前言
前面我们了解了Hugging Face Spaces空间、DataSets数据集 和 Models 的使用方式,今天我们继续探索Hugging Face核心库 transformers 的使用,模型训练部分还是很难的,不需要完全能掌握看懂,先知道即可。对往期内容感兴趣的小伙伴也可以看往期:
- 【Hugging Face】初识Hugging Face
- 【Hugging Face】Hugging Face Hub与Hugging Face CLI
- 【Hugging Face】Hugging Face Space空间的基本使用方式
- 【Hugging Face】Hugging Face数据集的基本使用
- 【Hugging Face】Hugging face模型的基本使用
简介
Transformers 是Hugging Face的一个基于注意力机制的深度学习模型架构的开源工具包,旨在简化Transformer模型的开发和使用。Transformers支持多种流行的深度学习框架,如 TensorFlow 和 PyTorch,提供了丰富的预训练模型和微调。Transformers 库不仅支持文本生成、分类、翻译等任务,还扩展到图像处理和多模态任务。
核心功能
- 管道:适用于多种机器学习任务的简单且优化的推理类,如文本生成、图像分割、自动语音识别、文档问答等。
- 训练器:一个全面的训练器,支持混合精度、torch.compile 和 FlashAttention 等功能,用于 PyTorch 模型的训练和分布式训练。
- 生成:使用大型语言模型(LLMs)和视觉语言模型(VLMs)进行快速文本生成,包括对流式传输和多解码策略的支持。
应用场景
- 机器翻译:Transformers 架构最初被提出就是为了解决机器翻译问题,它能够处理长距离依赖关系,提高翻译的准确性和流畅性
- 文本生成:在文本生成任务中,如文本摘要、聊天机器人、内容创作等,Transformers 能够生成连贯且有意义的文本
- 问答系统:Transformers 可以用于构建问答系统,通过理解问题并从给定文本中提取答案
- 文本分类:在情感分析、主题分类等文本分类任务中,Transformers 能够识别文本的特征并进行有效分类
- 智能填词:在智能填词或文本补全任务中,Transformers 能够预测缺失的单词或短语
- 文本摘要:Transformers 还可以用于生成文档或文章的摘要,提取关键信息并生成简洁的总结
安装
安装PyTorch
安装CPU版本
php
$ pip install torch torchvision torchaudio安装NVIDIA GPU版本,更多安装方式可以查看PyTorch官网:pytorch.org/
perl
$ pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126安装Transformers
安装最新版本的 Transformers 以及 Hugging Face 生态系统中的其他一些库,用于访问数据集和视觉模型、评估训练以及优化大型模型的训练。
php
$ uv add transformers evaluate accelerate timm
或者
$ pip install transformers evaluate accelerate timm安装DataSets
php
$ pip install datasets基本使用
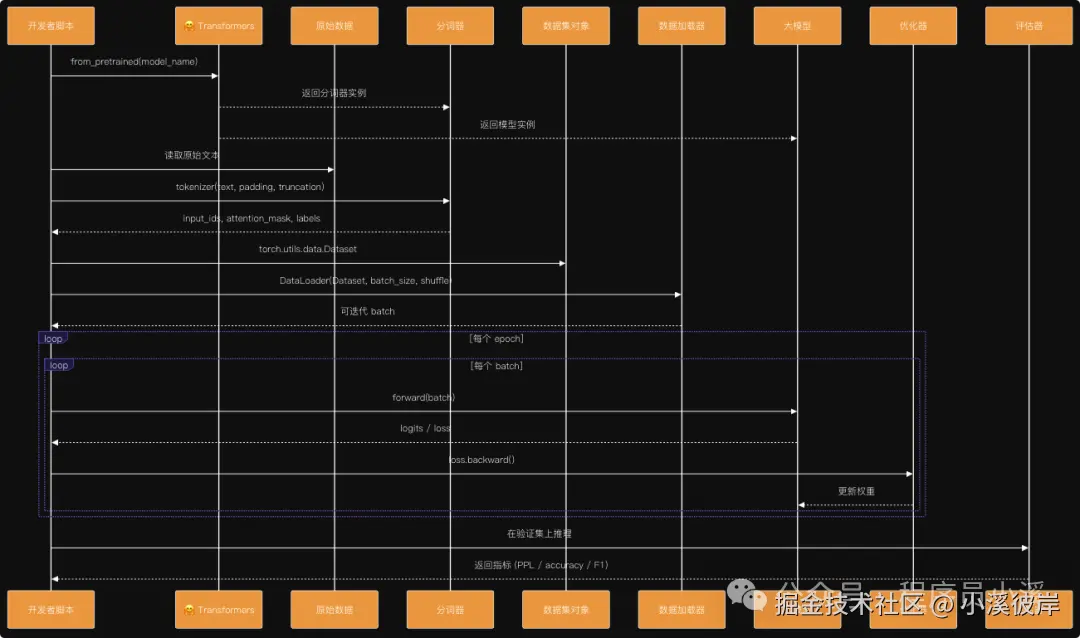
由于本人机器硬件限制,这里在Colab上体验,对Colab不了解的小伙伴可以看往期:初识Google Colab,这里让AI简单输出了下整个模型训练的流程,更有助于我们理解整个操作流程
缓存模型
使用模型每次都使用在线加载无疑是比较浪费时间的,我们可以选择将模型缓存到本地,之前也讲过通过 Hugging Face Hub 和 Hugging Face CLI下载模型的方式,感兴趣的小伙伴可以看往期:【Hugging Face】Hugging face模型的基本使用,这次使用transformers库中的方式缓存模型
ini
from transformers import BertTokenizer, BertForSequenceClassification, pipeline
model_name = "ckiplab/bert-base-chinese"
cache_dir = "./models"
tokenizer = BertTokenizer.from_pretrained(model_name, cache_dir=cache_dir)
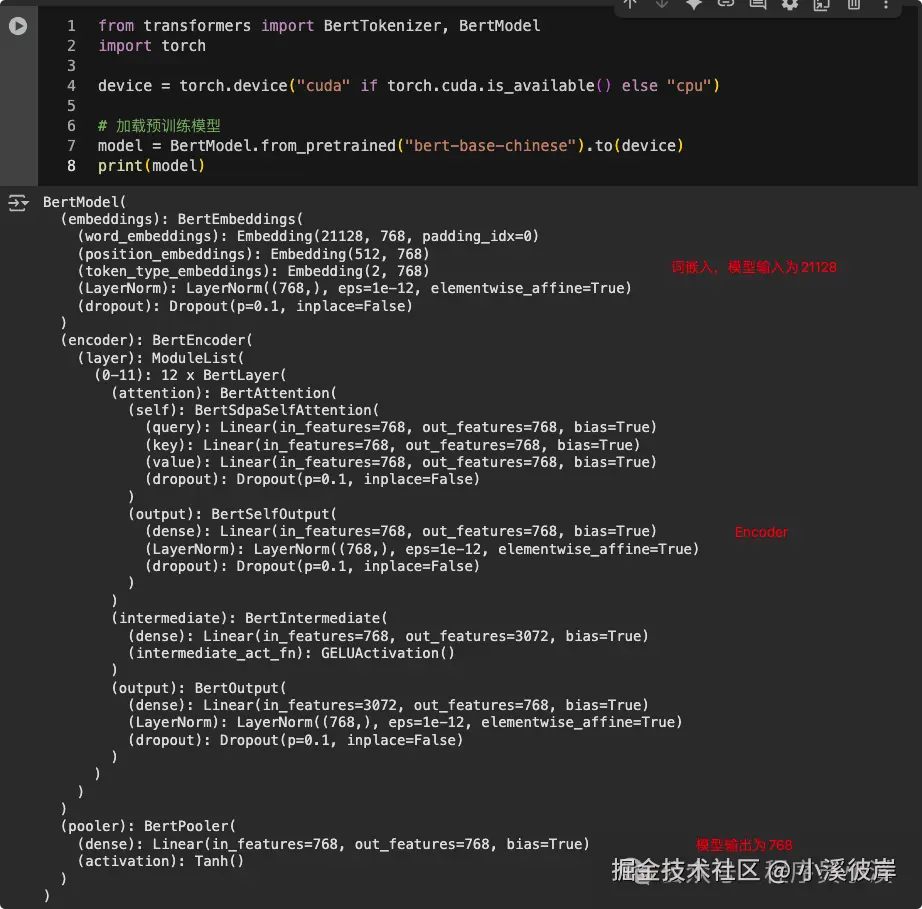
model = BertForSequenceClassification.from_pretrained(model_name, cache_dir=cache_dir模型缓存完成后,我们可以得到一个类似如下的模型目录,具体的模型文件存放在snapshots目录下

打印模型,我们将得到模型结构如下:
使用本地模型
Transformers 4.x后本地模型路径需要指定为绝对路径
使用本地模型只需将模型名称改成本地模型路径
python
from transformers import BertTokenizer, BertForSequenceClassification, pipeline
model_name = r"本地模型绝对路径/model/models--bert-base-chinese/snapshots/8f23c25b06e129b6c986331a13d8d025a92cf0ea"
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name)加载预训练模型和Tokenizer
使用Transformers库,可以非常方便地加载预训练模型和对应的Tokenizer(分词器),这里Tokenizer的主要作用是将文本数据转换为模型可以理解的格式。
ini
from transformers import BertTokenizer, BertModel
model_name = "bert-base-uncased"
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name)模型加载完毕后就可以正常使用模型了
scss
text = "Replace me by any text you'd like."
# text = ["Replace me by any text you'd like."]
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
print(output)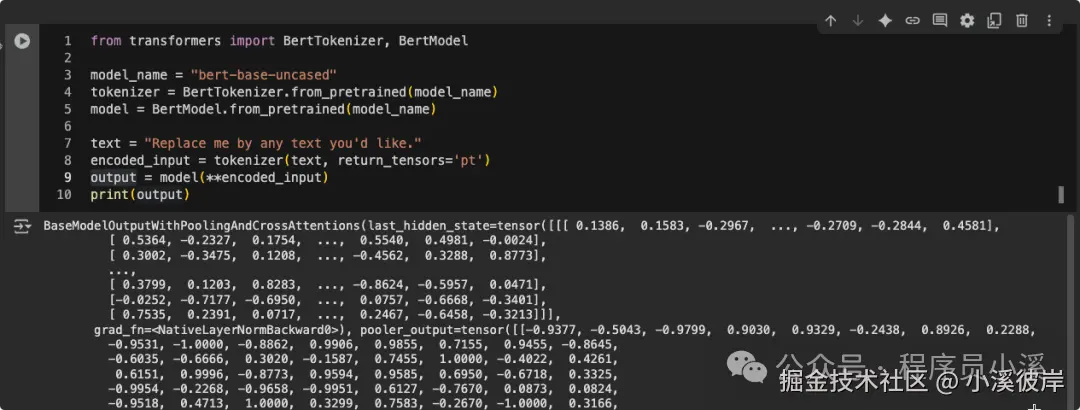
使用AutoModel和AutoTokenizer
为了更具通用性,Hugging Face提供了AutoModel和AutoTokenizer类。这些类可以自动根据模型名称加载合适的模型和Tokenizer,无需要指定具体的模型类。
ini
from transformers import AutoTokenizer, AutoModel
model_name = "uer/gpt2-chinese-cluecorpussmall"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)数据预处理
所谓的数据预处理就是把原始数据转化为模型可以理解和使用形式的过程。自然语言处理(NLP)任务中,数据预处理通常包括以下几个步骤:将文本转化为数字(Tokenization)、使所有输入的长度一致(Padding 和 Truncation),然后将数据组织成方便模型训练的数据集和数据加载器。
Tokenization(文本转化为数字)
Tokenization是将文本转换为模型可以处理的数字序列的过程,如果输入的是句子,Tokenization会将句子拆分为一个个单词并将它们转为数字。在Transformers库中,Tokenizer类是处理Tokenization的核心工具,不同的预训练模型(如 BERT、GPT-3 等)都有各自对应的 Tokenizer(分词器),且使用时需要使用对应的Tokenizer。
我们可以手动指定bert-base-uncased需要的BertTokenizer
ini
from transformers import BertTokenizer
model_name = "bert-base-uncased"
tokenizer = BertTokenizer.from_pretrained(model_name)
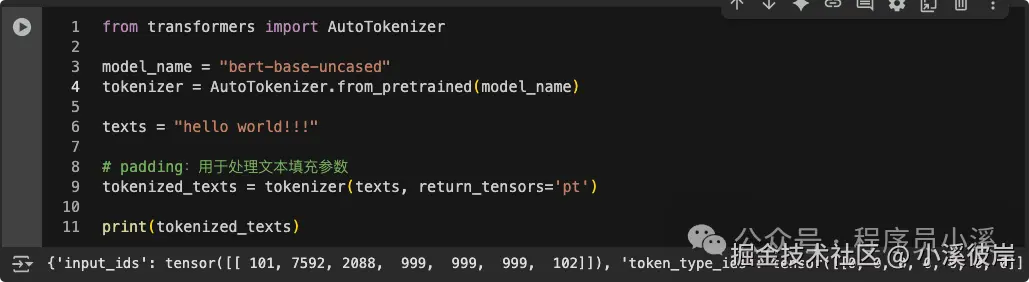
texts = "hello world!!!"
# padding:用于处理文本填充参数
tokenized_texts = tokenizer(texts, return_tensors='pt')
print(tokenized_texts)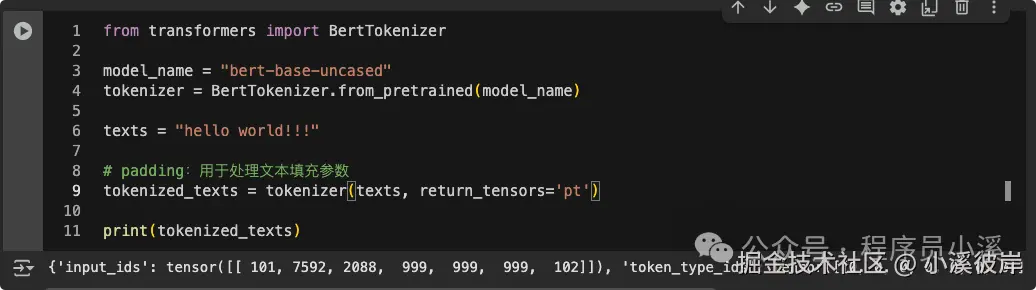
也可以使用AutoTokenizer自动选择并加载bert的Tokenizer
Padding和Truncation(保存输入长度一致)
在将文本转换为Token序列后,我们需要确保所有序列的长度一致,可以通过 Padding 和 Truncation 来实现。
- Padding:将较短的序列填充到指定长度,使得所有序列长度一致
- padding=true:自动根据当前批次中最长的序列进行填充,可以减少不必要的填充,提高计算效率
- padding='max_length':将所有序列填充到指定的最大长度,所有批次中的序列长度一致,适合在需要固定输入长度的情况下使用
- Truncation:是将过长的序列截断到指定长度,以确保输入序列的长度不超过模型的最大处理能力
使用方式如下:
ini
tokenized_texts = tokenizer(
"hello world!!!",
padding=True, # 填充到最大长度
truncation=True, # 截断到模型允许的最大长度
return_tensors='pt' # 返回 PyTorch 张量
)
tokenized_texts = tokenizer(
"hello world!!!",
padding='max_length', # 填充到最大长度
max_length=10, # 设置最大长度为10
truncation=True, # 截断到模型允许的最大长度
return_tensors='pt' # 返回 PyTorch 张量
)
print(tokenized_texts)
ini
from transformers import BertTokenizer
model_name = "bert-base-uncased"
tokenizer = BertTokenizer.from_pretrained(model_name)
texts = ["hello world!!!", "how are you?"]
# padding:用于处理文本填充参数
tokenized_texts = tokenizer(texts, padding=True, truncation=True, return_tensors='pt')
print(tokenized_texts)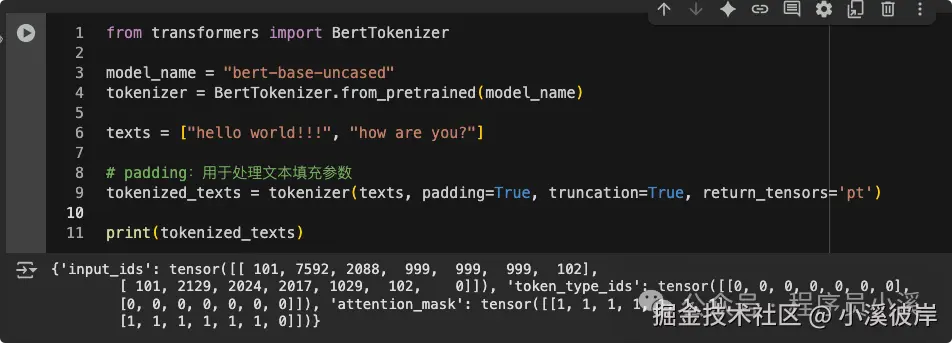
也可以使用AutoTokenizer自动选择并加载bert的Tokenizer
ini
from transformers import AutoTokenizer
model_name = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
texts = ["hello world!!!", "how are you?"]
# padding:用于处理文本填充参数
tokenized_texts = tokenizer(texts, padding=True, truncation=True, return_tensors='pt')
print(tokenized_texts)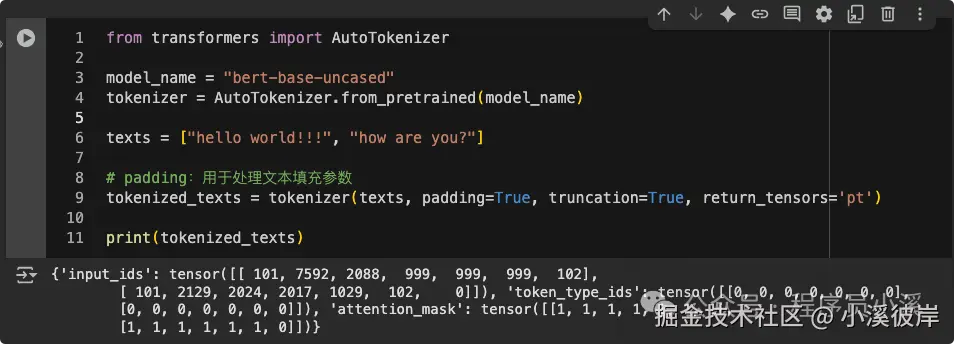
也可以对数据集进行批量编码处理
ini
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-chinese")
sents = ["今天天气真好,我想去划水,在办公室真是太浪费时间了,你觉得呢,我也觉得很好哈", "哈哈你好"]
# 批次编码, 单句可以使用tokenizer.encode
# output = tokenizer.encode(
# sents[0],
# text_pair=None,
# padding="max_length",
# max_length=10,
# truncation=True,
# add_special_tokens=True,
# )
# print(tokenizer.decode(output))
output = tokenizer.batch_encode_plus(
batch_text_or_text_pairs=sents,
add_special_tokens=True, # 添加特殊符号
padding="max_length", # 对其
max_length=30,
truncation=True, # 截取模型接收的最大长度
return_tensors=None, # pt
return_token_type_ids=True, # token_type_ids
return_attention_mask=True, # attention_mask
return_special_tokens_mask=True, # 添加特殊符号标识
return_length=True, # 标识长度
)
# print(output)
for k, v in output.items():
print(k, v)
# 输入预处理后的结果
print(tokenizer.decode(output["input_ids"][0]), tokenizer.decode(output["input_ids"][1]))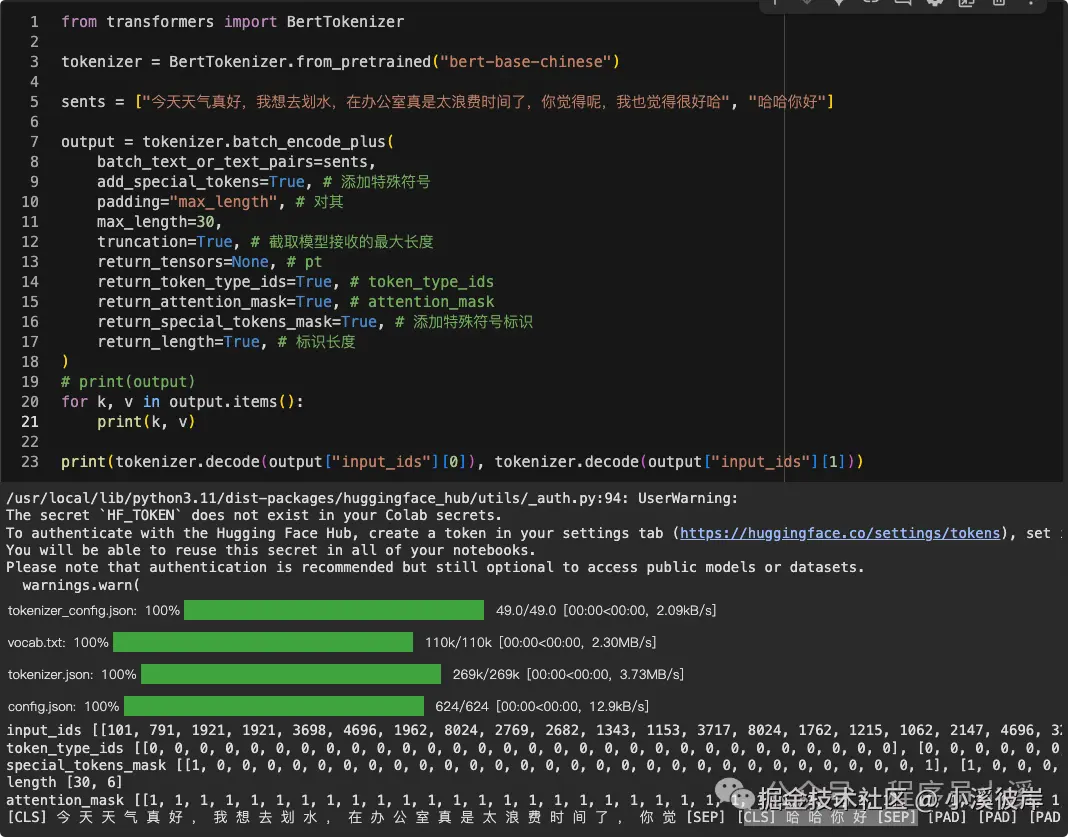
最后再来看下,padding=True和 padding='max_length'的区别
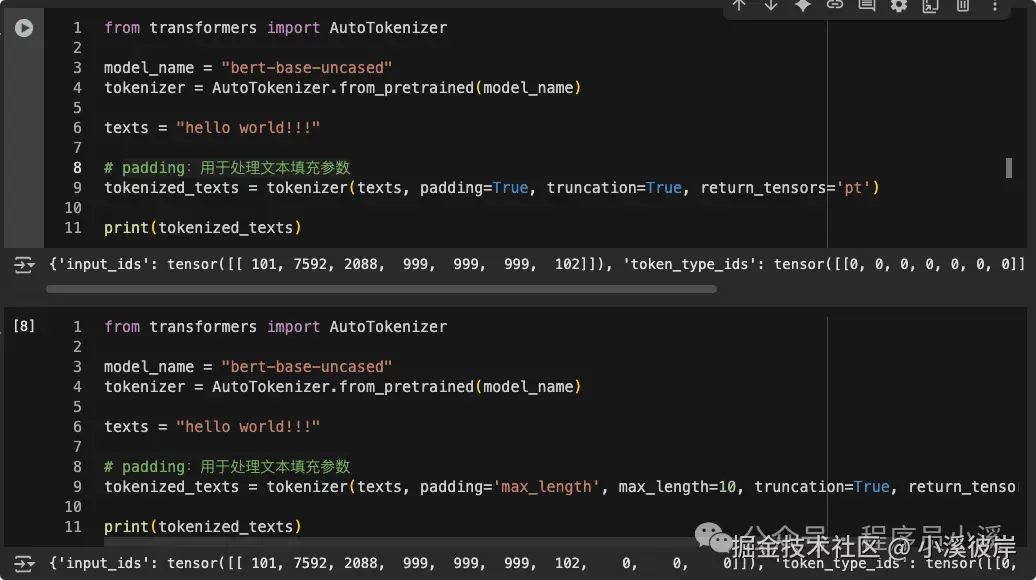
创建数据集和数据加载器
在完成 Tokenization、Padding和Truncation后,就需要将数据转换为可供模型训练使用的数据集和数据加载器了
ini
from transformers import AutoTokenizer
from datasets import Dataset
import torch
from torch.utils.data import DataLoader
model_name = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
texts = ["hello world!!!", "how are you?"]
# padding:用于处理文本填充参数
tokenized_texts = tokenizer(texts, padding=True, truncation=True, return_tensors='pt')
# 创建数据集
data = {
'input_ids': tokenized_texts['input_ids'],
'attention_mask': tokenized_texts['attention_mask'],
'labels': torch.tensor([1, 0]) # 示例标签,与数据集文本数量保存一致
}
dataset = Dataset.from_dict(data)
# 定义 DataLoader
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)
# 打印DataLoader
for batch in dataloader:
print(batch)这里创建了一个包含 input_ids、attention_mask 和 labels 的字典,然后我们使用 Dataset.from_dict 将其转换为 Hugging Face 数据集,最后通过 PyTorch 的 DataLoader 创建数据加载器用于模型训练。
AutoModelForSequenceClassification(文本分类)
AutoModelForSequenceClassification 是 Transformers 提供的 "一站式"文本分类模型加载器,简单来说就是把一段文本映射成 N 个类别概率,用来做分类任务。
ini
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)Tokenizer扩展
Tokenizer分词器提供了很多API,这里探索一下常用的操作
使用Tokenizer获取vocab(模型字典)
bash
# 获取模型字典
vocab = tokenizer.get_vocab()
print(vocab)
# 判断字是否在字典中
print("天" in vocab)为模型词典添加新词
bash
# 字典添加新词
tokenizer.add_tokens(["阳光", "大地"])
# 获取字典
vocab = tokenizer.get_vocab()
print("阳光" in vocab)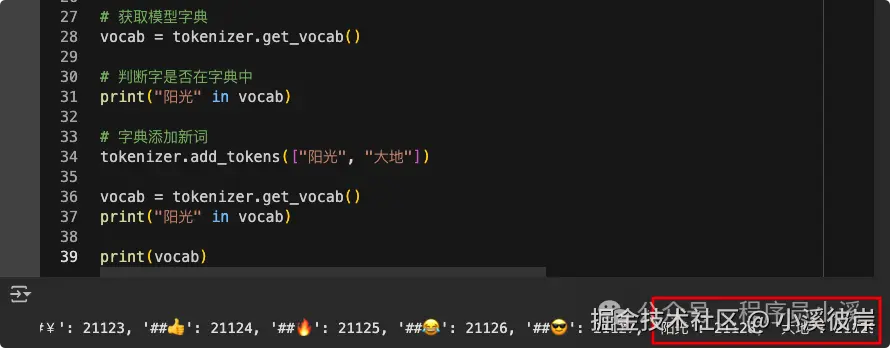
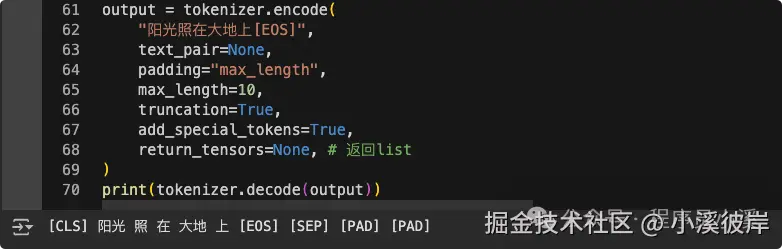
为模型添加特殊符号,特殊符号只接收官方键名:

bash
# 添加特殊符号, 特殊符号为键值对
tokenizer.add_special_tokens({"eos_token": "[EOS]"})
print(tokenizer)下面通过一个案例看下自定义词典和特殊符号的作用
ini
output = tokenizer.encode(
"阳光照在大地上",
text_pair=None,
padding="max_length",
max_length=10,
truncation=True,
add_special_tokens=True,
return_tensors=None, # 返回list
)
print(tokenizer.decode(output))添加词典和特殊符号前
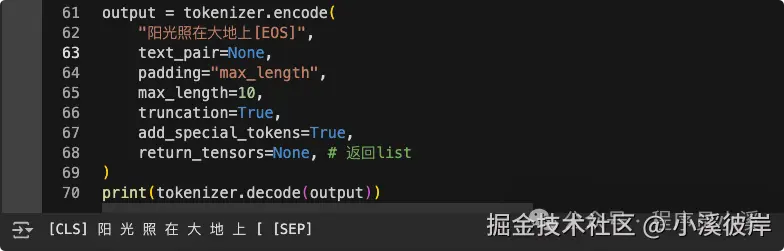
添加词典和特殊符号后,再看一下编码方式的区别
Pipeline(管道)
pipeline是 Hugging Face transformers库中的一个高层次接口,用于简化模型的使用。它可以处理输入的文本、进行推理并返回结果。Pipeline中有多种管道,每种管道的使用方式各不相同。
- 文本分类(Text Classification):用于对输入的文本进行分类,例如情感分析、垃圾邮件检测等, 'text-classification',默认值
- 命名实体识别(NER):用于识别文本中的命名实体,例如人名、地名、组织名等, 'ner'
- 问答(Question Answering):用于从提供的段落中找到问题的答案, 'question-answering'
- 填空(Fill-Mask):用于预测被遮蔽的词语,适用于掩码语言模型(如 BERT), 'fill-mask'
- 文本生成(Text Generation):用于生成文本,适用于生成型语言模型, 'text-generation'
- 翻译(Translation):用于将文本从一种语言翻译为另一种语言, 'translation_en_to_fr'
- 摘要生成(Summarization):用于生成文本的摘要, 'summarization'
- 文本相似性(Text Similarity):用于计算两个文本的相似度, 'text-similarity'
- 零样本分类(Zero-Shot Classification):用于在没有特定训练数据的情况下进行分类任务, 'zero-shot-classification'
- 对话(Conversational):用于实现对话代理或聊天机器人, 'conversational'
- 情感分析(Sentiment Analysis):用于分析文本的情感倾向, 'sentiment-analysis'
- 特征提取(Feature Extraction):用于提取文本的特征向量, 'feature-extraction'
- 音频分类(Audio Classification):用于对音频数据进行分类, 'audio-classification'
- 自动语音识别( ASR):用于将语音转换为文本, 'automatic-speech-recognition'
- 图像分类(Image Classification):用于对图像数据进行分类, 'image-classification'
- 图像分割(Image Segmentation):用于对图像数分割, 'image-segmentation'
NER 管道
python
from transformers import pipeline
# 使用 pipeline 创建一个 NER 管道
ner_pipeline = pipeline("ner", model="dbmdz/bert-large-cased-finetuned-conll03-english")
# 输入文本
text = "Hugging Face Inc. is a company based in New York City. Its headquarters are in DUMBO, therefore very close to the Manhattan Bridge."
# 进行命名实体识别
ner_results = ner_pipeline(text)
# 打印识别结果
for entity in ner_results:
print(f"Entity: {entity['word']}, Label: {entity['entity']}, Start: {entity['start']}, End: {entity['end']}")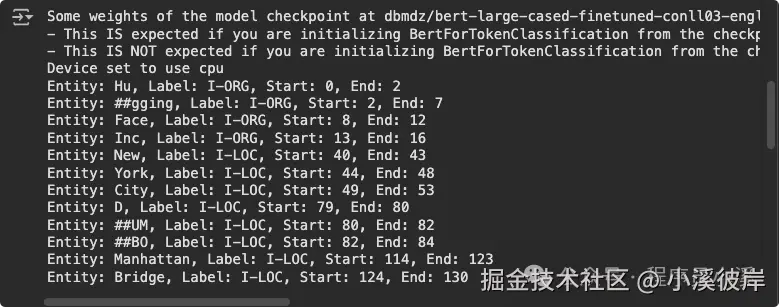
文本分类
python
from transformers import pipeline
# 文本分类
text_classifier = pipeline("text-classification")
print(text_classifier("I love using Hugging Face transformers!"))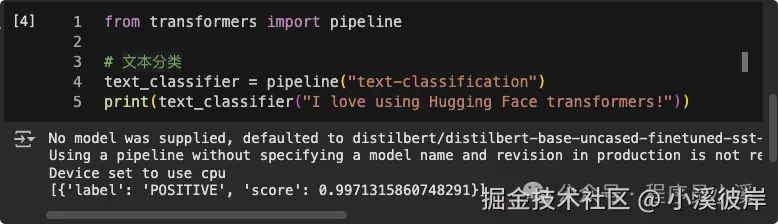
图像分割
ini
from transformers import pipeline
pipeline = pipeline("image-segmentation", model="facebook/detr-resnet-50-panoptic", device="cuda")
segments = pipeline("https://huggingface.co/datasets/Narsil/image_dummy/raw/main/parrots.png")
segments[0]["label"]
'bird'
segments[1]["label"]
'bird'模型补充
Transformers库中包含多种模型,如 AutoModel、AutoModelForCausalLM、等
- AutoModel:"通用编码器",把一段文本(或多种模态)直接转成 上下文相关向量(隐藏状态),不负责任何下游任务(不分类、不生成、不问答),只输出句向量
- AutoModelForCausalLM:"生成式语言模型" 的通用入口,给它一段上文,它帮你 自回归地(causal)逐 token 生成下文,典型任务包括对话、续写、代码补全、故事创作等。额外带 LM Head,把隐藏状态映射成词表 logits,用于预测下一个词。
Trainer 训练器
Trainer 是 PyTorch 模型的完整训练和评估循环。它抽象了手动编写训练循环时通常涉及的大量样板代码,我们只需要一个模型、数据集、一个预处理器和数据整理器,就可以从数据集中构建数据批次。
下面是官方的模型训练示例,加载用于训练的模型、分词器和数据集
ini
from transformers import AutoModelForSequenceClassification, AutoTokenizer
from datasets import load_dataset
# 模型
model = AutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
# 分词器
tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
# 数据集
dataset = load_dataset("rotten_tomatoes")创建一个函数来对文本进行分词并将其转换为 PyTorch 张量
python
def tokenize_dataset(dataset):
return tokenizer(dataset["text"])
dataset = dataset.map(tokenize_dataset, batched=True)加载一个数据组合器来创建数据批次
ini
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)使用训练特性和超参数设置 TrainingArguments
ini
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="distilbert-rotten-tomatoes",
learning_rate=2e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=2,
push_to_hub=True,
)最后,将这些独立的组件传递给 Trainer,并调用train()来开始
ini
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
tokenizer=tokenizer,
data_collator=data_collator,
)
trainer.train()使用push_to_hub()将您的模型和分词器分享到 Hub 上
scss
trainer.push_to_hub()使用案例
机器翻译
Hugging Face的Transformers库提供了很多专门为翻译任务训练的模型,翻译效果比较好的例如 T5 、MarianMT等。
t5-base:huggingface.co/google-t5/t...
这里以T5为例做一个英语转德语,该模型对中文支持不好就不尝试中文了
ini
from transformers import T5Tokenizer, T5ForConditionalGeneration
# 加载 T5 模型和分词器
model_name = "t5-base"
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name)
# 定义要翻译的文本,对中文支持不好
src_texts = ["translate English to German: Hello, how are you?", "translate English to German: This is a machine translation example."]
# 将文本转换为模型输入格式
inputs = tokenizer(src_texts, padding=True, truncation=True, return_tensors="pt")
# 生成翻译
translated = model.generate(**inputs)
# 将翻译内容转换为文本
translated_texts = [tokenizer.decode(t, skip_special_tokens=True) for t in translated]
# 打印翻译结果
for src, tgt in zip(src_texts, translated_texts):
print(f"{src} -> {tgt}")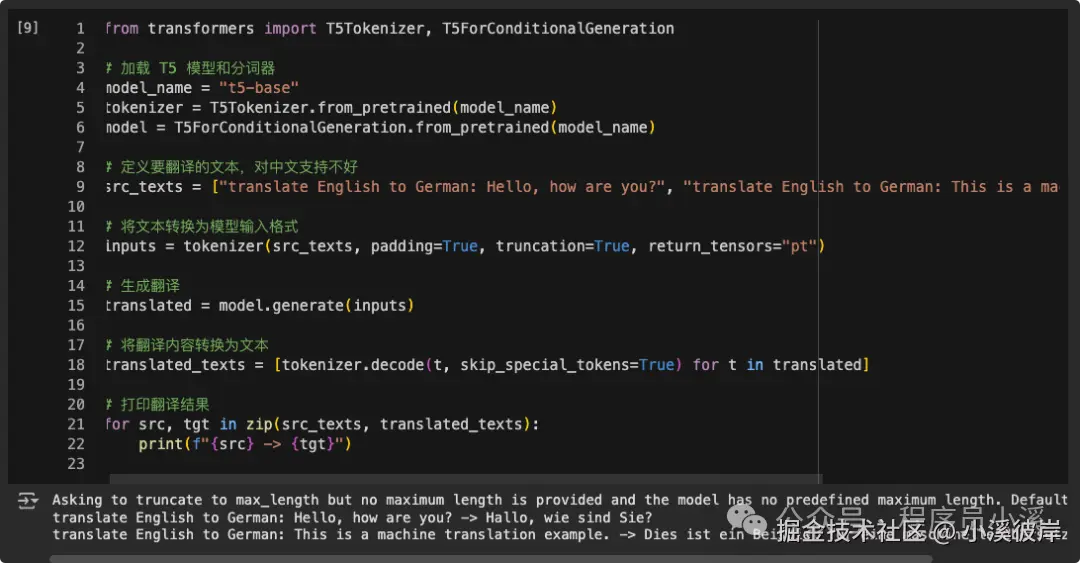
文本生成
gpt2-chinese-cluecorpussmall:huggingface.co/uer/gpt2-ch...
该模型用于生成中文文本
ini
from transformers import AutoModelForCausalLM, AutoTokenizer
# 文本生成模型
model_name = "uer/gpt2-chinese-cluecorpussmall"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 数据预处理
model_inputs = tokenizer(
["The secret to baking a good cake is "],
return_tensors="pt"
)
# 生成文本
generated_ids = model.generate(**model_inputs, max_length=30)
# 解码
output = tokenizer.batch_decode(
generated_ids,
skip_special_tokens=True # 过滤特殊符号
)[0]
print(output)也可以使用pipeline
ini
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
# 文本生成模型
model_name = "uer/gpt2-chinese-cluecorpussmall"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 任务名称:text-generation
generator = pipeline('text-generation', model=model, tokenizer=tokenizer)
# 生成文本, 生成50个字符,以一句话返回
# output = generator("你好", max_length=50, num_return_sequences=1)
output = generator(
"你好,我是语言模型",
max_length=50, # 生成文本最大长度
num_return_sequences=1, # 返回一句话
truncation=True, # 截断文本以适应模型最大输入长度
temperature=0.7, # 控制文本生成的随机性,值越低生成的越保守,值越高多样性越高
top_k=50, # 每步生成从概率最高的K个词中选择一个
top_p=0.9, # 核采样,从高概率集合中选择,控制质量
clean_up_tokenization_spaces=True, # 是否清除多余的格式,保留格式设置为False, 设置为True清理格式
)
print(output)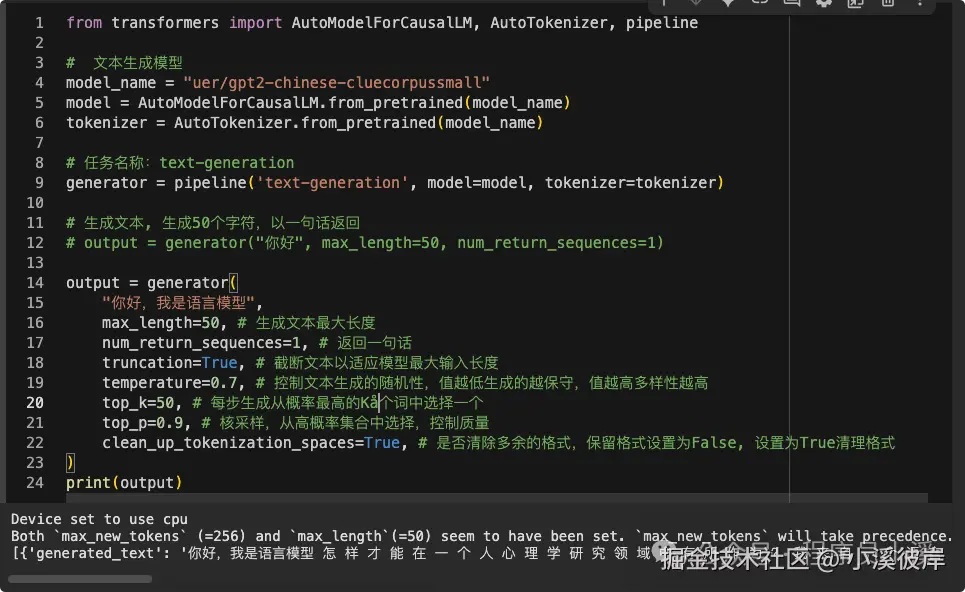
bert-base-chinese:huggingface.co/ckiplab/ber...
bert-base-chinese为最早期中文语言生成模型
ini
from transformers import BertTokenizer, BertForSequenceClassification, pipeline
model_name = "bert-base-chinese"
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name)
sentiment_classifier = pipeline("text-classificatioon", model=model, tokenizer=tokenizer)
result = sentiment_classifier("你好,我是一款语言模型")
print(result)bert-base-chinese预训练模型无法做分类处理,这里只会输出评分结果
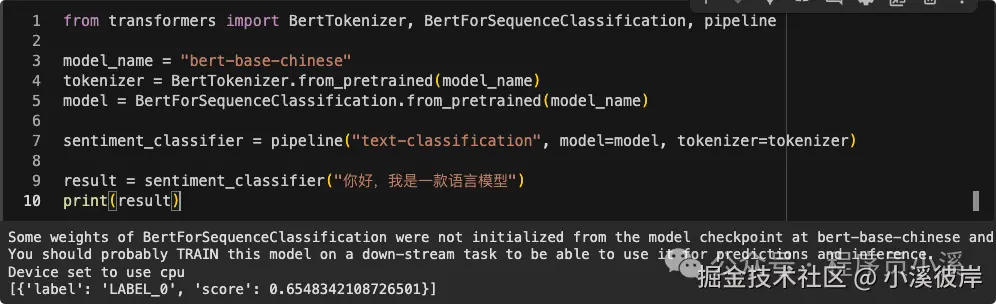
情感分析
使用pipeline
python
from transformers import pipeline
clf = pipeline("sentiment-analysis", model="bert-base-uncased")
print(clf("I love transformers!"))使用BertForSequenceClassification
ini
from transformers import BertTokenizer, BertForSequenceClassification
import torch
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertForSequenceClassification.from_pretrained("bert-base-uncased")
# model.eval()
text = ["I love transformers!"]
inputs = tokenizer(text, padding=True, truncation=True, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# 输出最后一层结果
probs = torch.softmax(logits, dim=-1)
# 得预测类别
pred_id = probs.argmax(-1).item()
print(model.config.id2label[pred_id], probs[0, pred_id].item())训练模型
该示例是使用Pytorch进行模型训练的,非官方的Trainer
第一步缓存数据集,为了使运行更加快速,我们可以先对数据集进行缓存
java
from datasets import load_dataset
dataset = load_dataset("lansinuote/ChnSentiCorp")
dataset.save_to_disk("./datasets/ChnSentiCorp")第二步加载数据集,这里使用Pytorch的Dataset
python
from torch.utils.data import Dataset
from datasets import load_from_disk
class MyDataset(Dataset):
# 初始化数据
def __init__(self, split):
self.dataset = load_from_disk("/content/datasets/ChnSentiCorp")
if split == "train": # 训练集
self.dataset = self.dataset["train"]
elif split == "validation": # 验证集
self.dataset = self.dataset["validation"]
elif split == "test": # 测试集
self.dataset = self.dataset["test"]
else:
raise ValueError("Invalid split name")
# 获取数据集大小
def __len__(self):
return len(self.dataset)
# 对数据做定制化处理
def __getitem__(self, index):
text = self.dataset[index]["text"]
label = self.dataset[index]["label"]
return text, label
dataset = MyDataset("validation")
for data in dataset:
print(data)运行代码块,我们将得到数据集的内容
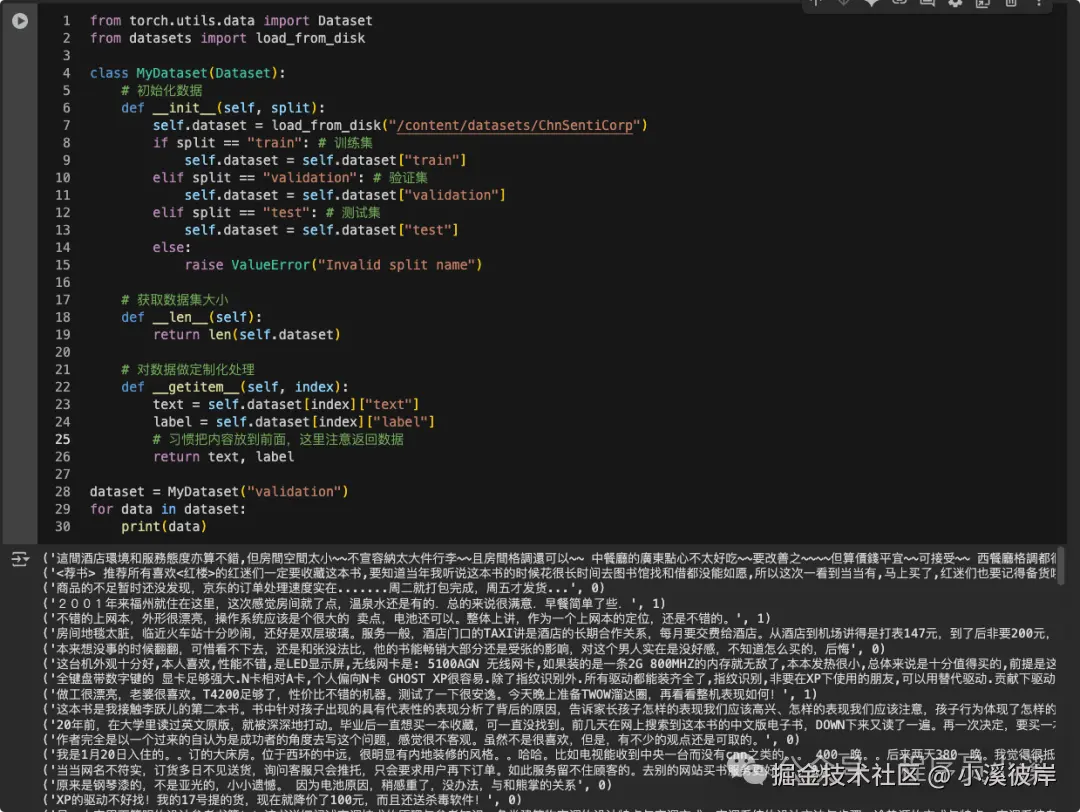
第三步加载模型,同样使用torch定义Model
python
import torch
import torch.nn as nn
class Model(nn.Module):
def __init__(self, bert_model):
super().__init__()
self.bert = bert_model
# 全连接,模型输入为768,分类为2
self.fc = nn.Linear(768, 2)
def forward(self, input_ids, attention_mask, token_type_ids):
# 使用预训练模型提取特征, 上游任务不参与训练,锁定权重
with torch.no_grad():
# Correctly call the BertModel instance stored in self.bert
output = self.bert(input_ids, attention_mask, token_type_ids)
# 下游参与训练,二分类任务,获取最新后的状态
output = self.fc(output.last_hidden_state[:, 0])
# NV结构,获取特征值
output = output.softmax(dim=1)
return output
# model = Model(bert_model)第四步创建数据加载器
ini
from transformers import BertTokenizer
from torch.utils.data import DataLoader
# 加载分词器
tokenizer = BertTokenizer.from_pretrained("bert-base-chinese")
# 获取训练集
train_dataset = MyDataset("train")
# 自定义函数,对数据做编码处理
def collate_fn(data):
sents = [i[0] for i in data]
labels = [i[1] for i in data]
# 编码处理
# data = tokenizer(sents, padding=True, truncation=True, return_tensors="pt")
data = tokenizer.batch_encode_plus(
batch_text_or_text_pairs=sents,
padding="max_length", # 对其
max_length=350,
truncation=True, # 截取模型接收的最大长度
return_tensors="pt", # pt: Pytorch类型
return_length=True, # 标识长度
)
# 获取编码结果
input_ids = data["input_ids"]
attention_mask = data["attention_mask"]
token_type_ids = data["token_type_ids"]
labels = torch.LongTensor(labels)
return input_ids, attention_mask, token_type_ids, labels
# 创建数据加载器
train_loader = DataLoader(
train_dataset,
batch_size=32, # 加载数据批次大小32条
shuffle=True, # 打乱数据集
drop_last=True, # 丢弃最后一个不完整的batch
collate_fn=collate_fn # 数据集做定制化处理
)第五步定义训练器
ini
from transformers import BertModel
# AdamW在bert模型上是一个不错的训练器
from torch.optim import AdamW
import torch
import os
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 训练次数
EPOCH = 100
# 优化器
# 加载预训练模型
bert_model = BertModel.from_pretrained("bert-base-chinese").to(device)
model = Model(bert_model).to(device)
optimizer = AdamW(model.parameters(), lr=5e-4) # lr初始值0.0005
# 损失函数
loss_func = torch.nn.CrossEntropyLoss()
# 开启训练
model.train()
for epoch in range(EPOCH):
for i,(input_ids, attention_mask, token_type_ids, labels) in enumerate(train_loader):
# 将数据放到device
input_ids = input_ids.to(device)
attention_mask = attention_mask.to(device)
token_type_ids = token_type_ids.to(device)
labels = labels.to(device)
# 执行计算
output = model(input_ids, attention_mask, token_type_ids)
# 计算损失
loss = loss_func(output, labels)
# 优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 5 == 0:
out = output.argmax(dim=1)
# 准确度
acc = (out == labels).sum().item() / len(labels)
print("epoch: {}, step: {}, loss: {}, acc: {}".format(epoch, i, loss.item(), acc))
## 文件不存在创建
if not os.path.exists("params"):
os.mkdir("params")
# 保存模型参数
torch.save(model.state_dict(), f"params/{epoch}bert.pt")
# 添加打印,防止输入写入异常
print(epoch, "保存成功")训练完成,我们将得到一组模型参数
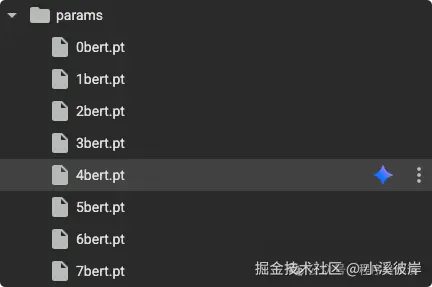
第六步验证模型
ini
from transformers import BertTokenizer
import torch
import os
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
tokenizer = BertTokenizer.from_pretrained("bert-base-chinese")
def collate_fn(data):
sentes = [i[0] for i in data]
label = [i[1] for i in data]
#编码
data = tokenizer.batch_encode_plus(
batch_text_or_text_pairs=sentes,
truncation=True,
padding="max_length",
max_length=350,
return_tensors="pt",
return_length=True
)
input_ids = data["input_ids"]
attention_mask = data["attention_mask"]
token_type_ids = data["token_type_ids"]
labels = torch.LongTensor(label)
return input_ids,attention_mask,token_type_ids,labels
#创建数据集
test_dataset = MyDataset("test")
#创建dataloader
test_laoder = DataLoader(
dataset=test_dataset,
batch_size=32,
shuffle=True,
drop_last=True,
collate_fn=collate_fn
)
acc = 0
total = 0
#开始测试DEVICE
# 加载预训练模型
bert_model = BertModel.from_pretrained("bert-base-chinese").to(device)
model = Model(bert_model).to(device)
model.load_state_dict(torch.load("/content/params/2bert.pt"))
# 切换到eval模式
model.eval()
for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(test_laoder):
# 将数据放到device
input_ids = input_ids.to(device)
attention_mask = attention_mask.to(device)
token_type_ids = token_type_ids.to(device)
labels = labels.to(device)
out = model(input_ids, attention_mask, token_type_ids)
out = out.argmax(dim=1)
acc += (out == labels).sum().item()
total+= len(labels)
# 打印结果
print(acc/total)问答系统
问答系统数据集以SQuAD为例,SQuAD数据集包含了大量的问题和对应的答案
ini
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForQuestionAnswering
import torch
# 加载数据集
dataset = load_dataset("rajpurkar/squad")
# 加载模型和分词器
model_name = "distilbert-base-uncased"
model = AutoModelForQuestionAnswering.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
def answer_question(question, context):
inputs = tokenizer.encode_plus(
question,
context,
add_special_tokens=True,
return_tensors="pt",
max_length=512,
truncation=True
)
input_ids = inputs["input_ids"][0] # 一维张量即可
with torch.no_grad():
output = model(**inputs)
start_logits, end_logits = output.start_logits, output.end_logits
answer_start = torch.argmax(start_logits)
answer_end = torch.argmax(end_logits) + 1
# 直接拿子序列的 token ids 再解码即可
answer_ids = input_ids[answer_start:answer_end]
answer = tokenizer.decode(answer_ids, skip_special_tokens=True)
return answer
context = "Hugging Face Inc. is a company based in New York City. Its headquarters are in DUMBO, therefore very close to the Manhattan Bridge."
question = "Where is Hugging Face based?"
result = answer_question(question, context)
print("result:", result)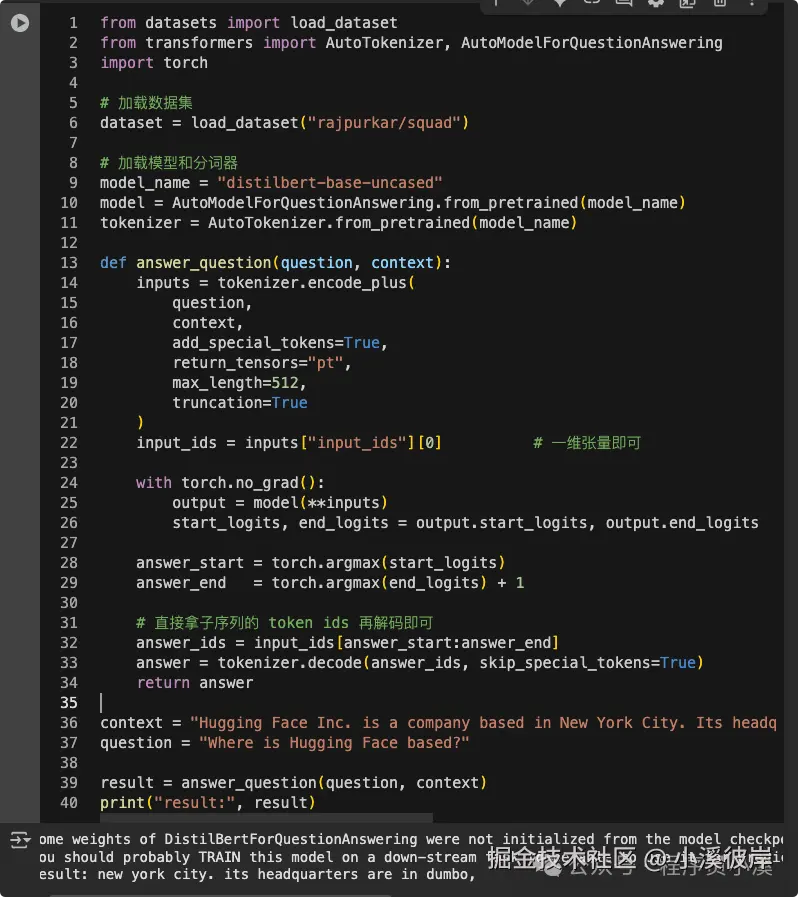
常见问题
datasets找不到模型
如果提示模型找不到,可以执行如下指令重试
php
$ pip install -U datasets huggingface_hub fsspec参考来源
友情提示
见原文:【Hugging Face】Hugging Face Transformers的使用方式
本文同步自微信公众号 "程序员小溪" ,这里只是同步,想看及时消息请移步我的公众号,不定时更新我的学习经验。