不是每个特征都有用,尽量挑出更有用的来节约计算资源
一、方差过滤
假设最开始数据是有很多个特征的数据集

使用方差过滤
python
from sklearn.feature_selection import VarianceThreshold
selector = VarianceThreshold() # 不填写默认方差为0
X_var0 = selector.fit_transform(X) # 删除方差为0的新矩阵特征值在下降

可以用不同的策略进行过滤特征
python
# 删除二分类特征中某一类占比≥80%或≤20%的列
x_bvar = VarianceThreshold(.8 * (1-.8)).fit_transform(X)
x_bvar.shape这是时候可以过滤更多

方差的中位数来赛选
python
import numpy as np
x_fsvar = VarianceThreshold(np.median(X.var().values)).fit_transform(X)效果更加明显了

二、卡方过滤
python
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import cross_val_score
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
#假设在这里我一直我需要300个特征
X_fschi = SelectKBest(chi2, k=300).fit_transform(x_fsvar, y) # 这个y是标签
X_fschi.shape1、F检验找k值再卡方过滤
先获取k值,选取的是p值小于0.05的特征,因为这些特征与标签是强相关的
python
from sklearn.feature_selection import f_classif
F, pvalues_f = f_classif(X_fsvar,y)
F
pvalues_f
k = F.shape[0] - (pvalues_f > 0.05).sum()再放到卡方过滤
python
X_fsF = SelectKBest(f_classif, k=填写具体的k).fit_transform(X_fsvar, y)
cross_val_score(RFC(n_estimators=10,random_state=0),X_fsF,y,cv=5).mean()2、互信息法找k值再卡方过滤
python
from sklearn.feature_selection import mutual_info_classif as MIC
result = MIC(X_fsvar,y)
k = result.shape[0] - sum(result <= 0)
X_fsmic = SelectKBest(MIC, k=填写具体的k).fit_transform(X_fsvar, y)
cross_val_score(RFC(n_estimators=10,random_state=0),X_fsmic,y,cv=5).mean()三、Embedded嵌入法
选出重要性 ≥0.005 的特征训练集
python
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier as RFC
RFC_ = RFC(n_estimators =10,random_state=0) # 随机森林的分类器
X_embedded = SelectFromModel(RFC_,threshold=0.005).fit_transform(X,y) # 选出重要性 ≥0.005 的特征训练集
X_embedded.shape重要性画出表格,再不断找最优秀
python
import numpy as np
import matplotlib.pyplot as plt
RFC_.fit(X,y).feature_importances_
threshold = np.linspace(0,(RFC_.fit(X,y).feature_importances_).max(),20)
score = []
for i in threshold:
X_embedded = SelectFromModel(RFC_,threshold=i).fit_transform(X,y)
once = cross_val_score(RFC_,X_embedded,y,cv=5).mean()
score.append(once)
plt.plot(threshold,score)
plt.show()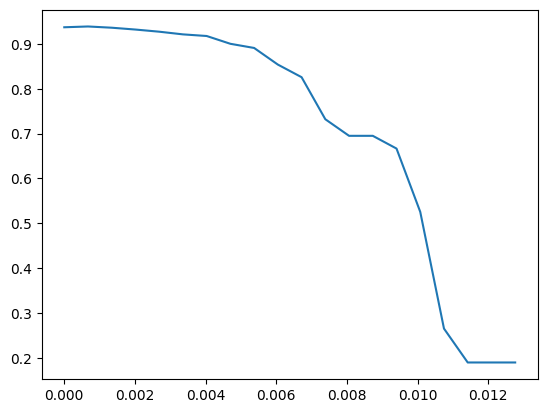
四、Wrapper包装法
RFE(递归特征消除)从原始训练集 X 中筛选出 340 个最重要的特征,生成新的训练集 X_wrapper
python
from sklearn.feature_selection import RFE
RFC_ = RFC(n_estimators =10,random_state=0) # 随机森林分类
selector = RFE(RFC_, n_features_to_select=340, step=50).fit(X, y)
selector.support_.sum()
selector.ranking_
X_wrapper = selector.transform(X)调参找出最佳训练集数量
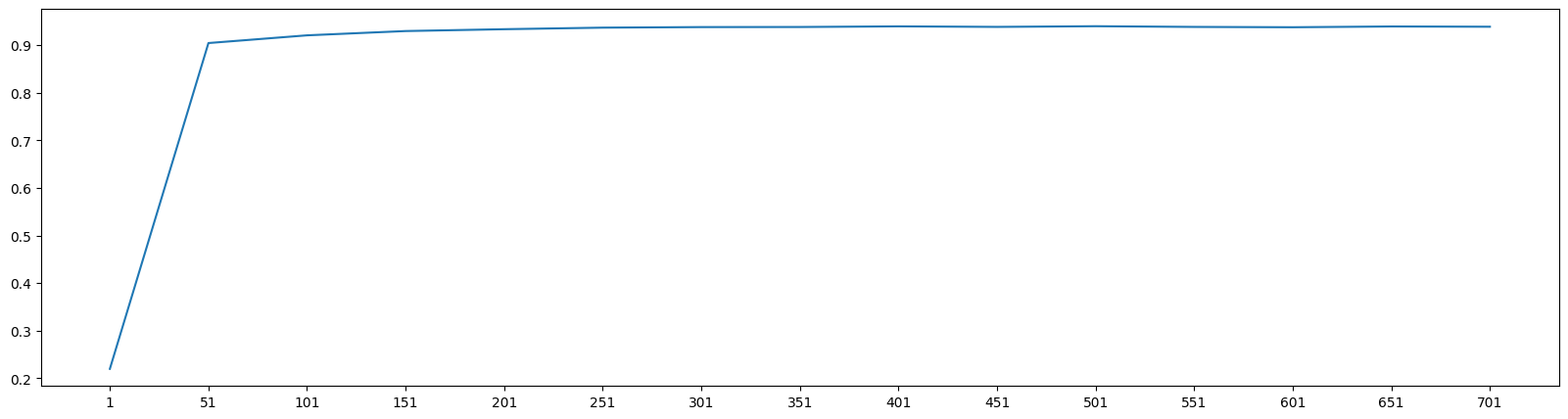
python
for i in range(1,751,50):
X_wrapper = RFE(RFC_,n_features_to_select=i, step=50).fit_transform(X,y)
once = cross_val_score(RFC_,X_wrapper,y,cv=5).mean()
score.append(once)
plt.figure(figsize=[20,5])
plt.plot(range(1,751,50),score)
plt.xticks(range(1,751,50))
plt.show()