目录
- 前言
- 一、list的接口使用
-
- [1.1 构造+迭代器+范围for](#1.1 构造+迭代器+范围for)
- [1.2 find+insert+erase+list的迭代器失效问题](#1.2 find+insert+erase+list的迭代器失效问题)
- [1.3 reverse](#1.3 reverse)
- [1.4 sort + 迭代器分类](#1.4 sort + 迭代器分类)
-
- [1.4.1 sort相关性能分析(assign)](#1.4.1 sort相关性能分析(assign))
- [1.5 merge](#1.5 merge)
- [1.6 unique](#1.6 unique)
- [1.7 remove 和 remove_if](#1.7 remove 和 remove_if)
- [1.8 splice](#1.8 splice)
- 二、接口使用源码
- 结语


🎬 云泽Q :个人主页
🔥 专栏传送入口 : 《C语言》《数据结构》《C++》《Linux》
⛺️遇见安然遇见你,不负代码不负卿~
前言
大家好啊,我是云泽Q,欢迎阅读我的文章,一名热爱计算机技术的在校大学生,喜欢在课余时间做一些计算机技术的总结性文章,希望我的文章能为你解答困惑~
一、list的接口使用
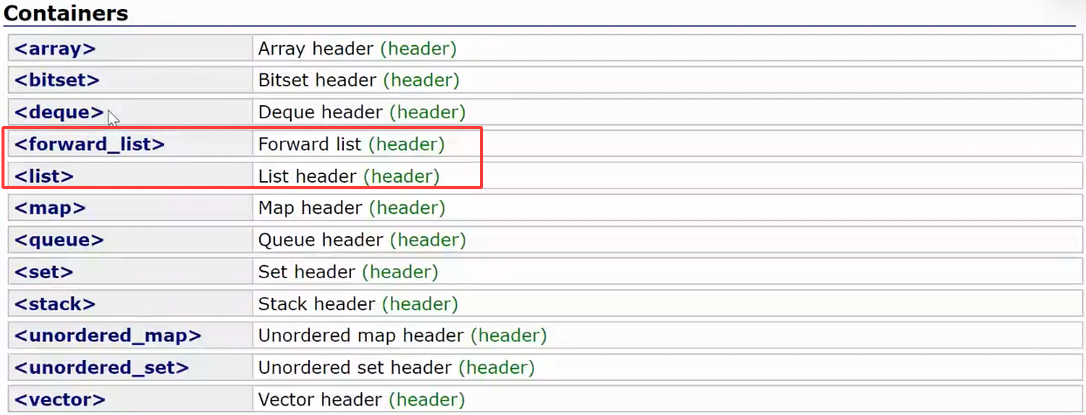
STL库中的list是个带头双向循环链表 ,所以其能在任意位置进行插入删除,不需要挪动数据

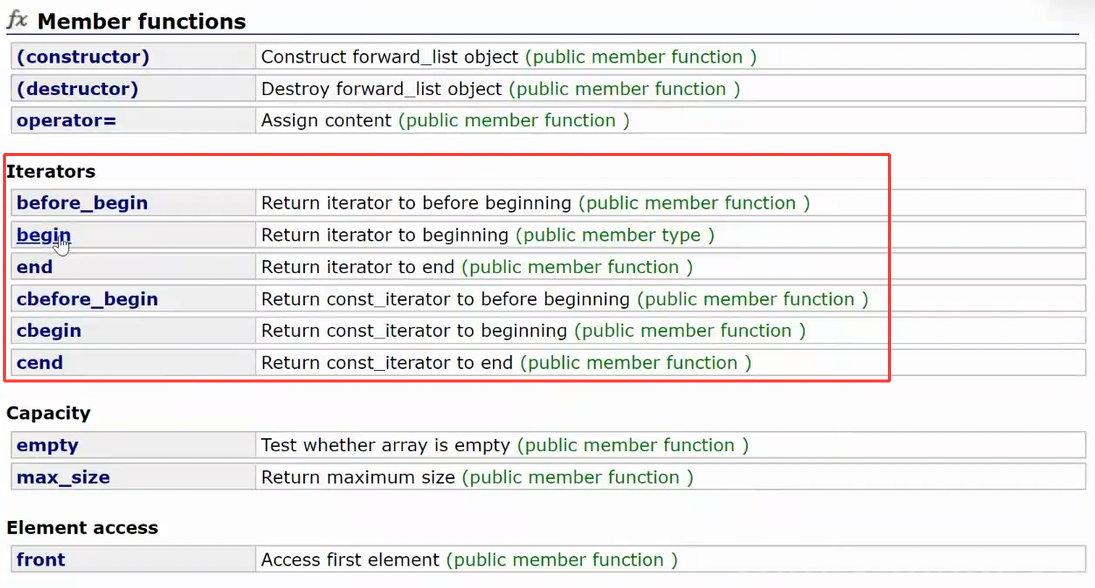
STL库中还有一个单链表叫forward_list,只不过用的很少
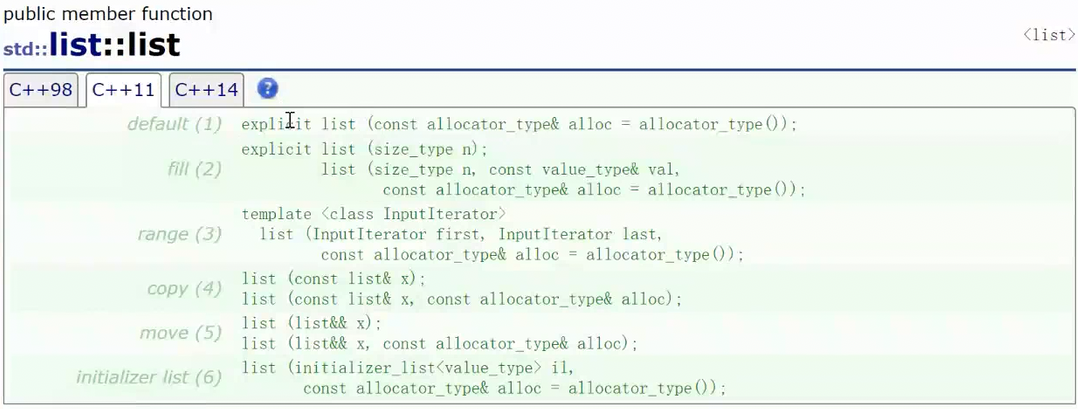
list的构造
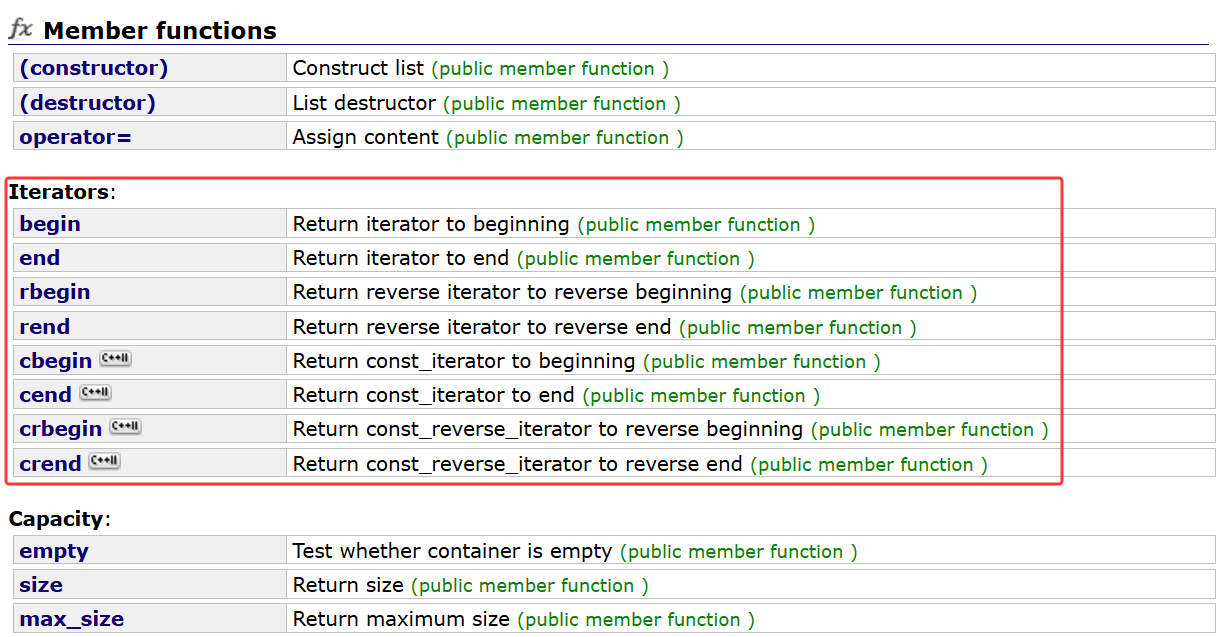
list的迭代器是双向的,可以正着走也可以倒着走
且list也没有reserve的概念了,毕竟没有扩容了,也没有capacity了
单链表的迭代器就没有rbegin,rend,只有begin,end,只支持加加,不支持减减
list访问数据也不支持下标方括号了,因为其底层不是连续的物理空间,支持方括号的代价就太高了,只支持迭代器访问

插入删除支持的接口很多
1.1 构造+迭代器+范围for
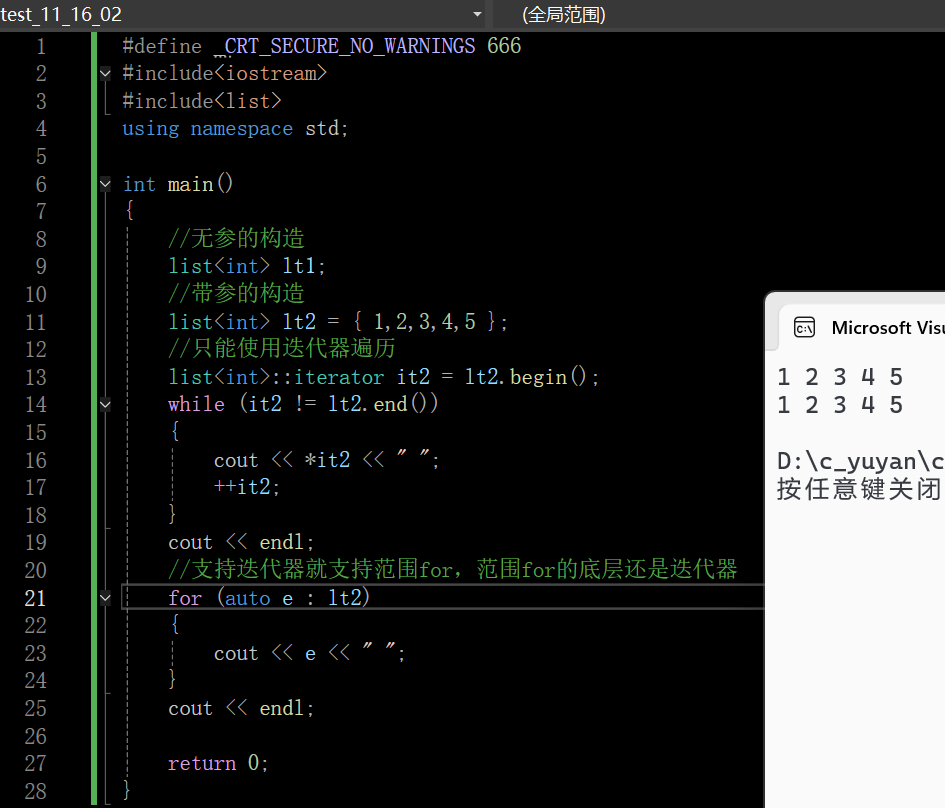
这里说一下图中范围for的代码逻辑:
一、范围 for 的本质:迭代器遍历的 "语法糖"
C++11 引入的范围 for(for (auto e : 容器))是编译器提供的语法简化,其底层完全依赖迭代器遍历。对于代码中的 for (auto e : lt2),编译器会自动将其转换为基于迭代器的循环结构。
二、底层转换的详细步骤
以 for (auto e : lt2) 为例(lt2 是 std::list),编译器会执行以下转换:
- 获取迭代器的起始和结束位置
调用容器的 begin() 和 end() 成员函数,分别获取起始迭代器(指向第一个元素)和结束迭代器(指向 "尾后位置",不存储实际元素)。
等价代码:
cpp
auto __begin = lt2.begin(); // 起始迭代器,指向第一个元素
auto __end = lt2.end(); // 结束迭代器,指向尾后位置- 循环遍历逻辑以 "起始迭代器!= 结束迭代器" 为条件,循环执行以下操作:
-
- 解引用迭代器 * __begin,获取当前元素的值;
-
- 将该值赋值给循环变量 e(auto 会推导为 int 类型,因为 lt2 存储的是 int);
-
- 迭代器自增(++__begin),移动到下一个元素。
等价代码:
- 迭代器自增(++__begin),移动到下一个元素。
cpp
for (; __begin != __end; ++__begin) {
auto e = *__begin; // 解引用迭代器,获取元素值
cout << e << " "; // 输出元素
}三、范围 for 的适用条件
范围 for 能工作的核心前提是:
- 容器(或对象)必须支持 **begin() 和 end() 操作 **(可以是成员函数,也可以是全局的 std::begin/std::end 函数);
- 迭代器必须支持前置自增(++)、不等于比较(!=)、解引用( * ) 操作。
以 std::list 为例:
- 它的 begin()/end() 是成员函数,返回双向迭代器;
- 该迭代器支持 ++(移动到下一个节点)、!=(判断是否到尾后)、*(获取节点值),因此完全兼容范围 for。
四、与手动迭代器遍历的对比
手动迭代器遍历的代码是:
cpp
list<int>::iterator it = lt2.begin();
while (it != lt2.end()) {
cout << *it << " ";
++it;
}范围 for 只是将上述逻辑隐藏在编译器转换中,让代码更简洁、可读性更高。
1.2 find+insert+erase+list的迭代器失效问题
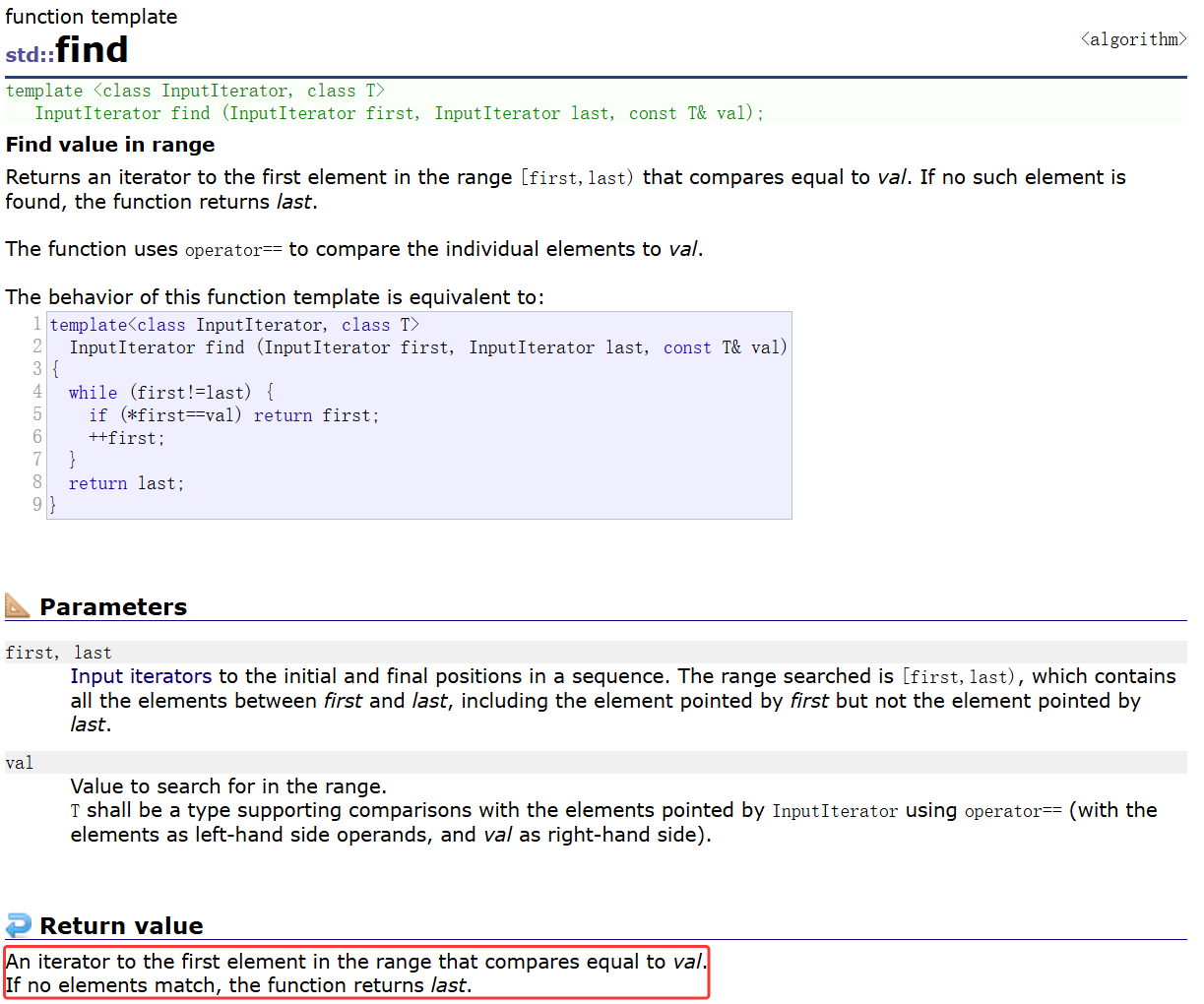
list是没有提供find接口的,若想使用find就要使用算法库中的find
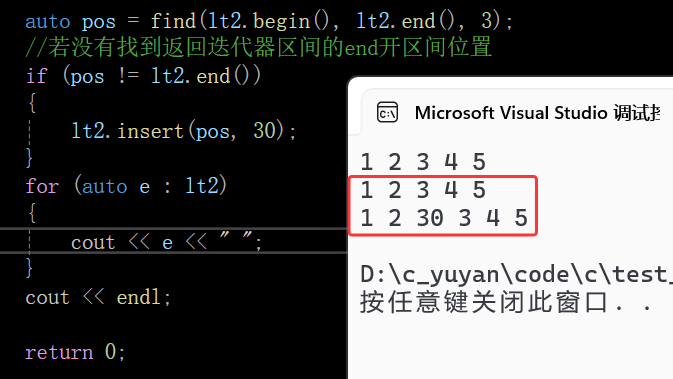
list的insert就不会出现迭代器失效了,由于list是带头双向循环链表,在3这个结点前插入数据,不存在挪动数据扩容之类的问题

但是list的erase会出现迭代器失效,因为是把pos指向的底层的结点删除了
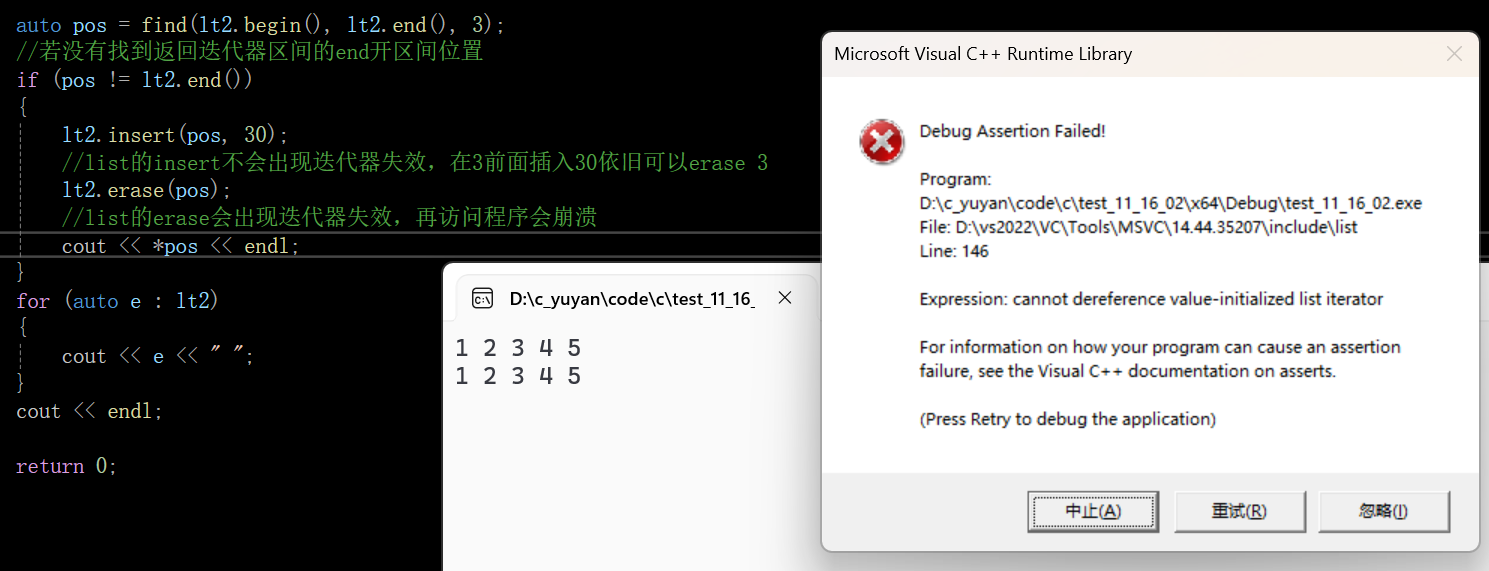
所以erase后就不能使用指向pos位置的迭代器了
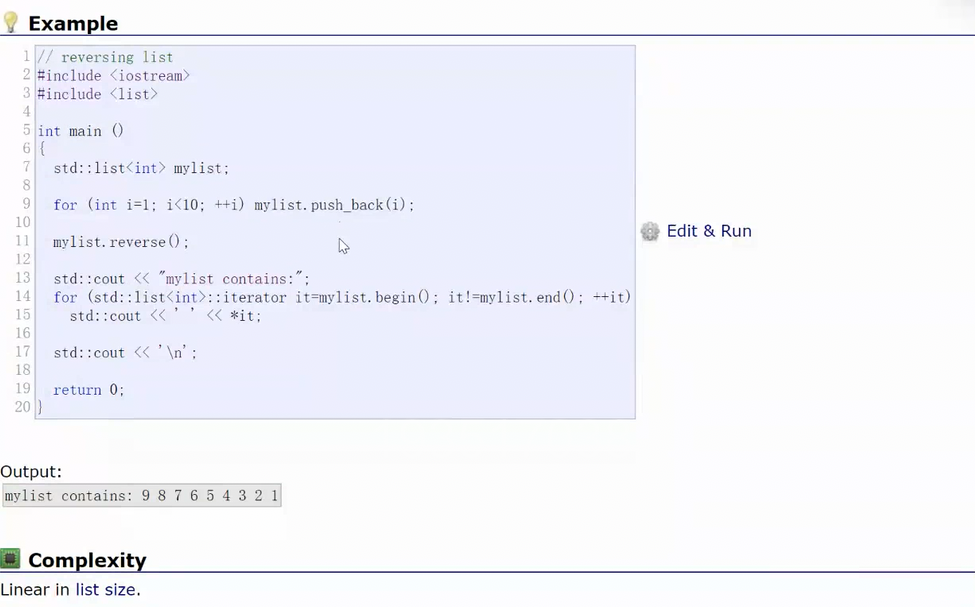
1.3 reverse
list还有一些其他相关的操作

list单独实现了一个自己的逆置函数,就是把带头双向循环链表反转一下
1.4 sort + 迭代器分类
这里list容器内部实现了自己的sort函数,而不是用算法库中的sort的原因也牵扯到迭代器的分类
功能角度:按操作能力(是由容器的底层结构决定)

list中拥有的迭代器类型
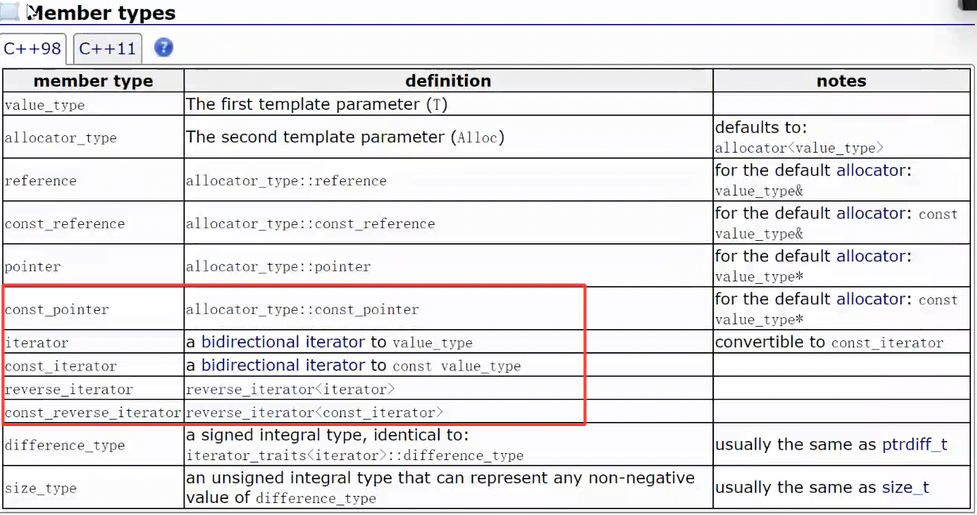
forward_list拥有的迭代器类型

vector拥有的迭代器类型
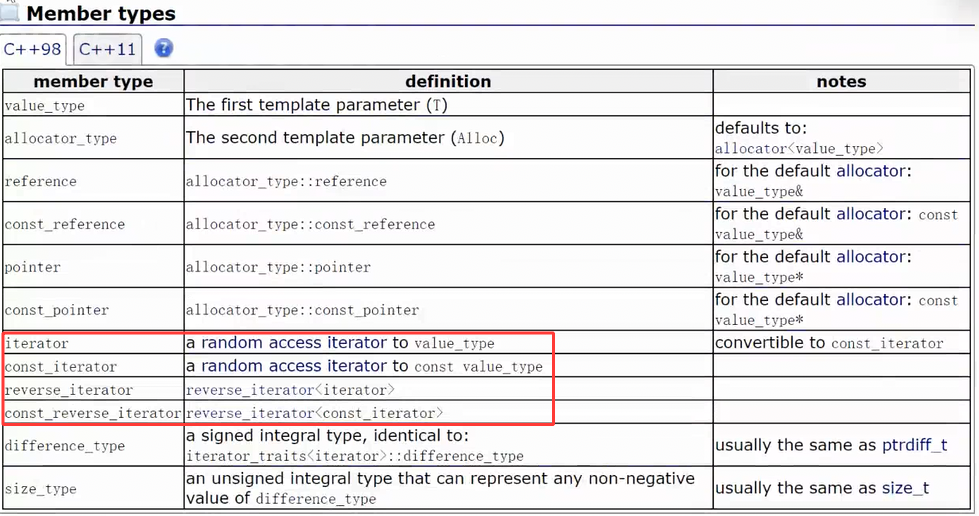
使用角度:按遍历方向 + 读写权限

其次就是具体原因:
一、std::list的底层结构与迭代器限制
std::list是 C++ STL 中双向链表的实现,其底层结构是:
- 每个元素被封装在独立的节点中,节点包含:数据域(存储元素)、前驱指针(指向前一个节点)、后继指针(指向后一个节点);
- 节点在内存中非连续存储(地址随机),只能通过指针依次访问(无法直接跳转到第 n 个元素)。
这种结构直接决定了std::list的迭代器类型是 "双向迭代器(Bidirectional Iterator)",它仅支持以下操作:
- 自增(++it):移动到下一个节点;
- 自减(--it):移动到上一个节点;
- 解引用( * it):获取当前节点的元素;
- 不等于比较(it1 != it2):判断是否指向同一个节点。
关键限制:双向迭代器不支持随机访问(如it + 3、it - 2这类直接跳转操作),也无法通过\[\]运算符访问指定位置的元素。
二、算法库std::sort的核心依赖:随机访问迭代器
标准库中的std::sort(定义在< algorithm >中)是一个通用排序算法,其内部实现通常基于快速排序(或其改进版,如 introsort,因为快排在情况最差的情况会有性能退化),这类算法的高效性严重依赖于随机访问能力,具体表现为:
- 频繁访问 "中间元素":快速排序需要选取 "枢轴元素"(通常是序列中间的元素),这要求能通过begin + (end - begin) / 2直接定位到中间位置;
- 高效交换元素:排序过程中需要交换任意位置的元素,依赖迭代器的+、-操作快速计算元素位置;
- 计算区间长度:需要通过end - begin快速获取序列长度,用于判断是否继续递归排序。
这些操作都要求迭代器必须是 "随机访问迭代器(Random Access Iterator)"------ 这种迭代器支持+、-、\[\]、<、>等操作(如std::vector、std::array的迭代器)。
三、std::list用std::sort报错的根本原因:迭代器类型不兼容
由于std::list的迭代器是双向迭代器,而std::sort要求随机访问迭代器,两者的 "能力集" 不匹配:
- 当调用std::sort(list.begin(), list.end())时,编译器会检查迭代器类型是否满足std::sort的模板要求(通过迭代器特性std::iterator_traits判断);
- 由于双向迭代器缺少std::sort必需的随机访问操作(如+、-),编译器会触发模板实例化失败,报 "迭代器类型不匹配" 的错误(通常提示 "没有与操作符 + 匹配的重载")。
四、std::list自带sort成员函数的原因:适配链表特性的高效实现
std::list的成员函数sort是专门为链表结构设计的,其核心逻辑基于归并排序(Merge Sort,库中基于list结构特殊处理过的变形优化过的归并排序),这种算法的特性完美适配链表:
- 归并排序的核心操作是 "合并两个有序序列",对于链表而言,合并仅需调整节点的前驱 / 后继指针(无需移动元素本身),时间复杂度为 O (n),效率极高;
- 归并排序不需要随机访问,仅需顺序遍历(通过双向迭代器的++操作即可完成),完全兼容链表的迭代器能力;
- 避免元素拷贝开销:链表节点的 "值" 通常存储在堆上,归并排序通过指针调整完成排序,无需复制元素(而std::sort对链表排序时,每次交换都需要拷贝元素,开销极大)。
因此,list::sort的时间复杂度是 O (n log n),且常数因子远低于 "强行用std::sort对链表排序" 的情况(后者即使能编译,也会因频繁的迭代器移动和元素拷贝导致效率骤降)。
1.4.1 sort相关性能分析(assign)
list内实现的sort在数据量小的时候可以使用,但是在数据量大的时候就效率不高了。虽然归并排序和快速排序的时间复杂度为 O (n log n),但是时间复杂度只是算其的性能属于哪个量级,但是二者还是有大概一两倍的差异,二者的差异除了算法上的差异,真正的差异在于访问数据的差异
下面看一下二者的性能差异,在Release平台下测试一下性能对比(Debug平台下测试的性能不能作为性能对比的依据,尤其是递归)
- Debug 模式禁用了编译器优化,导致代码执行效率失真
编译器的优化(如 Visual Studio 的/O2、GCC 的-O3)是提升代码性能的关键,而 Debug 模式为了保留调试所需的代码原貌,会强制关闭几乎所有优化,包括:
- 函数内联:递归本质是重复调用自身函数,Release 模式下编译器可能对简单递归进行 "内联优化"(将函数调用直接展开为代码块),减少函数调用的栈开销;但 Debug 模式会保留每一次完整的函数调用,导致递归的栈操作(压栈、弹栈)开销被放大。
- 尾递归优化:对于符合尾递归特征(递归调用是函数最后一步操作)的代码,Release 模式可能将其优化为循环(消除栈溢出风险,同时减少栈操作开销),但 Debug 模式会严格保留递归调用的原始逻辑,导致性能差异极大。
- 循环 / 分支优化:递归中常包含的循环、条件判断,在 Release 模式下可能被优化(如循环展开、分支预测优化),而 Debug 模式会按原始代码执行,进一步拉大性能差距。
- Debug 模式插入大量调试代码,引入额外性能开销
为了支持断点调试、变量监视、内存检查等功能,Debug 模式会在代码中插入大量 "调试辅助代码",例如:
- 变量地址追踪:保留所有变量的内存地址不变,禁止编译器对变量进行寄存器缓存(强制从内存读写),而递归中频繁的变量访问会因此产生额外的内存 IO 开销。
- 栈帧完整性检查:每次函数调用(包括递归)都会插入栈帧校验代码(如检查栈溢出、保存完整的调用栈信息),这对递归这种 "高频函数调用" 场景来说,会累积成巨大的额外开销。
- 内存越界检测 :对数组、指针操作插入边界检查(如 Visual Studio 的_CRTDBG_MAP_ALLOC),递归中若涉及内存操作(如递归处理数组),会进一步拖慢执行速度。
这些额外代码与业务逻辑无关,但会显著增加执行时间,且不同代码(如递归 vs 循环)受这些额外开销的影响程度不同,导致性能对比失去公平性。
- 递归的 "栈敏感特性" 被 Debug 模式放大
递归的性能本身高度依赖函数调用栈的效率:
- 每次递归调用都需要在栈上分配栈帧(保存返回地址、局部变量、寄存器状态等),递归深度越大,栈操作的累积开销越明显。
- 在 Release 模式下,编译器会通过优化减少栈帧大小(如复用寄存器、合并局部变量),甚至消除栈操作(如尾递归转循环);但在 Debug 模式下,栈帧会被完整保留,且每次调用的栈操作无法优化,导致递归的性能被严重低估(与实际运行场景偏差极大)。
相比之下,非递归代码(如循环)对栈操作的依赖较弱,受 Debug 模式的影响相对较小,这会进一步导致 "递归 vs 非递归" 的性能对比结果失真。
Debug 模式的核心目标是 "可调试性",而非 "性能真实性"。其关闭优化、插入调试代码的特性,会对依赖高频函数调用(如递归)的代码产生不成比例的性能干扰,导致测试结果无法反映代码在实际运行环境(Release 模式)中的真实性能差异。因此,性能测试(尤其是递归这类对调用开销敏感的场景)必须在开启编译器优化的 Release 模式下进行,才能得到可信的对比结果。
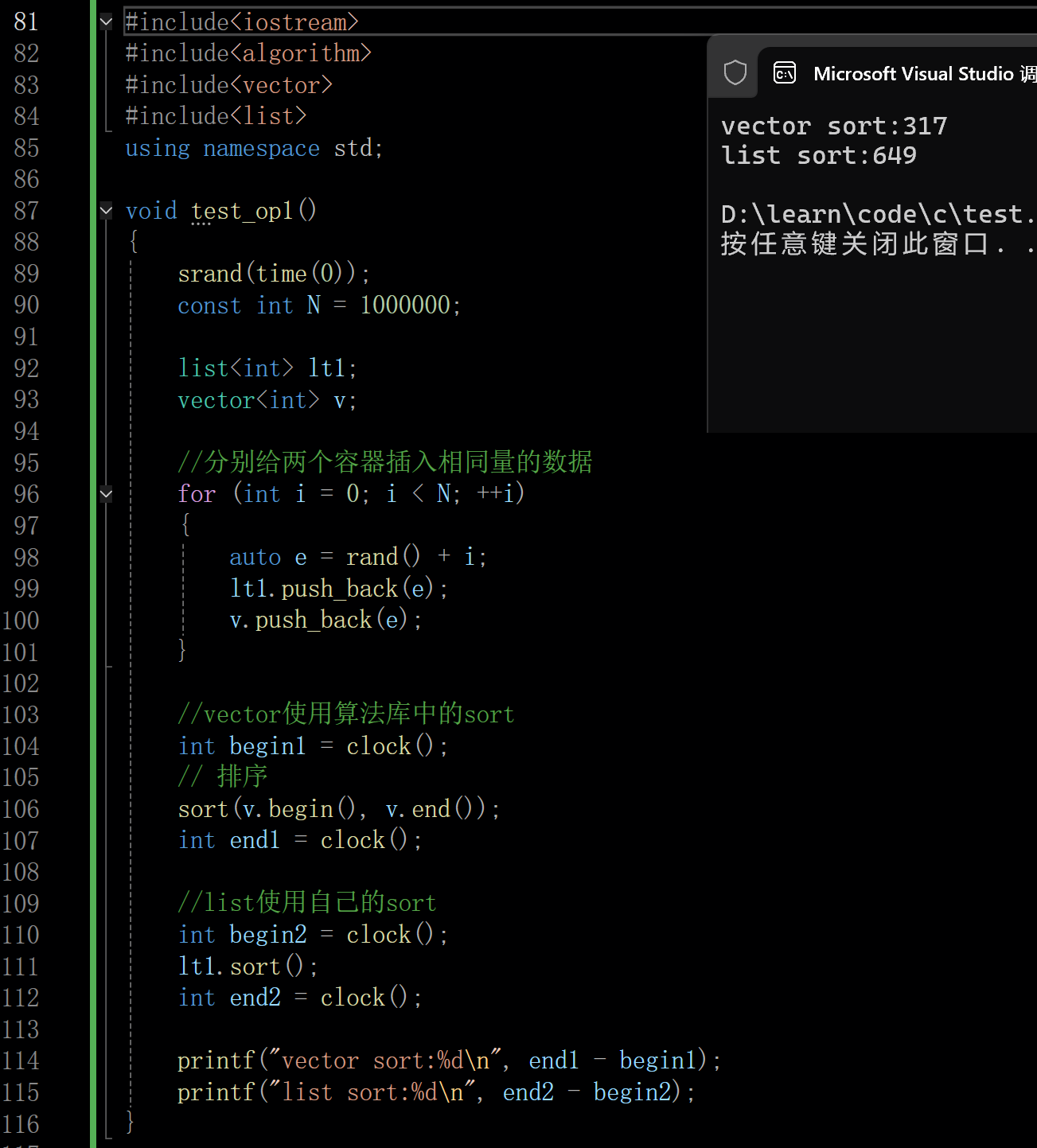
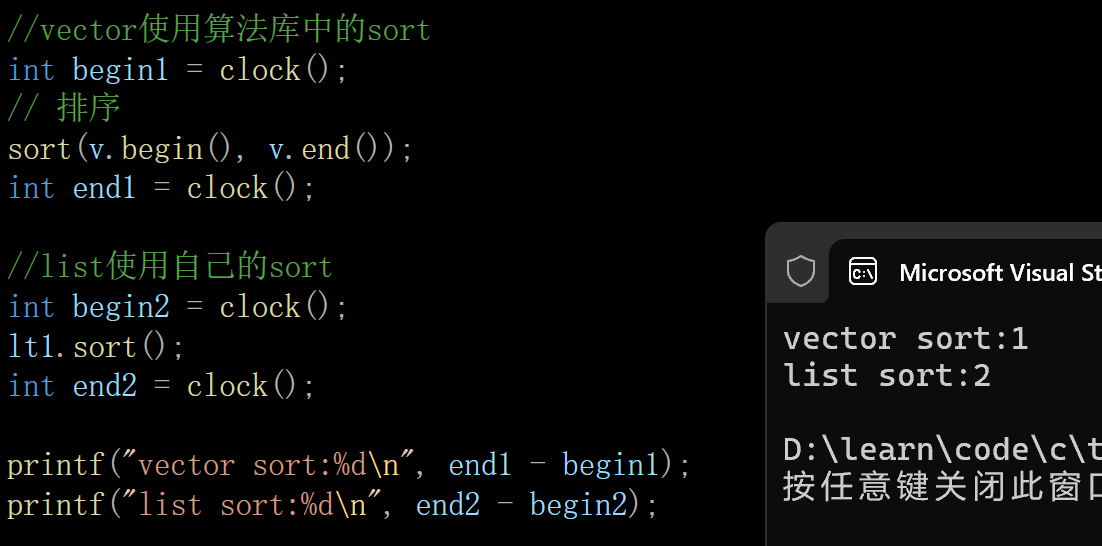
可以看出算法库中sort的性能比list中的sort中的性能快两倍差不多,所以list中的sort还是少用,这是一百万个数据的测试,1w个数据性能差距就不大了
归并排序和快速排序在进行数组排序的时候效率几乎没有差异的,前面数据结构的排序算法的性能测试我有写。这也体现出在大量访问数据的情况下(例如这里的排序),用vector这样具有连续物理空间存储数据的访问效率更高(结构造成的差异,不是算法本身的差异,只要不是大量的在头部中间插入删除,顺序表用来存储访问数据是个很不错的方案),这里还涉及CPU高速缓存的问题,在C++栈和队列的双端队列我会写
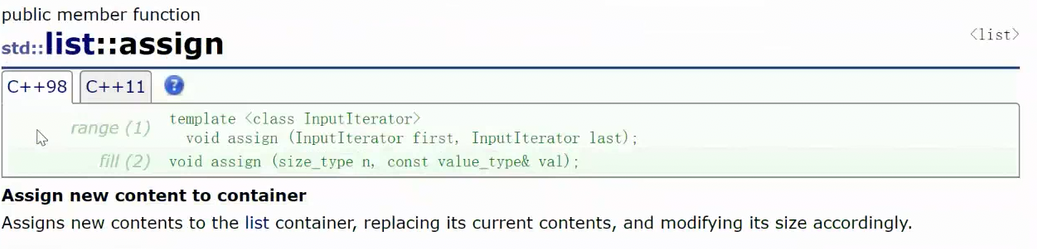
下面也是一个测试,不过是在两个链表中插入数据,第二个打印是直接用list中的sort的结果,第一个打印是先将list中的数据拷贝到vector(链表用不了算法库中的sort),然后在vector使用算法库中的sort,然后再将vector中的数据拷贝回list(链表中已经有数据,所以用assign,而不是直接赋值,直接赋值一般用在同容器之间的拷贝,assign支持不同容器之间的迭代器区间赋值)
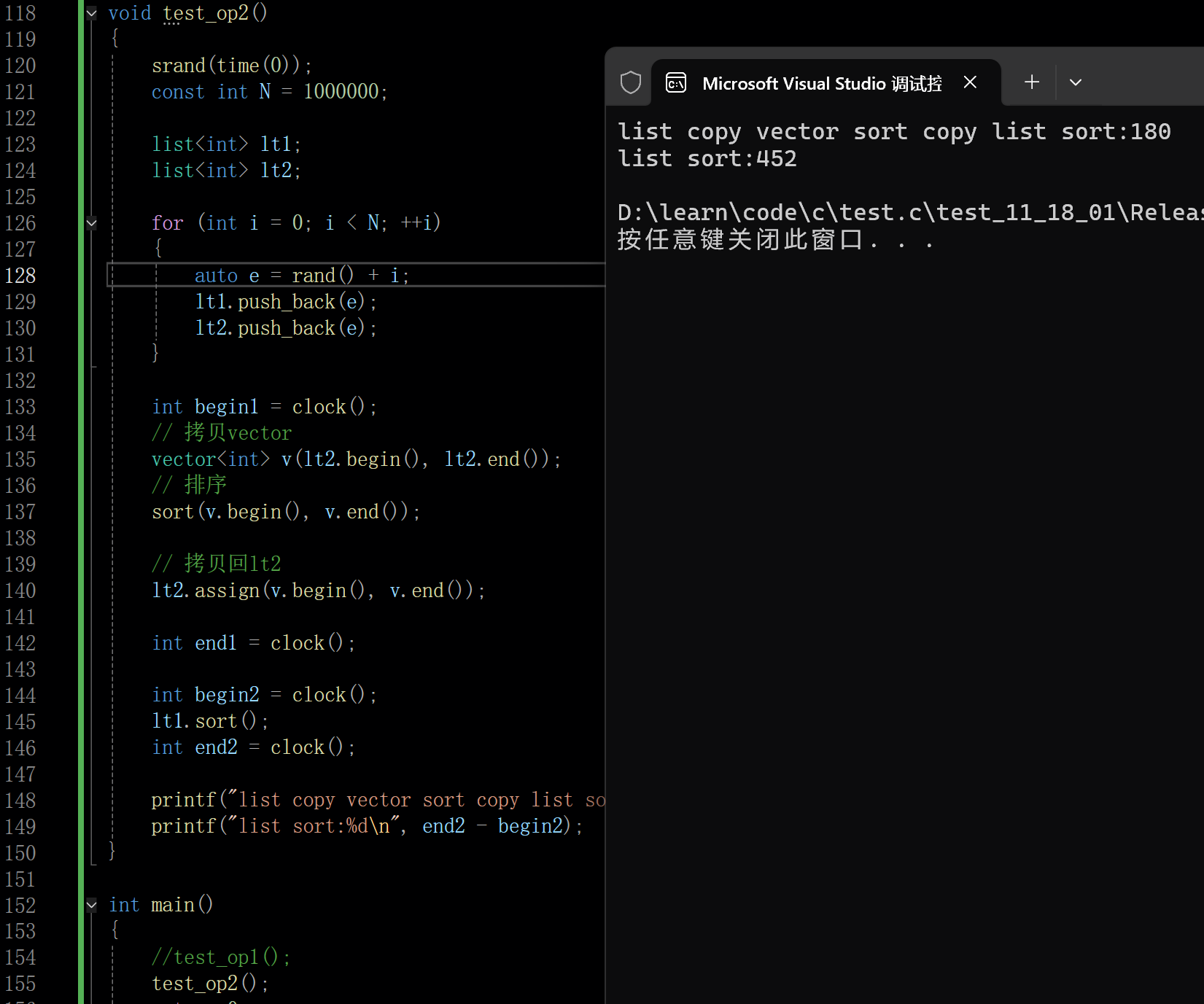
在该场景下使用算法库中的sort效率依旧比list中的sort效率快两倍多

算法库中sort的形参名称也暗示了什么类型的迭代器适用该函数
cpp
list<int> lt2 = { 1,2,3,4,5 };
//sort(lt2.begin(), lt2.end());不支持,会报错
lt2.sort();再比如说算法库中的reverse
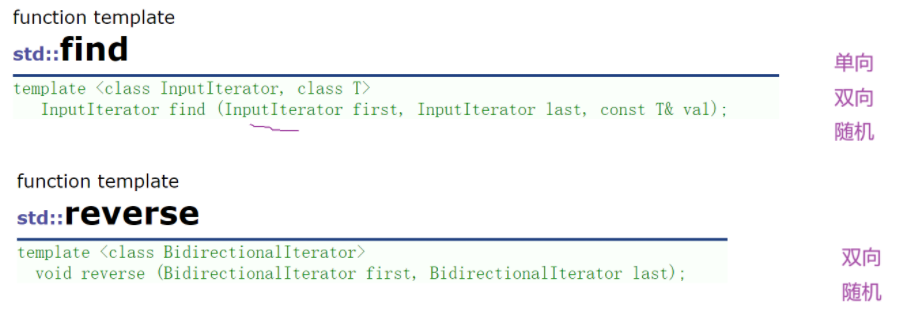
这里reverse要求双向迭代器,但随机迭代器(例如string的迭代器)也可以使用逆置的原因是一种继承关系
继承就是子类是一个特殊的父类(存在一个父子关系,父类满足的子类都满足),随机迭代器是一个特殊的双向迭代器,随机迭代器也是一个特殊的单向迭代器,双向迭代器也是一个特殊的单向迭代器。这些关系就如正方形是一个特殊的长方形一样

这里就意味着要求随机只能传随机,要求双向既可以传双向也可以传随机,如果形参是一个Forward Iterator,既可以传单向也可以传双向也可以传随机
后面我会单独写一篇继承的文章,继承还做了一层高度抽象
InputIterator就是只写,OutputIterator就是只读,可以认为所有的迭代器都是只写/只读的迭代器
就比如说算法库中的find

1.5 merge
归并要求两个链表必须是有序的(归并前先排序,和归并排序一样),将一个链表归并到另外一个链表
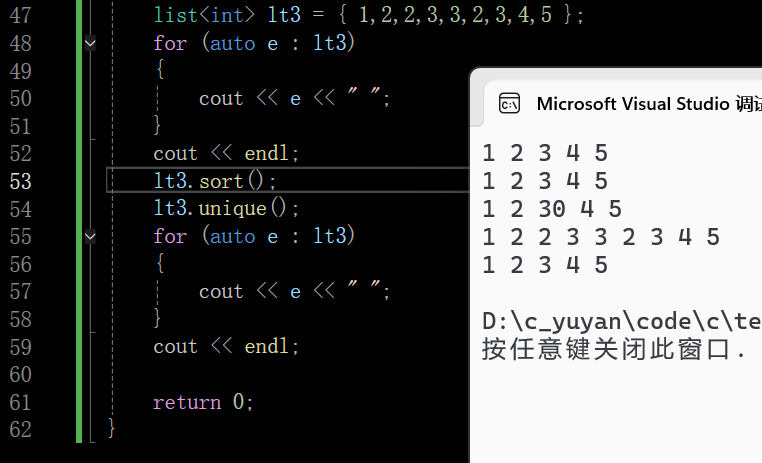
1.6 unique
去重也是要求先排序的,把重复的数据去掉只留下一个,过程类似双指针去重,一前一后两个指针,若两个指针指向的值相同,就把后一个值删掉
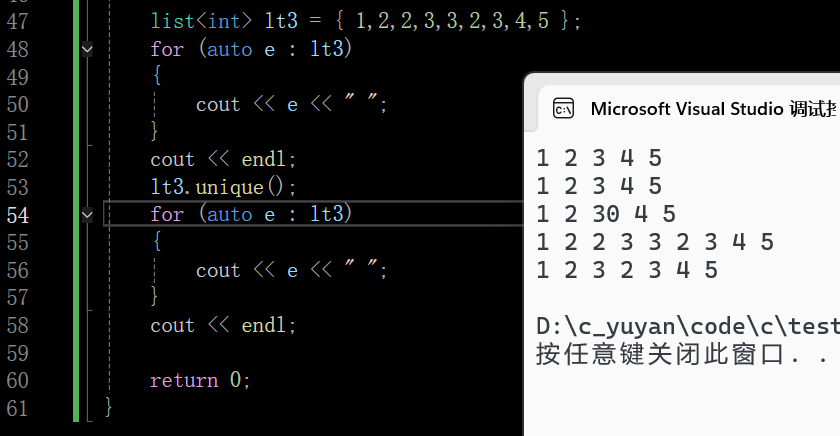
如图不经过排序,不相邻的值是无法完成去重的
1.7 remove 和 remove_if

remove和erase有相似支持,erase是给一个迭代器位置去删除迭代器指向的值,remove是给一个值去删除
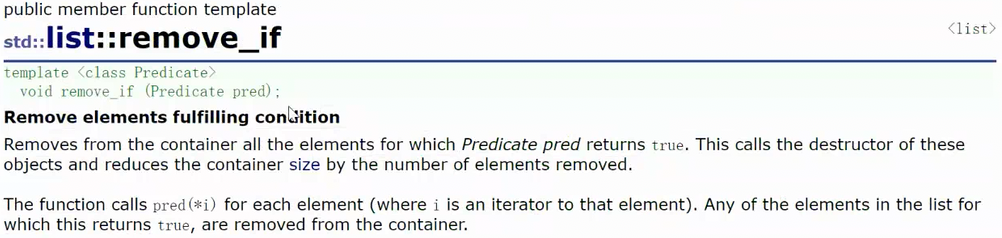
remove_if设计一个仿函数问题,满足某个条件才删除(该条件用仿函数实现)
1.8 splice
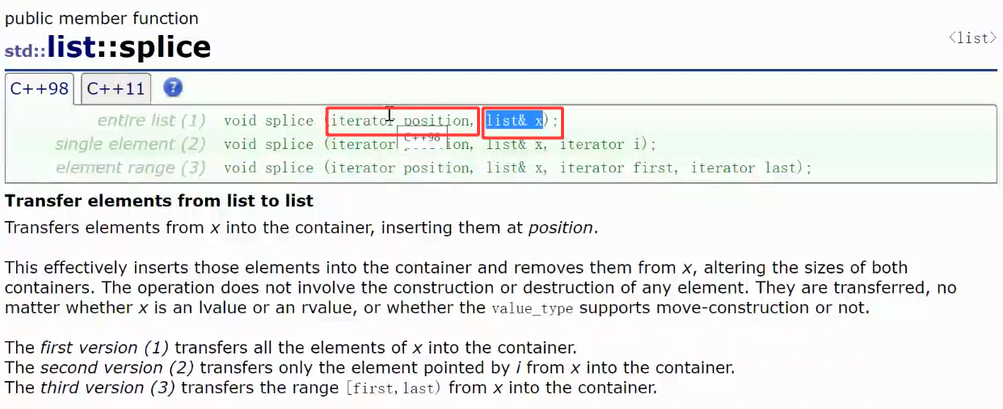
它叫接合,本质上是一种转移,可以把一个链表里的结点挪到另外一个链表中去
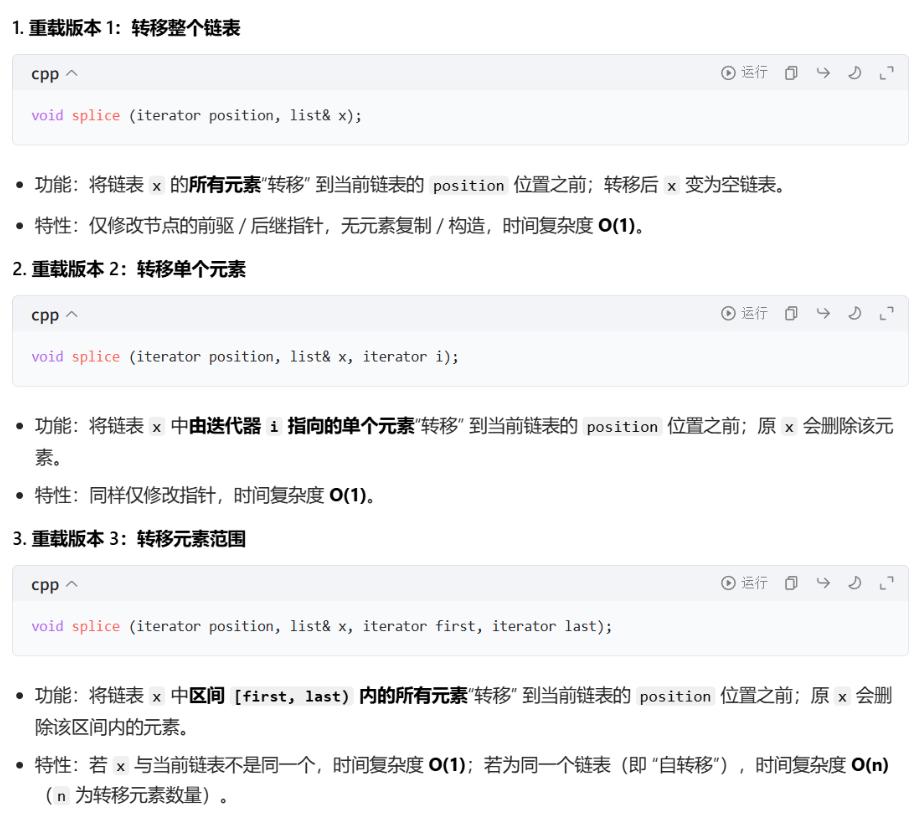
但是其也可以在当前链表进行挪动,不仅限于两个链表之间的挪动
二、接口使用源码
cpp
#define _CRT_SECURE_NO_WARNINGS 666
//#include<iostream>
//#include<list>
//#include<algorithm>
//using namespace std;
//
//int main()
//{
// ////无参的构造
// //list<int> lt1;
// ////带参的构造
// //list<int> lt2 = { 1,2,3,4,5 };
// ////只能使用迭代器遍历
// //list<int>::iterator it2 = lt2.begin();
// //while (it2 != lt2.end())
// //{
// // cout << *it2 << " ";
// // ++it2;
// //}
// //cout << endl;
// ////支持迭代器就支持范围for,范围for的底层还是迭代器
// //for (auto e : lt2)
// //{
// // cout << e << " ";
// //}
// //cout << endl;
//
// //auto pos = find(lt2.begin(), lt2.end(), 3);
// ////若没有找到返回迭代器区间的end开区间位置
// //if (pos != lt2.end())
// //{
// // lt2.insert(pos, 30);
// // //list的insert不会出现迭代器失效,在3前面插入30依旧可以erase 3
// // lt2.erase(pos);
// // //list的erase会出现迭代器失效,再访问程序会崩溃
// // //cout << *pos << endl;
// //}
// //for (auto e : lt2)
// //{
// // cout << e << " ";
// //}
// //cout << endl;
//
// ////sort(lt2.begin(), lt2.end());会报错
// //lt2.sort();
//
// //list<int> lt3 = { 1,2,2,3,3,2,3,4,5 };
// //for (auto e : lt3)
// //{
// // cout << e << " ";
// //}
// //cout << endl;
// //lt3.sort();
// //lt3.unique();
// //for (auto e : lt3)
// //{
// // cout << e << " ";
// //}
// //cout << endl;
//
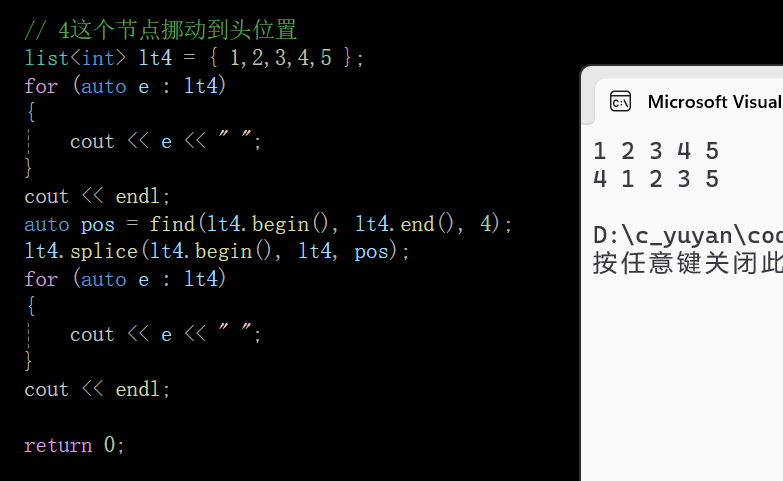
// // 4这个节点挪动到头位置
// list<int> lt4 = { 1,2,3,4,5 };
// for (auto e : lt4)
// {
// cout << e << " ";
// }
// cout << endl;
// auto pos = find(lt4.begin(), lt4.end(), 4);
// lt4.splice(lt4.begin(), lt4, pos);
// for (auto e : lt4)
// {
// cout << e << " ";
// }
// cout << endl;
//
// return 0;
//}
//////////////////////////////////////////////////////
#include<iostream>
#include<algorithm>
#include<vector>
#include<list>
using namespace std;
void test_op1()
{
srand(time(0));
const int N = 10000;
list<int> lt1;
vector<int> v;
//分别给两个容器插入相同量的数据
for (int i = 0; i < N; ++i)
{
auto e = rand() + i;
lt1.push_back(e);
v.push_back(e);
}
//vector使用算法库中的sort
int begin1 = clock();
// 排序
sort(v.begin(), v.end());
int end1 = clock();
//list使用自己的sort
int begin2 = clock();
lt1.sort();
int end2 = clock();
printf("vector sort:%d\n", end1 - begin1);
printf("list sort:%d\n", end2 - begin2);
}
void test_op2()
{
srand(time(0));
const int N = 1000000;
list<int> lt1;
list<int> lt2;
for (int i = 0; i < N; ++i)
{
auto e = rand() + i;
lt1.push_back(e);
lt2.push_back(e);
}
int begin1 = clock();
// 拷贝vector
vector<int> v(lt2.begin(), lt2.end());
// 排序
sort(v.begin(), v.end());
// 拷贝回lt2
lt2.assign(v.begin(), v.end());
int end1 = clock();
int begin2 = clock();
lt1.sort();
int end2 = clock();
printf("list copy vector sort copy list sort:%d\n", end1 - begin1);
printf("list sort:%d\n", end2 - begin2);
}
int main()
{
//test_op1();
test_op2();
return 0;
}结语
