OS-Genesis 实践了 「自动探索 GUI - 反向推导任务数据」 的 GUI 数据构造,并基于 Qwen2-VL-7B 进行了模型训练,目前 数据未开源。
主要训练过程:
- 首先会基于特定规则遍历 App,然后利用操作前后的状态和操作描述生成 单步的操作指令(low-level instructions),然后结合多个单一指令生成多步的复杂任务指令( high-level instructions)
- 使用一个奖励模型(gpt4o)对生成的任务指令和截图进行打分,针对一些不完整但有价值的数据任然加入到模型训练
实验数据结论:
- OS-Genesis(反向任务推理)对比 Task-Driven/Zero-Shot/Self-Instructions 有效提升任务完成率
- OS-Genesis(反向任务推理)对比真实人类操作的 GUI 的过程相似度超过 80%
训练数据:
App 遍历:Type 利用 gpt4o 给出匹配上下文的内容
系统地遍历动作交互元素 a ∈ A ={CLICK, TYPE, SCROLL} 。整个自动探索基于特定规则(论文没有细说),在需要输入时( TYPE ),会调用GPT-4o 来生成与上下文适配的内容 。通过探索收集了大量动作以及动作前后的状态组成操作序列。
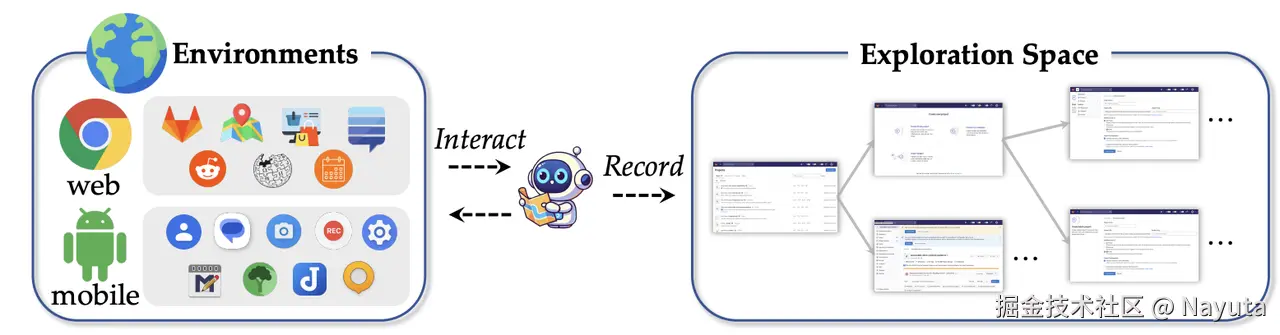
Reverse Task Synthesis:利用 GPT4o 生成单步指令和多步指令
利用一个 GPT-4o 基于操作序列生成 low-level instructions 和 high-level instructions。
low-level instructions 表示一次单步操作任务,基于一次操作序列生成,比如在当位于微信首页时-打开通讯录
high-level instructions 表示一个更完整复杂的多步的任务,基于多次操作序列生成。
单步任务生成的 Prompt 论文没有提到,多步任务生成的 Prompt 如下:

vbnet
Prompt for Associating High-Level Tasks You are an expert at envisioning specific tasks corresponding to changes in mobile screenshots. I will provide you with the following:
1. The type of action currently being executed. The type of action currently being executed, which can be one of five types: CLICK, SCROLL, TYPE, PRESS_BACK, and LONG_PRESS. If the action is TYPE, an additional value representing the input will be provided. If the action is SCROLL, an additional scroll direction will be provided. 2. Screenshots of the interface before and after the current action is performed. If the action is CLICK, the pre-action screenshot will include a red bbox highlighting the element being interacted with (if applicable). Pay particular attention to the content of the element corresponding to the red bbox.
3. The name of the app where the current screenshot is located.
Your task is to envision a specific task based on the current action and the corresponding changes in screenshots. The output should include three parts:
1. Sub-Instruction: Based on the interface change caused by the current action, generate a corresponding natural language instruction for the current action. The instruction should be concise, clear, and executable. It must include specific details critical to the operation, such as file names, times, or other content as they appear in the screenshots. For example: "Scroll left to open the app drawer, displaying all installed applications on the devic", "Click the chat interface, allowing the user to view and participate in conversation", "Type the username 'Agent', preparing for the next step in logging into the account". 2. Analysis: Based on the interface changes and the current action instructions, analyze the possible subsequent operations. This analysis should involve step-by-step reasoning, considering the potential changes on the screen and the actions that can be taken after these changes. For example: "After clicking the plus button, a dropdown menu appears with an option to create a document. I can select this option to create a new document. First, I need to name the document, then enter any content into the document, and finally save the document and exit". 3. High-Level-Instruction: Based on the analysis results, envision a high-level task that can be completed within the current interface. There are two types of High-Level-Instruction: Task-Oriented: Completing a series of operations to achieve a specific goal. Question-Oriented: Performing a series of operations and deriving an answer to a specific question.
For example: {examples}.
Ensure that the High-Level-Instruction is executable by including all critical specifics, such as file names, relevant timings, or required details.
You ONLY need to return a dictionary formatted as follows: { "Sub-Instruction": "xxx", "Analysis": "xxx", "High-Level-Instruction": "xxx" }
Current Action: {current_action} App Name: {app_name} RETURN ME THE DICTIONARY I ASKED FOR.Exploration and Reward Modeling: 再次对生成数据进行评估完成率
从描述来看,从 GUI 反向生成的任务数据也不意味着 100% 准确,比如某些任务中间可能有冗余步骤。
为了确保这些轨迹的质量和实用性,OS-Genesis 采用了轨迹奖励模型 (TRM)。TRM 基于 GPT-4o 构建,根据完成度(任务完成度) 和连贯性(动作的逻辑顺序) 评估每个轨迹,并分配从 1 到 5 的分级奖励分数。与传统的二进制筛选方法不同,TRM 允许不完整但有价值的轨迹为训练做出贡献。
而且这个奖励模型做不同策略最终也会影响到效果,在最后有数据给出:
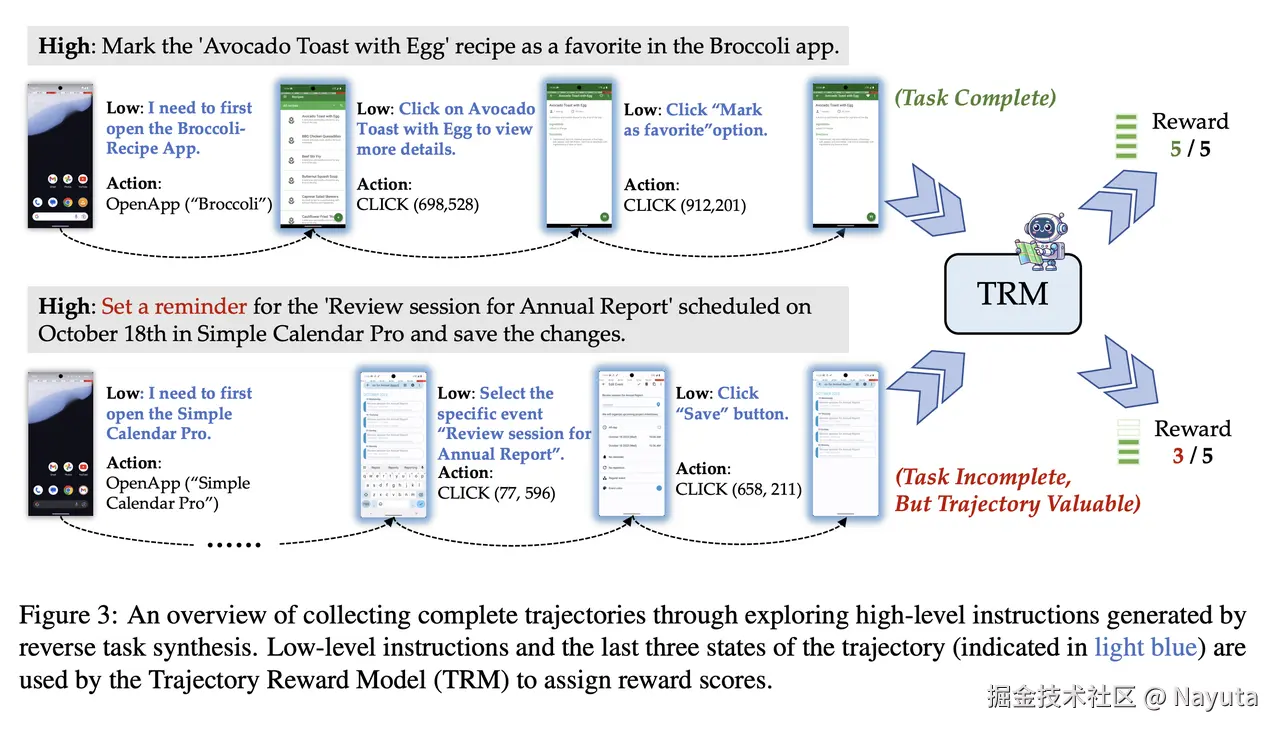
以下是对应的 prompt:
vbnet
Trajectory Reward Model Prompt
You are an expert in evaluating GUI agent task trajectories. Your task is to assess the quality and effectiveness of task trajectories for GUI manipulation tasks.
A trajectory consists of the following components:
1. High-level Instruction: Describes the user's intended task (e.g., "Create a new blank project name 'OS-Genesis'").
2. Action History: Includes two key parts:
- Reasoning and Action for Each Step: A sequence of actions performed by the agent, including the reasoning thought and final executed action.
- GUI Screenshots: Screenshots of the last state: (if there are at least three states; otherwise, include all states).
When evaluating a trajectory, consider these key aspects:
Evaluation Criteria:
1. Trajectory Coherence:
- Do the low-level steps and corresponding actions follow a logical sequence toward the goal?
- Are the actions clearly described and specific?
- Are there redundant or unnecessary actions?
2. Task Completion:
- Does the trajectory successfully achieve the instructed task?
- Are all necessary interactions completed?
- Are error cases handled appropriately?
Scoring Guidelines:
Rate the trajectory on a scale of 1 to 5 based on the evaluation criteria:
- 5 : The task is perfectly completed, successfully executing multiple actions to achieve the goal. The sequence is logically clear with no noticeable redundancies.
- 4 : The task is mostly completed, successfully executing multiple actions. However, due to challenges or ambiguities in the instructions, the completion is not perfect, or there are inefficiencies in the process.
- 3 : The task is partially completed, with some successful actions executed. However, due to task or environmental constraints, the goal is not fully achieved, or the sequence ends in a loop or error.
- 2 : Only a few actions are executed. Although there is an attempt to complete the task, the trajectory deviates from the goal early on or demonstrates significant inefficiencies in execution and logic.
- 1: The task fails completely, with no meaningful actions executed at the start. The sequence either falls into an immediate deadlock, a repetitive loop, or demonstrates no value in completing the task. Or the tasks are completely inaccessible.
Note: If the task is relatively complex, but the trajectory demonstrates valuable attempts, even if the task is not fully completed, consider adjusting the score upward. However, if the task is complex but the trajectory fails to perform actions that contribute meaningfully to task completion, no extra points should be awarded.
You need to judge the score based on the agent's actions and screenshots combined.
Response Format:
Format your response into two lines as shown below:
Reason: < your thoughts and reasoning process for the score >
Score: < your score from 1-5 > 训练目标:
Plan + Action,做法类似,不过他好像不是纯图像的 Grounding ,看起来和 ViewTree 有关,这块儿数据目前没有公开,也不确定。
- Planning Training : ⽬的是加强模型的规划能⼒。给定截图,high-level instruction 和操作历史 ,预测 low-level instruction 和 动作:

- Action Training : ⽬的是加强 agent 根据 low-level instruction 执⾏适当动作的能⼒(保留模型的 grounding 等基础能⼒)。给定多模态输⼊ 、low-level instruction 和历史背景 ,预测动作:

实验结果:
任务完成情况
AndroidControl 和 AndroidWorld 作为移动测试数据集,WebArena 作为测试数据集;
主要使用 GPT-4o 进行反向任务合成和奖励建模,决策模型使用 InternVL2 - 4B/8B 和 Qwen2 - VL - 7BInstruct,并在 8×A100 80GB GPUs 上进行 SFT 全量微调,结果如下:
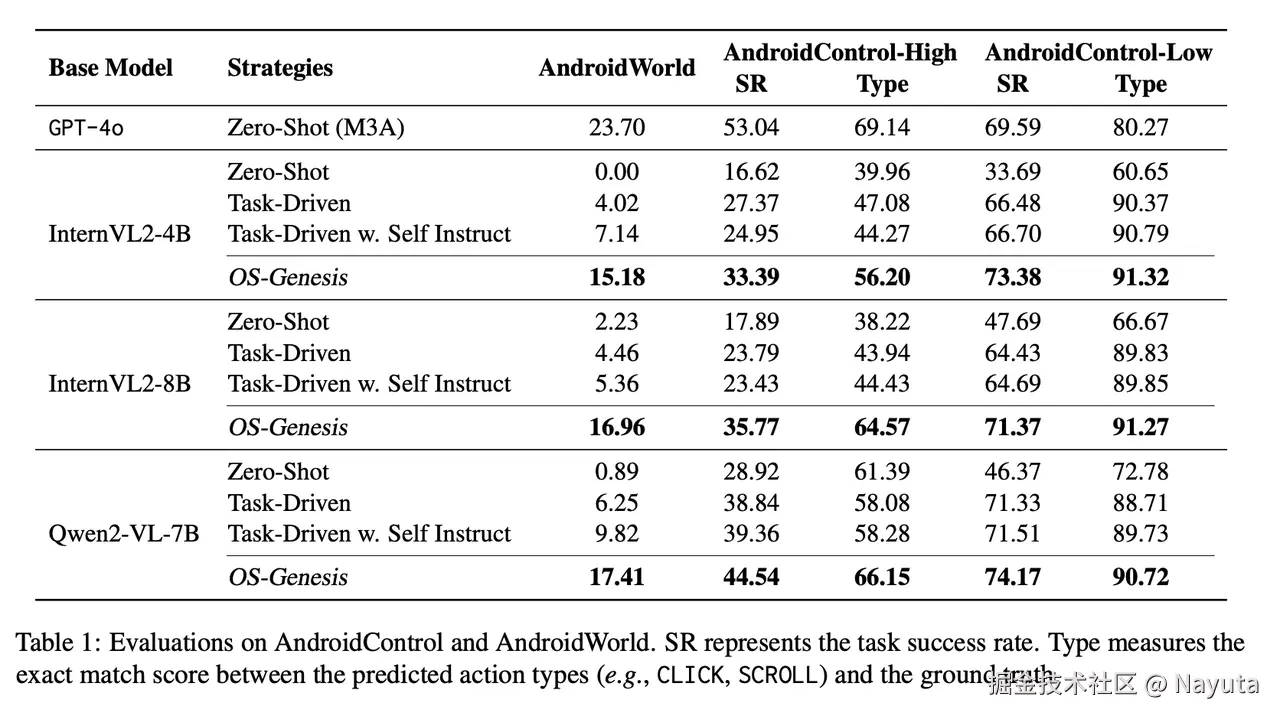
四种对比测试方式如下:
- Zero-Shot: This baseline leverages CoT (Wei et al., 2022) prompting to guide the model in perceiving environments and taking actions. For AndroidWorld tasks, we follow Rawles et al. (2024) to adopt M3A agent setup with multimodal input for this setting. (理解是 不带数据微调)
- Task-Driven: We build this baseline to compare with the common approach for agent data synthesis (Lai et al., 2024, inter alia). Given the initial screenshots of the app/web page and task examples, use GPT-4o to generate highlevel instructions and explore the environment to collect trajectories. These trajectories are then used for training.(理解是 利用现有 gpt4o 去针对测试集生成一个任务描述并且执行任务,然后利用 gpt4o 执行过程的数据来训练)
- Self-Instructions: Building upon the taskdriven baseline, this approach employs GPT-4o to perform self-instruction (Wang et al., 2023), generating additional high-level tasks for exploration and trajectory collection. Together with the previously collected trajectories, they are then used for training(理解是 利用 gpt4o 的执行的数据 和 本身训练集 一起训练)
- OS-Genesis:1.5K trajectories, with an average trajectory length of 6.4 steps
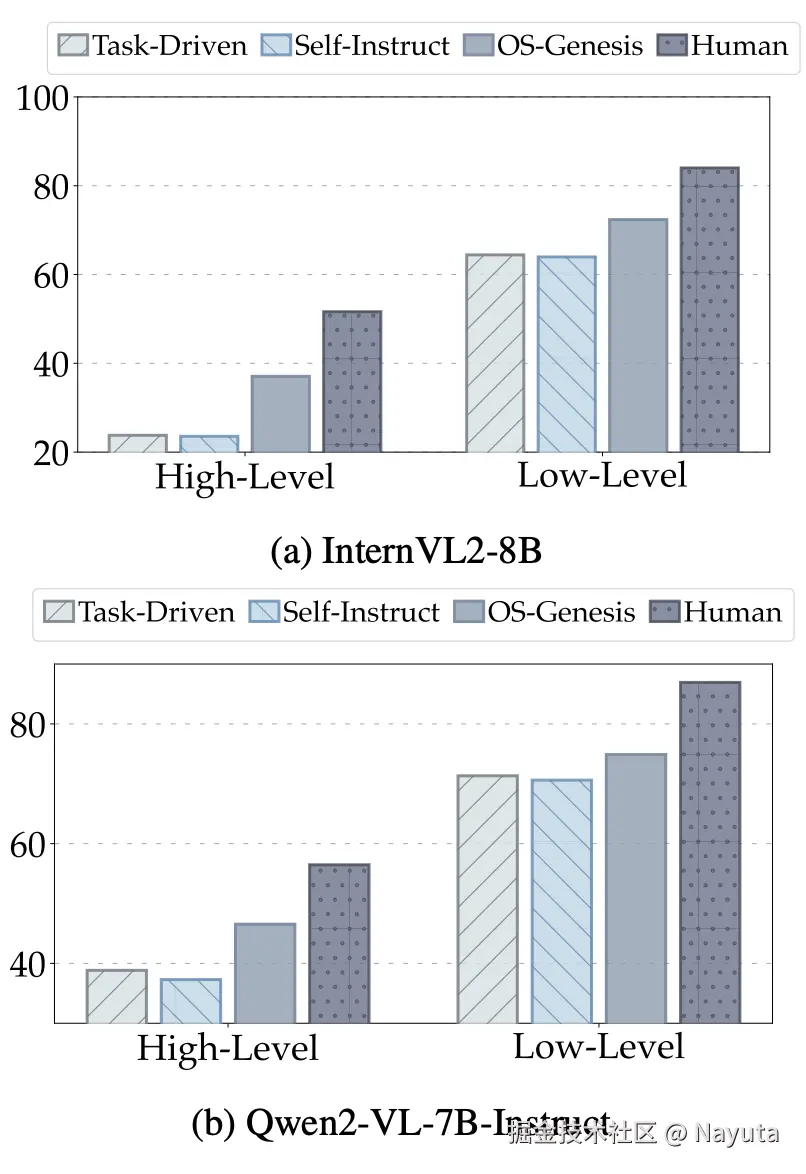
数据质量
同等轨迹数据训练 agent 得到的模型效果。利用 OS-Genesis 生成的轨迹数据训练的模型效果人类操作相速度超过 80%
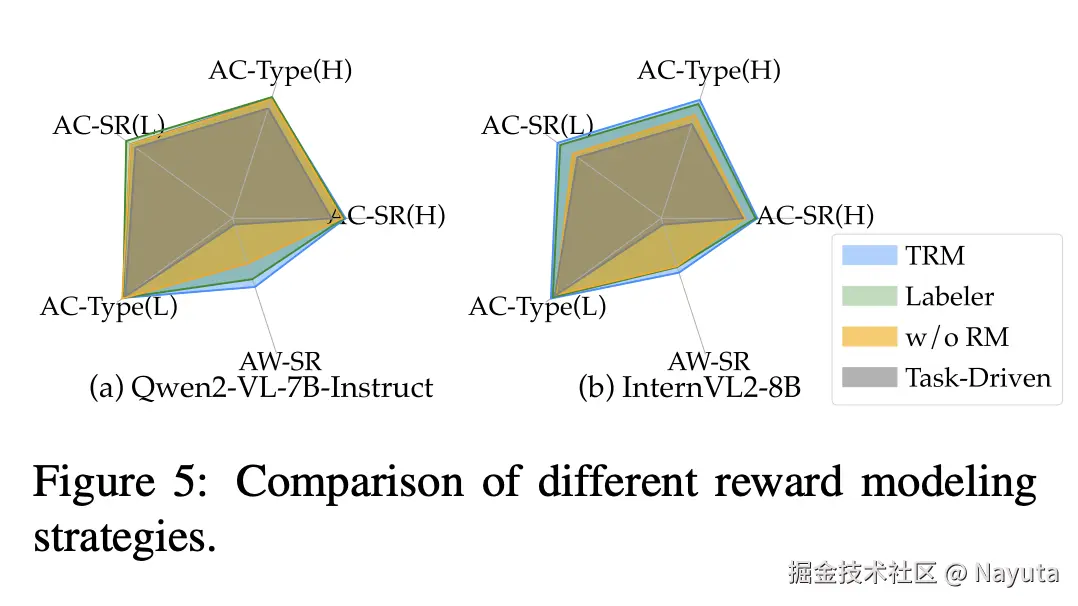
奖励模型对于指标的影响:
We introduce a Trajectory Reward Model (TRM) for data quality control and exploitation, substituting traditional labeler filtering methods (He et al., 2024; Murty et al., 2024a). To analyze its impact and for ablation purposes, we include additional settings for comparison: (1) training without an RM, where all synthesized data is treated equally during training, and (2) using a labeler , similar to previous approaches where only complete trajectories are retained for training.
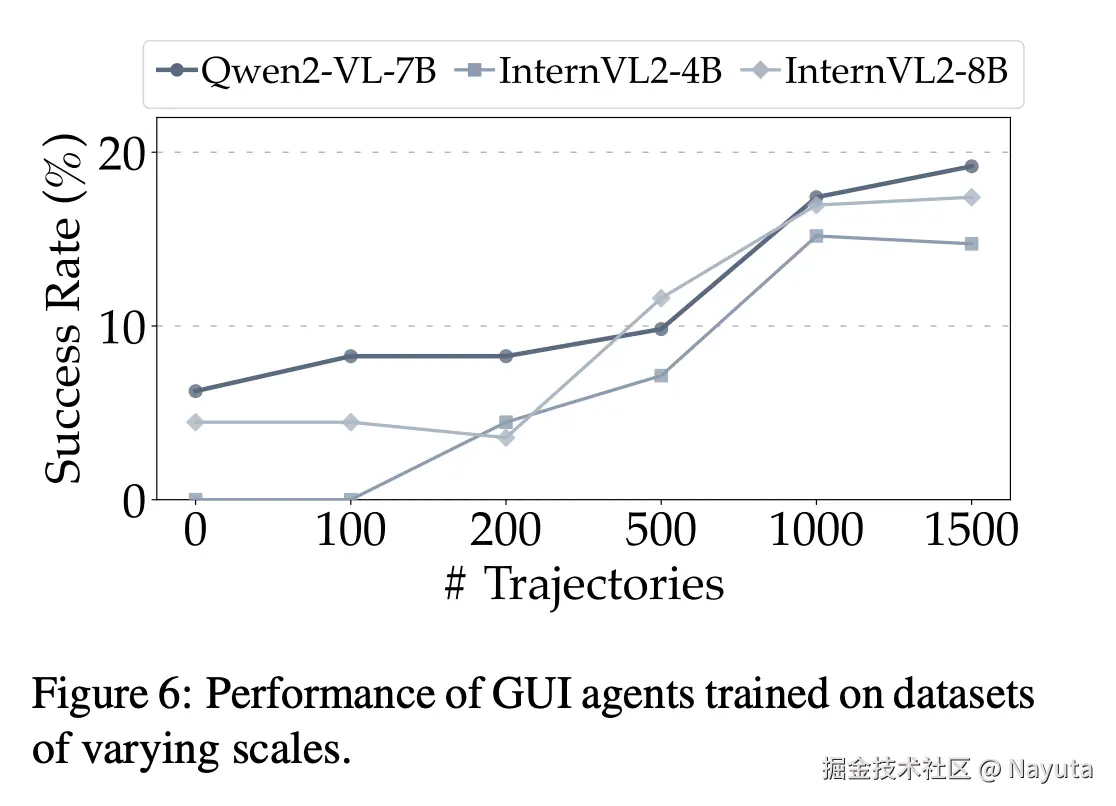
训练数据量在 AndroidWorld 完成率的提升
采用不同数据量的任务在 AndroidWorld 测试集上的任务表现(Android-Control 的成功率比这个高很多)