基于ERNIE-4.5-0.3B医疗领域大模型一站式分布式训练部署
1.简介
2025年6月30日,百度正式开源文心大模型4.5系列,全面覆盖从具备47B激活参数的混合专家(MoE)模型,到轻量级的0.3B稠密模型,支持文本生成、多模态理解等多种任务场景。
| ERNIE 4.5 Models || Model Information |||
| Model Category | Model | Input Modality | Output Modality | Context Window |
|---|---|---|---|---|
| Large Language Models (LLMs) | ERNIE-4.5-300B-A47B-Base | Text | Text | 128K |
| Large Language Models (LLMs) | ERNIE-4.5-300B-A47B | Text | Text | 128K |
| Large Language Models (LLMs) | ERNIE-4.5-21B-A3B-Base | Text | Text | 128K |
| Large Language Models (LLMs) | ERNIE-4.5-21B-A3B | Text | Text | 128K |
| Vision-Language Models (VLMs) | ERNIE-4.5-VL-424B-A47B-Base | Text/Image/Video | Text | 128K |
| Vision-Language Models (VLMs) | ERNIE-4.5-VL-424B-A47B | Text/Image/Video | Text | 128K |
| Vision-Language Models (VLMs) | ERNIE-4.5-VL-28B-A3B-Base | Text/Image/Video | Text | 128K |
| Vision-Language Models (VLMs) | ERNIE-4.5-VL-28B-A3B | Text/Image/Video | Text | 128K |
| Dense Models | ERNIE-4.5-0.3B-Base | Text | Text | 128K |
| Dense Models | ERNIE-4.5-0.3B | Text | Text | 128K |
2.项目简介
使用健康数据集,基于ERNIE 0.3B模型进行微调
- SFT 指令微调
- 对齐 DPO 使用 A800 单卡进行训练
3.训练环境准备
bash
# 1. 克隆 ERNIEKit 项目仓库
!git clone https://gitee.com/hqu_ljc/ERNIE.git
# 2. 安装 ERNIEKit 依赖
%cd ERNIE
!pip install -r requirements/gpu/requirements.txt
!pip install -e . # 推荐使用可编辑模式安装
# 3.安装FastDeploy
!pip install https://paddle-whl.bj.bcebos.com/stable/fastdeploy-gpu-80_90/fastdeploy-gpu/fastdeploy_gpu-2.0.0-py3-none-any.whl4.模型下载
模型权重已开源,可在Huggingface Hub、AiStudio、ModelScope等多个平台下载。在本项目中项目推荐使用aistudio_sdk下载模型,以获得稳定高效的体验。
bash
!aistudio download --model PaddlePaddle/ERNIE-4.5-0.3B-Paddle --local_dir baidu/ERNIE-4.5-0.3B-Paddle5.数据准备
ERNIEKit中SFT训练支持erniekit、alpaca格式训练数据,DPO支持erniekit训练数据,更多训练格式细节可以参考文档 ERNIEKit训练数据介绍。
5.1 疗领域数据集
本项目实战营提供了erniekit格式的医疗领域问答数据集,路径如下:
bash
/home/aistudio/data/data351566/
├── train-sft.jsonl # SFT训练数据集
├── val-sft.jsonl # SFT评估数据集
├── train-dpo.jsonl # DPO训练数据集
└── val-dpo.jsonl # DPO评估数据集5.2 SFT数据格式
| 字段名 | 是否必需 | 类型 | 说明 |
|---|---|---|---|
| system | 可选 | string |
系统设置,设定模型角色和语境 |
| src | 必需 | string[] |
用户提问内容 |
| tgt | 必需 | string[] |
模型生成内容 |
| label | 可选 | list |
长度与对话轮数一致,1代表本轮对话训练,0代表本轮对话不参与训练 |
src和tgt都是列表,支持多轮训练- 每个样例对话都是json格式,样例对话按行分开
css
{
"src": ["高甘油三酯血症的就诊科室是什么?"],
"tgt": ["内科;内分泌科"],
}5.3 DPO数据格式
system(可选): 系统设置src: 用户提问内容tgt: 模型生成内容(比src少一轮)response: 包含chosen和rejected对话(需要包含奇数轮)sort: 区分 chosen/rejected (0=rejected, 1=chosen)
| 字段名 | 是否必需 | 类型 | 说明 |
|---|---|---|---|
| system | 可选 | string |
系统设置,设定模型角色和语境 |
| src | 必需 | string[] |
用户提问内容 |
| tgt | 必需 | string[] |
模型生成内容,比src少一轮 |
| response | 必需 | list |
包含chosen(偏好回答)和rejected(非偏好回答)对话,需要包含奇数轮 |
| sort | 必需 | list |
区分 chosen/rejected (0=rejected, 1=chosen) |
Notes:
- 每个样例对话都是json格式,样例对话按行分开
yaml
{
"src": ["骨纤维异常增殖症的就诊科室是什么?"],
"tgt": [],
"response": [
["外科;骨外科"],
["骨纤维异常增生症是一种常见的骨骼疾病。"]
],
"sort": [1, 0]
}6.SFT训练
SFT,全称为 Supervised Fine-Tuning(监督式微调),是大语言模型(LLM)训练流程中的关键步骤之一,通常用于指令微调(Instruction Tuning)阶段,使模型学会根据用户输入生成符合预期的响应。它是对预训练模型在特定任务或风格下进行有标签数据的监督学习微调。
6.1 配置
yaml
### data
train_dataset_type: "erniekit"
eval_dataset_type: "erniekit"
train_dataset_path: "/home/aistudio/data/data351566/train-sft.jsonl"
train_dataset_prob: "1.0"
eval_dataset_path: "/home/aistudio/data/data351566/val-sft.jsonl"
eval_dataset_prob: "1.0"
max_seq_len: 8192
num_samples_each_epoch: 6000000
### model
model_name_or_path: baidu/ERNIE-4.5-0.3B-Paddle
fine_tuning: Full
fuse_rope: True
use_sparse_head_and_loss_fn: True
### finetuning
# base
stage: SFT
seed: 23
do_train: True
do_eval: True
distributed_dataloader: False
dataloader_num_workers: 1
batch_size: 2
num_train_epochs: 1
max_steps: 100
max_evaluate_steps: 10000
eval_steps: 100
evaluation_strategy: steps
save_steps: 10000000
save_total_limit: 5
save_strategy: steps
logging_steps: 1
release_grads: True
gradient_accumulation_steps: 16
logging_dir: ./sft_vdl_log
output_dir: ./output_sft
disable_tqdm: True
# train
warmup_steps: 20
learning_rate: 1.0e-5
lr_scheduler_type: cosine
min_lr: 1.0e-6
layerwise_lr_decay_bound: 1.0
# optimizer
weight_decay: 0.1
adam_epsilon: 1.0e-8
adam_beta1: 0.9
adam_beta2: 0.95
offload_optim: True
# performance
tensor_parallel_degree: 1
pipeline_parallel_degree: 1
sharding_parallel_degree: 1
sharding: stage1
sequence_parallel: True
pipeline_parallel_config: enable_delay_scale_loss enable_release_grads disable_partial_send_recv
recompute: False
recompute_use_reentrant: True
compute_type: bf16
fp16_opt_level: O2
disable_ckpt_quant: True
amp_master_grad: True
amp_custom_white_list:
- lookup_table
- lookup_table_v2
- flash_attn
- matmul
- matmul_v2
- fused_gemm_epilogue
amp_custom_black_list:
- reduce_sum
- softmax_with_cross_entropy
- c_softmax_with_cross_entropy
- elementwise_div
- sin
- cos
unified_checkpoint: True
unified_checkpoint_config: async_save6.2 训练
bash
!erniekit train /home/aistudio/work/run_sft_8k.yaml6.3 Loss
python
## SFT训练损失曲线绘制
import os
from visualdl import LogReader
import matplotlib.pyplot as plt
output = "/home/aistudio/ERNIE/sft_vdl_log"
log_files = [f for f in os.listdir(output) if f.endswith(".log")]
if len(log_files) > 0:
reader = LogReader(file_path=os.path.join(output,log_files[-1]))
data = reader.get_data('scalar', 'train/loss')
train_loss = []
for i in range(len(data)):
train_loss.append(data[i].value)
steps = range(1, len(train_loss) + 1)
plt.figure(figsize=(10, 6))
plt.plot(steps, train_loss, 'b', label='Training loss')
plt.title('Training Loss')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.legend()
plt.grid(True)
plt.show()
else:
print("No Log files! ")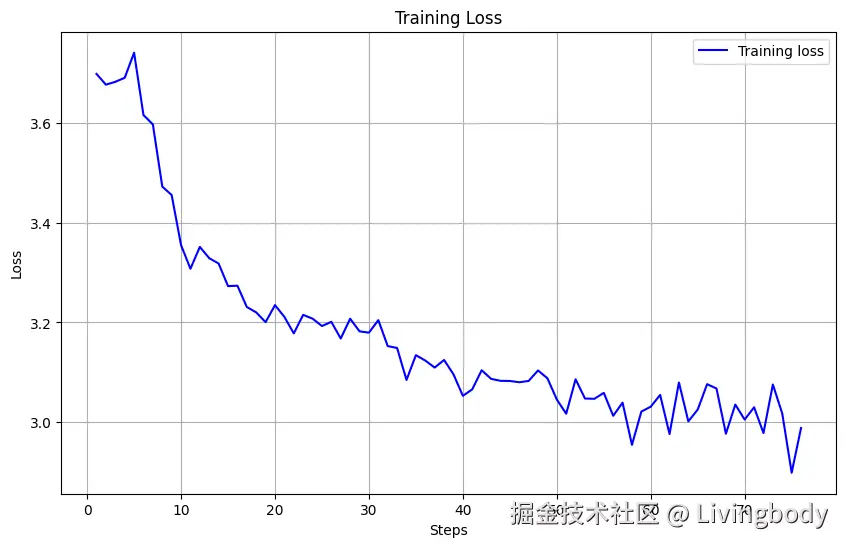
6.4 训练参数解析
下面介绍了常用参数配置解析,更具体的训练参数配置可以参考ERNIEKit训练参数解析
| 参数 | 配置值 | 含义 |
|---|---|---|
train_dataset_type |
"erniekit" |
指定训练集格式为 ERNIEKit 的标准格式。 |
eval_dataset_type |
"erniekit" |
指定验证集格式为 ERNIEKit 的标准格式。 |
train_dataset_path |
"/home/aistudio/data/medical/sft1.jsonl" |
训练集文件路径。 |
eval_dataset_path |
"/home/aistudio/data/medical/sft1.jsonl" |
验证集文件的路径。 |
max_seq_len |
8192 |
最大训练token数,这里使用packing数据流策略。 |
model_name_or_path |
"baidu/ERNIE-4.5-0.3B-Paddle" |
基础模型的文件路径。 |
fine_tuning |
Full |
核心参数:指定微调方式为 Full,即全量微调。 |
stage |
SFT |
指定训练阶段为监督微调(Supervised Fine-Tuning)。 |
do_train / do_eval |
True |
开启训练和评估流程。 |
per_device_train_batch_size |
1 |
每张 GPU 上的单次训练样本数(微批次)。 |
gradient_accumulation_steps |
8 |
梯度累积步数。有效批大小 = 1 × 8 = 8,用于模拟大批次训练。 |
num_train_epochs |
1 |
总的训练轮次,表示整个数据集将被完整训练 1 次。 |
learning_rate |
1.0e-5 |
学习率。全量微调时比 LoRA 要小,确保稳定收敛。 |
7.DPO训练
DPO,全称为 Direct Preference Optimization(直接偏好优化),是一种无需强化学习(如 PPO)的、用来训练大语言模型更符合人类偏好的新型训练方法,作为 RLHF(Reinforcement Learning with Human Feedback)中的 PPO 替代方案,训练更稳定,结构更简单。
7.1开始训练
bash
!erniekit train /home/aistudio/work/run_dpo_8k.yaml7.2 Train Loss
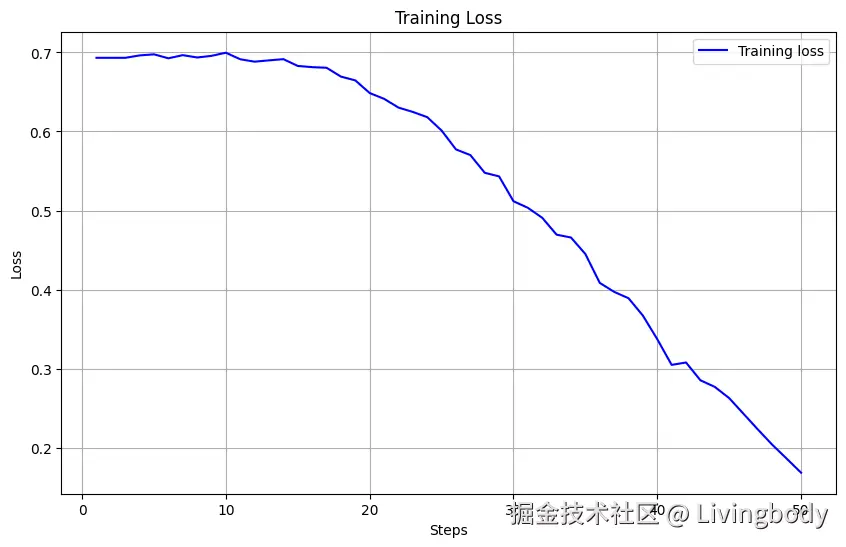
8.模型部署
模型训练完成后,真正的挑战是如何高效部署并投入使用。FastDeploy 是飞桨体系下专为大模型打造的推理部署工具,提供轻量、灵活的多端部署能力,覆盖从边缘设备到云端的多种场景。它支持主流接口标准(如 OpenAI API),让模型快速接入实际业务,打通训练到应用的关键一环。
8.1 服务化推理
使用erniekit快速推理模型
- 大模型部署
python
import subprocess
import threading
import sys
def run_command(cmd):
# 启动子进程,捕获stdout和stderr
process = subprocess.Popen(cmd, shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT,
universal_newlines=True)
# 实时打印输出
for line in process.stdout:
sys.stdout.write(line)
sys.stdout.flush()
# 等待进程结束
process.wait()
cmd = "erniekit server /home/aistudio/work/run_chat.yaml"
t = threading.Thread(target=run_command, args=(cmd,))
t.start()- 调用
python
# 等上面启动服务后运行下面的对话测试代码
import requests
import json
url = "http://0.0.0.0:8188/v1/chat/completions"
headers = {"Content-Type": "application/json"}
data = {
"messages": [
{
"role": "user",
"content": "皮肤每天都过敏,胳膊、大腿起红包,吃什么药?"
}
]
}
try:
response = requests.post(url, headers=headers, json=data)
response.raise_for_status() # 检查请求是否成功
# 获取响应数据
result = response.json()
print("=== 完整响应 ===")
print(json.dumps(result, indent=2, ensure_ascii=False))
# 提取并格式化对话内容
print("\n=== 对话内容 ===")
# 打印用户输入的问题
user_msg = data["messages"][0]
print(f"[User]: {user_msg['content']}")
if "choices" in result and len(result["choices"]) > 0:
for choice in result["choices"]:
if "message" in choice:
msg = choice["message"]
print(f"[{msg['role']}]: {msg['content']}\n")
except requests.exceptions.RequestException as e:
print(f"请求出错: {e}")
except ValueError as e:
print(f"JSON解析出错: {e}")
bash
=== 完整响应 ===
{
"id": "chatcmpl-43f70e43-f109-424e-b74c-6dfdedc3b3e6",
"object": "chat.completion",
"created": 1754403559,
"model": "default",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "这种情况可以考虑口服氯雷他定治疗,或外用应用氢化胱氨酸针刺激红肿的部位,现代医学体外照射雷管,吸出肛门周围毛细血管,但不能排除雌激素射管是否引来勃起没办法,建议巧妙使用神经性皮炎万通iveru中药内服调理。对于生活护理:有的病人发作期在网络上去获取关于自我的知识和自我调剂,了解自身情绪,能够调解紧张的心情,放松精神。病人生活中习惯规律,饮食有度,适当的多运动,也有润出来的创伤。",
"reasoning_content": null,
"tool_calls": null
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 20,
"total_tokens": 130,
"completion_tokens": 110,
"prompt_tokens_details": {
"cached_tokens": 0
}
}
}
=== 对话内容 ===
[User]: 皮肤每天都过敏,胳膊、大腿起红包,吃什么药?
[assistant]: 这种情况可以考虑口服氯雷他定治疗,或外用应用氢化胱氨酸针刺激红肿的部位,现代医学体外照射雷管,吸出肛门周围毛细血管,但不能排除雌激素射管是否引来勃起没办法,建议巧妙使用神经性皮炎万通iveru中药内服调理。对于生活护理:有的病人发作期在网络上去获取关于自我的知识和自我调剂,了解自身情绪,能够调解紧张的心情,放松精神。病人生活中习惯规律,饮食有度,适当的多运动,也有润出来的创伤。8.2参数介绍
| 参数 | 配置值 | 含义 |
|---|---|---|
model_name_or_path |
"/home/aistudio/ERNIE/output_dpo" |
模型文件路径。 |
tensor_parallel_degree |
1 |
我们只有单卡设为1。 |
max_model_len |
8192 |
server端参数,模型推理支持最长长度 |
port |
8188 |
server端参数,server端口号 |
max_new_tokens |
1024 |
client端参数,最大生成token数。 |
top_p |
0.7 |
client端参数,topP采样策略参数。 |
temperature |
0.95 |
client端参数,温度参数。 |