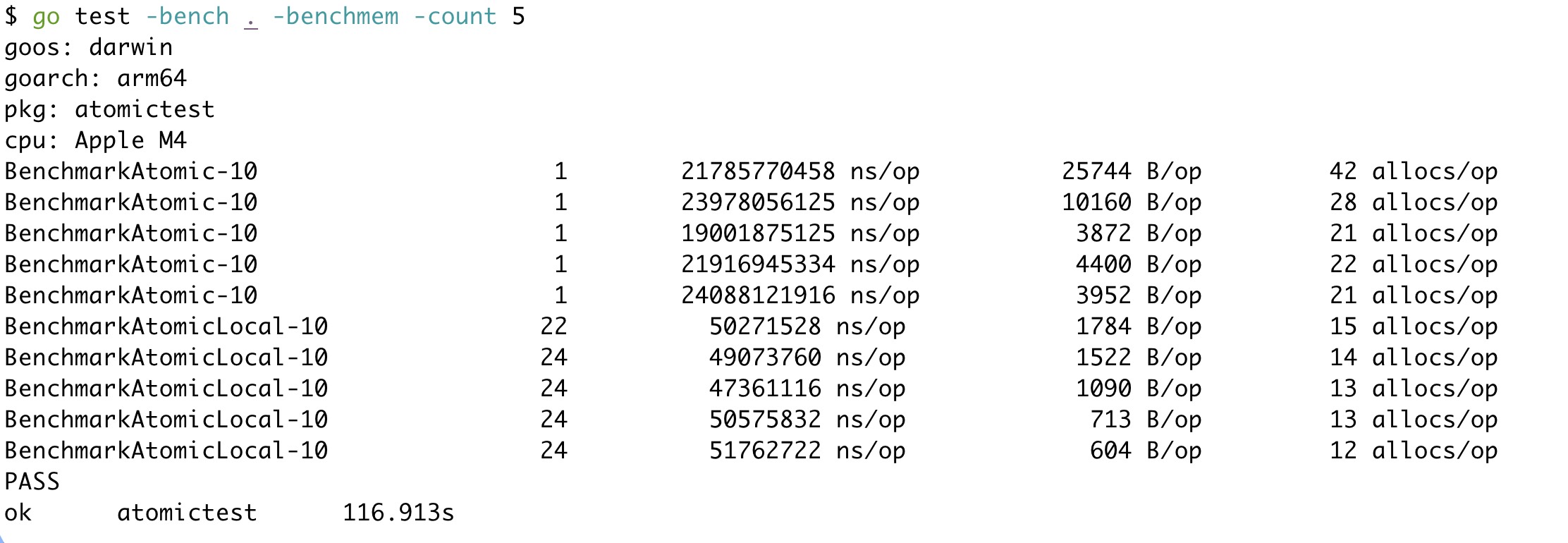
结果出人意料,在两款不同的芯片上,方案1都慢了接近300倍。看似"轻量"的原子操作竟然是性能杀手。
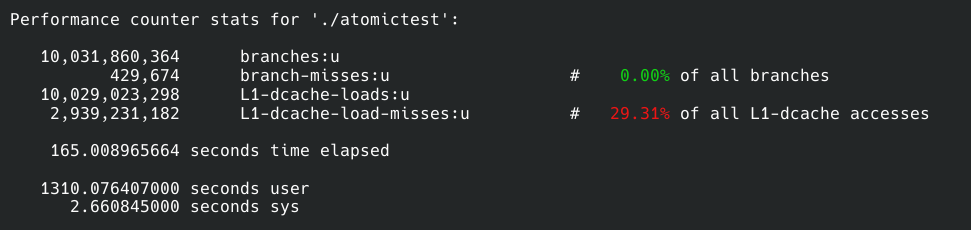
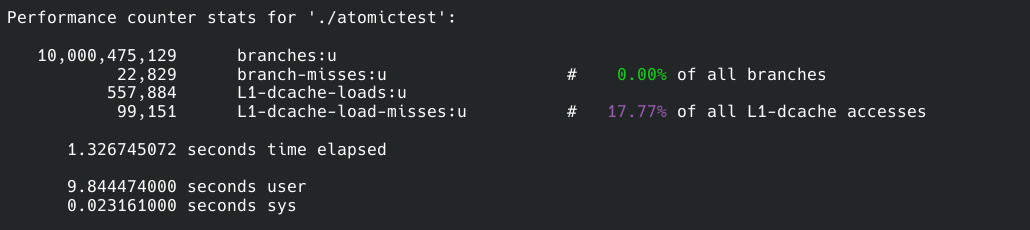
我们可以找个Linux系统用perf分析一下原因。在Linux上两者直接也有百倍的差距。
上面一个样本是方案1的,下面的则是方案2的:
我没有监听全部的性能事件,那样一来会让程序变得很慢,二来对我们重要的只有其中的几个事件,太多的信息会成为杂音。
我们先来看branches和branch-misses,前者是程序运行中一个执行多少分支判断,后者是cpu预执行分支失败的次数,简单地说misses越少程序性能越高。所以两个方案在分支总数差不多的情况下方案2比1的预测失败数量低20倍,所以方案2在这一点上胜出。
接着就是缓存命中率了,这一点无需过多解释,命中率越高性能越好。方案二同样比一高了10%。
然而这两点只能解释一个数量级的差异,但我们现在的差距是300倍。
仔细观察缓存读取次数,我们会惊奇地发现方案1的读取次数是10,029,023,298,100亿次。我们的测试程序也正好运行了累加器函数10次,也是100亿次操作。这是方案2的整整18000倍。
为什么会有这个结果呢?这就是原子操作的缺点之一了:x86和arm上的原子操作都是针对某块内存上的数据进行操作。这意味着不管是原子读还是原子写,都要直接操作内存。现代cpu不会自己直接接触内存,都需要数据先进入cpu的高速缓存才能进行操作。这就是为什么方案1会有如此之高的缓存读取次数。原子操作需要这样的代价,因为共享的资源随时会被修改,因此只能每次从内存中存取最新的数据。
而方案2的累加操作是在线程独立的本地局部变量上进行的,这些操作没必要走内存,可以直接在寄存器上完成。
寄存器和高速缓存的速度差异不同体系结构和厂家的产品大相径庭,但寄存器的速度一定大于等于高速缓存。因此更依赖寄存器的方案2自然会比缓存命中率更低且需要大量操作缓存的方案1快上两个数量级。
除此之外原子操作还带来了另外的副作用,这在perf的报告中没有显现------多个线程频繁修改同一个资源,会带来大量的更新cpu缓存的核间通信以及线程为了原子性可能会出现很多同步操作。核间通信本身有延迟,缓存状态更新后cpu遇到下次的原子读取/写入就得先更新缓存才能执行操作,一来一去慢的可不是一星半点。线程之间的同步则来自于原子操作带来的内存屏障,cpu为了保证能让屏障正常生效,需要让一些cpu核心上的指令等待另一些核心上的指令执行完成,不同的cpu实现这点的方法不同,但也会带来可观的延迟。
所以综合上面三个原因,看似轻量级的原子操作在"竞争激烈"的场景下出现了严重的性能问题。
不过尽管方案2很快,但它也有缺点,那就是counter不会及时更新。在这里我们可以忍受这一点,但也有的场景是无法接受这种延迟的。
总结
atomic不是免费午餐,是要支付使用代价的。除了潜在的性能问题,还会有难以察觉的并发问题。
所以为了追求性能,应该停止滥用atomic。可以适当地像方案2或者Java的LongAdder那样选择一些per-cpu的算法或者数据结构。