用 Flux + Langchain4j 构建一个可恢复的流式响应系统。
使用到的技术栈:SpringBoot、Langchain、Elasticsearch
Langchain现在被广泛用于实现AI Agent,而流式响应是大模型主流的交互方式。在生产环境中,网络环境复杂,可能出现模型响应慢等情况。于是为了优化用户体验,解决断流问题,我通过实践构建了一个可恢复的流式响应系统,支持断线后自动重连。起因是作者接到了一个与智慧校园、信息查询有关的AI Agent后端需求,所以将实践过程分享给大家。
Langchain4j 介绍
Langchain 大家应该都耳熟能详了,它是一个能够将 LLM 集成到 Java 应用程序的框架。我的使用的后端框架是 SpringBoot,由于 Spring AI 更新速度较慢,跟不上 Langchain4j 的版本,所以我没有使用 SpringAI,而是直接在Maven中引入了 langchain4j。
Langchain4j 集成了15+个 LLM 提供商,集成了向量储存、图像生成、评分模型等,支持多模态、消息持久化、流式传输、Tool calling,还有 RAG(增强检索)功能。这次主要使用到的是它的 Tool calling 与流式传输。
Langchain4j 的基本使用
首先简要介绍一下我是如何在 SpringBoot 中使用 Langchain4j的:
- 为大模型提供可调用的 tool(工具)
java
@Component
public class LLMTools {
@Tool("Tool Description")
public String function() {
// Do something...
}
}这样就创建了一个包含工具的 Bean,其中注解里可以写上工具的介绍,但方法名也是包括在上下文中的。返回值可以是String类型,其它类型的返回值会在发送给 LLM 之前转换为 JSON 字符串。而方法参数类型可以有很多选择:
- 基本类型:int、double 等
- 对象类型:String、Integer、Double 等
- 自定义 POJO(可以包含嵌套 POJO)
- enum(枚举)
- List<T>/Set<T>,其中 T 是上述类型之一
- Map<K,V>(需要使用 @P 描述 K 和 V 的类型)
举一个例子,如果我想让大模型可以获得我的 Elasticsearch 中的所有索引,我应该怎么写?
java
@Tool("Get field mappings for a specific Elasticsearch index")
public String getMapping(@P("Name of the Elasticsearch index to get mappings for") String index) throws IOException {
GetMappingResponse response = esClient.indices().getMapping(r -> r.index(index));
ObjectNode node = objectMapper.createObjectNode();
ArrayNode content = node.putArray("content");
ObjectNode n1 = objectMapper.createObjectNode();
n1.put("type", "text");
n1.put("text", "Mappings for index: " + index);
content.add(n1);
ObjectNode n2 = objectMapper.createObjectNode();
n2.put("type", "text");
n2.put("text", "Mappings for index " + index + ": " + response.toString());
content.add(n2);
return objectMapper.writeValueAsString(node);
}其中 esClient 是 Elasticsearch 官方 sdk 提供的类。
- 定义一个 Agent
java
interface Agent {
TokenStream ask(@UserMessage String question);
}其中 question 是用户发送的字符串。
接着,为你的 agent 写一个提示词,有了大模型的api key,就可以注册一个 Agent 了:
java
String prompt = "提示词";
StreamingChatLanguageModel model = OpenAiOfficialStreamingChatModel.builder()
.baseUrl("https://api.deepseek.com")
.apiKey("your key here")
.modelName("deepseek-chat")
.build();
Agent agent = AiServices.builder(Agent.class)
.streamingChatLanguageModel(model)
.tools(llmTools)
.systemMessageProvider(s -> prompt)
.build();- 暴露一个接口来对话
考虑到场景需要,在这里使用了 SSE 来流式传输大模型的回答。实际上也可以用 WebSocket 实现。
java
public SseEmitter chat(String message) {
TokenStream tokenStream = agent.ask(memoryId, message);
SseEmitter sseEmitter = new SseEmitter(0L);
tokenStream.onPartialResponse(s -> {
sseEmitter.send(s);
});
return sseEmitter;
}这样,就实现了一个最基本的拥有 tool calling 和对话功能的 AI Agent。
单机中断恢复
直接上分布式的方案过于复杂,单体架构对于并发量不高的需求也足够使用,所以首先介绍单机中断恢复的方案。
首先,不管是用户主动还是被动断开连接,对于 LLM 侧,处理的方法有几种:
- 继续保持 LLM 连接,直到输出结束
- 直接断开LLM 连接
对于断开连接后是否需要保存已经输出的内容,这就根据需求而决定了,实现起来难度也不大,不过似乎 langchain4j 也没有提供主动断开连接的方法。
那么如何在用户中断后恢复连接呢?首先可以想到的是,后端与 LLM 的连接和后端与用户的连接是两个不同的连接,用户与后端连接中断并不影响后端与 LLM 的连接,所以方案是可行的。接下来就是思考如何重连。前端尝试与后端建立连接时有两种可能的状态:
- LLM 正在回复前一条信息
- 没有正在回复的信息
对于第二种情况很好处理,只要做了消息记录,那么不管有没有中断,消息结束后都会被持久化。而对于第一种情况,则需要考虑一些特殊的处理办法。目前我经过尝试后可行的思路如下:
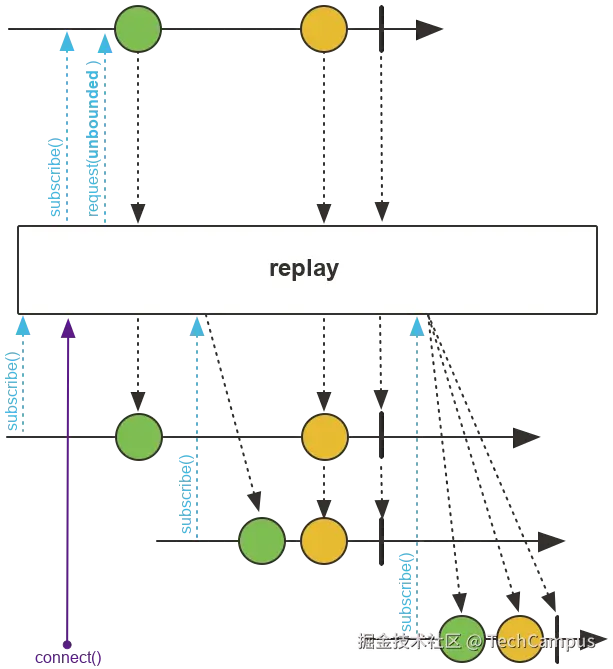
封装一个ResumableSseEmitter,其中包含了一个可以推送事件的 Flux,并通过 AtomicReference 持有 sink,用于主动推送事件。注意 Flux 创建时调用了 replay(),表示这个 Flux 在连接时会将已传输的数据重新传输一遍。subscribe() 方法返回一个SseEmitter,通过订阅 Flux 来为 SseEmitter 传输数据。构造函数有一个 onComplete 回调,用于在传输完毕时修改状态。
java
public class ResumableSseEmitter {
@Getter
private final AtomicReference<FluxSink<SseEmitter.SseEventBuilder>> sink = new AtomicReference<>();
private final Flux<SseEmitter.SseEventBuilder> flux = Flux.create(sink::set).replay().autoConnect();
public ResumableSseEmitter(TokenStream tokenStream, Runnable onComplete) {
tokenStream.onPartialResponse(s -> {
sink.get().next(new SseEventBuilderImpl().data(s));
});
tokenStream.onCompleteResponse(c -> {
sink.get().complete();
onComplete.run();
});
tokenStream.onError(throwable -> {
sink.get().next(new SseEventBuilderImpl().name("error").data("发生了错误,请稍后再试"));
// sink.get().error(throwable);
sink.get().complete();
onComplete.run();
});
tokenStream.start();
}
public SseEmitter subscribe() {
SseEmitter sseEmitter = new SseEmitter(0L);
flux.subscribe(s -> {
try {
sseEmitter.send(s);
} catch (Exception e) {
throw new RuntimeException(e);
}
}, sseEmitter::completeWithError, sseEmitter::complete);
return sseEmitter;
}
}这样,就可以使用一个 Map 来储存 ResumableSseEmitter,实现一个 resume() 接口,用于续传数据:
java
public static final Map<String, ResumableSseEmitter> EMITTER_MAP = new ConcurrentHashMap<>();
public SseEmitter resume() {
String memoryId = //...
ResumableSseEmitter emitter = EMITTER_MAP.get(memoryId);
if (emitter == null) {
throw new BusinessException(ErrorEnum.NO_CHAT_RUNNING);
}
return emitter.subscribe();
}当然,每个用户还需要有唯一标识来区分。
这种方案最好配套持久化消息记录使用,这里使用 Redis 举例,大家可以自己实现 langchain4j 提供的 ChatMemoryStore接口:
java
@Component
public class RedisChatMemoryStore implements ChatMemoryStore {
@Resource
private RedisCache redisCache;
private final ObjectMapper objectMapper;
public RedisChatMemoryStore() {
this.objectMapper = new ObjectMapper();
SimpleModule module = new SimpleModule();
module.addSerializer(ChatMessage.class, new ChatMessageSerializer());
module.addDeserializer(ChatMessage.class, new ChatMessageDeserializer());
objectMapper.registerModule(module);
}
@SneakyThrows
@Override
public List<ChatMessage> getMessages(Object memoryId) {
String json = redisCache.get("chat:message:" + memoryId, String.class);
if (json == null) {
return new ArrayList<>();
}
List<ChatMessage> messages = objectMapper.readValue(json, new TypeReference<>() {
});
if (messages == null) {
return new ArrayList<>();
}
return messages;
}
@SneakyThrows
@Override
public void updateMessages(Object memoryId, List<ChatMessage> messages) {
String json = objectMapper.writeValueAsString(messages);
redisCache.set("chat:message:" + memoryId, json, 7, TimeUnit.DAYS);
}
@Override
public void deleteMessages(Object memoryId) {
redisCache.remove("chat:message:" + memoryId);
}
private static class ChatMessageSerializer extends JsonSerializer<ChatMessage> {
@Override
public void serialize(ChatMessage chatMessage, JsonGenerator jsonGenerator, SerializerProvider serializerProvider) throws IOException {
jsonGenerator.writeStartObject();
if (chatMessage instanceof ToolExecutionResultMessage toolExecutionResultMessage) {
jsonGenerator.writeStringField("id", toolExecutionResultMessage.id());
jsonGenerator.writeStringField("toolName", toolExecutionResultMessage.toolName());
}
jsonGenerator.writeStringField("type", chatMessage.type().name());
jsonGenerator.writeStringField("text", chatMessage.text());
jsonGenerator.writeEndObject();
}
}
private static class ChatMessageDeserializer extends JsonDeserializer<ChatMessage> {
@Override
public ChatMessage deserialize(JsonParser jsonParser, DeserializationContext deserializationContext) throws IOException, JacksonException {
ObjectMapper objectMapper = (ObjectMapper) jsonParser.getCodec();
JsonNode node = objectMapper.readTree(jsonParser);
ChatMessageType type = ChatMessageType.valueOf(node.get("type").asText());
String text = node.get("text").asText();
return switch (type) {
case SYSTEM -> new SystemMessage(text);
case USER -> new UserMessage(text);
case AI -> new AiMessage(text);
case TOOL_EXECUTION_RESULT ->
new ToolExecutionResultMessage(node.get("id").asText(), node.get("toolName").asText(), text);
default -> throw new IllegalArgumentException("Unknown chat message type: " + type);
};
}
}
}然后,在构造 Agent 时,传入这个 ChatMemoryStore 就可以了。
java
this.agent = AiServices.builder(Agent.class)
.streamingChatLanguageModel(model)
.tools(elasticsearchTools)
// 传入 ChatMemoryProvider
.chatMemoryProvider(memoryId -> MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(10)
.chatMemoryStore(chatMemoryStore)
.build())
.systemMessageProvider(s -> prompt)
.build();分布式系统中断恢复
在生产环境中,部署在单节点上的服务往往存在单点风险,而分布式系统(例如 K8s 容器集群 + 网关负载均衡)可以实现更好的可用性和扩展性。但相应地,也带来了一些复杂性,尤其是在处理流式连接、状态一致性、用户重连等问题时。
与单机不同,分布式环境中用户请求可能会被负载均衡器随机分发到不同节点上,而每个节点的内存和状态又是独立的,这就带来了一个挑战:如何让任意节点都能接管和恢复一个"中断的流式会话"?
由此,我们可以提出我们的目标:
- 无状态服务设计:服务本身不保存对话状态,状态持久化到共享中间件。
- 幂等重连接口:支持用户在任意节点请求恢复流式对话。
- 全局唯一会话 ID:标识每一轮对话,用于索引状态与控制重连。
在多实例部署或微服务架构中,仅靠 Map 实现的 emitterRegistry 是无法满足分布式要求的。消息队列是解决跨节点推送 token 的核心组件,可以将 Langchain4j 生成的 token 数据广播至多个 Web 前端连接消费者,并实现了两条信息流的解耦。

- Langchain4j 节点推送 token 到 MQ
在 onPartialResponse(token -> {}) 中:
java
kafkaTemplate.send("chat-stream-" + memoryId, token);- SSE 节点消费 MQ 并转发给前端
java
@KafkaListener(topics = "chat-stream-${memoryId}", groupId = "sse-${memoryId}")
public void onTokenReceived(String token) {
emitterRegistry.push(memoryId, token); // 或直接 emitter.send(...)
}Kafka 也可以用其它例如 Redis Stream 等中间件代替。这样就实现了一套高可用的流式传输方案。
如果你看懂了这篇文章,不妨点个赞或者转发一下;如果还有疑问,也欢迎评论交流。