2.2、string-最基本的数据类型
- 是二进制安全的,可以包含任何数据。比如jpg图片或者序列化的对象等.
- 最大能存储512M,动态数组,会+1M进行扩容
- 安全:不同于C语言以'\0'作为字符串的结束标志,而是以长度来决定字符串的结束位置。
- 提供了三种不同的编码方式(int, embstr, raw)
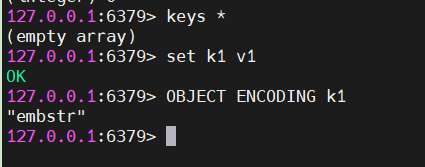
结合上面的dictEntry结构体,可以发现,k1和V1都是字符串,但是作者都没直接使用C语言的字符数组或者指针来进行存储,而是void*指针
再执行OBJECT ENCODING K1得到的结果是embstr,说明底层使用的是动态字符串sds。
而value 并不是直接指向sds,而是指向了redisObject对象,再通过redisObject的 ptr指向sds 。
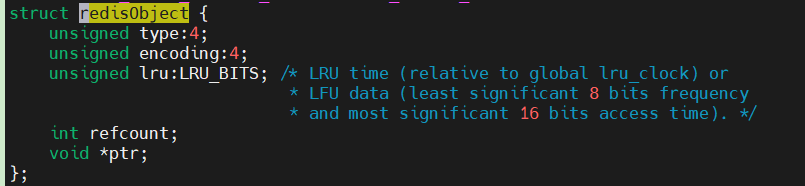
回顾redisObject结构体:
c
struct redisObject {
unsigned type:4; // 当前值的数据类型,比如string、list等
unsigned encoding:4; // 当前值对象底层存储编码方式,比如int、embstr等
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr; // 指向底层实现数据结构,比如哈希表、双向链表等
};
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* is set to one of this fields for this object. */
#define OBJ_ENCODING_RAW 0 /* Raw representation */
#define OBJ_ENCODING_INT 1 /* Encoded as integer */
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
#define OBJ_ENCODING_ZIPMAP 3 /* No longer used: old hash encoding. */
#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */
#define OBJ_ENCODING_ZIPLIST 5 /* No longer used: old list/hash/zset encoding. */
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of listpacks */
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */作者通过typr以及encoding字段来区分底层的数据结构,进而实现不同的功能。
c
/* 具体实现,路径:redis\src\object.c */
char *strEncoding(int encoding) {
switch(encoding) {
case OBJ_ENCODING_RAW: return "raw";
case OBJ_ENCODING_INT: return "int";
case OBJ_ENCODING_HT: return "hashtable";
case OBJ_ENCODING_QUICKLIST: return "quicklist";
case OBJ_ENCODING_LISTPACK: return "listpack";
case OBJ_ENCODING_LISTPACK_EX: return "listpackex";
case OBJ_ENCODING_INTSET: return "intset";
case OBJ_ENCODING_SKIPLIST: return "skiplist";
case OBJ_ENCODING_EMBSTR: return "embstr";
case OBJ_ENCODING_STREAM: return "stream";
default: return "unknown";
}
}SDS动态字符串:
c
//在redis\src\sds.h中定义了sds的结构体
typedef char *sds;
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};在结构体中可以看到:
len:表示已使用的长度
alloc:表示分配的长度(不包括头部和结尾的'\0'),也可以用来计算free未使用的空间,实现动态扩容,缩容
flags:用来标识类型,是sdshdr8还是sdshdr16等
buf 字段: 用于存储字符串的实际内容。它是一个变长数组,其大小由 alloc 字段决定。
这种结构体,作者采用柔性数组的特性来定义
- 结构体中,数组必须放在最后
- 数组必须是不固定的
- 结构体除了柔性数组,还必需包含其他成员
- sizeof返回结构体大小时,不包含柔性数组的大小
- 可以在单个内存块中高效地管理结构体和关联的数据,从而简化内存管理和提高程序性能。
c
//这种结构体如何malloc, 以sdshdr8为例
char* str = "hello world";
size_t total_size = sizeof(struct sdshdr8) + strlen(str) + 1; // 计算总大小,包括头部、字符串内容和结尾的空字符 '\0'
struct sdshdr8* sds = (struct sdshdr8*)malloc(total_size);
if (sds == NULL) {
perror("malloc failed");
return NULL;
}
// 初始化结构体成员
sds->len = (uint8_t)strlen(str);
sds->alloc = (uint8_t)(sds->len + 1); // 包括结尾的空字符 '\0'
sds->flags = 0; // 根据需要设置 flags
// 复制字符串到柔性数组
strcpy(sds->buf, str);物理编码方式:
- int:保存long型64位,8个字节的有符号整数,19位数字;只保存整数,不能保存浮点数;
- embstr: 保存小于等于44字节的字符串
- raw:保存大于44字节的字符串
那redis是如何实现编码转化的?
首先Redis启动时会预先建立10000个redisObject变量作为共享对象,当set字符串的键值在10000以内时,就直接使用共享对象,无序创建新的redisObject变量,节省内存空间。
bash
set k1 1234567890
set k2 1234567890 # 此时k1和k2指向同一个对象,k2不占空间 <=====> C++的引用,int& k2 = k1
c
/* path: server.h */
#define OBJ_SHARED_INTEGERS 10000
/* PATH: object.c */
/* Try to encode a string object in order to save space */
robj *tryObjectEncodingEx(robj *o, int try_trim) {
long value;
sds s = o->ptr;
size_t len;
/* Make sure this is a string object, the only type we encode
* in this function. Other types use encoded memory efficient
* representations but are handled by the commands implementing
* the type. */
serverAssertWithInfo(NULL,o,o->type == OBJ_STRING);
/* We try some specialized encoding only for objects that are
* RAW or EMBSTR encoded, in other words objects that are still
* in represented by an actually array of chars. */
if (!sdsEncodedObject(o)) return o;
/* It's not safe to encode shared objects: shared objects can be shared
* everywhere in the "object space" of Redis and may end in places where
* they are not handled. We handle them only as values in the keyspace. */
if (o->refcount > 1) return o;
/* Check if we can represent this string as a long integer.
* Note that we are sure that a string larger than 20 chars is not
* representable as a 32 nor 64 bit integer. */
len = sdslen(s);
if (len <= 20 && string2l(s,len,&value)) { // 长度 <= 20, 可以转换为long类型,则尝试共享对象或者转为int编码
/* This object is encodable as a long. Try to use a shared object.
* Note that we avoid using shared integers when maxmemory is used
* because every object needs to have a private LRU field for the LRU
* algorithm to work well. */
if ((server.maxmemory == 0 ||
!(server.maxmemory_policy & MAXMEMORY_FLAG_NO_SHARED_INTEGERS)) &&
value >= 0 &&
value < OBJ_SHARED_INTEGERS) // 共享对象
{
decrRefCount(o);
return shared.integers[value];
} else {
if (o->encoding == OBJ_ENCODING_RAW) { // 编码为RAW时,转换INT
sdsfree(o->ptr);
o->encoding = OBJ_ENCODING_INT;
o->ptr = (void*) value;
return o;
} else if (o->encoding == OBJ_ENCODING_EMBSTR) { // 编码为EMBSTR时,转换到RAW
decrRefCount(o);
return createStringObjectFromLongLongForValue(value);
}
}
}
/* If the string is small and is still RAW encoded,
* try the EMBSTR encoding which is more efficient.
* In this representation the object and the SDS string are allocated
* in the same chunk of memory to save space and cache misses. */
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT) {
robj *emb;
if (o->encoding == OBJ_ENCODING_EMBSTR) return o;
emb = createEmbeddedStringObject(s,sdslen(s));
decrRefCount(o);
return emb;
}
/* We can't encode the object...
* Do the last try, and at least optimize the SDS string inside */
if (try_trim)
trimStringObjectIfNeeded(o, 0);
/* Return the original object. */
return o;
}字符长度未超过44字节,为什么会变成RAW编码?
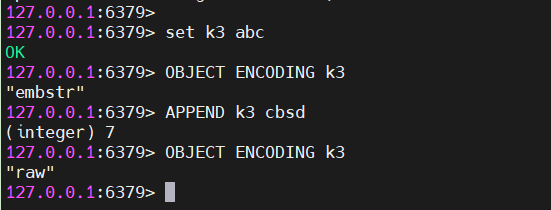
对于embstr,由于是只读的,当在对embstr进行修改时,会先转换成RAW编码再进行修改,因此只要是修改操作,都会转换成RAW编码,无论是否会超过44字节。
小结:
- C数组和柔性数组的区别:
| C数组 | SDS | |
|---|---|---|
| 字符串长度处理 | 需要从头开始遍历,直到遇到'\0',时间复杂度O(n) | 直接通过len字段获取,时间复杂度O(1) |
| 内存重新分配 | 分配的内存空间超过后,会导致下标越界,溢出,要重新分配内存,拷贝数据 | alloc空间预分配,扩容缩容时,只需要拷贝len长度的数据 |
| 二进制安全 | 不是二进制安全的,会将'\0'之后的字符也当做字符串的末尾 | 是二进制安全的,可以直接存储任意数据,包括'\0' |
- redis会根据不同的键值类型,自动选择不同的编码方式
- 当对embstr进行修改时,会先转换成RAW编码再进行修改,与是否会超过44字节无关。
2.3、hash
redis6.0版本及之前,hash == 压缩列表 + 哈希表<br
redis7.0版本之后,hash == listpack(紧凑列表) + 哈希表
hash在Redis6.0版本中的实现
在redis6.0版本中,执行以下命令:
bash
config get hash*
# redis6.0版本
1) "hash-max-ziplist-entries"
2) "512"
3) "hash-max-ziplist-value
4) "64"配置参数:
hash-max-ziplist-entries:使用压缩列表保存时,集合中最大元素个数
hash-max-ziplist-value:使用压缩列表保存时,集合中的单个元素最大长度
如果以上两个条件,任意一个不满足,那么就会使用哈希表来保存hash键值对。
c
/* t_hash.c */
void hsetCommand(client *c) {
int i, created = 0;
robj *o;
if ((c->argc % 2) == 1) {
addReplyErrorArity(c);
return;
}
if ((o = hashTypeLookupWriteOrCreate(c,c->argv[1])) == NULL) return;
hashTypeTryConversion(c->db,o,c->argv,2,c->argc-1); // 尝试将压缩列表转换为哈希表,如果满足条件则转换。
for (i = 2; i < c->argc; i += 2)
created += !hashTypeSet(c->db, o,c->argv[i]->ptr,c->argv[i+1]->ptr,HASH_SET_COPY);
/* HMSET (deprecated) and HSET return value is different. */
char *cmdname = c->argv[0]->ptr;
if (cmdname[1] == 's' || cmdname[1] == 'S') {
/* HSET */
addReplyLongLong(c, created);
} else {
/* HMSET */
addReply(c, shared.ok);
}
signalModifiedKey(c,c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_HASH,"hset",c->argv[1],c->db->id);
server.dirty += (c->argc - 2)/2;
}
void hashTypeTryConversion(redisDb *db, robj *o, robj **argv, int start, int end) {
int i;
size_t sum = 0;
if (o->encoding != OBJ_ENCODING_ZIPLIST)
return;
for (i = start; i <= end; i++) {
if (!sdsEncodedObject(argv[i]))
continue;
size_t len = sdslen(argv[i]->ptr);
if (len > server.hash_max_ziplist_value) {
hashTypeConvert(o, OBJ_ENCODING_HT);
return;
}
sum += len;
}
if (!ziplistSafeToAdd(o->ptr, sum))
hashTypeConvert(o, OBJ_ENCODING_HT);
}可以看到底层在处理时,与string类似,根据元素个数来选择最优的编码方式。
注意:
- ziplist升级到hashtable可以,但是反过来不行。
ziplist到底是什么?
ziplist是redis为了节约内存而设计的一种数据结构,总体思想:以时间换空间 它将多个连续的entry存储在一块连续的内存空间中,以此来减少内存碎片的开销,并且通过指针偏移量来定位元素的位置。
它一个双向链表,但不存储指向前一个链表节点prev和指向下一个链表节点next,而是存储上一个节点长度和当前节点长度
c
/* ----------------------------------------------------------------------------
* path: ziplist.c
*
* ZIPLIST OVERALL LAYOUT
* ======================
*
* The general layout of the ziplist is as follows:
*
* <zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
......
*/
typedef struct zlentry {
unsigned int prevrawlensize; /* 上一个链表节点占用长度*/
unsigned int prevrawlen; /* 存储上一个链表节点的长度数值所需要的字节数 */
unsigned int lensize; /* 存储当前链表节点长度数值所需要的字节数 */
unsigned int len; /* 当前链表节点占用的长度 */
unsigned int headersize; /* 当前链表节点的头部大小 */
unsigned char encoding; /* 编码方式 */
unsigned char *p; /* 压缩链表以字符串的形式保存,指向当前节点的起始位置 */
} zlentry;
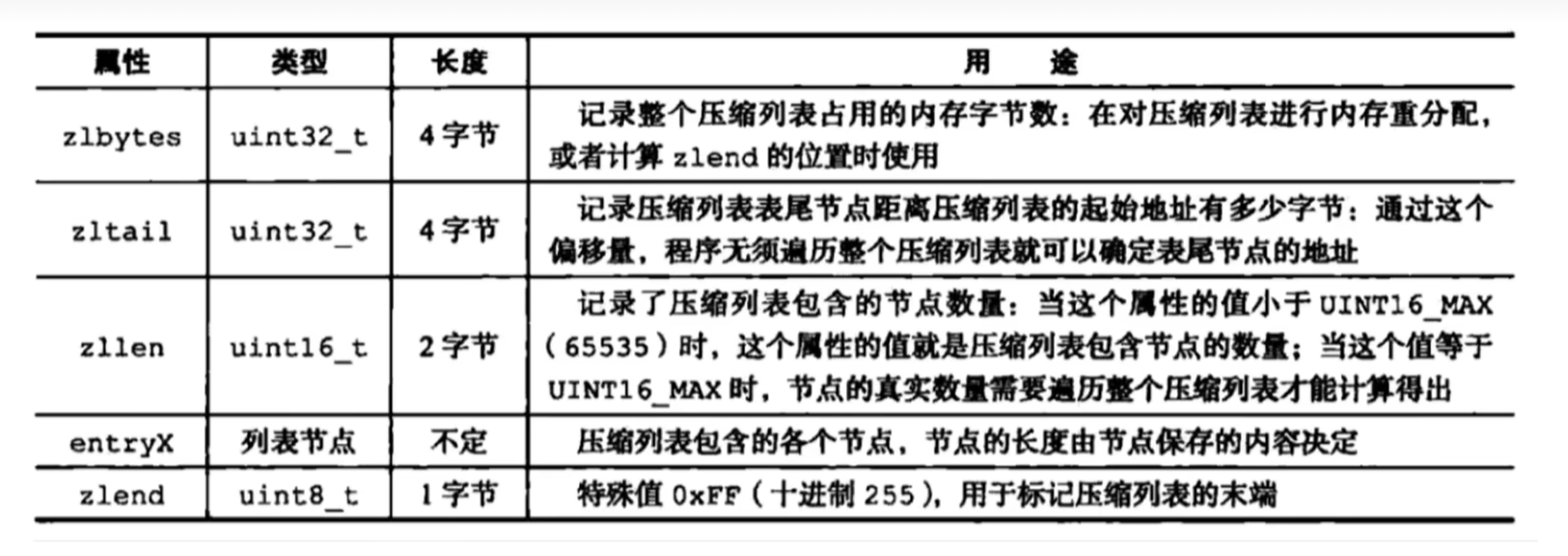
ziplist为entry开辟一段连续的内存,如果知道当前节点的起始地址,那么可以得知:
上个节点的起始地址 = 当前节点的起始地址 - 上一个节点长度
这个方法在 查询速度上比传统的双端链表要快,而且指针也要额外占用内存空间
hash在Redis7.0版本中的实现
bash
config get hash*
# redis7.0版本
1) "hash-max-listpack-value"
2) "64"
3) "hash-max-listpack-entries"
4) "512"
5) "hash-max-ziplist-value"
6) "64"
7) "hash-max-ziplist-entries"
8) "512"可以看到新增了两个配置参数,不过redis7.0版本中,并没有使用这两个参数,只是为了版本兼容而已.
配置参数:
hash-max-listpack-entries: 使用listpack保存时,集合中最大元素个数
hash-max-listpack-value: 使用listpack保存时,集合中的单个元素最大长度
c
/* object.c */
robj *createHashObject(void) {
unsigned char *zl = lpNew(0);
robj *o = createObject(OBJ_HASH, zl);
o->encoding = OBJ_ENCODING_LISTPACK; // 默认使用listpack编码方式创建hash对象
return o;
}
/* listpack.c */
#define LP_HDR_SIZE 6 /* 32 bit total len + 16 bit number of elements. */
unsigned char *lpNew(size_t capacity) {
unsigned char *lp = lp_malloc(capacity > LP_HDR_SIZE+1 ? capacity : LP_HDR_SIZE+1);
if (lp == NULL) return NULL;
lpSetTotalBytes(lp,LP_HDR_SIZE+1);
lpSetNumElements(lp,0);
lp[LP_HDR_SIZE] = LP_EOF;
return lp;
}创建默认是6个字节,其中4个字节是记录listpack的总长度,2个字节记录元素个数,最后一个字节是LP_EOF标识结束,值为255.
已经有了ziplist,为什么还要引入listpack?
***ziplist的缺点:***当新增或更新元素可能会出现连续更新现象.

所以listpack就是为了解决这个连续更新问题,才诞生,通过每个节点记录自己的长度且放在节点的末尾来实现的,不再记录上一个节点的长度
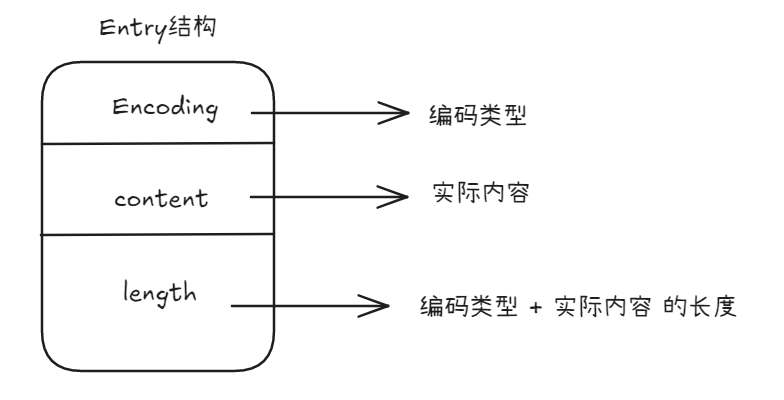
listpack的结构:
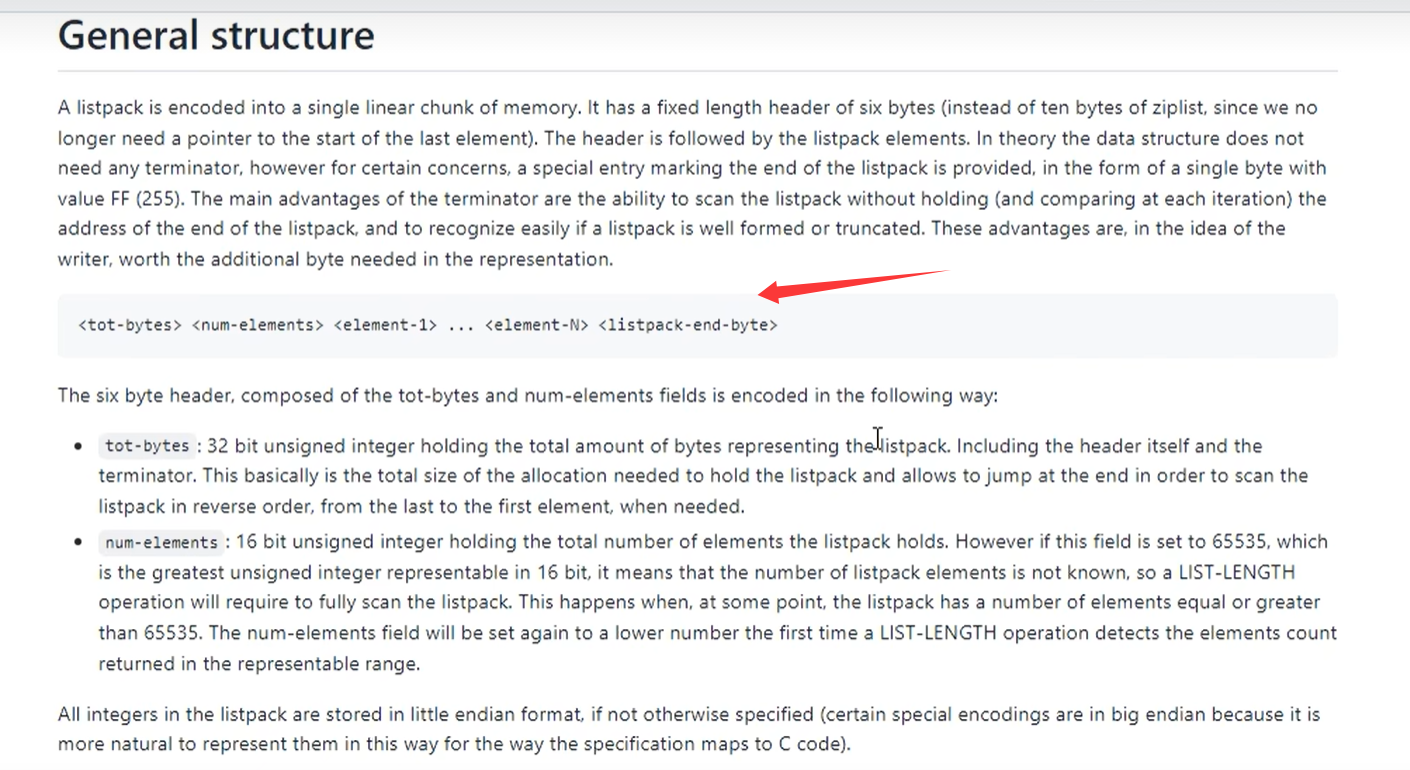
|total bytes|为整个listpack的空间大小,占用4个字节|
|num-elements|为listpack中元素的个数,占用2个字节|
|entry-1~N|每个具体元素,占用4个字节记录长度,后面跟着具体的值|
|listpack-eof|为listpack的结束标识,值为255,占1个字节|
2.4、list
执行config get list*查看下相关配置:
bash
config get list*
1) "list-compress-depth"
2) "0"
3) "list-max-listpack-size"
4) "-2"
5) "list-max-ziplist-size"
6) "-2"可以看到类似于hash,redis7.0版本为了兼容,也保留了ziplist
- list-compress-depth: 表示一个quicklist两端不被压缩的节点个数
- 0 :表示不进行压缩,默认值
- 1 :表示quicklist两端各有1个节点不压缩,中间的节点压缩
- 2 :表示quicklist两端各有2个节点不压缩,中间的节点压缩
... 以此类推
- list-max-ziplist-size: 当取正值时,表示按照数据项个数来限定ziplist的大小,当取负值时,表示按照占用字节大小来限定ziplist的大小。
- -2 :每个quicklist节点上的ziplist大小不能超过8KB,默认值
- -1 :每个quicklist节点上的ziplist大小不能超过4KB
- 5 :每个quicklist节点上的ziplist大小不能超过5个元素
- list-max-listpack-size: 和list-max-ziplist-size一样
c
/* t_list.c */
/* LPUSH <key> <element> [<element> ...] */
void lpushCommand(client *c) {
pushGenericCommand(c,LIST_HEAD,0);
}
/* RPUSH <key> <element> [<element> ...] */
void rpushCommand(client *c) {
pushGenericCommand(c,LIST_TAIL,0);
}
/* Implements LPUSH/RPUSH/LPUSHX/RPUSHX.
* 'xx': push if key exists. */
void pushGenericCommand(client *c, int where, int xx) {
int j;
robj *lobj = lookupKeyWrite(c->db, c->argv[1]);
if (checkType(c,lobj,OBJ_LIST)) return;
if (!lobj) {
if (xx) {
addReply(c, shared.czero);
return;
}
lobj = createListListpackObject();
dbAdd(c->db,c->argv[1],lobj);
}
listTypeTryConversionAppend(lobj,c->argv,2,c->argc-1,NULL,NULL);
for (j = 2; j < c->argc; j++) {
listTypePush(lobj,c->argv[j],where);
server.dirty++;
}
addReplyLongLong(c, listTypeLength(lobj));
char *event = (where == LIST_HEAD) ? "lpush" : "rpush";
signalModifiedKey(c,c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_LIST,event,c->argv[1],c->db->id);
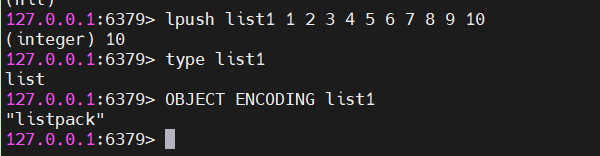
}通过前面hash对底层ziplist和listpack的了解,Redis7.0与6.0版本,list在实现上就把原来的ziplist换成listpack。
2.5、set
set == 整数集合 + 哈希表
整数集合是什么?
整数集合(intset)是 Redis 为了节约内存而设计的特殊数组,它可以保存所有元素的升序排列,且不包含任何重复元素。整数集合的底层实现为 int16_t 、int32_t 或者 int64_t。
c
void saddCommand(client *c) {
robj *set;
int j, added = 0;
set = lookupKeyWrite(c->db,c->argv[1]);
if (checkType(c,set,OBJ_SET)) return;
if (set == NULL) {
set = setTypeCreate(c->argv[2]->ptr, c->argc - 2);
dbAdd(c->db,c->argv[1],set);
} else {
setTypeMaybeConvert(set, c->argc - 2);
}
for (j = 2; j < c->argc; j++) {
if (setTypeAdd(set,c->argv[j]->ptr)) added++;
}
if (added) {
signalModifiedKey(c,c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_SET,"sadd",c->argv[1],c->db->id);
}
server.dirty += added;
addReplyLongLong(c,added);
}
/* returned, otherwise the new element is added and 1 is returned. */
int setTypeAdd(robj *subject, sds value) {
return setTypeAddAux(subject, value, sdslen(value), 0, 1);
}
/* Add member. This function is optimized for the different encodings. The
* value can be provided as an sds string (indicated by passing str_is_sds =
* 1), as string and length (str_is_sds = 0) or as an integer in which case str
* is set to NULL and llval is provided instead.
*
* Returns 1 if the value was added and 0 if it was already a member. */
int setTypeAddAux(robj *set, char *str, size_t len, int64_t llval, int str_is_sds) {
char tmpbuf[LONG_STR_SIZE];
if (!str) {
if (set->encoding == OBJ_ENCODING_INTSET) { // 整数集合
uint8_t success = 0;
set->ptr = intsetAdd(set->ptr, llval, &success);
if (success) maybeConvertIntset(set);
return success;
}
/* Convert int to string. */
len = ll2string(tmpbuf, sizeof tmpbuf, llval);
str = tmpbuf;
str_is_sds = 0;
}
serverAssert(str);
if (set->encoding == OBJ_ENCODING_HT) { // 哈希表
/* Avoid duping the string if it is an sds string. */
sds sdsval = str_is_sds ? (sds)str : sdsnewlen(str, len);
dict *ht = set->ptr;
void *position = dictFindPositionForInsert(ht, sdsval, NULL);
if (position) {
/* Key doesn't already exist in the set. Add it but dup the key. */
if (sdsval == str) sdsval = sdsdup(sdsval);
dictInsertAtPosition(ht, sdsval, position);
} else if (sdsval != str) {
......
}
}
}2.6、zset
Redis6.0: zset == 跳表 + 压缩列表
Redis7.0: zset == 跳表 + 紧凑列表
什么是跳表?
回顾下单链表,插入、删除快,但是查找效率为O(n);对其进行优化,以空间换时间,给链表增加索引,使得查找效率提升至O(logn)。
明显可以看出,添加索引之后,查找一个节点需要遍历的次数变少了。
跳表是可以实现二分查找的有序链表,总之就是跳表 = 链表 + 多级索引
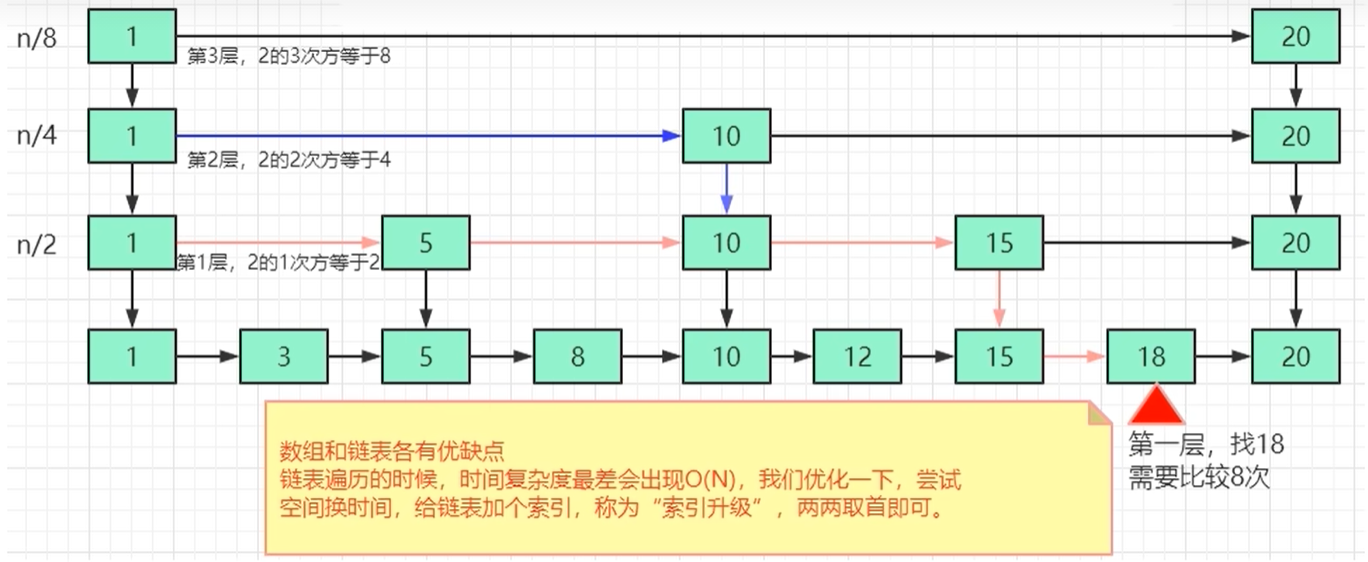
为什么使用跳表?
- 跳跃表的实现方式,使得它在查找、删除、添加等操作都可以在对数期望时间复杂度内完成。
- 跳跃表在内存中的存储结构类似于多层链表,通过这种方式可以快速定位到元素的位置。
- 跳跃表相比于平衡树等其他数据结构来说,它的实现更为简单,而且效率也相对较高。
- 在Redis中,跳跃表主要用于有序集合的实现,它可以保证元素的唯一性并且能够按照一定的顺序进行排序。因此,跳跃表成为了Redis中最常用的数据结构之一。
时间复杂度与空间复杂度
时间复杂度: O(logn)
空间复杂度:O(n)
优点:
- 以空间换时间,在数据量大的时候才能体现出来查询优势
- 适合读多写少的场景
缺点:
- 索引也需要占用内存空间。
- 一旦新增或者删除元素,都需要把索引重新更新一遍
三、总结:
-
- redis从命令处理的角度来看,是单线程的。
-
- 从整体架构来看,是多线程的,使用了多个线程来处理不同类型的后台任务。
-
-
Redis高效的数据结构:
redis6.0版本以及之前:
string == sds
list == quciklist(压缩列表)
hash == 压缩列表 + 哈希表
set == 整数集合 + 哈希表
zset == 跳表 + 压缩列表
redis7.0版本之后:
string == sds
list == quciklist(listpack)
hash == listpack(紧凑列表) + 哈希表
set == 整数集合 + 哈希表
zset == 跳表 + listpack
-
-
- C数组和柔性数组的区别:
| C数组 | SDS | |
|---|---|---|
| 字符串长度处理 | 需要从头开始遍历,直到遇到'\0',时间复杂度O(n) | 直接通过len字段获取,时间复杂度O(1) |
| 内存重新分配 | 分配的内存空间超过后,会导致下标越界,溢出,要重新分配内存,拷贝数据 | alloc空间预分配,扩容缩容时,只需要拷贝len长度的数据 |
| 二进制安全 | 不是二进制安全的,会将'\0'之后的字符也当做字符串的末尾 | 是二进制安全的,可以直接存储任意数据,包括'\0' |
四、问题:
4.1、处于渐进式 rehash 阶段时,是否会发生扩容缩容?
不会!
4.2、为什么redis中字符串选择64个字节作为分界线?
- 首先内存分配器是按照大小为2^n来进行分配的,而且CPU最小访问单位是64字节,所以选择64字节作为分界线。
- 其次string由于结构较为特殊,buf可用字节数为44字节,计算过程如下:
c
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};64 - 16 - 3 - 1 = 44 ,多减去的1是因为C语言字符串结尾的'\0'。
0vice·GitHub