目录
简介
接上两篇篇博客最后,我们使用了K折交叉验证去寻找最合适的C值,提升模型召回率,对于选取C的最优值,我们就要把不同C值放到模型里面训练,然后用验证集去验证得到结果进行比较 ,发现最后模型得到很大的提升 ,但是相对与召回率还是差了很多
机器学习第二课之逻辑回归(一)LogisticRegression
机器学习第二课之逻辑回归(一)LogisticRegression
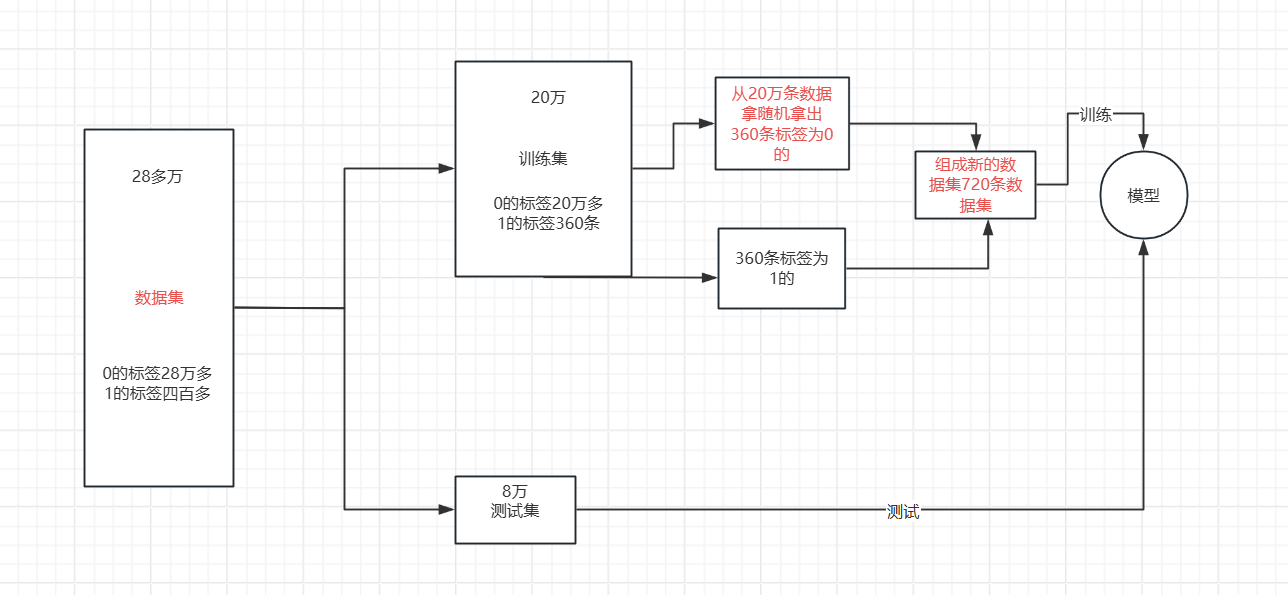
我们可以清楚的发现我们虽然有28万条数据集,但是相对于标签为1的数据集却只有四百多条,数据集分布及其不均匀,想要对于暂时学习的模型进行进一步提升没有太大的效果,只能对数据集进行一些处理,使得模型的效果得到提升,使用今天我来介绍两种对于数据集分布不均匀的优化处理。
1.下采样
我们要想用这样的数据去建模显然是存在问题的。尤其是在我们更关心少数类的问题的时候数据分类不均衡会更加的突出,例如,信用卡诈骗、病例分析等。在这样的数据分布的情况下,运用机器学习算法的预测模型可能会无法做出准确的预测,最后的模型显然是趋向于预测多数集的,少数集可能会被当做噪点或被忽视,相比多数集,少数集被错分的可能性很大。从本质上讲,机器学习算法就是从大量的数据集中通过计算得到某些经验,进而判定某些数据的正常与否。但是,不均衡数据集,显然少数类的数量太少,模型会更倾向于多数集。
针对多样本的类筛选一部分样本参与训练。 下采样的具体流程就是下图所示
代码分析:
1.导入库、数据标准化、划分数据集。(跟前面都一样)
python
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
from sklearn.model_selection import cross_val_score
data = pd.read_csv("creditcard.csv")
# 数据预处理
scaler = StandardScaler()
data["Amount"] = scaler.fit_transform(data[["Amount"]])
data = data.drop(["Time"], axis=1) # 移除时间列
# 划分特征和标签
x = data.iloc[:, :-1] # 特征
y = data.iloc[:, -1] # 标签
# 拆分训练集和测试集
x_train_w, x_test_w, y_train_w, y_test_w = train_test_split(x, y, test_size=0.2, random_state=1000)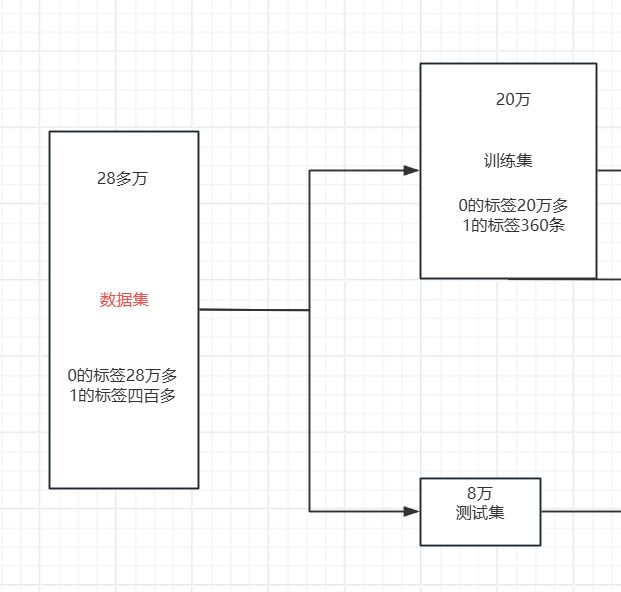
- 数据准备
python
data_train_temp = x_train_w.copy()
data_train_temp['Class'] = y_train_w- 首先复制特征数据
x_train_w到data_train_temp - 然后将标签数据
y_train_w作为新列Class添加到data_train_temp中 - 这样就创建了一个包含特征和对应标签的完整数据集
3.分离正负样本
python
positive_eg = data_train_temp[data_train_temp['Class'] == 0] # 正常样本
negative_eg = data_train_temp[data_train_temp['Class'] == 1] # 欺诈样本Class=0表示正常样本(positive_eg)Class=1表示欺诈样本(negative_eg)
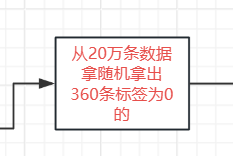
- 下采样处理
python
positive_eg = positive_eg.sample(len(negative_eg))- 这是下采样的核心操作
- 从正常样本中随机抽样,抽样数量等于欺诈样本的数量
- 这样处理后,正常样本和欺诈样本的数量将保持一致
5.组合数据集
python
data_c = pd.concat([positive_eg, negative_eg])- 将下采样后的正常样本和原始欺诈样本组合起来
- 得到一个类别平衡的新数据集
6.拆分特征和标签
python
x_new = data_c.drop('Class', axis=1)
y_new = data_c.Class- 从平衡后的数据集
data_c中拆分出新的特征集x_new和标签集y_new - 这些新数据可以用于后续的模型训练
7.交叉验证、训练、验证、得到结果
python
scores = []
c_param_range = [0.01, 0.1, 1, 10, 100]
for i in c_param_range:
lr = LogisticRegression(C=i, penalty="l2", solver='lbfgs', max_iter=10000)
# 使用平衡后的数据集进行交叉验证
score = cross_val_score(lr,x_new, y_new, cv=5, scoring="recall")
score_mean = sum(score) / len(score)
scores.append(score_mean)
print(f"C等于{i}的召回率为{score_mean}")
best_c = c_param_range[np.argmax(scores)]
print("最好的C是:", best_c)
# 使用最佳参数构建模型并训练
estimator = LogisticRegression(C=best_c, max_iter=100)
estimator.fit(x_new,y_new ) # 使用原始训练特征(不含额外添加的Class列)
# 在测试集上进行预测和评估
test_predicted = estimator.predict(x_test_w)
print("训练集准确率:", estimator.score(x_train_w, y_train_w))
print(metrics.classification_report(y_test_w, test_predicted))8.结果
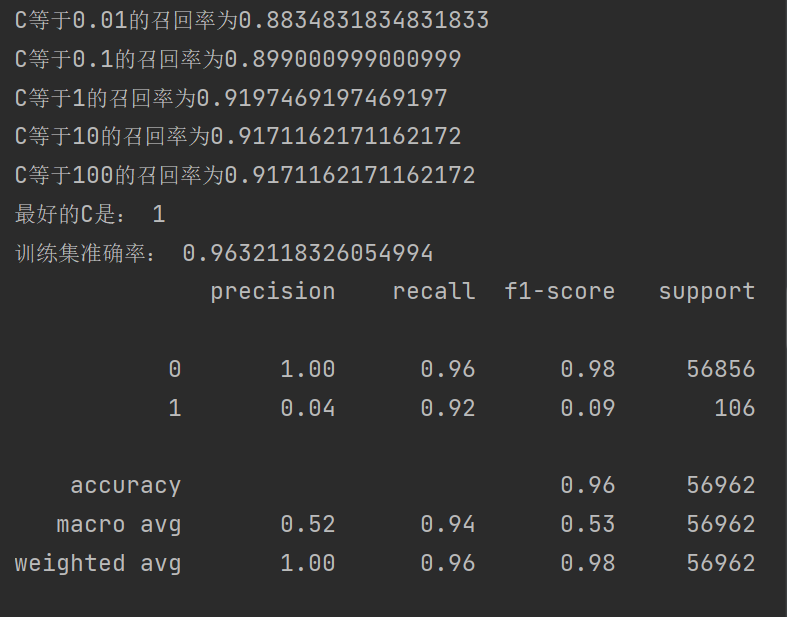
可以发现我们的召回率到达92%,效果得到很大的提升 ,对于准确率有些稍微下降,但是对于银行来说是可以接受的,之前也说过最主要的是看召回率的高低。
2.过采样
针对少样本类生成新的数据样本参与训练。
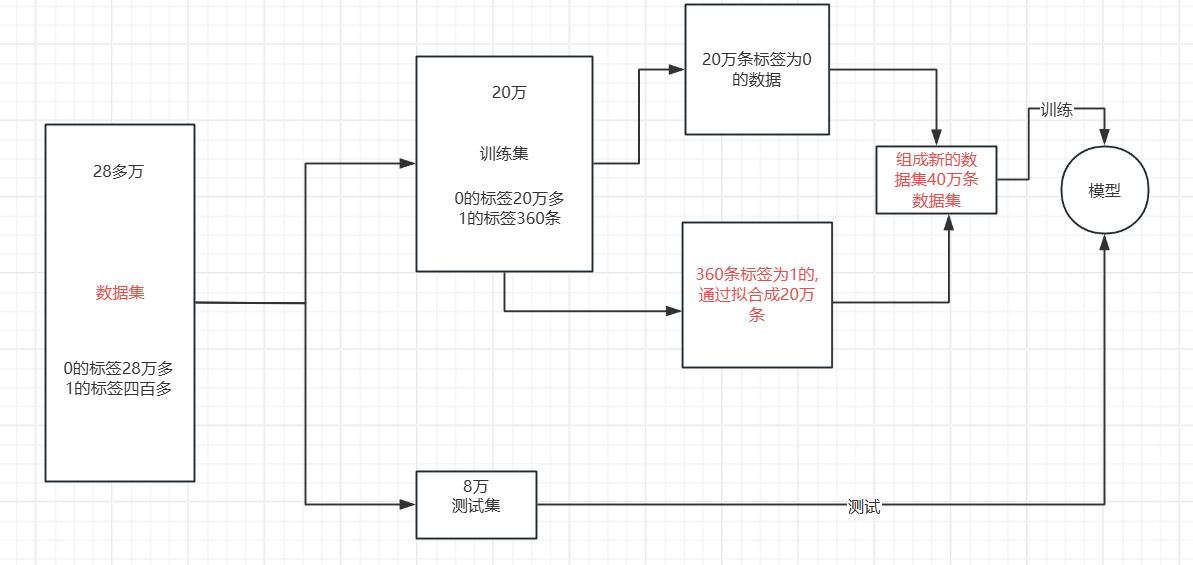
那我们依据什么拟合增加那么多数据呢 ?这就使用到了SMOTE 算法。
SMOTE 算法是一种用于解决分类问题中数据类别不平衡问题的技术。在很多实际的分类场景中,比如欺诈检测、疾病诊断等,少数类样本(如欺诈交易、患病样本)的数量往往远少于多数类样本(如正常交易、健康样本)。这种不平衡的数据分布会导致模型在训练时偏向于多数类,而对少数类的预测效果不佳。
SMOTE 算法的核心思想是通过对少数类样本进行分析,然后人工合成新的少数类样本并添加到数据集中,从而增加少数类样本的数量,使数据分布更加平衡。具体来说,SMOTE 算法会为每个少数类样本找到其在特征空间中的 k 个最近邻,然后在这些最近邻之间随机插值,生成新的合成样本。这些合成样本具有与原始少数类样本相似的特征分布,从而可以帮助模型更好地学习少数类的特征,提高对少数类样本的分类准确率。
SMOTE 算法:
- 对于少数类中每一个样本x,以欧氏距离为标准计算它到少数类样本集
中所有样本的距离,得到其k近邻。
- 根据样本不平衡比例设置一个采样比例以确定采样倍率N,对于每一个少数类样本x,从其k近邻中随机选择若干个样本,假设选择的近邻为xn。
- 对于每一个随机选出的近邻xn,分别与原样本按照如下的公式构建新的样本
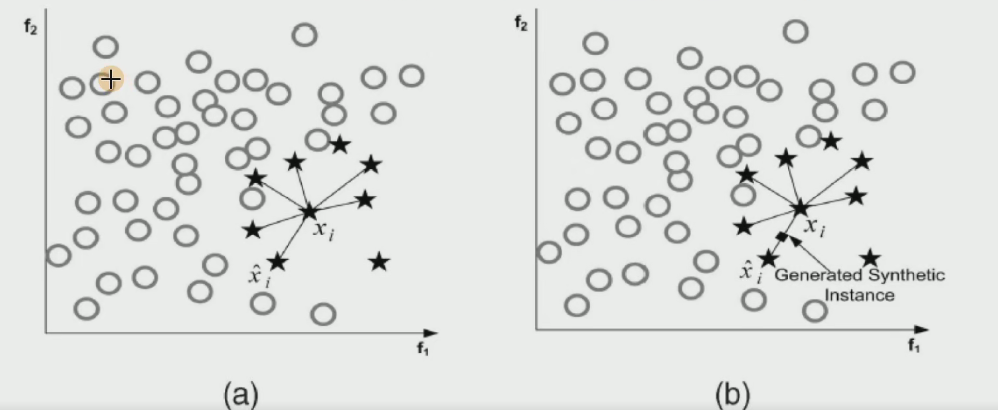 新生成的这些数据点都是在这些线上
新生成的这些数据点都是在这些线上
代码分析:
1.导入 SMOTE 类
python
from imblearn.over_sampling import SMOTE从imblearn库的过采样模块中导入SMOTE类,该类实现了合成少数类过采样技术。
2.初始化 SMOTE 对象
python
oversampler = SMOTE(random_state=0)创建一个 SMOTE 过采样器实例,random_state=0设置随机种子,确保结果的可重复性。
3.执行过采样
python
os_x_train, os_y_train = oversampler.fit_resample(x_train_w, y_train_w)fit_resample方法是 SMOTE 的核心操作,它会对少数类样本进行分析并合成新样本x_train_w是原始训练特征数据,y_train_w是对应的标签- 处理后返回
os_x_train(过采样后的特征数据)和os_y_train(过采样后的标签) - 此时的数据集已经通过合成少数类样本达到了类别平衡
4.划分训练集和测试集
经过过采样后得到的数据比较多,我们可以再一次进行数据集划分。
python
os_x_train_w, os_x_test_w, os_y_train_w, os_y_test_w = train_test_split(
os_x_train, os_y_train, test_size=0.2, random_state=0
)- 使用
train_test_split将过采样后的数据集划分为新的训练集和测试集 test_size=0.2表示将 20% 的数据作为测试集,80% 作为训练集random_state=0保证划分结果的可重复性- 返回四个变量分别为:过采样后的训练特征、过采样后的测试特征、过采样后的训练标签、过采样后的测试标签
完整代码:
只有中间部分跟下采样有所不同,其他步骤都是相同的
python
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
from sklearn.model_selection import cross_val_score
data=pd.read_csv("creditcard.csv")
scaler=StandardScaler()
data["Amount"]=scaler.fit_transform(data[["Amount"]])
data=data.drop(["Time"],axis=1)
x=data.iloc[:, :-1]
y=data.iloc[:, -1]
x_train_w,x_test_w,y_train_w,y_test_w=train_test_split(x,y,test_size=0.2,random_state=0)
from imblearn.over_sampling import SMOTE
oversampler=SMOTE(random_state=0)
os_x_train,os_y_train=oversampler.fit_resample(x_train_w,y_train_w)
os_x_train_w,os_x_test_w,os_y_train_w,os_y_test_w=train_test_split(os_x_train,os_y_train,test_size=0.2,random_state=0)
scores = []
c_param_range = [0.01, 0.1, 1, 10, 100]
for i in c_param_range:
lr = LogisticRegression(C=i, penalty="l2", solver='lbfgs', max_iter=10000)
# 使用平衡后的数据集进行交叉验证
score = cross_val_score(lr,os_x_train_w, os_y_train_w, cv=8, scoring="recall")
score_mean = sum(score) / len(score)
scores.append(score_mean)
print(f"C等于{i}的召回率为{score_mean}")
best_c=c_param_range[np.argmax(scores)]
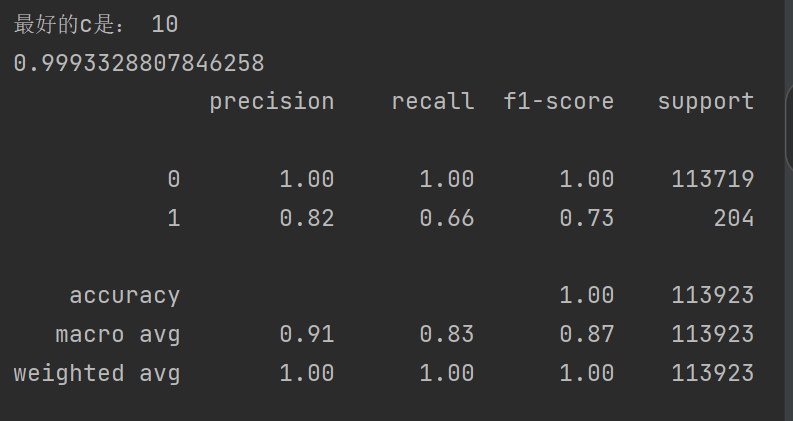
print("最好的c是:",best_c)
estimator=LogisticRegression(C=best_c)
estimator.fit(os_x_train_w,os_y_train_w)
test_predicted=estimator.predict(x_test_w)
print(metrics.classification_report(y_test_w,test_predicted))结果:
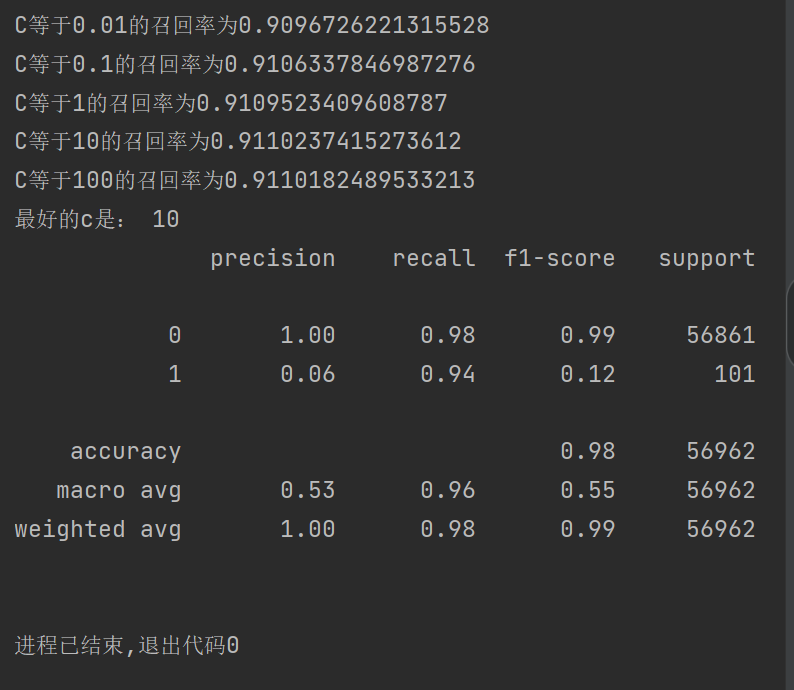
可以发现我们的召回率到达94%,效果又得到很大的提升 ,