搭建神经网络架构
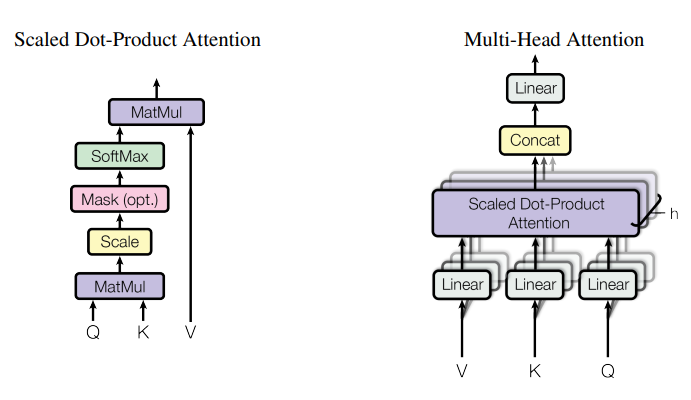
在pytorch中,神经网络被抽象成由一系列对数据执行特定操作的层或者模块组成,比如下面的Attention实现,每个块都是一个模块或者层。
如果你想快速搭建网络架构,torch.nn这个命名空间提供了所有很多开箱即用的层/模块/算子:
如果你想自定义一个模块也是完全可以的。每个模块都是nn.Module的子类,你只需要继承然后复写即可,这个后面有例子。
这种简洁的架构抽象可以让使用pytorch的人们快速搭建并管理精妙的模型架构。
接下来,我们将搭建一个神经网络来分类FashionMNIST数据集,来过一遍搭建网络的工作流。
python
import os
import torch
from torch import nn
from torch.utils.data import Dataloader
from torchvision import datasets, transforms1. 获取可能的加速设备
为了在 加速器(accelerator) 上训练我们的模型,例如 CUDA 、MPS 、MTIA 或 XPU,我们将遵循以下逻辑:
如果当前设备有可用的加速器,我们就使用它;否则,我们将使用 CPU。
python
device = torch.accelerator.current_accelerator().type if torch.accelerator.is_available() else "cpu"
print(f"Using {device} device")2. 搭建网络结构
2.1 定义网络类
通过继承nn.Module,我们可以定义我们的神经网络类,并且在__init__里面定义我们要用到的模块或者层。然后实现forward方法来定义对输入模型的数据的实际操作以及操作顺序,并且返回推理结果。
python
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.faltten = nn.Faltten() # 展平层
self.linear_relu_stack = nn.Sequential( # 定义一个序列模块,被调用时会依次执行所含模块
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logit = self.linearr_relu_stack(x)
return logits注意,
__init__只负责把需要的块给初始化出来,具体数据是怎么在块间流动由forward实现。
2.2 实例化网络并查看结构
现在我们实例化网络,并且把它搬到device侧,然后打印出他的结构:
python
model = NeuralNetwork().to(device)
print(model)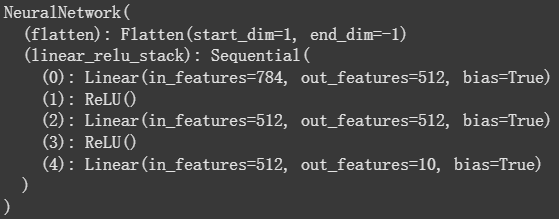
2.3 进行网络"冒烟测试"
搭建好网络结构之后,强烈建议进行一次"冒烟测试",用一个符合输入shape的tensor看看整个网络能不能跑通。
要给模型传入数据进行推理,直接给模型传入数据即可,千万别直接调用forward方法,因为model(x)还会做一些forward没做的一些其他必要操作。
python
X = torch.rand(1, 28, 28, device=device)
logits = model(X)
print(logits.shape)
pred_probab = nn.Softmax(dim=1)(logits)
print(pred_probab)
y_pred = pred_probab.argmax(1)
print(f"Predicted class: {y_pred}")
给模型输入数据之后,模型返回一个2维的tensor,dim=0的数据是batch中的具体样本idx,dim=1的数据则是输出的这个样本的所属10个不同类别的预测值。最后我们套一层nn.Softmax, 就可以获得每个类别的概率pred_probab了。最后对其使用argmax(1)找到该张量在dim=1维度上的最大值索引,就获得了这一次推理的分类结果。
3. 进阶操作:获取模型当前的参数
如果你想要一点可解释性,你可能得用到这个
神经网络中的许多层都是参数化 的,也就是说,它们有相关的权重(weights)和偏差(biases),这些值会在训练过程中进行优化。
当你的模型继承自 nn.Module 时,PyTorch 会自动追踪模型对象中定义的所有字段。因此,你可以通过模型的 parameters() 或 named_parameters() 方法来访问所有这些参数。
python
print(model)
for name, param in model.named_parameters():
pritn(f"Layer: {name} | Size: {param.size()} | Values : {param[:2]} \n") # 矩阵获取前两行,bias获取前两个在这个例子中,我们遍历了每一个参数,并打印出它的尺寸(size)和部分值预览。