TVM 现已更新到 0.21.0 版本,TVM 中文文档已经和新版本对齐。
Apache TVM 是一个深度的深度学习编译框架,适用于 CPU、GPU 和各种机器学习加速芯片。更多 TVM 中文文档可访问 →Apache TVM
Apache TVM 的一个主要设计目标是便于自定义优化流程,无论是用于科研探索还是工程开发,都可以灵活迭代优化过程。本教程将涵盖以下内容:
随着大语言模型(LLM)在多个领域成为热门的研究课题,如何将它们部署在云端或边缘设备上成为一项具有挑战性的任务。本教程将演示如何使用 Apache TVM 对大语言模型进行优化。我们将使用来自 Hugging Face 的预训练 TinyLlama 模型,并将其部署到多种设备上。
总览整体流程
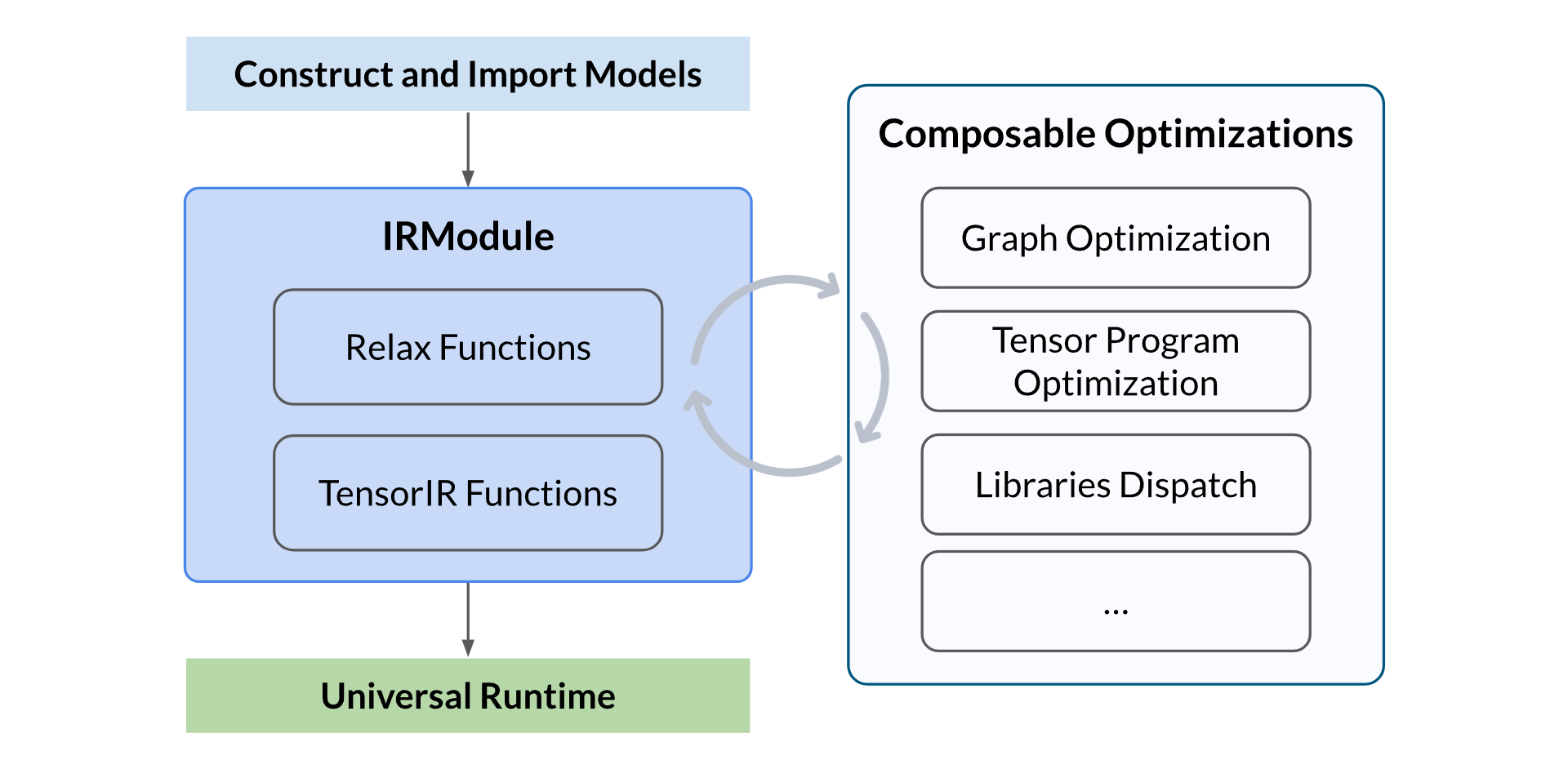
整体流程包括以下几个步骤:
- 构建或导入模型:可以手动构建一个神经网络模型,或从其他框架(如 PyTorch、ONNX)中导入一个预训练模型,并生成 TVM 的 IRModule。该模块包含编译所需的所有信息,包括用于表示计算图的高层 Relax 函数,以及用于描述张量程序的低层 TensorIR 函数
- 执行可组合优化:执行一系列优化转换,包括计算图优化、张量程序优化和算子调度/分发等
- 构建并进行通用部署:将优化后的模型构建为可部署模块,使用 TVM 通用运行时在不同设备上运行,例如 CPU、GPU 或其他加速器
构建模型结构
我们将使用来自 Hugging Face 的预训练 TinyLlama 模型。但通常我们只会从 Hugging Face 加载预训练权重,而不是模型结构。因此,我们需要自己构建模型结构。Apache TVM 提供了类似 PyTorch 的 API 来构建模型结构,我们可以使用这些 API 来完成模型搭建。
import dataclasses
import enum
import os
from pathlib import Path
from pprint import pprint
from typing import List, Optional
import tvm
from tvm import dlight, relax, te, tir
from tvm.relax import register_pipeline
from tvm.relax.frontend import nn
from tvm.relax.frontend.nn import Tensor, op
from tvm.relax.frontend.nn.llm.kv_cache import PagedKVCache, TIRPagedKVCache
from tvm.runtime import ShapeTuple首先,我们需要定义模型的配置。配置中包括模型的关键参数,如隐藏层维度、中间层维度等。为了方便起见,我们为 TinyLlama 模型专门定义一个常量配置。
@dataclasses.dataclass
class LlamaConfig:
hidden_size: int = 2048
intermediate_size: int = 5632
num_attention_heads: int = 32
num_hidden_layers: int = 22
rms_norm_eps: float = 1e-05
vocab_size: int = 32000
rope_theta: int = 10000
context_window_size: int = 2048
prefill_chunk_size: int = 2048
num_key_value_heads: int = 4
head_dim: int = 64 # hidden_size // num_attention_heads
dev = tvm.device("cuda", 0)
target = tvm.target.Target.from_device(dev)接着,我们定义分页 KV 缓存(Paged KV cache)的 RoPE 模式。RoPE(相对位置编码)用于在自注意力中对 query 和 key 张量进行编码。RoPE 模式可设置为 NONE、NORMAL 或 INLINE 如果 RoPE 模式为 ,则键值缓存(KV cache)不会对查询(query)和键(key)张量应用 RoPE;如果 RoPE 模式为,则在将键张量加入缓存之前,会对其应用 RoPE;如果 RoPE 模式为 INLINE,则会在注意力机制的核心计算过程中即时对查询和键张量应用 RoPE。
class RopeMode(enum.IntEnum):
"""
分页 KV 缓存的 RoPE 模式。
如果是 NONE,KV 缓存将不会对 q 和 k 应用 RoPE。
如果是 NORMAL,RoPE 将在将 k 添加到缓存之前应用于 k。
否则,RoPE 将在注意力内核中即时应用于 q/k。
"""
NONE = 0
NORMAL = 1
INLINE = 2接下来,我们定义模型的结构。模型结构包含三个部分:
- 嵌入层(Embedding Layer) :将输入的 token ID 转换为隐藏状态
- 解码器层(Decoder Layers) :模型的核心部分。每一层解码器包含一个自注意力层和一个前馈神经网络(FFN)层。
- 输出层(Output Layer) :将隐藏状态转换为 logits 输出
首先我们定义 FFN 层。注意以下是一个经过优化的 FFN 实现,它将 gate 和 up 投影融合成一个 kernel。普通的 FFN 计算公式为:FFN(x) = down_proj(silu(gate(x)) * up(x)),为了更高性能,我们将 gate 和 up 投影合并优化处理。
concat_x = gate_up(x)
gate_x, up_x = split(concat_x, 2, axis=-1)
FFN(x) = down_proj(silu(gate_x) * up_x)
class LlamaFFN(nn.Module):
def __init__(self, config: LlamaConfig):
super().__init__()
self.gate_up_proj = nn.Linear(
in_features=config.hidden_size,
out_features=2 * config.intermediate_size,
bias=False,
)
self.down_proj = nn.Linear(config.intermediate_size, config.hidden_size, bias=False)
def forward(self, x: Tensor):
concat_x1_x2 = self.gate_up_proj(x)
x1, x2 = op.split(concat_x1_x2, 2, axis=-1)
return self.down_proj(op.silu(x1) * x2)接着我们定义自注意力层(Self-Attention Layer),它由以下 3 部分组成:
- QKV 投影:将输入隐藏状态转换为 query、key、value 张量。
- 注意力机制:计算注意力分数并执行 softmax 操作。
- 输出投影:将注意力输出转换为隐藏状态。
在自注意力层中,我们对不同部分进行了优化:
-
QKV 投影:对 Q、K、V 执行横向融合,将它们合并为一个 kernel
-
注意力机制:将 QKV 投影与注意力逻辑融合,进一步提升性能
class LlamaAttention(nn.Module): # 关闭 Pylint 对"类的实例属性过多"的检查
def init(self, config: LlamaConfig):
self.head_dim = config.head_dim
self.num_q_heads = config.num_attention_heads
self.num_kv_heads = config.num_key_value_heads
# QKV 投影的横向融合
self.qkv_proj = nn.Linear(
in_features=config.hidden_size,
out_features=(self.num_q_heads + 2 * self.num_kv_heads) * self.head_dim,
bias=False,
)
self.o_proj = nn.Linear(self.num_q_heads * self.head_dim, config.hidden_size, bias=False)def forward(self, hidden_states: Tensor, paged_kv_cache: PagedKVCache, layer_id: int): d, h_q, h_kv = self.head_dim, self.num_q_heads, self.num_kv_heads b, s, _ = hidden_states.shape # QKV 投影 qkv = self.qkv_proj(hidden_states) qkv = op.reshape(qkv, (b, s, h_q + h_kv + h_kv, d)) # 注意力计算 output = op.reshape( paged_kv_cache.attention_with_fused_qkv( layer_id, qkv, self.num_q_heads, sm_scale=self.head_dim**-0.5 ), (b, s, h_q * d), ) # 输出投影 return self.o_proj(output)
最后,我们将 FFN 层和自注意力层组合,定义完整的模型结构。
class LlamaDecoderLayer(nn.Module):
def __init__(self, config: LlamaConfig):
rms_norm_eps = config.rms_norm_eps
self.self_attn = LlamaAttention(config)
self.mlp = LlamaFFN(config)
self.input_layernorm = nn.RMSNorm(config.hidden_size, -1, rms_norm_eps, bias=False)
self.post_attention_layernorm = nn.RMSNorm(config.hidden_size, -1, rms_norm_eps, bias=False)
def forward(self, hidden_states: Tensor, paged_kv_cache: PagedKVCache, layer_id: int):
hidden_states += self.self_attn(
self.input_layernorm(hidden_states), paged_kv_cache, layer_id
)
hidden_states += self.mlp(self.post_attention_layernorm(hidden_states))
return hidden_states
class LlamaModel(nn.Module):
def __init__(self, config: LlamaConfig):
assert config.hidden_size % config.num_attention_heads == 0
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size)
self.layers = nn.ModuleList(
[LlamaDecoderLayer(config) for _ in range(config.num_hidden_layers)]
)
self.norm = nn.RMSNorm(config.hidden_size, -1, config.rms_norm_eps, bias=False)
def forward(self, input_embed: Tensor, paged_kv_cache: PagedKVCache):
hidden_states = input_embed
for layer_id, layer in enumerate(self.layers):
hidden_states = layer(hidden_states, paged_kv_cache, layer_id)
hidden_states = self.norm(hidden_states)
return hidden_states
class LlamaForCasualLM(nn.Module):
def __init__(self, config: LlamaConfig):
self.model = LlamaModel(config)
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
self.num_hidden_layers = config.num_hidden_layers
self.num_attention_heads = config.num_attention_heads
self.num_key_value_heads = config.num_key_value_heads
self.head_dim = config.head_dim
self.hidden_size = config.hidden_size
self.vocab_size = config.vocab_size
self.rope_theta = config.rope_theta
self.dtype = "float32"
def to(self, dtype: Optional[str] = None):
super().to(dtype=dtype)
if dtype is not None:
self.dtype = dtype
def embed(self, input_ids: Tensor):
return self.model.embed_tokens(input_ids)
def get_logits(self, hidden_states: Tensor):
logits = self.lm_head(hidden_states)
if logits.dtype != "float32":
logits = logits.astype("float32")
return logits
def prefill(self, input_embed: Tensor, paged_kv_cache: PagedKVCache):
def _index(x: te.Tensor): # x[:-1,:]
b, s, d = x.shape
return te.compute((b, 1, d), lambda i, _, k: x[i, s - 1, k], name="index")
hidden_states = self.model(input_embed, paged_kv_cache)
hidden_states = op.tensor_expr_op(_index, name_hint="index", args=[hidden_states])
logits = self.get_logits(hidden_states)
return logits, paged_kv_cache
def decode(self, input_embed: Tensor, paged_kv_cache: PagedKVCache):
hidden_states = self.model(input_embed, paged_kv_cache)
logits = self.get_logits(hidden_states)
return logits, paged_kv_cache
def create_tir_paged_kv_cache(
self,
max_batch_size: tir.Var,
max_total_seq_len: tir.Var,
prefill_chunk_size: tir.Var,
page_size: tir.Var,
) -> PagedKVCache:
return TIRPagedKVCache(
attn_kind="mha",
max_batch_size=max_batch_size,
max_total_seq_len=max_total_seq_len,
prefill_chunk_size=prefill_chunk_size,
page_size=page_size,
support_sliding_window=0,
layer_partition=relax.ShapeExpr([0, self.num_hidden_layers]),
num_hidden_layers=self.num_hidden_layers,
num_attention_heads=self.num_attention_heads,
num_key_value_heads=self.num_key_value_heads,
qk_head_dim=self.head_dim,
v_head_dim=self.head_dim,
mla_original_qk_head_dim=0,
mla_original_v_head_dim=0,
rope_mode=RopeMode.NORMAL,
rope_scale=1,
rope_theta=self.rope_theta,
rope_scaling={},
rope_ext_factors=relax.PrimValue(0),
rotary_dim=self.head_dim,
dtype=self.dtype,
target=target,
enable_disaggregation=False,
)
def get_default_spec(self):
mod_spec = {
"embed": {
"input_ids": nn.spec.Tensor(["seq_len"], "int32"),
"$": {
"param_mode": "packed",
"effect_mode": "none",
},
},
"prefill": {
"input_embed": nn.spec.Tensor([1, "seq_len", self.hidden_size], self.dtype),
"paged_kv_cache": nn.spec.Object(object_type=PagedKVCache),
"$": {
"param_mode": "packed",
"effect_mode": "none",
},
},
"decode": {
"input_embed": nn.spec.Tensor([1, 1, self.hidden_size], self.dtype),
"paged_kv_cache": nn.spec.Object(object_type=PagedKVCache),
"$": {
"param_mode": "packed",
"effect_mode": "none",
},
},
"create_tir_paged_kv_cache": {
"max_batch_size": int,
"max_total_seq_len": int,
"prefill_chunk_size": int,
"page_size": int,
"$": {
"param_mode": "none",
"effect_mode": "none",
},
},
}
return nn.spec.ModuleSpec.from_raw(mod_spec, self)将模型导出为 Relax IRModule
在定义好模型架构之后,我们可以将模型导出为 Relax IRModule。为了演示,这里只展示模型架构的一部分以及参数。
model_config = LlamaConfig()
model = LlamaForCasualLM(model_config)
model.to("float16")
mod, named_params = model.export_tvm(spec=model.get_default_spec())
prefill_str = mod["prefill"].script()
print(*prefill_str.split("\n")[3:20], sep="\n") # 仅展示前 10 行用于演示
print(" ...")
print("\nParameters:")
pprint(named_params[:5]) # 仅展示前 5 个参数用于演示输出
@R.function
def prefill(input_embed: R.Tensor((1, "seq_len", 2048), dtype="float16"), paged_kv_cache: R.Object, packed_params: R.Tuple(R.Tensor((32000, 2048), dtype="float16"), R.Tensor((2560, 2048), dtype="float16"), R.Tensor((2048, 2048), dtype="float16"), R.Tensor((11264, 2048), dtype="float16"), R.Tensor((2048, 5632), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2560, 2048), dtype="float16"), R.Tensor((2048, 2048), dtype="float16"), R.Tensor((11264, 2048), dtype="float16"), R.Tensor((2048, 5632), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2560, 2048), dtype="float16"), R.Tensor((2048, 2048), dtype="float16"), R.Tensor((11264, 2048), dtype="float16"), R.Tensor((2048, 5632), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2560, 2048), dtype="float16"), R.Tensor((2048, 2048), dtype="float16"), R.Tensor((11264, 2048), dtype="float16"), R.Tensor((2048, 5632), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2560, 2048), dtype="float16"), R.Tensor((2048, 2048), dtype="float16"), R.Tensor((11264, 2048), dtype="float16"), R.Tensor((2048, 5632), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2560, 2048), dtype="float16"), R.Tensor((2048, 2048), dtype="float16"), R.Tensor((11264, 2048), dtype="float16"), R.Tensor((2048, 5632), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2560, 2048), dtype="float16"), R.Tensor((2048, 2048), dtype="float16"), R.Tensor((11264, 2048), dtype="float16"), R.Tensor((2048, 5632), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2560, 2048), dtype="float16"), R.Tensor((2048, 2048), dtype="float16"), R.Tensor((11264, 2048), dtype="float16"), R.Tensor((2048, 5632), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2560, 2048), dtype="float16"), R.Tensor((2048, 2048), dtype="float16"), R.Tensor((11264, 2048), dtype="float16"), R.Tensor((2048, 5632), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2560, 2048), dtype="float16"), R.Tensor((2048, 2048), dtype="float16"), R.Tensor((11264, 2048), dtype="float16"), R.Tensor((2048, 5632), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2560, 2048), dtype="float16"), R.Tensor((2048, 2048), dtype="float16"), R.Tensor((11264, 2048), dtype="float16"), R.Tensor((2048, 5632), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2560, 2048), dtype="float16"), R.Tensor((2048, 2048), dtype="float16"), R.Tensor((11264, 2048), dtype="float16"), R.Tensor((2048, 5632), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2560, 2048), dtype="float16"), R.Tensor((2048, 2048), dtype="float16"), R.Tensor((11264, 2048), dtype="float16"), R.Tensor((2048, 5632), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2560, 2048), dtype="float16"), R.Tensor((2048, 2048), dtype="float16"), R.Tensor((11264, 2048), dtype="float16"), R.Tensor((2048, 5632), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2560, 2048), dtype="float16"), R.Tensor((2048, 2048), dtype="float16"), R.Tensor((11264, 2048), dtype="float16"), R.Tensor((2048, 5632), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2560, 2048), dtype="float16"), R.Tensor((2048, 2048), dtype="float16"), R.Tensor((11264, 2048), dtype="float16"), R.Tensor((2048, 5632), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2560, 2048), dtype="float16"), R.Tensor((2048, 2048), dtype="float16"), R.Tensor((11264, 2048), dtype="float16"), R.Tensor((2048, 5632), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2560, 2048), dtype="float16"), R.Tensor((2048, 2048), dtype="float16"), R.Tensor((11264, 2048), dtype="float16"), R.Tensor((2048, 5632), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2560, 2048), dtype="float16"), R.Tensor((2048, 2048), dtype="float16"), R.Tensor((11264, 2048), dtype="float16"), R.Tensor((2048, 5632), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2560, 2048), dtype="float16"), R.Tensor((2048, 2048), dtype="float16"), R.Tensor((11264, 2048), dtype="float16"), R.Tensor((2048, 5632), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2560, 2048), dtype="float16"), R.Tensor((2048, 2048), dtype="float16"), R.Tensor((11264, 2048), dtype="float16"), R.Tensor((2048, 5632), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2560, 2048), dtype="float16"), R.Tensor((2048, 2048), dtype="float16"), R.Tensor((11264, 2048), dtype="float16"), R.Tensor((2048, 5632), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((2048,), dtype="float16"), R.Tensor((32000, 2048), dtype="float16"))) -> R.Tuple(R.Tensor((1, 1, 32000), dtype="float32"), R.Object):
seq_len = T.int64()
R.func_attr({"num_input": 2})
with R.dataflow():
model_embed_tokens_weight1: R.Tensor((32000, 2048), dtype="float16") = packed_params[0]
model_layers_0_self_attn_qkv_proj_weight1: R.Tensor((2560, 2048), dtype="float16") = packed_params[1]
model_layers_0_self_attn_o_proj_weight1: R.Tensor((2048, 2048), dtype="float16") = packed_params[2]
model_layers_0_mlp_gate_up_proj_weight1: R.Tensor((11264, 2048), dtype="float16") = packed_params[3]
model_layers_0_mlp_down_proj_weight1: R.Tensor((2048, 5632), dtype="float16") = packed_params[4]
model_layers_0_input_layernorm_weight1: R.Tensor((2048,), dtype="float16") = packed_params[5]
model_layers_0_post_attention_layernorm_weight1: R.Tensor((2048,), dtype="float16") = packed_params[6]
model_layers_1_self_attn_qkv_proj_weight1: R.Tensor((2560, 2048), dtype="float16") = packed_params[7]
model_layers_1_self_attn_o_proj_weight1: R.Tensor((2048, 2048), dtype="float16") = packed_params[8]
model_layers_1_mlp_gate_up_proj_weight1: R.Tensor((11264, 2048), dtype="float16") = packed_params[9]
model_layers_1_mlp_down_proj_weight1: R.Tensor((2048, 5632), dtype="float16") = packed_params[10]
model_layers_1_input_layernorm_weight1: R.Tensor((2048,), dtype="float16") = packed_params[11]
...
Parameters:
[('model.embed_tokens.weight', Tensor([32000, 2048], "float16")),
('model.layers.0.self_attn.qkv_proj.weight', Tensor([2560, 2048], "float16")),
('model.layers.0.self_attn.o_proj.weight', Tensor([2048, 2048], "float16")),
('model.layers.0.mlp.gate_up_proj.weight', Tensor([11264, 2048], "float16")),
('model.layers.0.mlp.down_proj.weight', Tensor([2048, 5632], "float16"))]定义优化流程(Optimization Pipeline)
我们定义了一系列用于优化模型的传递过程(pass)。这个优化流程是专门为大语言模型(LLMs)设计的。
@register_pipeline("opt_llm")
def _pipeline( # pylint: disable=too-many-arguments
ext_mods: List[nn.ExternModule] = None,
):
ext_mods = ext_mods or []
@tvm.transform.module_pass(opt_level=0)
def _pipeline(mod: tvm.ir.IRModule, _ctx: tvm.transform.PassContext) -> tvm.ir.IRModule:
seq = tvm.transform.Sequential(
[
# 第一阶段:针对高层操作图的优化
# 可以启用 cublas以进一步优化
relax.transform.FuseTransposeMatmul(),
# 第二阶段:向 TIR(张量中间表示)下沉,继承 TVM Relax 的官方 "zero" 流程
relax.transform.LegalizeOps(),
relax.transform.AnnotateTIROpPattern(),
relax.transform.FoldConstant(),
relax.transform.FuseOps(),
relax.transform.FuseTIR(),
# 第三阶段:对 TIR 进行优化
relax.transform.DeadCodeElimination(),
# 第四阶段:底层优化
dlight.ApplyDefaultSchedule(
dlight.gpu.Matmul(),
dlight.gpu.GEMV(),
dlight.gpu.Reduction(),
dlight.gpu.GeneralReduction(),
dlight.gpu.Fallback(),
),
# 第五阶段:转换为虚拟机字节码
relax.transform.RewriteDataflowReshape(),
relax.transform.ToNonDataflow(),
relax.transform.RemovePurityChecking(),
relax.transform.CallTIRRewrite(),
relax.transform.StaticPlanBlockMemory(),
relax.transform.RewriteCUDAGraph(),
relax.transform.LowerAllocTensor(),
relax.transform.KillAfterLastUse(),
relax.transform.LowerRuntimeBuiltin(),
relax.transform.VMShapeLower(),
relax.transform.AttachGlobalSymbol(),
relax.transform.AttachExternModules(ext_mods),
]
)
mod = seq(mod)
return mod
return _pipeline
with target:
ex = tvm.compile(mod, target, relax_pipeline=relax.get_pipeline("opt_llm"))
vm = relax.VirtualMachine(ex, dev)准备模型权重
我们从 Hugging Face 加载预训练权重并准备模型权重。预训练权重是以 Hugging Face 格式存储的,我们需要加载权重并准备模型参数。
备注
注意:本教程中不会执行以下代码,因为在 CI 环境中无法获取预训练权重。
IS_IN_CI = os.getenv("CI", "") == "true"
HF_WEIGHT_PATH = None
# HF_WEIGHT_PATH = Path("/path/to/TinyLlama-1.1B-Chat-v1.0/")
if not IS_IN_CI:
import numpy as np
import safetensors.torch
import torch
if HF_WEIGHT_PATH is None or not HF_WEIGHT_PATH.exists():
raise ValueError("Please set the HF_WEIGHT_PATH to the path of the pre-trained weights.")
# Torch 格式权重
param_dict = safetensors.torch.load_file(HF_WEIGHT_PATH / "model.safetensors", device="cpu")
# Numpy 格式权重
param_dict = {
k: v.half().numpy() if v.dtype == torch.bfloat16 else v.numpy()
for k, v in param_dict.items()
}
named_params = dict(named_params)
for i in range(model_config.num_hidden_layers):
# 在自注意力机制中添加 QKV 权重
attn = f"model.layers.{i}.self_attn"
param_dict[f"{attn}.qkv_proj.weight"] = np.concatenate(
[
param_dict.pop(f"{attn}.q_proj.weight"), # 移除旧参数来节省内存
param_dict.pop(f"{attn}.k_proj.weight"),
param_dict.pop(f"{attn}.v_proj.weight"),
],
axis=0,
)
# 在 MLP 中添加 gate 权重
mlp = f"model.layers.{i}.mlp"
param_dict[f"{mlp}.gate_up_proj.weight"] = np.concatenate(
[
param_dict.pop(f"{mlp}.gate_proj.weight"),
param_dict.pop(f"{mlp}.up_proj.weight"),
],
axis=0,
)
# 将参数转换为 ndarray
params = [
tvm.runtime.tensor(param_dict[k].astype("float16"), device=dev) for k in named_params.keys()
]部署已编译模型
当模型和权重准备好后,我们就可以在目标设备上部署已编译的模型。语言模型推理包括两个步骤:prefill 和 decode。prefill 步骤用于处理输入的 token 并存储 KVCache;decode 步骤用于生成 token,直到生成结束 token 为止。
分词
第一步是对输入提示进行分词,并将分词后的 token 嵌入到隐藏状态中。分词和嵌入与原始模型相同。我们使用 Hugging Face 的分词器对输入提示进行分词,并将 token 嵌入到隐藏状态中。请注意,不同模型需要不同的分词方法和提示格式,具体请参考模型的文档以获取正确的分词和提示格式。
if not IS_IN_CI:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(HF_WEIGHT_PATH)
messages = [
{"role": "user", "content": "What's your name?"},
]
prompt = tokenizer.apply_chat_template(messages)
input_len = len(prompt)
# 将提示 token 加载到目标设备上的 TVM ndarray
tokens = tvm.runtime.tensor(np.array(prompt).astype("int32"), device=dev)创建 KVCache
在开始推理之前,需要创建 KVCache。KVCache 用于存储注意力层的 key 和 value 张量。Apache TVM 提供了 PagedKVCache 用于存储 key 和 value 张量。我们根据指定参数创建 PagedKVCache。
if not IS_IN_CI:
kv_cache = vm["create_tir_paged_kv_cache"](
ShapeTuple([1]), # max_batch_size=1
ShapeTuple([2048]), # max_total_seq_len=2048
ShapeTuple([2048]), # prefill_chunk_size=2048
ShapeTuple([16]), # page_size=16
)嵌入
下一步是将 token 嵌入到隐藏状态中。我们使用在 Relax IRModule 中编译的 embed 函数,将 token 嵌入到隐藏状态。
nd_view_func = tvm.get_global_func("vm.builtin.reshape")
def embed(tokens, params):
_embed = vm["embed"](tokens, params)
# 将 hidden 的形状从 [seq_len, hidden_size] 重塑为 [1, seq_len, hidden_size]
_embed = nd_view_func(_embed, ShapeTuple([1, _embed.shape[0], _embed.shape[1]]))
return _embedPrefill
在执行前向计算之前,我们先获取一些辅助函数以做准备。
add_sequence_func = tvm.get_global_func("vm.builtin.kv_state_add_sequence")
begin_forward_func = tvm.get_global_func("vm.builtin.kv_state_begin_forward")
end_forward_func = tvm.get_global_func("vm.builtin.kv_state_end_forward")在我们创建一个新序列时,需要调用 add_sequence_func 来初始化请求。此外,还需要调用 begin_forward_func 来开始前向计算,调用 end_forward_func 来结束前向计算。
if not IS_IN_CI:
seq_id = 0
add_sequence_func(kv_cache, seq_id)
hidden_states = embed(tokens, params)
begin_forward_func(kv_cache, ShapeTuple([seq_id]), ShapeTuple([input_len]))
logits, kv_cache = vm["prefill"](hidden_states, kv_cache, params)
end_forward_func(kv_cache)现在我们从 prefill 步骤得到了输出的 logits,logits 用于通过采样生成 token。我们从 logits 中采样 token。
在本教程中,我们简化采样过程,选择概率最高的 token。实际应用中,应该基于概率分布进行采样。为了使教程简洁,采样过程在 CPU 上执行。
def sample_token(logits):
logits_np = logits.numpy()
return np.argmax(logits_np)
if not IS_IN_CI:
last_token = sample_token(logits)
output_tokens = [last_token]Decode
Prefill 步骤完成后,我们可以开始 decode 步骤。decode 步骤用于持续生成 token,直到生成结束 token。我们使用 Relax IRModule 中编译的 decode 函数来生成 token。可右键另存为下载。
if not IS_IN_CI:
print("The generated token:")
while last_token != tokenizer.eos_token_id:
tokens = tvm.runtime.tensor(np.array([last_token]).astype("int32"), device=dev)
hidden_states = embed(tokens, params)
begin_forward_func(kv_cache, ShapeTuple([seq_id]), ShapeTuple([1]))
logits, kv_cache = vm["decode"](hidden_states, kv_cache, params)
end_forward_func(kv_cache)
last_token = sample_token(logits)
output_tokens.append(last_token)
print(tokenizer.decode(output_tokens))