一、Kafka高吞吐
1、 核心架构设计
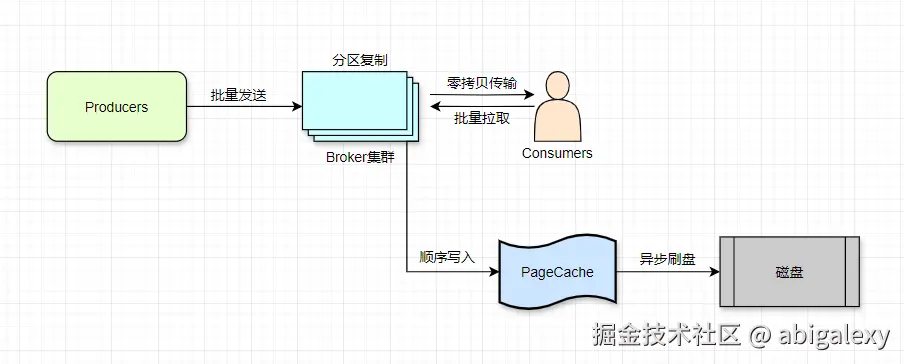
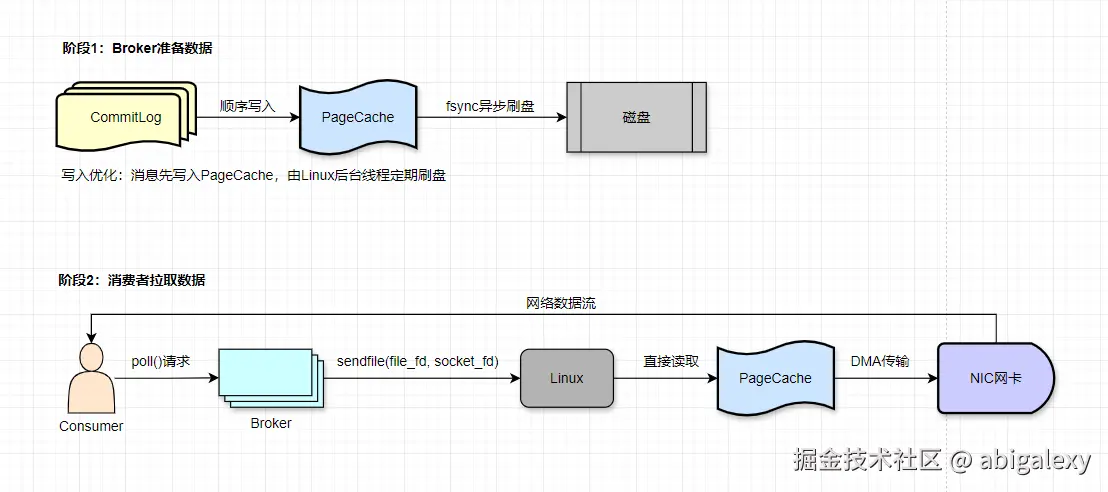
顺序磁盘I/O: 磁盘顺序写入速度接近内存随机写入速度(300MB/s+)
批量处理: Producer批量发送、Broker批量存储、Consumer批量拉取
分区(Partition)并行: 每个Topic拆分为多个Partition,消费者组内多消费者并行消费不同Partition
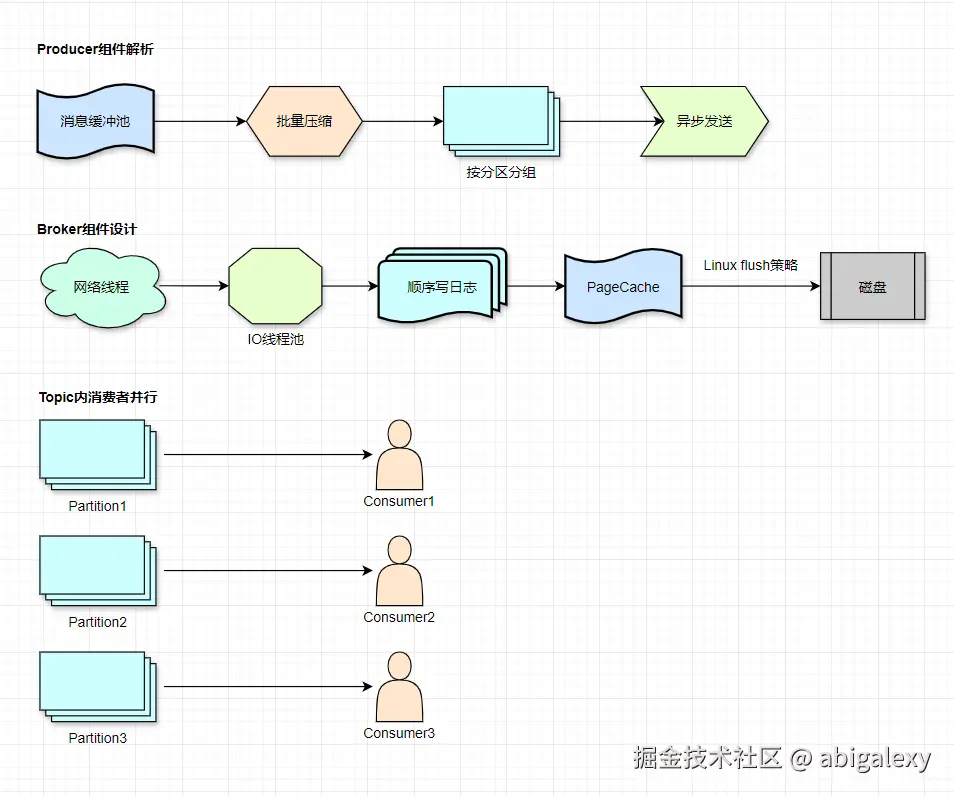
零拷贝(Zero-Copy)技术: 使用sendfile系统调用减少数据在内核空间和用户空间的拷贝
页缓存(Page Cache): 利用OS缓存减少磁盘IO,消费者直接读取缓存数据
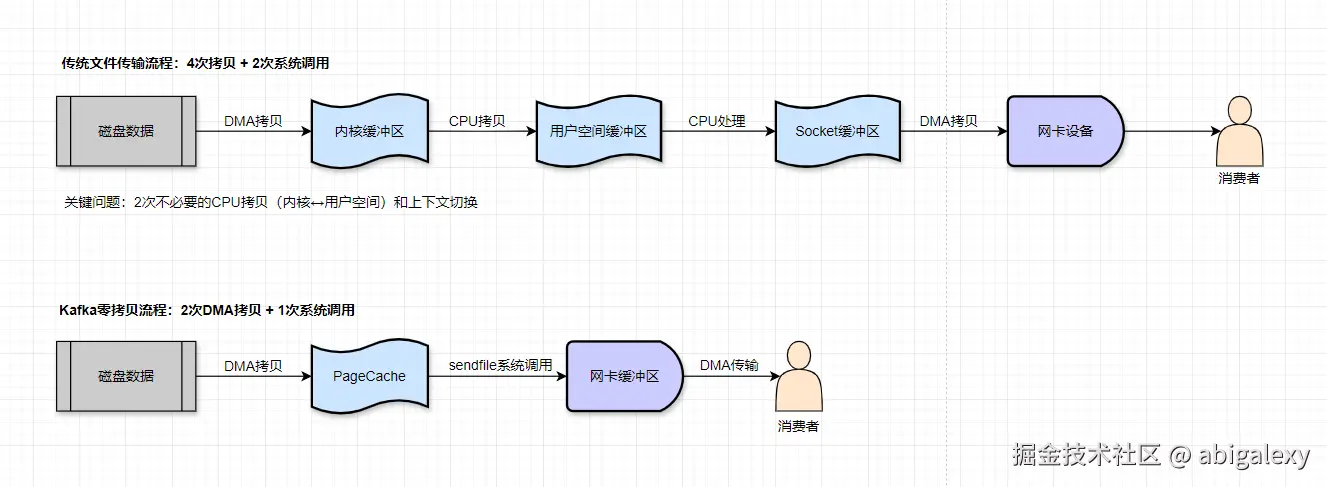
与传统技术对比
| 技术要素 | 传统方式 | Kafka零拷贝 |
|---|---|---|
| 拷贝次数 | 4次(2次DMA+2次CPU) | 2次(纯DMA) |
| 系统调用 | read()+write() | sendfile() |
| CPU参与 | 全程参与 | 仅发起调用 |
| 上下文切换 | 用户态/内核态多次切换 | 保持内核态 |
| 适用场景 | 需要修改数据的场景 | 纯转发场景 |
2、性能优化参数配置
sh
# Broker端
# 单条消息最大1MB
message.max.bytes=1000012
# 网络处理线程数
num.network.threads=8
# IO处理线程数
num.io.threads=32
# 刷盘消息数阈值
log.flush.interval.messages=10000
# 刷盘时间阈值
log.flush.interval.ms=1000
# 发送缓冲区优化
socket.send.buffer.bytes=1024000
# 接收缓冲区
socket.receive.buffer.bytes=1024000
# 禁用消息校验(避免破坏零拷贝)
socket.disable.tcp.no.delay=false
# 日志分段大小(1GB)
log.segment.bytes=1073741824
# Producer端
# 批量发送大小(16KB)
batch.size=16384
# 批量发送等待时间(5ms)
linger.ms=5
# 压缩算法
compression.type=snappy
# 发送缓冲区大小(32MB)
buffer.memory=33554432
# Consumer端
# 最小拉取字节
fetch.min.bytes=1
# 最大等待时间
fetch.max.wait.ms=500
# 分区最大拉取字节
max.partition.fetch.bytes=10485763、硬件优化建议
磁盘:SSD或RAID10阵列
网络:万兆网卡
CPU:多核处理器(分区数建议与CPU核心数匹配)
4、实践建议
1)监控体系
建立Prometheus+Grafana监控大盘,关键指标
| 类别 | 指标 | 说明 |
|---|---|---|
| Producer | RequestLatencyAvg | 请求平均延迟 |
| Broker | UnderReplicatedPartitions | 未充分复制的分区数 |
| Consumer | ConsumerLag | 消费延迟消息数 |
| System | NetworkProcessorAvgIdlePercent | 网络处理器空闲率 |
2)容量规划
生产环境分区数 = max(消费者数*2, 预计峰值QPS/单分区处理能力,目标吞吐量/单分区吞吐能力)
预留20%资源缓冲
合理配置批量参数和压缩算法
3)异常处理
实现ConsumerAwareListenerErrorHandler处理消费异常
配置auto.offset.reset=latest防止重复消费
4)压测方案
sh
# 使用kafka-producer-perf-test工具压测
kafka-producer-perf-test.sh --topic test-topic \
--num-records 10000000 --record-size 1000 \
--throughput -1 --producer-props \
bootstrap.servers=localhost:9092 \
batch.size=16384 linger.ms=5二、消息积压
1、积压原因
消费速度 < 生产速度:常见于突发流量或消费逻辑复杂
分区分配不均:消费者组内负载不均衡
反序列化/业务处理异常:导致消费线程阻塞
2、预防措施
合理评估业务量,设置足够的分区数
监控消费延迟(Consumer Lag)
设置合理的消息保留时间(log.retention.hours)
3、消息分流(Shunting)处理
3.1分流策略选择
| 积压场景 | 适用分流策略 | 技术实现 |
|---|---|---|
| 突发流量激增 | 临时Topic分流 | 动态创建Topic+消费者组 |
| 消费者处理能力不足 | 分区扩容+并行消费 | 增加分区数+Consumer实例 |
| 消息处理耗时差异大 | 优先级队列分流 | 多Topic分级消费 |
| 数据冷热分离 | 时间窗口分流 | 按时间戳路由到不同Topic |
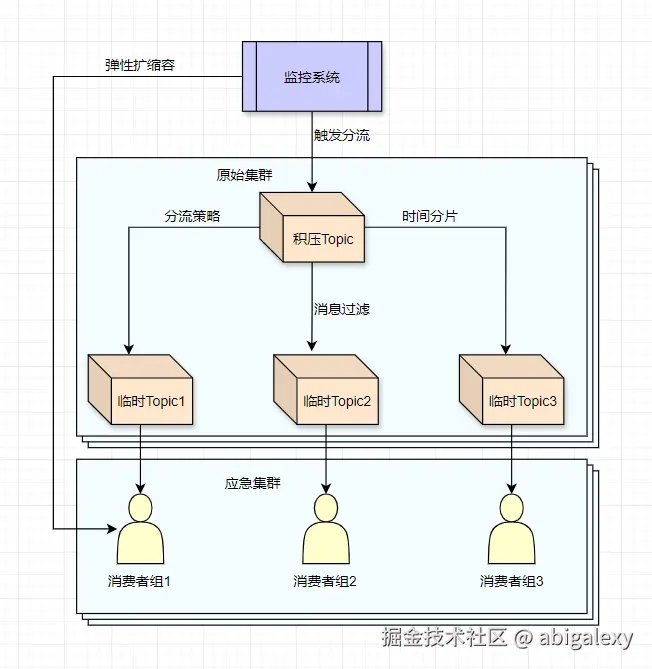
3.2方案一:动态Topic分流(应急处理)
java
// 1、监控到积压时自动创建临时Topic
AdminClient admin = KafkaAdminClient.create(properties);
NewTopic newTopic = new NewTopic("emergency-"+System.currentTimeMillis(),
10, (short)3); // 10分区3副本
admin.createTopics(Collections.singleton(newTopic));
// 2、将积压消息路由到临时Topic
@KafkaListener(topics = "${original.topic}")
public void handleMessage(String message) {
if(isBackpressure()) {
// 分流
kafkaTemplate.send("emergency-topic", message);
} else {
processNormally(message);
}
}
// 3、启动应急消费者组
@KafkaListener(
topics = "${emergency.topic}",
groupId = "emergency-group",
// 并发消费者数=分区数
concurrency = "10")
public void emergencyHandle(String message) {
// 简化处理逻辑
simplifiedProcess(message);
}3.3方案二:分区再平衡(长期方案)
1)增加原始Topic分区数(需提前规划,改变消息分布)
sh
bin/kafka-topics.sh --alter \
--topic original_topic \
--partitions 30 \ # 新分区数
--bootstrap-server kafka:90922)水平扩展消费者
确保消费者组实例数 ≤ 分区数
java
// 紧急扩容Consumer,增加消费者实例(需确保分区数≥消费者数)
Properties props = new Properties();
props.put("bootstrap.servers", "kafka:9092");
props.put("group.id", "emergency-group");
// 从最新开始消费
props.put("auto.offset.reset", "latest");
// 增加单次拉取量,每次拉取最大记录数
props.put("max.poll.records", 500);3.4方案三:消息属性分流
Producer端按消息特征路由
3.5方案四:降级处理策略
java
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
try {
// 简化处理逻辑
processSimplified(record.value());
} catch (Exception e) {
// 记录错误,跳过问题消息
log.error("Process error, skip message: {}", record.offset());
}
}
}3.6方案五:死信队列模式
java
// 消费失败超过3次的消息转入DLQ
try {
processMessage(record);
} catch (Exception e) {
if (retryCount++ > 3) {
kafkaTemplate.send("order-dlq", record);
} else {
// 重试逻辑
}
}3.7长期处理
优化消费者处理逻辑
实现消费能力弹性伸缩
建立多级消费策略(重要消息实时处理,次要消息延迟处理)
3.8关键配置优化
sh
# consumer.properties
# 单次最大拉取量
max.poll.records=500
# 单次拉取最大字节
fetch.max.bytes=52428800
# 单分区拉取量
max.partition.fetch.bytes=1048576
# broker配置
# 处理分流的IO线程数
num.io.threads=32
# 临时Topic保留时间
log.retention.hours=483.9分流工具链
1)监控预警
sh
# 实时监控积压量
bin/kafka-consumer-groups.sh --describe \
--group my_group \
--bootstrap-server kafka:90922)自动化分流决策
python
# 根据Lag值自动触发分流
if lag > 100000:
create_shunt_topic()
adjust_consumer_instances()3)数据一致性保障
使用事务消息确保分流不丢失
java
// 开启事务保证分流原子性
kafkaTemplate.executeInTransaction(t -> {
t.send("original", message);
t.send("shunt", message);
return true;
});三、高并发削峰(集成Sentinel)
1、Sentinel核心功能
流量控制(Flow Control): 根据系统容量动态调整请求流量
熔断降级(Circuit Breaking): 当下游服务不可用时自动熔断
系统负载保护(System Load Protection): 保护系统不被过载请求拖垮
实时监控: 提供实时流量监控和规则配置能力
Sentinel 与 Hystrix 类似但更轻量级,支持多种编程语言(Java、Go、C++等),并且与 Spring Cloud、Dubbo 等框架深度集成。
2、Kafka结合Sentinel实现削峰场景
生产者突发流量:当生产者突然产生大量消息时
消费者处理能力不足:消费者处理速度跟不上生产速度时
下游服务过载:消息处理需要调用其他服务,这些服务可能成为瓶颈
3、整体架构
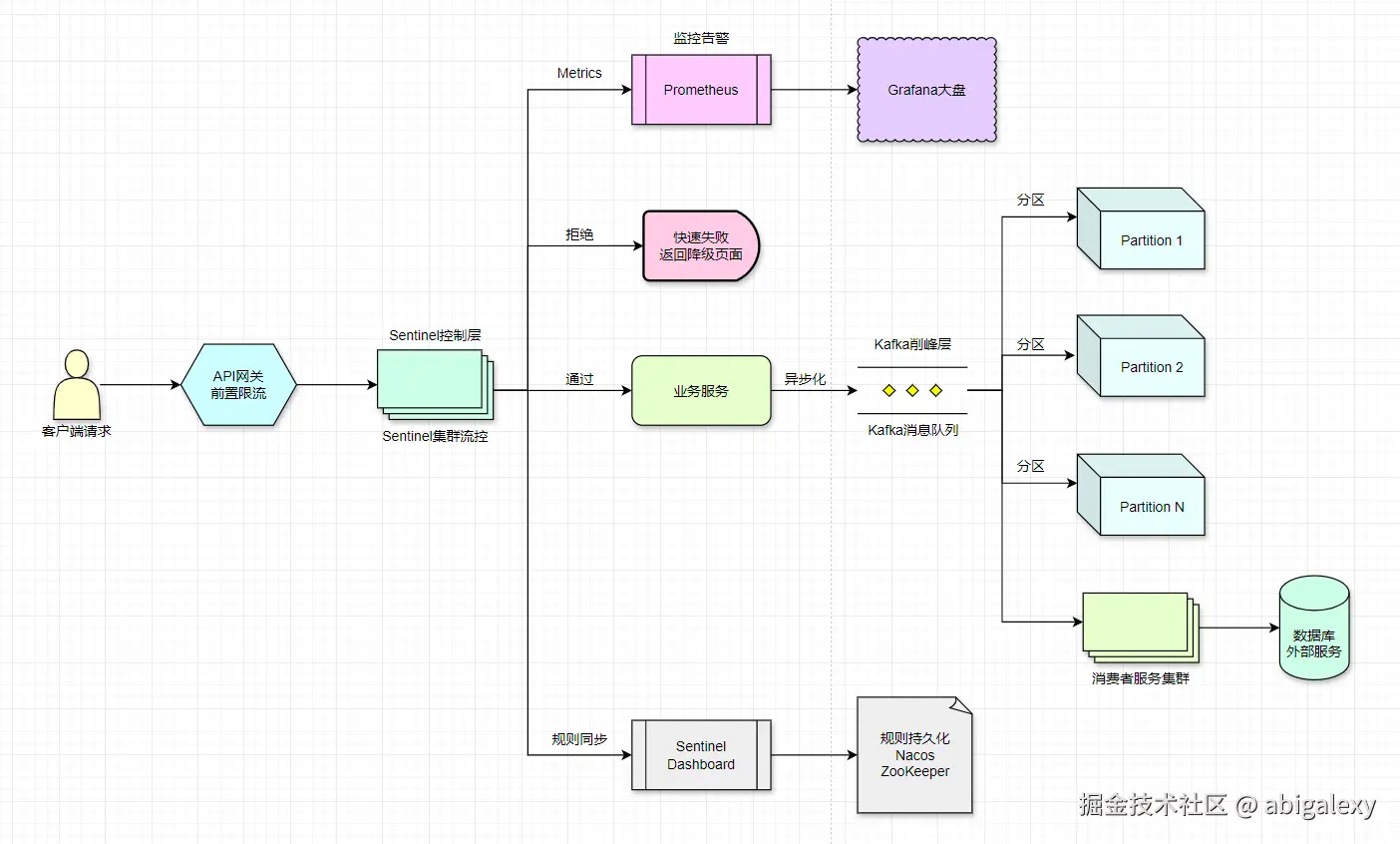
流程说明:
1)流量入口层(Sentinel前置削峰)
组件:API网关(如Spring Cloud Gateway)集成Sentinel插件。
规则配置:
QPS限制:全局阈值(如10万QPS)。
热点规则:针对秒杀商品ID单独限流。
拦截效果:超限请求直接返回429 Too Many Requests或静态降级页。
2)业务服务层(同步转异步)
通过Sentinel的请求:
生成订单/事件消息(如JSON格式)。
发送至Kafka指定Topic(注意分区设计):
java
// Sentinel通过后发送到Kafka
@SentinelResource(value = "createOrder", blockHandler = "handleBlock")
public void createOrder(OrderRequest request) {
kafkaTemplate.send("order-topic", request.getOrderId(), request.toJson());
}3)Kafka削峰层
分区设计:
分区数=消费者实例数(避免资源闲置)。
同一用户ID哈希到同一分区(保证顺序性)。
堆积能力:
磁盘存储支持高堆积(如百万级消息)。
监控Lag(消费延迟)触发告警。
4)消费者服务层
消费策略:
批量拉取(max.poll.records=500)。
线程池并发处理(但需控制并发数避免DB压力)。
Sentinel二次防护
java
// 消费者侧限流(如控制1000 TPS)
@SentinelResource(value = "processOrder", fallback = "processFallback")
public void processOrder(OrderMessage message) {
// 数据库批量写入
}5)监控与弹性
Sentinel Dashboard:
实时查看通过/拒绝的QPS曲线。
动态调整规则(如秒杀期间调低阈值)。
Kafka监控:
使用Burrow或Kafka Eagle监控Lag。
堆积时触发消费者自动扩容(K8s HPA)。
4、Sentinel与Kafka结合削峰方案
方案一:在生产者端使用 Sentinel 限流
java
// 初始化 Sentinel
FlowRule rule = new FlowRule();
// 资源名称
rule.setResource("kafkaProducer");
// 限流阈值类型(QPS)
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
// 每秒最大允许1000条消息
rule.setCount(1000);
FlowRuleManager.loadRules(Collections.singletonList(rule));
// 发送消息时
try (Entry entry = SphU.entry("kafkaProducer")) {
kafkaProducer.send(new ProducerRecord<>("topic", "message"));
} catch (BlockException e) {
// 被限流的处理逻辑
log.warn("Kafka生产被限流,消息丢弃或进入备用队列");
}方案二:在消费者端使用Sentinel限流
java
// 消费者配置
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList("topic"));
// 配置Sentinel规则
FlowRule consumerRule = new FlowRule();
consumerRule.setResource("kafkaConsumer");
// 并发线程数控制
consumerRule.setGrade(RuleConstant.FLOW_GRADE_CONCURRENCY);
// 最大并发处理消息数
consumerRule.setCount(10);
FlowRuleManager.loadRules(Collections.singletonList(consumerRule));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
try (Entry entry = SphU.entry("kafkaConsumer")) {
// 处理消息
processMessage(record);
} catch (BlockException e) {
// 被限流的处理逻辑
log.warn("消费者处理被限流,消息进入死信队列或重试");
}
}
}方案三:结合Kafka消费者组和Sentinel实现动态扩缩容
使用 Kafka 的消费者组机制实现基本的水平扩展
在每个消费者实例上配置Sentinel规则,根据系统负载动态调整处理能力
当系统负载过高时,Sentinel会自动限流,避免系统崩溃
方案四:使用Sentinel的热点参数限流
如果消息中有热点字段(如特定用户ID),可以针对这些热点参数进行限流
java
ParamFlowRule paramRule = new ParamFlowRule("kafkaConsumer")
.setParamIdx(0) // 针对第一个参数限流
.setGrade(RuleConstant.FLOW_GRADE_QPS)
.setCount(10); // 每个热点参数值最多10QPS
// 针对特定热点值设置更严格的限流
Map<String, Integer> hotItems = new HashMap<>();
// 用户hotUser123最多2QPS
hotItems.put("hotUser123", 2);
paramRule.setHotItems(hotItems);
ParamFlowRuleManager.loadRules(Collections.singletonList(paramRule));5、Sentinel核心配置
java
// 初始化资源规则
InitFunc executor = () -> {
// 限流规则:QPS>1000时触发
FlowRule rule = new FlowRule("kafka-consumer")
.setGrade(RuleConstant.FLOW_GRADE_QPS)
.setCount(1000);
FlowRuleManager.loadRules(Collections.singletonList(rule));
// 熔断规则:异常比例>10%时熔断
DegradeRule degradeRule = new DegradeRule("kafka-consumer")
.setGrade(RuleConstant.DEGRADE_GRADE_EXCEPTION_RATIO)
.setCount(0.1)
.setTimeWindow(10);
DegradeRuleManager.loadRules(Collections.singletonList(degradeRule));
};
FlowRuleManager.register2Property(executor.getProperty());6、多级削峰策略
1)前端削峰
按钮防重复点击
验证码/排队页面
2)网关层削峰
Spring Cloud Gateway限流配置
yml
spring:
cloud:
gateway:
routes:
- id: order-service
uri: lb://order-service
predicates:
- Path=/api/order/**
filters:
- name: RequestRateLimiter
args:
redis-rate-limiter.replenishRate: 100 # 每秒令牌数
redis-rate-limiter.burstCapacity: 200 # 令牌桶容量3)消息队列削峰
合理设置Kafka分区数
动态调整Consumer实例数
4)业务处理削峰
异步处理非核心流程
数据库批量写入
扩展优化
Kafka分区自动扩容:根据流量自动增加分区。
混合策略:Sentinel漏桶算法 + Kafka时间窗口聚合。