介绍:Onnx模型部署到Arm64进行推理的简单教程。
测试平台:Linux (Arm64 rk3568)
1.将训练好的模型导出为onnx格式
可参考将 PyTorch 模型转换为 ONNX 格式_pytorch.bin转onnx-CSDN博客
2.下载onnxruntime运行库
需要根据目标部署平台和运行环境来选择下载版本。
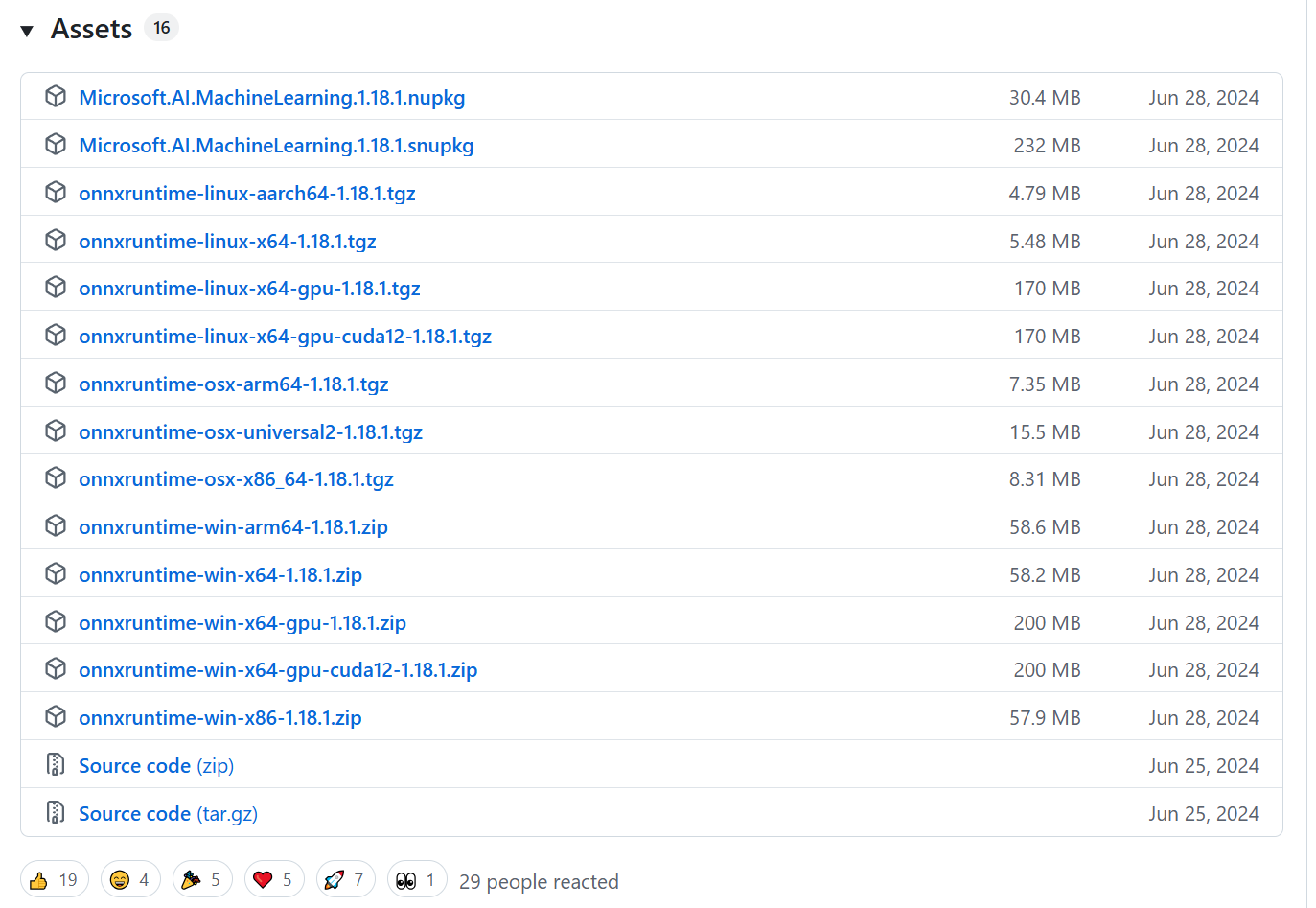
onnx历史版本:https://github.com/microsoft/onnxruntime/releases
点开某个版本下面的Assets,Source code是未编译的运行库文件,其他则是官方提供的已经编译好运行库,可以直接复制到目标平台上运行的文件。
比如我用的是onnxruntime-linux-aarch64-1.18.1.tgz,是用于arm64架构linux系统的运行库文件。
3.编写C++代码实现模型推理
用C++进行模型推理需要用到运行库的头文件(.h)和库文件(.so),分别位于include和lib文件夹里。
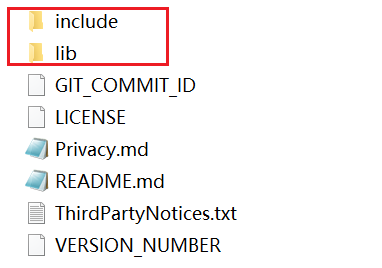
新建编写一个C++推理主程序文件main.cpp,引入onnxruntime_cxx_api.h头文件。
// main.cpp主程序文件
#include <vector>
#include <iostream>
#include "./include/onnxruntime_cxx_api.h"
using namespace std;
int main()
{
// 创建运行时环境变量
Ort::Env env(ORT_LOGGING_LEVEL_WARNING, "test");
Ort::SessionOptions session_options;
// 加载模型
std::string str = "/home/atom/app/onnx_test_arm/models/CNN.onnx";
const ORTCHAR_T* model_path = str.c_str();
Ort::Session session(env, model_path, session_options);
// 获取输入个数
int input_num = session.GetInputCount();
// 创建默认分配器
Ort::AllocatorWithDefaultOptions allocator;
std::vector<const char*> input_names;
std::vector<Ort::AllocatedStringPtr> input_name_ptrs;
// 获取输入名字
for (size_t i = 0; i < input_num; i++)
{
input_name_ptrs.emplace_back(session.GetInputNameAllocated(i, allocator));
input_names.push_back(input_name_ptrs.back().get());
}
// 获取输出个数
int output_num = session.GetOutputCount();
std::vector<const char*> output_names;
std::vector<Ort::AllocatedStringPtr> output_name_ptrs;
// 获取输入名字
for (size_t i = 0; i < output_num; i++)
{
output_name_ptrs.emplace_back(session.GetOutputNameAllocated(i, allocator));
output_names.push_back(output_name_ptrs.back().get());
}
/* CNN
* 该模型有三个输入,一个输出
*/
std::vector<int64_t> input_tensor_shape1 = { 1, 1, 400 }; // 第一个输入
std::vector<int64_t> input_tensor_shape2 = { 1, 1, 400 }; // 第二个输入
std::vector<int64_t> input_tensor_shape3 = { 1, 5 }; // 第三个输入
std::vector<float> input_tensor_values1(1 * 1 * 400, 1.0f); // 赋值,这里是假数据
std::vector<float> input_tensor_values2(1 * 1 * 400, 1.0f); // 赋值,这里是假数据
std::vector<float> input_tensor_values3(1 * 5, 1.0f); // 赋值,这里是假数据
std::vector<Ort::Value> ort_inputs;
// 创建输入张量1
Ort::MemoryInfo mem_info1 = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
ort_inputs.push_back(Ort::Value::CreateTensor<float>(
mem_info1,
input_tensor_values1.data(),
input_tensor_values1.size(),
input_tensor_shape1.data(),
input_tensor_shape1.size()
));
// 创建输入张量2
Ort::MemoryInfo mem_info2 = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
ort_inputs.push_back(Ort::Value::CreateTensor<float>(
mem_info2,
input_tensor_values2.data(),
input_tensor_values2.size(),
input_tensor_shape2.data(),
input_tensor_shape2.size()
));
// 创建输入张量3
Ort::MemoryInfo mem_info3 = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
ort_inputs.push_back(Ort::Value::CreateTensor<float>(
mem_info3,
input_tensor_values3.data(),
input_tensor_values3.size(),
input_tensor_shape3.data(),
input_tensor_shape3.size()
));
// 设置输出
std::vector<int64_t> output_tensor_shape = { 1, 5 }; // 假设输出维度
std::vector<float> output_tensor_values(1 * 5, 0.0f); // 初始化输出变量
Ort::MemoryInfo memory_info = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
std::vector<Ort::Value> output_tensors;
output_tensors.push_back(Ort::Value::CreateTensor<float>(
memory_info,
output_tensor_values.data(),
output_tensor_values.size(),
output_tensor_shape.data(),
output_tensor_shape.size()
));
// 执行推理
session.Run(Ort::RunOptions{ nullptr }, input_names.data(), ort_inputs.data(), input_num, output_names.data(), output_tensors.data(), output_num);
// output_tensor_values 的值就是模型推理结果
return 0;
}4.编译主程序并运行
将项目文件复制到arm机器上进行本地编译。
编译项目创建可执行文件的过程需要:包含.h头文件、链接.so库文件、编译main.cpp主程序。
这里提供常用的两种方法:
a. 文件较少,可以直接用命令行指令进行链接编译:
g++ -I./include main.cpp -L./lib -lonnxruntime -o mainb. 如果工程文件过多,可以使用cmake工具来进行编译。先编写CMakeLists.txt,
# CMakeLists.txt
cmake_minimum_required(VERSION 3.12)
project(onnx_test_arm)
# 设置C++标准
set(CMAKE_CXX_STANDARD 17)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
# 设置目标架构为ARM64
set(CMAKE_SYSTEM_PROCESSOR arm64)
# 添加可执行文件
add_executable(${PROJECT_NAME} main.cpp)
# 包含头文件目录
target_include_directories(${PROJECT_NAME} PRIVATE
${CMAKE_CURRENT_SOURCE_DIR}/include
)
# 设置库文件目录
set(LIB_DIR ${CMAKE_CURRENT_SOURCE_DIR}/lib)
# 添加链接目录
target_link_directories(${PROJECT_NAME} PRIVATE ${LIB_DIR})
# 链接所需的共享库
target_link_libraries(${PROJECT_NAME} PRIVATE
onnxruntime
# 添加其他依赖库(如果需要)
# onnxruntime_providers_shared
)
# 设置运行时库搜索路径(RPATH)
set_target_properties(${PROJECT_NAME} PROPERTIES
BUILD_RPATH "${LIB_DIR}"
INSTALL_RPATH "${LIB_DIR}"
INSTALL_RPATH_USE_LINK_PATH TRUE
)然后,执行cmake命令。
mkdir build
cd build
cmake ..
make找到生成的main可执行文件,在命令行输入可执行文件名字main就可以运行了。
额外说明:如果想要进行交叉编译(比如在Linux x86上编译主程序给arm运行),需要使用交叉编译工具来进行编译。
a. 命令行指令
aarch64-linux-gnu-g++ -I./include main.cpp -L./lib -lonnxruntime -o mainb.cmake
在上面的CMakeLists.txt基础上,需要额外再编写一个.cmake文件,来指定交叉编译工具。
#新建一个aarch64-toolchain.cmake
set(CMAKE_SYSTEM_NAME Linux)
set(CMAKE_SYSTEM_PROCESSOR aarch64)
# 指定交叉编译器路径
set(CMAKE_C_COMPILER aarch64-linux-gnu-gcc)
set(CMAKE_CXX_COMPILER aarch64-linux-gnu-g++)
# 仅在目标目录搜索库和头文件
set(CMAKE_FIND_ROOT_PATH_MODE_PROGRAM NEVER)
set(CMAKE_FIND_ROOT_PATH_MODE_LIBRARY ONLY)
set(CMAKE_FIND_ROOT_PATH_MODE_INCLUDE ONLY)执行cmake时带上这个新增的.cmake文件。
cmake -DCMAKE_TOOLCHAIN_FILE=./aarch64-toolchain.cmake ..
make