我是小瓶子,有我来完成带领大家进入ai的世界
我的主页如下:

主页:爱装代码的小瓶子
专栏 :1. 关于Linux的学习
希望大家都来学习哦!谢谢三联!

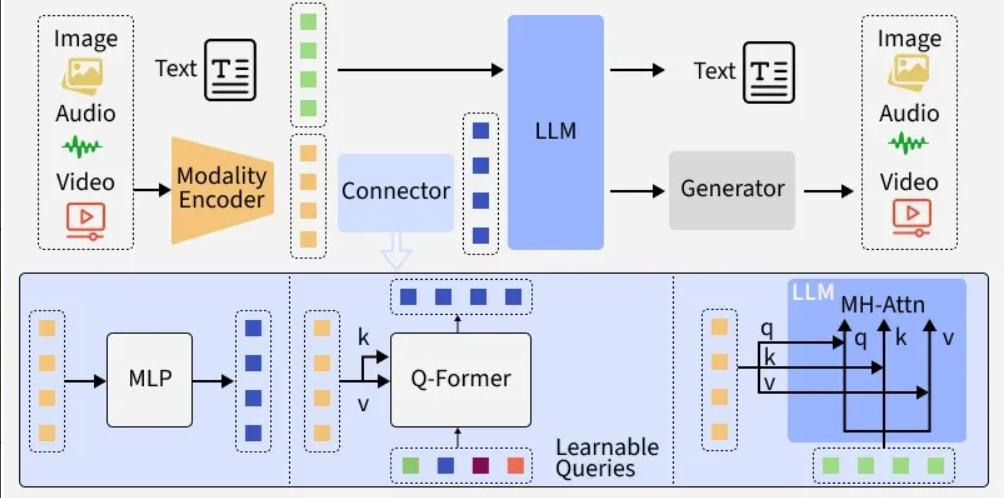
大模型基础架构
大语言模型的基础架构是其实现强大语言理解和生成能力的核心。目前主流的大语言模型大多基于Transformer架构,该架构通过自注意力机制能够有效捕捉文本中的长距离依赖关系。
Transformer架构主要由编码器(Encoder)和解码器(Decoder)组成。编码器负责将输入文本转换为上下文相关的向量表示,它包含多个堆叠的编码器层,每个编码器层又由多头自注意力机制和前馈神经网络组成。多头自注意力机制允许模型同时关注输入文本的不同位置,从而更好地理解文本的语义和语法结构。前馈神经网络则对注意力机制的输出进行进一步的处理和变换。
解码器的作用是根据编码器的输出和已生成的文本,生成后续的文本序列。解码器同样包含多个堆叠的解码器层,每个解码器层除了有多头自注意力机制和前馈神经网络外,还有一个编码器-解码器注意力机制,用于关注编码器输出的相关信息。
在模型训练过程中,通过大规模的文本数据对模型进行预训练,使模型学习到语言的规律和知识。预训练完成后,还可以通过微调(Fine-tuning)在特定任务数据集上进一步训练模型,以提高模型在特定任务上的性能。
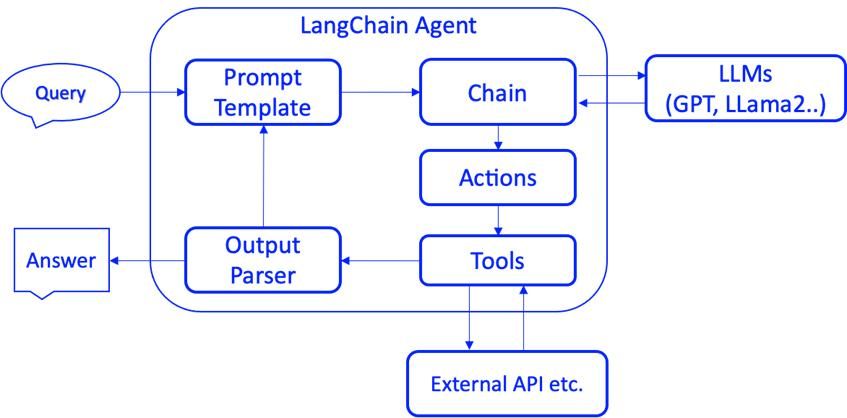
LangChain工作流程
LangChain是一个用于构建基于语言模型的应用程序的框架,它提供了一系列工具和组件,简化了将语言模型与其他数据源、API和工具集成的过程。LangChain的工作流程主要包括以下几个步骤:
- 数据加载:LangChain支持从多种数据源加载数据,如文本文件、PDF文档、数据库等。通过数据加载器,可以将外部数据引入到应用程序中,为语言模型提供更丰富的上下文信息。
- 文本分割:由于语言模型的输入长度通常有限,需要将加载的文本数据分割成较小的文本块。LangChain提供了多种文本分割策略,如按字符数、按句子或按段落分割。
- 嵌入生成:将分割后的文本块转换为向量表示(嵌入),以便于进行相似度计算和检索。LangChain支持多种嵌入模型,如OpenAI的Embeddings、Hugging Face的Embeddings等。
- 向量存储:将生成的文本嵌入存储到向量数据库中,以便快速检索与用户查询相关的文本片段。LangChain支持多种向量数据库,如Chroma、FAISS等。
- 检索增强生成(RAG):当用户提出查询时,LangChain从向量数据库中检索与查询相关的文本片段,并将这些文本片段与查询一起作为输入传递给语言模型,生成更准确、更相关的回答。
- 工具调用:LangChain允许语言模型调用外部工具和API,如计算器、搜索引擎、数据库查询等,以扩展模型的能力。通过工具调用,语言模型可以获取实时信息、执行复杂计算等。
直接调用API方法
直接调用大语言模型的API是使用模型能力的一种简单便捷的方式。不同的大语言模型提供商都提供了相应的API接口,开发者可以通过发送HTTP请求来调用这些接口。
以调用豆包API为例,首先需要在豆包开放平台注册账号,创建应用并获取API密钥。然后,根据API文档的要求,构造请求参数。一般来说,请求参数包括模型名称、输入文本、对话历史等。
以下是一个使用Python调用豆包API的示例代码:
python
import requests
api_key = "your_api_key"
url = "https://api.doubao.com/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
data = {
"model": "doubao-pro",
"messages": [
{"role": "system", "content": "你是一个 helpful 的助手。"},
{"role": "user", "content": "请介绍一下大语言模型的应用场景。"}
]
}
response = requests.post(url, headers=headers, json=data)
result = response.json()
print(result["choices"][0]["message"]["content"])在上述代码中,model指定了要使用的模型,messages包含了对话的历史信息,其中role为"system"的消息用于设置助手的行为和角色,"user"的消息是用户的输入。
不同的大语言模型API在请求参数和返回结果格式上可能会有所差异,在实际使用时需要参考相应的API文档。
主流LLM(豆包/DeepSeek/Qwen/智普)对比分析
目前市场上有许多主流的大语言模型,它们在性能、特点和应用场景等方面各有优势。以下对豆包、DeepSeek、Qwen(通义千问)和智普这几款主流LLM进行对比分析。
豆包
豆包是字节跳动开发的大语言模型,具有以下特点:
- 多轮对话能力强:能够理解用户的上下文意图,进行连贯的多轮对话。
- 知识覆盖广泛:涵盖了生活常识、科学知识、历史文化等多个领域。
- 生成内容自然流畅:生成的文本语言通顺,符合人类的表达习惯。
豆包适用于智能客服、聊天机器人、生活助手等场景,能够为用户提供便捷的信息咨询和服务。
DeepSeek
DeepSeek是深度求索公司开发的大语言模型,其优势主要体现在:
- 代码生成能力突出:支持多种编程语言,能够生成高质量的代码片段和函数。
- 数学推理能力强:可以解决复杂的数学问题,包括代数、几何、微积分等。
- 逻辑思维清晰:在进行推理和分析任务时,能够展现出较强的逻辑思维能力。
DeepSeek适合程序员辅助编程、数学教育、科研数据分析等场景。
Qwen(通义千问)
Qwen(通义千问)是阿里巴巴开发的大语言模型,具有以下特点:
- 电商领域知识丰富:在电商产品推荐、营销文案生成等方面有较好的表现。
- 金融知识专业:能够理解金融术语和金融市场动态,提供金融信息查询和分析服务。
- 多语言支持:支持多种语言的理解和生成,包括中文、英文、日文等。
Qwen适用于电商平台、金融机构、跨境业务等场景。
智普
智普是智谱AI开发的大语言模型,其特点包括:
- 文本生成富有创意:能够生成小说、诗歌、散文等富有文学性的文本。
- 情感分析准确:可以准确识别文本中的情感倾向,如积极、消极、中性等。
- 个性化服务能力:能够根据用户的偏好和需求,提供个性化的建议和服务。
智普适合文案创作、情感咨询、个性化推荐等场景。
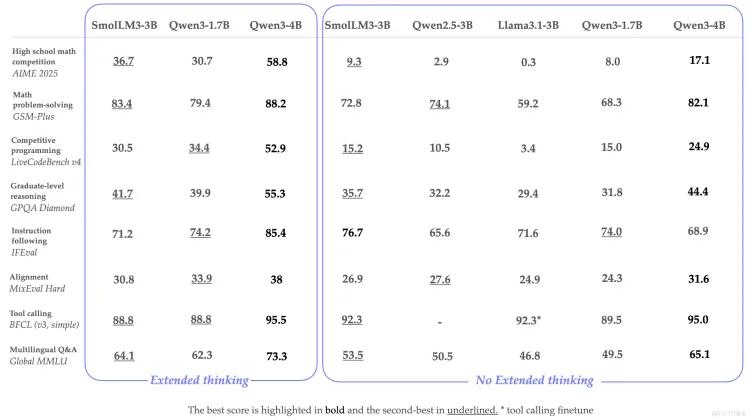
通过以上对比可以看出,不同的大语言模型各有侧重,开发者可以根据具体的应用场景选择合适的模型。
智能伙伴Agent核心特性
智能伙伴Agent是一种具有自主决策和行动能力的AI系统,它能够与环境交互,完成特定的任务。智能伙伴Agent具有以下核心特性:
自主性
智能伙伴Agent能够在没有人类干预的情况下,根据自身的目标和环境信息,自主地制定行动计划并执行。它可以感知环境的变化,调整自己的行为策略,以实现目标。
学习能力
智能伙伴Agent具有学习能力,能够通过与环境的交互和数据的积累,不断提升自身的性能和能力。它可以从成功和失败的经验中学习,优化自己的决策模型。
交互性
智能伙伴Agent能够与人类用户或其他Agent进行自然、流畅的交互。它可以理解人类的语言和指令,并用自然语言或其他方式进行回应。同时,它还可以与其他Agent协作,共同完成复杂的任务。
规划与推理能力
智能伙伴Agent具有较强的规划和推理能力。它可以根据任务目标,制定详细的行动计划,并对计划的可行性进行推理和评估。在执行过程中,如果遇到意外情况,能够及时调整计划。
多任务处理能力
智能伙伴Agent可以同时处理多个不同的任务,并根据任务的优先级和紧急程度进行合理的资源分配。它能够在不同任务之间进行切换,确保每个任务都能得到及时的处理。
智能伙伴Agent在智能家居、智能办公、智能交通等领域具有广泛的应用前景。例如,在智能家居中,智能伙伴Agent可以根据用户的生活习惯和偏好,自动调节家居设备的状态;在智能办公中,它可以协助用户处理邮件、安排会议、撰写文档等。