那网络游戏中呢,比如王者荣耀的摇杆移动,如果GPU就是渲染的太慢了,1秒只渲染了一帧呢?cpu还可以做到完整的接受玩家的移动输入吗
是的,即使 GPU 卡得要死,CPU 仍然可以正常接收并处理玩家输入,只是最终"反馈显示"会延迟甚至卡住。
OS层:Android/iOS 的 input 系统
↓
Unity / 自研引擎 input 系统(Update 阶段轮询)
↓
逻辑处理:移动角色、发起技能
这些都发生在 CPU 主线程 → 脚本 Update → 不需要 GPU 参与
所以哪怕 GPU 完全卡住了、没画出来、只有 1FPS,输入本身是能被接收到的。
王者荣耀等网络游戏还加入了输入预测与网络补偿
尤其是竞技游戏,为了保证响应性和"可玩性",引擎中会做:
-
客户端输入预测:即使服务器没回,你的角色也先在本地"动起来"
-
逻辑帧驱动 vs 渲染帧解耦:服务器按固定逻辑帧推进,不依赖客户端帧率
-
输入缓冲机制:即便你掉帧,系统也会采集并缓存你的多个输入点
所以你摇杆一滑,即使你画面卡着不动,后台仍在接收、处理、同步、移动角色逻辑位置,只是你没看到而已。
tangent.w是 切线空间正交性所必需的信息 ,它的值 = 副切线方向的符号(+1 或 -1) ,绝对不能省略,也不能由 shader 自己"推出来"。
Unity 不封装它,是因为:
只有模型导入时能计算出这个符号信息(w 分量),shader 运行时无法推导出来。
也就是说,这个w决定的是点乘这个公式的产生方向,是可以颠覆原来的顺逆时针的规则的
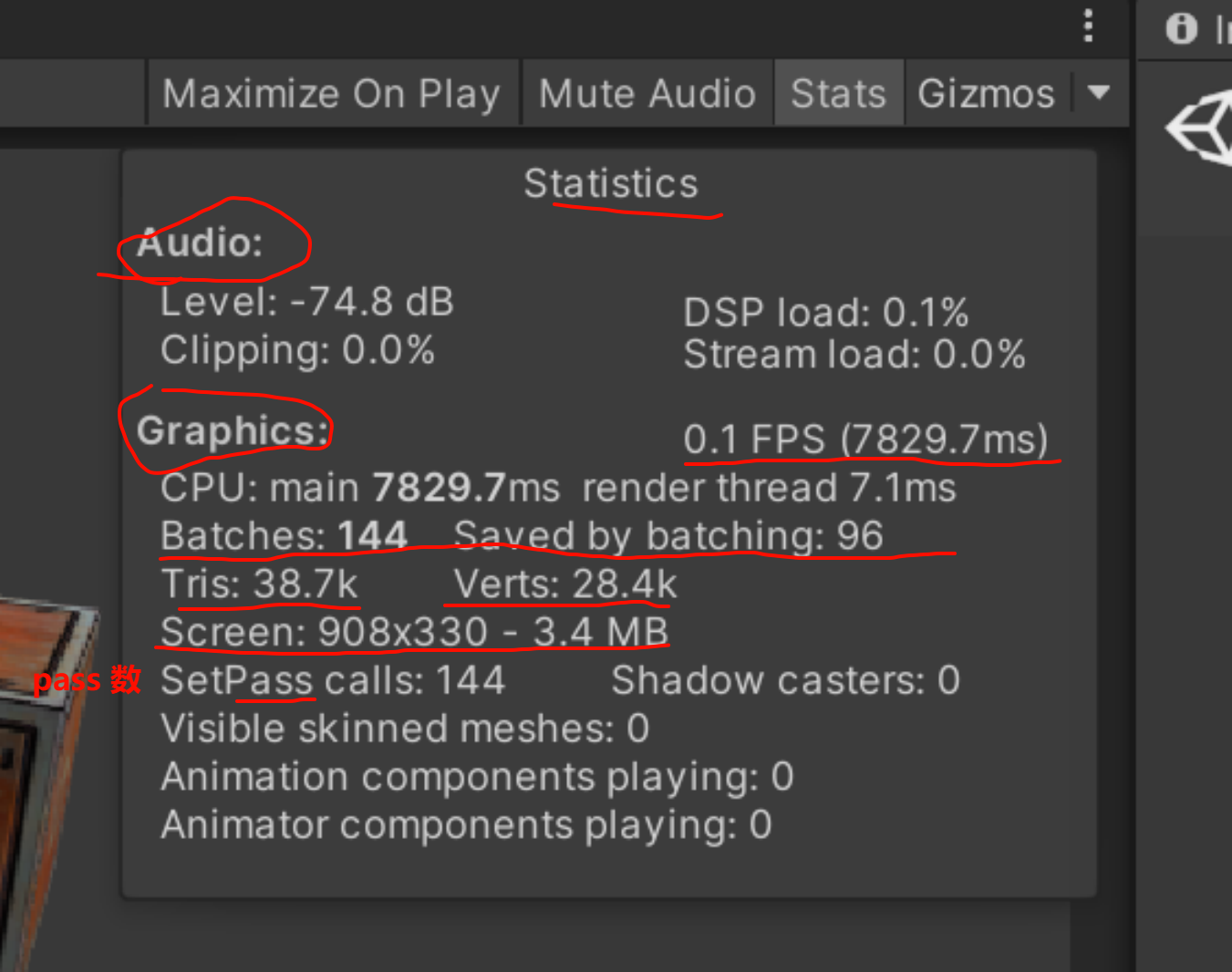
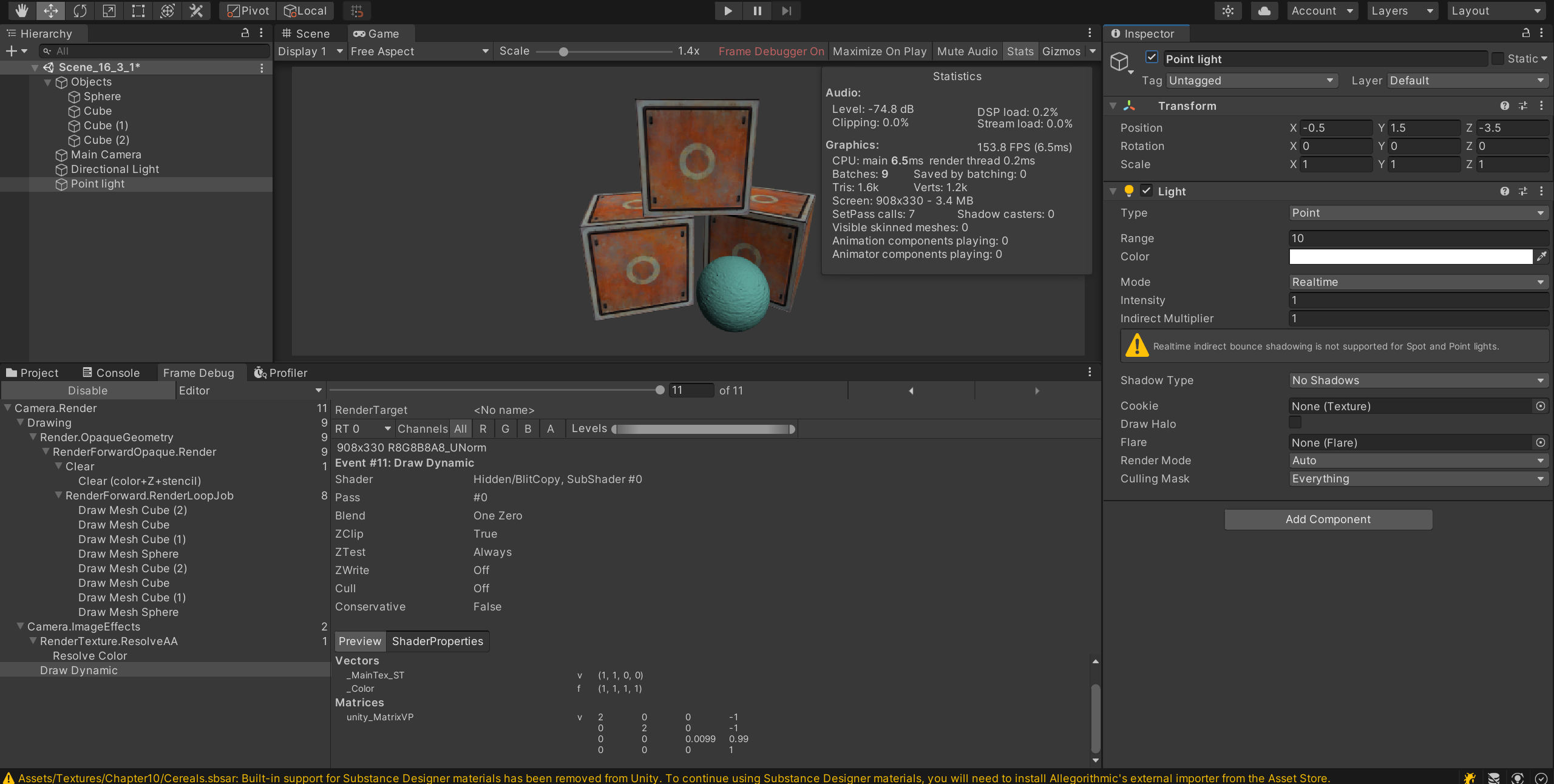
开启点光源之后,里面的save by batching完全消失了
多个pass的shader里,在需要应用多个光照的时候,就破坏了unity的动态批处理
因为不能batching了,所以四个物体,每个物体被directional 和point light影响,产生了2x4=8个dc

static的结果
Unity 的某些版本确实在 Profiler 里显示过 VBO Total(Vertex Buffer Objects 总数)**这一指标,尤其是在 Unity 5.x ~ 2019 LTS 之间的一些编辑器版本中。
从 Unity 2020.x 开始:
-
Unity 渐渐弱化对 OpenGL 概念模型的暴露
-
Universal Render Pipeline (URP) 和 SRP 更加抽象化了底层渲染结构
-
加上现代 GPU 的 buffer 管理越来越统一(多个 Mesh 可共享 VBO 区块)
-
Unity Profiler 的 Rendering 模块逐步统一为更通用的指标(如 batches、vertices、GPU memory)
因此,VBO Total 被移除或隐藏,你现在用的是 2020 或以上版本,就基本看不到它了。
GPU粒子的实现原理和ComputeShader GPU Instance 的基础应用。花最少的时间,了解粒子系统的核心奥义_哔哩哔哩_bilibili
看爽了,Compute Shader 基础知识点:
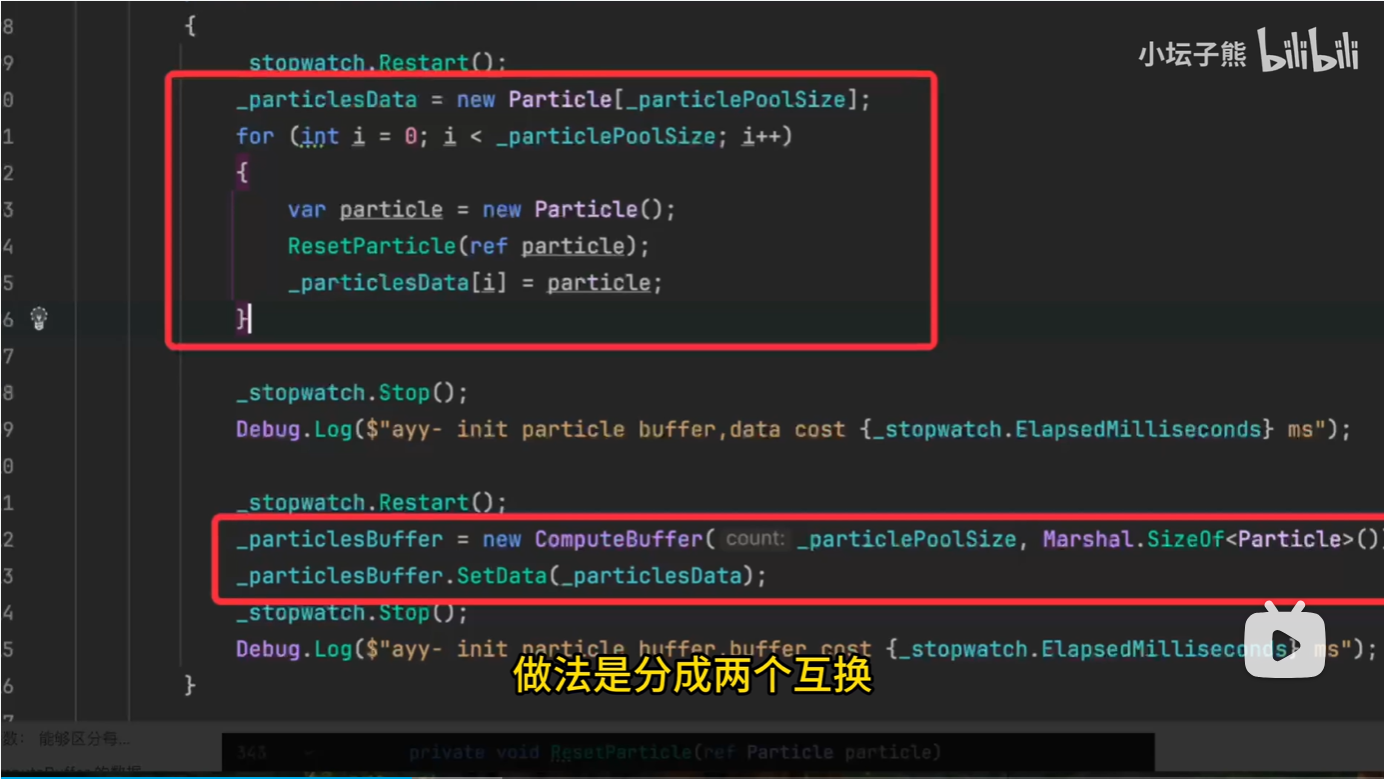
_particlesData = new Particle_particlePoolSize;
-
你需要先在 C# 端用结构体 Particle 创建粒子池数据。
-
每个
Particle是你自定义的结构体,必须能和 HLSL 里的结构一一对齐(字段顺序、对齐方式要匹配)。
ResetParticle(ref particle);
_particlesDatai = particle;
把每个粒子结构体初始化。通常会设置位置、速度、生命周期等。
_particlesBuffer = new ComputeBuffer(count, stride);
count:粒子数量。
stride:单个粒子结构体的字节大小 ,用 **Marshal.SizeOf<Particle>()**来获取。
这是把结构体数组包装成 GPU 可访问的 buffer,作为 Compute Shader 的输入或输出。
_particlesBuffer.SetData(_particlesData);
这一步是关键:把 CPU 上的数组数据传入 GPU 的 ComputeBuffer。
后面你在 compute shader 里就可以通过 ++StructuredBuffer<Particle>++ 或 ++RWStructuredBuffer<Particle>++来读写它了。
-
如果你要从 compute shader 回传结果回 CPU,你该怎么做?
-
ComputeBuffer 用完后需要做什么释放操作?
所以说最重要的,目前是知道自己可以实现什么,这个过程再继续深入,,如果没有想做的结果出来,一切都白谈
所以视频重要的点是告诉我这个方向可以去实现,而不是一直躲在基础知识后面反复,,,,
自己要有出效果的思考重心,如果可以作为技术效果,那才纳入知识区域的一种高度分明
看更多的案例,,
冯说的固定管线相关的人
xxx
开启和关闭透明度测试,和透明度混合
首先处理的对象是当前的这个pass,对于当前的颜色缓冲区里的颜色的处理方式
一个是通过pass内判断alpha值,然后决定是否丢弃当前的这个像素
blend则是选择与颜色缓冲里的值的处理方式,少了灵感,
但至少来说,核心的pass可以写成一个,一个shader里执行一个pass,要么就是2个,另一个额外做辅助的效果
所以pass数量是可以估计,pass是有核心的,是可以间隔shader之间的分析的
顶点的位置是可以修改的,即使是surface shader里面,顶点shader 的vertex函数也是存在的
不在定点上移动,一般来说是不合适的
还有finalcolor的修改函数,在单个shader之中
那整体来说是单个pass的,也就是说surface shader的使用范围就是基本的现实物体,如果要自定义风格的去做效果出来,则很不方便
默认情况下,一个方向光
带顶点动画的shadowpass要自己修改
surface shader里的关键词就是所有的想法去看一遍
xxxx
想象中也不会太难,这倒是很简单就做掉了
应该想想别的要实现的东西了,,交互水,交互雪地,交互草地,交互火,粒子效果,鱼群的效果
真是有够多的,,
Unity常用的粒子的Shader的解读_哔哩哔哩_bilibili
官方教程实现
Logo消融特效
https://connect.unity.com/p/shi-yong-li-zi-shi-xian-logoxiao-rong-xiao-guo
倒放粒子特效
https://connect.unity.com/p/dao-fang-li-zi-xi-tong
【Unity Shader】3D模型的粒子消散_哔哩哔哩_bilibili
溶解的过程中加上粒子的dissolve 和额外的一个粒子组件,凑在一起达成效果,但这是拼凑出来的
赛尔达里面的传送也是这样做的,也不会完全感觉到异常的
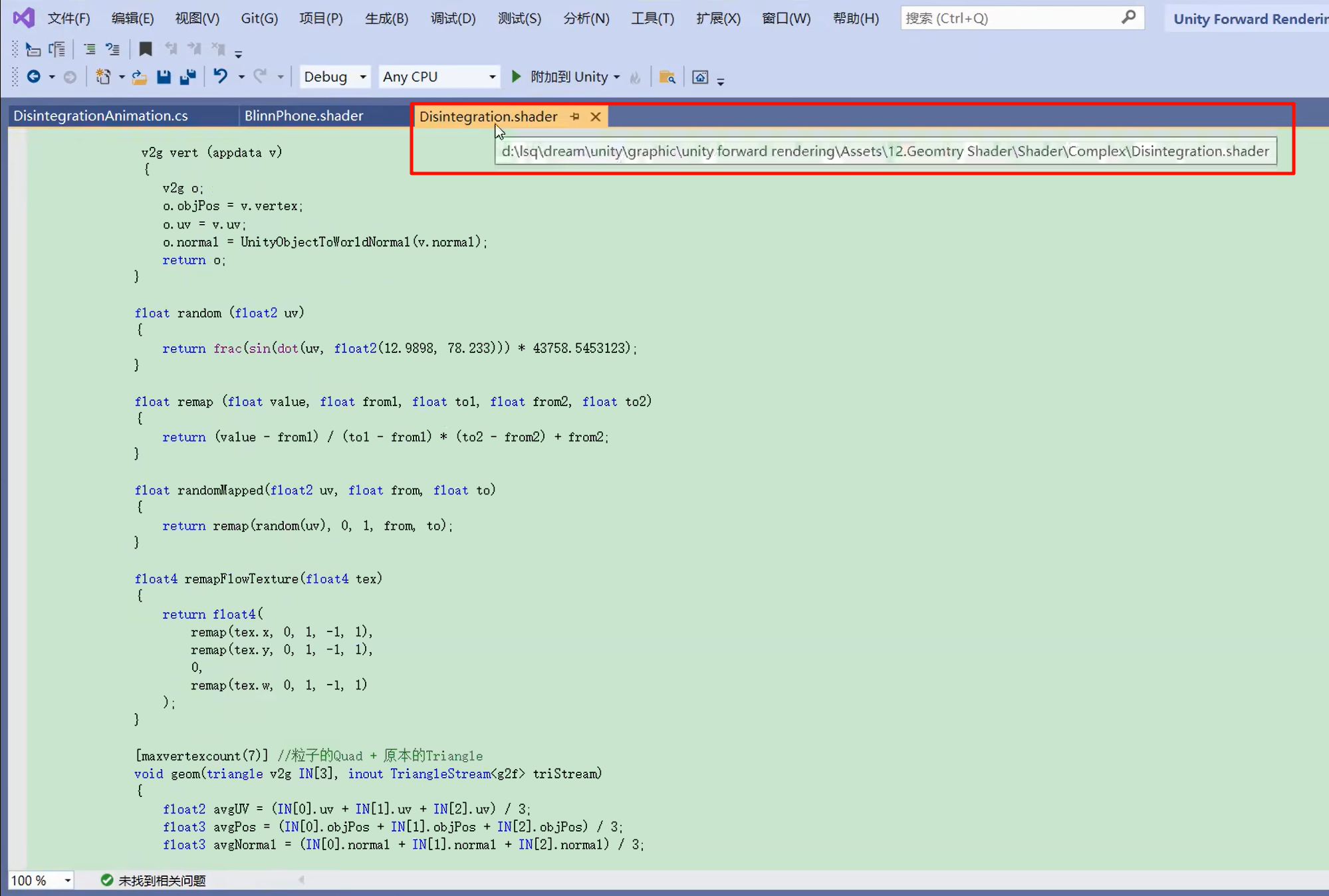
源码:https://gitee.com/luoxiaoc/tutorial-source-code/raw/master/Disintegration.unitypackage
guan方最权威参考:Microsoft Learning
Geometry-Shader Object(几何着色器函数)
涵盖了如下内容:
-
[maxvertexcount(n)]声明了几何着色器 最多输出 n 顶点,编译器据此分配资源和验证输出数量; -
函数签名格式:
To make the triangles appear as flat as they really are,
we have to use the surface normals of the actual triangles.
It will give meshes a faceted appearance, known as flat shading.
还是太难看了,语义不同,
如何声明输出三角形流以及两大内置方法:
-
Append(...):发送一个顶点输出; -
RestartStrip():结束当前三角形条,开始一条新的; -
类型示例:
inout TriangleStream<g2f>,表示输出类型为 structg2f(vs→gs→fs 过渡); -
TriangleStream 只用于几何着色器(SM4.0+),Unity CG/ShaderLab 中使用普遍。
Stream-Output Object - Win32 apps | Microsoft Learn
Unity 上实战解析:Catlike Coding(Advanced Rendering 系列)
该系列从 Unity ShaderLab + CG 的角度,详细展示了完整 geometry shader 编写流程:
-
第一步说明如何通过
#pragma geometry启用 GS; -
接着演示为何 必须写
[maxvertexcount(3)]才能通过编译; -
然后用
triangle MyInType v2g[3]来接收三角形; -
接着用
inout TriangleStream<MyInType>输出一组三角形顶点; -
最后演示
.Append(i[0])....Append(i[2])发送顶点。这些解析位于其教程中 GS 代码部分,清楚展示每行含义:
启用 Geometry Shader 阶段
为了使用几何着色器(Geometry Shader),Shader必须设置为至少 Shader Model 4.0。在 Unity 中,你可以这样显式指定:
#pragma target 4.0
#pragma geometry MyGeometryProgram
这样做会告诉编译器,将 MyGeometryProgram 纳入到渲染管线中作为 Geometry Shader 使用。
Geometry Shader 每次被调用时需要声明 最多能输出多少顶点。例如:
maxvertexcount(3)
void MyGeometryProgram(...) { ... }
这意味着:当前命令最多产生 3 个顶点(即一个三角形)。Unity 使用这个注解来验证输出是否合法,并为着色器分配相应的输出缓冲区。
[maxvertexcount(7)] 是告诉编译器:这个几何着色器(Geometry Shader)在每次被调用时,最多能输出 7 个顶点 。这个信息 HLSL 在编译时用来为输出流(如 TriangleStream<...>)预先分配缓冲区,运行时也会检查 .Append(...) 的数量不能超过这个限制。"
Geometry-Shader Object - Win32 apps | Microsoft Learn
-
资源预分配:GPU / 驱动程序必须在调用 GS 之前知道最大潜在输出顶点数,以分配临时缓冲。
-
运行时检查 :如果你
.Append(...)的次数超过了这个数,编译器/驱动会报错(尤其在 Direct3D 环境下)。 -
即使实际输出比上限少,也不会出错 ------ 只是不能超过。
假设你写的几何着色器是这样的:
-
输入一个三角形(3 顶点)
-
然后扩展为一个 Quad(用 2 个三角形 = 6 顶点)
-
最后还要再保留原三角形中的一个顶点(或其他顶点)
总顶点数 = 6(Quad) + 1 = 7。
这时就必须设置:
cpp
[maxvertexcount(7)]
void geom(triangle v2g IN[3], inout TriangleStream<g2f> triStream)
{ ... }这样你的 .Append(...) 调用不能写超过 7 次。
这就是"声明最大输出顶点数"真正的含义。如果你觉得自己 .Append(...) 顺序不稳定,也可以先估算最大可能值写大一点(比如 12、24),但不建议超过 1024(DirectX 的资源限制)
There is a resource limit in directX that limits the number of scalar components that can be emitted by a geometry shader instance to 1024
maxvertexcount(N) 是一个最大上限 声明;但你绝对不能输出超过 N 顶点,否则程序会拒绝执行。
同一次 Geometry Shader 调用,隐藏存在一个由编译器/驱动预分配 的"输出缓存";
编译期,它需要知道"最多可能输出多少顶点";
.Append() 超限,就容易破坏缓存机制,驱动必须检测并报错
只真的输出少量顶点,低于上限------这是允许也是正常的流程
dcl_maxOutputVertexCount (sm4 - asm) - Win32 apps | Microsoft Learn
cpp
[maxvertexcount(7)]
void geom(triangle v2g IN[3], inout TriangleStream<g2f> triStream)
{
// 假设你只拼 2 个三角形共 6 顶点
for (int i = 0; i < 6; i++)
triStream.Append(...);
triStream.RestartStrip();
}
这段代码中 .Append(...) 总数是 6(少于 max=7)
→ ✅ 编译与运行都没问题。for (int i = 0; i < 8; i++)
triStream.Append(...);
因为 8 > 7,编译器或 GPU 将报错(运行要么崩要么报 "Exceeded max vertex count")。
-
实际输出顶点数量 × 每顶点的标量属性数量(如位置 + UV + 法线...)有绝对上限;
-
一旦
.Append()超出限定数量,编译器或 GPU 驱动就会报错或忽略输出; -
若真的需要吐出成百上千个三角形,你必须靠 Shader Model 5 的 GS Instancing 多次调⽤。
https://stackoverflow.com/questions/24082570/geometry-shader-maxvertexcount-cannot-be-known
GPU 必须保持输出三角形 输入-输出的执行顺序一致,以满足管线的帧同步和驱动的排序需求。
设定的上限远远高于实际使用(比如设成 256 但你只输出 4),GPU 为它留了空白,但不会高效利用;反过来,设定太小(甚至等于实际),未能应对某些 edge case,也会报错。
cpp
void geom(triangle v2g IN[3], inout TriangleStream<g2f> triStream)
{
float2 avgUV = (IN[0].uv + IN[1].uv + IN[2].uv) / 3;
float3 avgPos = (IN[0].objPos + IN[1].objPos + IN[2].objPos) / 3;
float3 avgNormal = (IN[0].normal + IN[1].normal + IN[2].normal) / 3;
//随噪声溶解效果的消散
float dissolve_value = tex2Dlod(_DissolveTexture, float4(avgUV, 0, 0)).r;
float t = clamp(_Weight * 2 - dissolve_value, 0, 1);
//产生更多的随机性
float2 flowUV = TRANSFORM_TEX(mul(unity_ObjectToWorld, avgPos).xz, _FlowMap);
float4 flowVector = remapFlowTexture(tex2Dlod(_FlowMap, float4(flowUV, 0, 0)));
float3 pseudoRandomPos = (avgPos) + _Direction;
pseudoRandomPos += (flowVector.xyz * _Exapnd);
//控制位置和大小随消散效果变化
float3 p = lerp(avgPos, pseudoRandomPos, t);
float radius = lerp(_ParticleRadius, 0, t);
//构建一个广告牌QUAD
if (t > 0) //消散的部分
{
//让消散的粒子始终朝向摄像机,使用摄像机空间的坐标轴
float3 right = UNITY_MATRIX_IT_MV[0].xyz;
float3 up = UNITY_MATRIX_IT_MV[1].xyz;
//得到QUAD四个点的位置(沿着摄像机空间的坐标轴偏移)
float4 v[4];
v[0] = float4(p + radius * right - radius * up, 1.0f);
v[1] = float4(p + radius * right + radius * up, 1.0f);
v[2] = float4(p - radius * right - radius * up, 1.0f);
v[3] = float4(p - radius * right + radius * up, 1.0f);
//构建QUAD的顶点:位置和UV一一对应
g2f vert;
vert.pos = UnityObjectToClipPos(v[0]);
vert.uv = float2(1.0f, 0.0f);
vert.normal = UnityObjectToWorldNormal(avgNormal);
vert.worldPos = mul(unity_ObjectToWorld, v[0]);
triStream.Append(vert);
vert.pos = UnityObjectToClipPos(v[1]);
vert.uv = float2(1.0f, 1.0f);
vert.normal = UnityObjectToWorldNormal(avgNormal);
vert.worldPos = mul(unity_ObjectToWorld, v[1]);
triStream.Append(vert);
vert.pos = UnityObjectToClipPos(v[2]);
vert.uv = float2(0.0f, 0.0f);
vert.normal = UnityObjectToWorldNormal(avgNormal);
vert.worldPos = mul(unity_ObjectToWorld, v[2]);
triStream.Append(vert);
vert.pos = UnityObjectToClipPos(v[3]);
vert.uv = float2(0.0f, 1.0f);
vert.normal = UnityObjectToWorldNormal(avgNormal);
vert.worldPos = mul(unity_ObjectToWorld, v[3]);
triStream.Append(vert);
}
else //原本的顶点,并把世界坐标的w设置为-1作为区分
{
for (int j = 0; j < 3; j++)
{
g2f o;
o.pos = UnityObjectToClipPos(IN[j].objPos);
o.uv = TRANSFORM_TEX(IN[j].uv, _MainTex);
o.normal = UnityObjectToWorldNormal(IN[j].normal);
o.worldPos = float4(mul(unity_ObjectToWorld, IN[j].objPos).xyz, -1);
triStream.Append(o);
}
}
}都是 Microsoft Direct3D(或包含 Cg/HLSL)规范里的标准,与你是否在 Unity 无关,只要你的编译器支持 SM4.0+ 都能运行。
核心特性包括:
| 语法或关键字 | 说明 |
|---|---|
[maxvertexcount(7)] |
声明每次 Geometry Shader 最多输出 7 个顶点,用于输出缓冲区预分配和运行时检查 Unity Documentation+7Unity Documentation+7Unity Documentation+7Unity Documentation+1Unity Documentation+1 |
void geom(triangle v2g IN[3], inout TriangleStream<g2f> triStream) |
标准 HLSL 的几何着色器签名:接收三角形输入数组,输出顶点流 Microsoft LearnMicrosoft Learn |
.Append(...)、.RestartStrip() |
Geometry Shader 特有函数,控制顶点流生成和 Primitive Strip 划分 Microsoft LearnMicrosoft Learn |
triangle、TriangleStream<T>、数组 [3] |
规范定义的输入原语(Primitive Type)和输出流机制 Microsoft LearnWikipedia |
这些是 Unity 为了简化 Shader 写法,封装在 UnityCG.cginc 或 Core.hlsl 等内置 include 文件里的宏名、矩阵名、统一变量,Unity 以外就不存在:
-
UNITY_MATRIX_IT_MV、unity_ObjectToWorld、UNITY_MATRIX_MVP等由 Unity 自动传入的内置 MVP、Model、IT‑MV 矩阵变量; -
UnityObjectToClipPos(...)、UnityObjectToWorldNormal(...)等 Unity 内置函数宏,经编译器会被替换成矩阵 * 顶点 向量等操作 Unity Documentation+8Unity Documentation+8Unity Documentation+8; -
TRANSFORM_TEX(...),自动处理 tiling+offset 的 Unity 纹理坐标宏,同样只存在 Unity 内置宏库中 Unity Documentation+4Unity Documentation+4Unity Documentation+4; -
Unity 特有 ShaderLab property 变量如
_Exapnd、_FlowMap、_Weight、_ParticleRadius等,在 Unity 材质 inspector 中定义的属性; -
tex2Dlod(...)在 Unity 中是合法的(CG 语法兼容),但它作为 Unity Shader 的内嵌函数,其工作效果需要结合 Unity 绑定的 Texture 在 SRP/Builtin RP 管线中生效。
换言之,你如果把完整 shader 源码复制到普通的 D3D11 工程中(不带 Unity 头文件),所有 Unity 宏 都 不可识别,需要手动替换为:
-
自己的矩阵 uniform(如
uniform float4x4 UNITY_MATRIX_MVP;替换为你自己传入的modelViewProj矩阵); -
纹理坐标处理和
tex2Dlod()调用换为 HLSL 的Texture2D.SampleLevel(...),并使用Texture2D _DissolveTexture; SamplerState _Sampler;; -
世界空间和法线变换,用
mul(...)手工写等价于 UnityObjectToWorldNormal。
tex2Dlod(u, float4(tex, 0, 0))
HLSL 标准函数,用于按绝对 LOD(mipmap)纹理采样。常用于 Vertex 或 Geometry 阶段中的纹理获取,因为普通 tex2D 在这些阶段常无法使用。
Shader 中确实只有结构体没有类(class)
triangle
-
不是结构体、类,也不是你自己写的类型。
-
它是 HLSL 语法中的一个关键字 (PrimitiveType) ,用来指定 几何着色器 (Geometry Shader) 接收的输入顶点原语类型。
-
triangle IN[3]表示该几何着色器每次被调用会接收到一个三角形------也就是3 个顶点数据组成的数组。 -
这个关键字属于 HLSL/Direct3D 的 Shader Model 4 规范,是编译器语义解析的一部分,不允许用作变量名或结构体名。Microsoft Learn+1Microsoft Learn+1Microsoft Learn+5Microsoft Learn+5Microsoft Learn+5
TriangleStream<g2f>
-
也不是类或结构体,而是一种 HLSL 提供的预定义"输出流类型"(Stream‑Output Object)。
-
使用 模板语法 ,
TriangleStream<g2f>指的是一种 按三角形结构输出顶点数据的输出管道 ,g2f是开发者自定义的结构体,定义了每个输出顶点的属性(如位置、UV、世界法线等)。 -
在几何着色器中,通过调用
triStream.Append(...)向该流中逐个添加顶点;通过triStream.RestartStrip()重启条带(Strip)以控制三角形拓扑结构。Microsoft Learn+4Microsoft Learn+4Microsoft Learn+4 -
HLSL 共定义了三种此类流对象:
-
PointStream<T>--- 用于输出点列表; -
LineStream<T>--- 用于输出线条条带; -
TriangleStream<T>--- 用于输出三角形条带。Microsoft Learn+5Microsoft Learn+5Microsoft Learn+5
-
| 名称 | 类型 | 来源 & 作用 |
|---|---|---|
triangle |
关键字 | HLSL 原生关键字 ,告诉编译器当前输入原语是三角形 |
inout TriangleStream<g2f> |
模板类型 | HLSL 内置输出流类型,用于从 GS 向后续阶段输出顶点 |
-
Vertex Shader 输出一系列顶点数据,带有
v2g结构体标签; -
Geometry Shader 接受每组三个
v2g为输入(由triangle标识):
void geom(triangle v2g IN3, inout TriangleStream<g2f> triStream)
geom() 内部,你可以:
triStream.Append(v0);
triStream.Append(v1);
triStream.Append(v2);
triStream.RestartStrip();
来构建条带拓扑,每组三角形都必须不超过 maxvertexcount(...) 的预设上限。
-
triangle➝ 是写在函数定义里的 固定语法关键字,不是 struct/union 等"数据类型"; -
TriangleStream<g2f>➝ 是 HLSL 所定义的 输出流类型,相当于一个"泛型容器",不是结构体,而是一种管线控制层面的类型声明;
这正是几何着色器语义中必不可少的要素:定义输入原语类型 + 声明输出流类型与输出数据结构。
支持的 PrimitiveType 类型与对应输入数组长度如下:
| PrimitiveType | 描述 | 数组长度 NumElements |
|---|---|---|
point |
点原语 | [1] |
line |
线段/线带 | [2] |
triangle |
三角形/三角带 | [3] |
lineadj |
附属线带 | [4] |
triangleadj |
附属三角形(拓扑) | [6] |
TriangleStream<g2f>,,,,TriangleStream<T>定义 Geometry Shader 的 输出流对象(Stream-Output Object)
构造好的顶点"流式推送"到 GPU 渲染管线中的下一阶段(通常是 Rasterizer → Fragment Shader)
不是 struct/class:它是语义层面上的"输出流类型",类似 C# 的泛型容器,但无法用来封装逻辑。
如 inout TriangleStream<g2f> triStream 表明:输出由你定义的结构体 g2f(通常含 pos, normal, uv 等)构成顶点格式,每次 .Append(vert) 都将一个顶点加入输出流中。
struct v2g { ... }; // 从 Vertex 到 Geometry 的输入格式
struct g2f { ... }; // 从 Geometry 到 Fragment 的输出格式
maxvertexcount(N)
void geom(
triangle v2g IN3, // 输入为三角形(3个顶点)
inout TriangleStream<g2f> triStream // 输出三角形流
)
{
...
triStream.Append( g2f_vertex );
...
triStream.RestartStrip();
}
-
triangle控制输入原语; -
IN[3]指明数组长度(primitive size); -
TriangleStream<g2f>是对输出顶点组类型的封装; -
.Append(...)添加输出顶点; -
.RestartStrip()标志三角形条带结束,准备下一个条带。 -
整个函数没有返回值;输出由 triStream 驱动。
都是 Geometry Shader 特有的设计语义。
"为什么
geom(...)的输入是三角形(triangle IN[3])?"
这个问题的核心,在于 Geometry Shader(GS)阶段操作的是"整个原语(primitive)",而非单个顶点 。其中 triangle 在 HLSL 中是一个关键字,用来明确 GS 接收的原语类型是三角形(3 个顶点为一组)。
GPU 渲染中,Vertex Shader 完成顶点变换后,会进入 Primitive Assembly 阶段
将顶点组装成基本图元Primitive
常见的图元就有:
-
Points(点)
-
Lines(线段)
-
**Triangles(三角形)---**三个顶点总能组成平面
Geometry Shader 位于顶点与光栅化之间,它接受 一个完整的原语作为输入。
比如,若顶点着色器输出的是一个三角形列表(TriangleList),那么 GS 每次调用就会得到 整组三角形顶点(共3个)
triangle v2g IN3 也就是说如果是line v2g IN里就是2,因为一个单独的primitive就是两个顶点组成的?是的,你理解得完全正确------
当输入 primitive 类型改为 line 时,几何着色器(Geometry Shader)中的输入数组长度也会从 3 改为 2。也就是说,如果你希望以线段为输入,就得写:
void geom(line v2g IN2, inout LineStream<g2f> stream)
IN[2] 表示:每次调用 geom() 会接收到一个线段原语,由两个顶点组成;
LineStream<g2f> 则是输出线流类型,对应 2D "线"的输出拓扑。
https://www.youtube.com/watch?v=CaPYw5ts2Yg
可交互的樱花特效,樱花特效随机移动,然后角色的移动会扰动樱花花瓣的移动
geom()(Geometry Shader)被调用的次数确实与 vert(Vertex Shader)和 frag(Fragment Shader)不同 ,其调用频率取决于 所处理的"原语 (primitive)"数量,而不是顶点或像素数量。
| Shader 阶段 | 调用频率依据 | 示例说明 |
|---|---|---|
Vertex Shader (vert) |
每个顶点一次(appdata 输入) |
若你渲染 6 个顶点,VS 会被调用 6 次 |
Geometry Shader (geom) |
每个原语一次(由拓扑类型决定) | 渲染三角形:每 3 个顶点构成一个三角形 → GS 调用一次 |
Fragment Shader (frag) |
每个像素/样本一次(裁切 & 采样后) | 取决于图元覆盖的屏幕像素数,会调用大量次 |
-
只要你画的网格是 TriangleList(Unity 默认),那么每三个顶点组成一个三角形原语;
-
如果你渲染了 1000 个三角形,
geom()就会被调用 1000 次; -
而
frag()的调用次数则更高,取决于每个三角形覆盖了多少像素;超过 100 万像素的画面很常见。
渲染流程中,VS → (Tessellation)→ GS → Rasterizer → FS 是静态固定顺序 ------ GS 必须等 VS 输出完毕,FS 必须等 GS 输出后才能执行
你的 HLSL 代码中,每个 triStream.Append(...) 输出顶点的顺序,必须与你的 .RestartStrip() 分隔形式对应原语的想法一致 。最终 GPU 保证按你在同一次 GS 调用里写入数据的顺序发往 rasterizer,而不会被其他 GS 调用插入。输出顺序封装在 SMT 调度层面。不过,不同 GS 调用之间的执行顺序不保证稳序;系统可能提前执行调用 B 的附加代码响应任务调度。
-
视图空间进行 Tile-Based、面片缓存合并和 Early Z 测试;
-
GPU 在进行 FS 时,会对同一像素可能来自多个三角形的 fragment 运行深度/stencil 测试,才能判断哪一个最终写入。
-
开启 Depth-Pre-Pass / MSAA / Conservative Rasterization 等设置会影响 FS 的调用频率与时机。
渲染排序(如"画深度近的先"或启用"Multi-Layer")会调整 FS 处理顺序,但仍受 GPU 决定。
-
Dissolve 驱动:每个三角形片段采样噪声贴图,决定该片段是否"该消散";
-
位置偏移 :当进入溶解阶段(
t > 0),粒子逐渐从 avgPos 朝着 pseudoRandomPos 位移; -
尺寸渐变:半径按 t 缩小,对粒子视觉上产生"消散减淡"的感觉;
-
Flow + Direction 作用是避免所有粒子都向同一方向移动而造成单调感;
-
最终在 GS 中用 billboard quad 来输出粒子时,就把
p和radius当顶点位移。这样效果更自然、有风动感,也更有层次。
Implementing a Dissolve Effect with Shaders and Particles in Three.js | Codrops
对于 triangle 原语,geometry shader 每次接收整组三角形,不会拆分位置或重排序。
每个调用的 IN[0]~IN[2] 是 draw call 中连续的三角形顶点,最后不满 3 顶点的部分会被忽略 Stack Overflow
假设你的 mesh 有 6 个顶点索引(TriList):[0, 1, 2, 3, 4, 5]。
-
VS 会被调用 6 次,分别处理索引 0~5 的顶点;
-
Geometry Shader 被调用 2 次:
-
第一次得到
IN = { v2g(vert0), v2g(vert1), v2g(vert2) } -
第二次得到
IN = { v2g(vert3), v2g(vert4), v2g(vert5) }
-
-
每个
geom()你拿这三者算 avgPos / avgUV / avgNorm,生成 billboard quad 或 dissolve 粒子; -
Fragment Shader 在实际光栅化的每个像素被调用无数次,由三角形覆盖区域和采样率决定(与 GS 调用次数完全不同);
底层 GPU 调度可能是大批量 dispatch VS / GS / FS,但每个 geom() invocation 内部的 IN[0]~IN[2] 从属关系与顺序则是精确和稳定的
Geo 阶段的定位 & 负责什么 🎯
-
在标准 GPU 渲染流水线中:
Vertex Shader → 入栈 Primitive → Rasterizer → Fragment Shader如果加上 Geometry Shader(GS),流程变为:
Vertex → GS → Rasterizer → Fragment 。GS 接收 整组 Primitive (例如:3 个顶点构成一个三角形),它可以决定:摒弃它、原样传递、或用更多/更少的 Primitive 替换它 ------ 也就是所谓的"几何扩展"能力 ogldev.org。
-
声明
[maxvertexcount(7)] triangle ... IN[3]表明这个 GS 将"每次"接收一个 triangle primitive(即 3 个 v2g 顶点),最多可以调用
triStream.Append(...)输出 7 次,但输出 topology 固定为 TriangleStream<g2f> ------ 意味着后续这些被 Append 的顶点会被按一个三角形条带(triangle strip)送入片段阶段(也可用RestartStrip()重启条带)Microsoft LearnMicrosoft Learn。
float t = clamp(_Weight * 2 - dissolve_value, 0, 1);
if (t > 0) {
// 构建摄像机对齐的广告牌 quad (由4 个顶点组成 )
// triStream.Append 了四次 → 代表一个 quad,**后续(传给frag时)**被当作两三个三角形碎片渲染出来
} else {
// 只传递原三角形的三个顶点,一样通过 triStream.Append
}
-
当
t > 0(物体开始 dissolve) :你计算一个围绕 avgPos 的四边形,将四个角顶点的
pos,uv,normal,worldPos填入 g2f,然后连续Append()四次。(你没显式RestartStrip(),但默认每个 GS 调用一个条带,一般能正确输出 quad) -
当
t ≤ 0:你只是把原来传入的 3 个 三角形顶点 封装为 g2f,再依次
Append()三次,并将worldPos.w = -1用作片段 shader 里的 flag,表示这部分是未 dissolve 的原始三角形。
所以说GS 就是负责"组装最终三角形"的阶段。
Fragment Shader 会被这些最终三角形中的每个 fragment 调用一次。它不关心这些顶点是 VS 直接来,还是 GS 重写后来的,只关心最终 rasterized geometry。
在没有 GS 的情况下,是 VS 输出的那三角形被 rasterize;但一旦有 GS,真正送到 frag 的顶点来自 GS 的输出 。VS 的数据仅是输入来源之一。
GS 唯一的作用确实就是它可以"重新组织 Primitive 拆分/合并、决定是否输出",这在 VS 和 FS 中都做不到