我业余时间维护着一款视频翻译软件。最初只是个小工具,所有代码都塞在一个文件里。后来,随着功能迭代,我用 PySide6 重写了界面,代码也拆分成了多个模块。这种"野蛮生长"的方式,终于让我付出了代价------应用的冷启动时间,达到了令人难以忍受的两三分钟。
于是,我花了几个周末的时间,踏上了一段充满挑战的性能优化之旅。最终,应用的冷启动时间被压缩到了10秒左右。
这篇文章,就是对那段历程的完整复盘,深入代码的细节,探寻每个性能瓶颈背后的根本原因,并分享那些让应用"起死回生"的优化思路。
一、 一切的开始:用数据定位问题
面对性能问题,最忌讳的是凭感觉猜测。直觉可能会告诉你"AI库加载慢",但具体是哪个库?在哪个环节加载?耗时多久?这些问题都需要精确的数据来回答。
我的武器库很简单,只有两件:
cProfile:Python 内置的性能分析器。它能记录下程序运行期间所有函数的调用次数和执行时间。snakeviz:一个能将cProfile输出结果可视化的工具。它生成的"火焰图",是性能分析的寻宝地图。pip install snakeviz安装

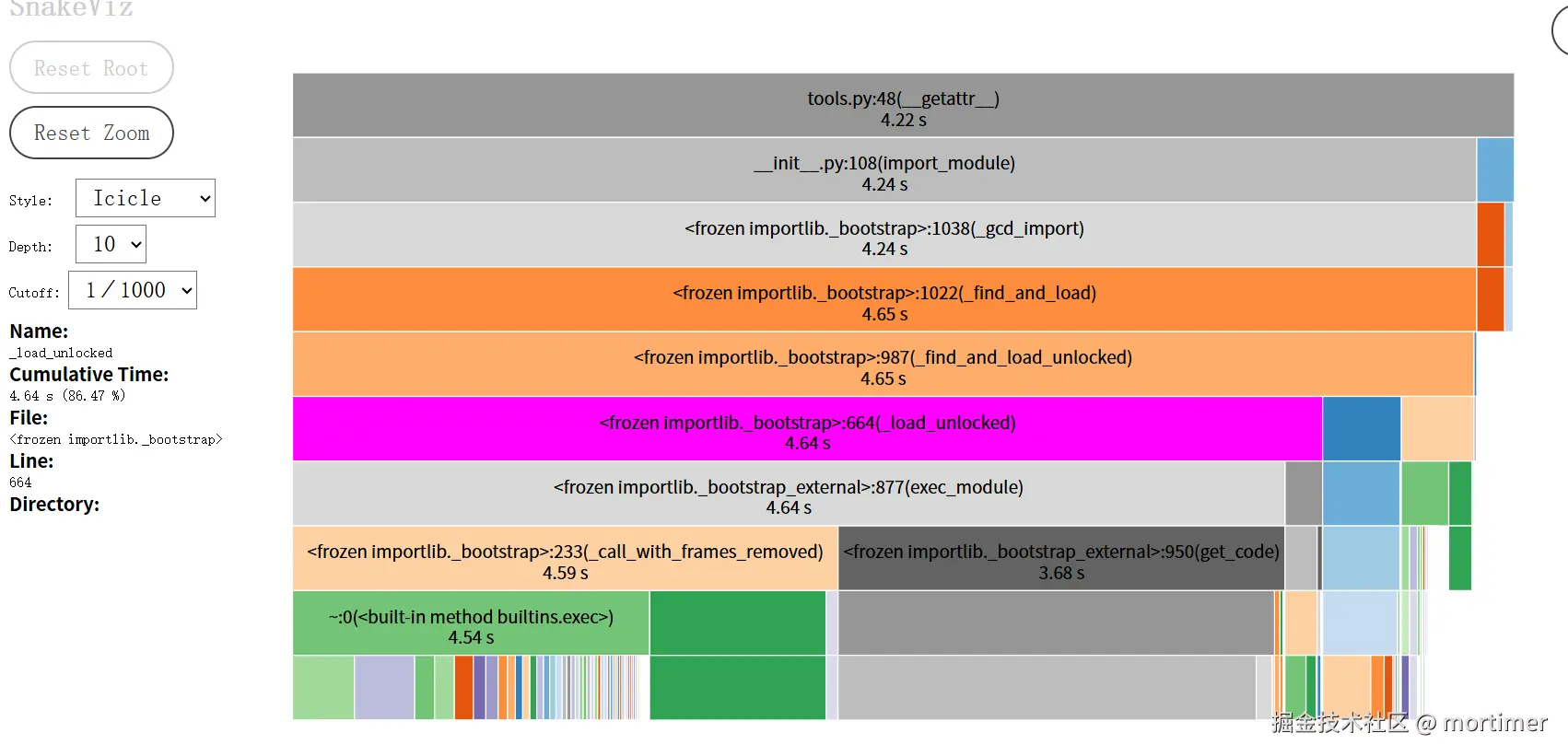
我用 cProfile 包裹了应用的整个启动逻辑,然后用 snakeviz 打开生成的性能数据文件。一幅壮观的火焰图展现在眼前。

如何解读火焰图?
- 横轴代表时间:一个方块越宽,说明它消耗的时间越长。
- 纵轴代表调用栈:下方的函数调用了上方的函数。
- 我们要找的:就是那些位于顶层、又宽又平的"高原"。它们就是消耗了大量时间的罪魁祸首。
果然,火焰图清晰地告诉我,绝大部分时间都消耗在了 import 阶段。这为我的优化之旅指明了第一个,也是最重要的方向:控制模块的加载。
二、 优化之旅:一场关于"懒惰"的修行
第一站:初见成效 ------ 斩断"急切"的导入链
火焰图的第一个线索,指向了 from videotrans import winform。这个看似无辜的导入,耗时竟长达 80 多秒。
1. 问题代码
videotrans/winform/__init__.py 文件的内容非常直接:

这个文件定义了所有与弹出窗口相关的模块。
2. 思路分析:什么是"急切导入"?
这行代码是典型的急切导入 。它的行为模式是"我全都要"。当 Python 解释器执行到 import videotrans.winform 时,它会立刻、无条件地把 __init__.py 中列出的所有模块(baidu.py, azure.py 等)全部加载到内存中。
这就像一个多米诺骨牌效应:
import winform是第一张牌。- 它推倒了几十张牌(
baidu,azure...)。 - 而这些子模块中,很多又依赖于
torch或modelscope这样的重型 AI 库。这些 AI 库在被导入时,需要进行复杂的初始化,检查硬件、加载底层库等等。
结果就是,我只是想启动一个主窗口,却被迫等待所有可能用到的、也可能永远用不到的功能窗口的后台依赖全部加载完毕。这 80 秒的延迟,正是这种"急切"付出的代价。
3. 解决方案:切换到"懒加载"模式
优化的核心思想很简单:从"我全都要",切换到"你需要时我再给"的懒加载模式。
我重构了 videotrans/winform/__init__.py,让它不再是一个"仓库管理员",而是一个轻量级的"前台接待"。
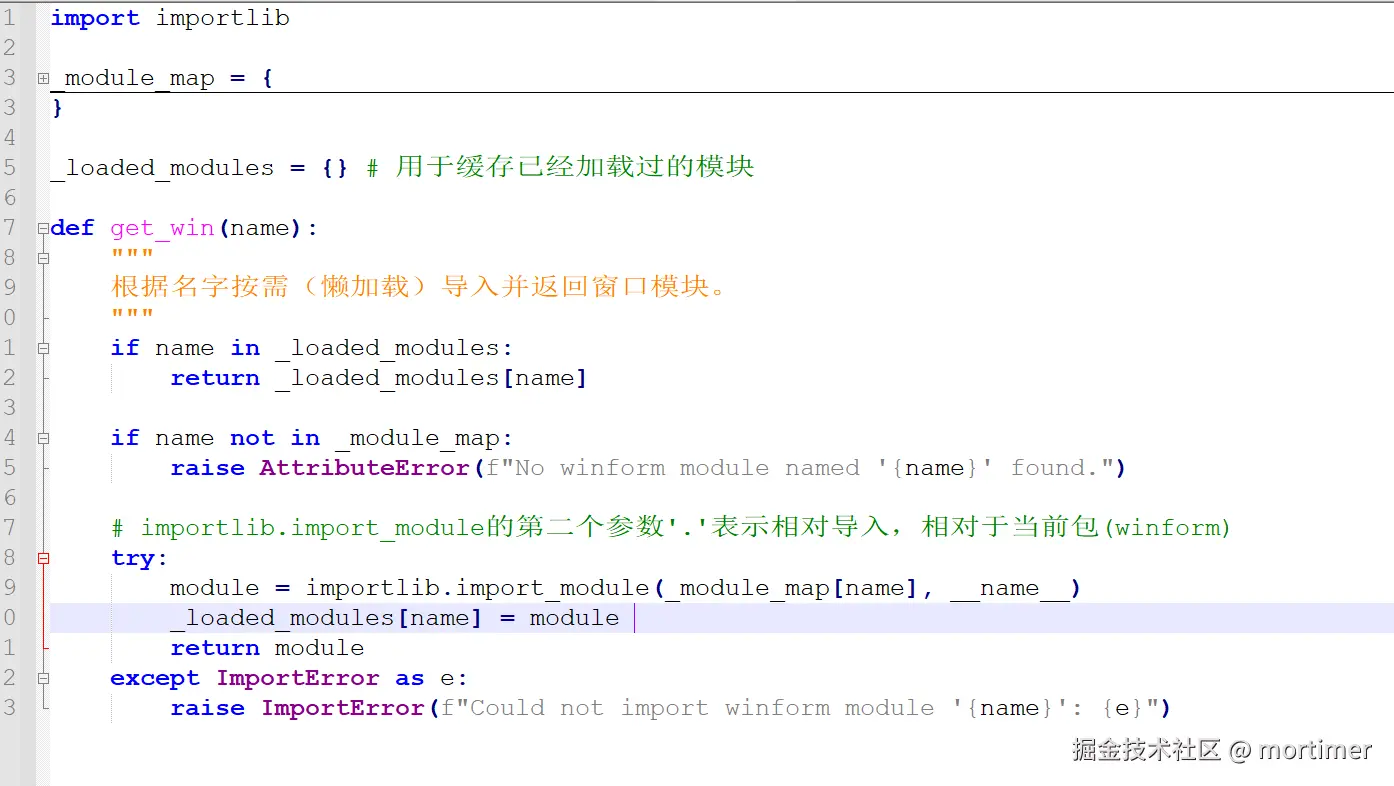
现在,import videotrans.winform 只会执行这个极简的 __init__.py 文件,它不依赖任何重型库,瞬间就能完成。
真正的 import 操作,被封装在了 get_win 函数内部。那么,什么时候调用 get_win 呢?答案是:用户真正需要的时候。
我修改了主窗口中菜单项的信号连接,使用了 lambda:
python
# 旧代码: self.actionazure_key.triggered.connect(winform.azure.openwin)
# 新代码:
self.actionazure_key.triggered.connect(lambda: winform.get_win('azure').openwin())lambda 在这里的作用至关重要。它创建了一个微小的匿名函数,但并不立即执行 。只有当用户点击菜单,triggered 信号被发射时,这个 lambda 函数体才会被调用。这时,winform.get_win('azure') 才会被执行,从而实现了加载时机从程序启动时 到用户交互时的完美推迟。
这次优化效果立竿见影,启动时间直接减少了 80 多秒。
第二站:净化被污染的"蓝图" ------ UI 与逻辑的彻底解耦
启动快了很多,但主窗口的创建依然需要 20 多秒。通过简单的"打点计时法",我发现问题出在 from videotrans.ui.en import Ui_MainWindow 这一步。
1. 问题代码
Ui_MainWindow 类是由 pyside6-uic 工具从 .ui 文件生成的,它理应只包含纯粹的界面布局代码,就像一张建筑蓝图。但检查 ui/en.py 文件后,我发现了不该出现的东西:
python
# 旧的 ui/en.py
from videotrans.configure import config
from videotrans.recognition import RECOGN_NAME_LIST
from videotrans.tts import TTS_NAME_LIST
class Ui_MainWindow(object):
def setupUi(self, MainWindow):
# ...
self.tts_type.addItems(TTS_NAME_LIST) # 蓝图上不该有具体的装修材料
# ...2. 思路分析:关注点分离原则
这是一个典型的违反关注点分离原则的例子。
- UI 文件 的职责本应只是描述"界面长什么样"。
- 逻辑文件 的职责才是获取数据,并决定如何将数据展示在界面上。
我的"建筑蓝图" (ui/en.py) 不仅画了结构,还自己跑去"建材市场"(import config, import tts)搬来了"水泥"和"砖头"(TTS_NAME_LIST)。这导致任何想看一眼蓝图的人,都必须先把整个建材市场搬回家。
3. 解决方案:让蓝图回归纯粹
优化的核心是让每个模块都只做自己的事。
-
净化 UI 文件 :我大刀阔斧地删除了
ui/en.py中所有非 PySide6 的import,以及所有设置文本、填充数据的代码。这让它变回一个纯粹的、只负责布局的"UI骨架",加载速度恢复到了毫秒级。 -
逻辑回归主窗口 :在我的主窗口逻辑类
MainWindow(_main_win.py) 中,我才去import那些业务模块。__init__方法的执行顺序被严格控制:
python
# _main_win.py
from videotrans.ui.en import Ui_MainWindow # 这一步现在飞快
from videotrans.configure import config # 业务逻辑在这里导入
from videotrans.tts import TTS_NAME_LIST
class MainWindow(QMainWindow, Ui_MainWindow):
def __init__(self):
super().__init__()
# 1. 先用纯净的蓝图把房子的框架搭起来
self.setupUi(self)
# 2. 然后,再用水泥和砖头(业务数据)去装修
self.tts_type.addItems(TTS_NAME_LIST)
# ...这次优化不仅提升了性能,更重要的是理清了代码结构,让 UI 和逻辑解耦,为后续的维护和优化打下了坚实的基础。
第三站:拆解"万能工具箱" ------ tools.py 的分治与懒加载
经过前两轮优化,启动速度已经有了质的飞跃。但 import videotrans.util.tools 依然需要 6 秒。tools.py 是一个 80KB 的"大杂烩"文件,里面定义了几十个功能各异的函数,从获取角色列表到设置网络代理,无所不包。
1. 思路分析:import 不仅仅是"加载"
很多人认为,如果一个 .py 文件里只有函数定义,import 它应该很快。这是一个常见的误解。当 Python 执行 import 时,它在幕后做了三件主要的事:读取、解析和编译。
对于一个 80KB 的大文件来说,Python 解释器需要逐行读取,分析语法结构,然后将其编译成 Python 虚拟机可以执行的"字节码"。这个编译过程本身就是非常耗时的。
2. 解决方案:分而治之,并用 ast 实现终极懒加载
优化的方向很明确:将一个大的编译任务,分解成多个小的编译任务,并且只在需要时才执行。
-
拆分 :我首先将
tools.py按功能拆分成了多个小文件,如help_role.py,help_ffmpeg.py等,放在同级目录下。 -
智能聚合 :然后,我将
tools.py变成了一个智能的"路由器",它使用ast(抽象语法树)模块来实现懒加载。
python
# 优化后的 videotrans/util/tools.py
import os
import ast
import importlib
_function_map = None # 函数地图,初始为空
def _build_function_map_statically():
# ...
# 只读取文件文本,不执行不编译
source_code = f.read()
# 将文本解析成一个数据结构 (AST)
tree = ast.parse(source_code)
# 遍历这个数据结构,找出所有函数定义的名字
for node in tree.body:
if isinstance(node, ast.FunctionDef):
_function_map[node.name] = module_name
# ...
def __getattr__(name):
# 首次调用 tools.xxx 时触发
_build_function_map_statically() # 构建一次函数地图
# ... 从地图中找到模块名,然后才 import 那个小模块 ...ast 在这里的应用是点睛之笔:
ast.parse()可以在不执行、不编译代码的情况下,将其作为纯文本进行分析,并提取出其中的结构信息。这个过程非常快,因为它跳过了最耗时的编译步骤。_build_function_map_statically函数就像一个快速的侦察兵。它只"看"了一下所有help_*.py文件,画出了一张"哪个函数在哪"的地图,而没有真正进入任何一间"房子"(加载模块)。- 只有当
tools.some_function()被实际调用 时,__getattr__才会被触发,根据地图精确地import那个小文件。编译成本被完美地分摊到了每一次不同功能的首次调用上。
这次优化后,import tools 的耗时也消失了。
第四站:釜底抽薪 ------ 为全局配置模块实现代理
我的 config.py 是一个"重灾区"。它不仅定义常量,还会在被导入时就读写 .json 配置文件,并被当作全局变量在多个模块中被修改和读取。这种顶层 I/O 操作,严重拖慢了任何 import config 的模块。
解决方案:代理模式与模块替换
由于 config 模块的接口不能变,我使用了一个高级技巧:代理模式。
- 将原
config.py重命名为_config_loader.py(内部实现)。 - 创建一个新的
config.py,它本身是一个"代理对象"。
python
# 新的 videotrans/configure/config.py
import sys
import importlib
class LazyConfigLoader:
def __init__(self):
object.__setattr__(self, "_config_module", None)
def _load_module_if_needed(self):
# 首次访问时,才加载 _config_loader
if self._config_module is None:
self._config_module = importlib.import_module("._config_loader", __package__)
def __getattr__(self, name): # 拦截读操作: config.params
self._load_module_if_needed()
return getattr(self._config_module, name)
def __setattr__(self, name, value): # 拦截写操作: config.current_status = "ing"
self._load_module_if_needed()
setattr(self._config_module, name, value)
# 用代理实例替换掉当前模块
sys.modules[__name__] = LazyConfigLoader()这个方案的精妙之处在于:
- 模块替换 :
sys.modules[__name__] = ...这行代码,让所有import config的地方,得到的都是我这个LazyConfigLoader的实例。 - 拦截与转发 :
__getattr__和__setattr__使得这个代理对象可以拦截所有对它的属性的读写操作。 - 状态唯一性 :所有的读写操作,最终都被转发到了同一个、只被加载一次 的
_config_loader模块上。这完美地保证了config作为一个全局状态存储,其数据在所有模块间都是一致和同步的。
终极冲刺:让第一印象完美
经过以上优化,我的应用逻辑层面已经非常快了。但启动时,依然有几秒钟的白屏,启动画面才姗姗来迟。
最后的瓶颈:PySide6.QtWidgets 的重量 import PySide6.QtWidgets 是一个非常重的操作。它不仅加载 Python 代码,更重要的是,它会在后台加载大量与窗口系统交互的 C++ 动态链接库。这是显示任何窗口前都无法避免的开销。
解决方案:两阶段启动 既然无法避免,那就让它在用户最不经意的时候发生。
- 阶段一:显示启动画面
- 在入口
main.py中,只import那些最最核心、轻量级的 PySide6 组件,比如from PySide6.QtWidgets import QApplication, QWidget。 - 立即创建并
show()一个极简的、无任何其他依赖的启动窗口StartWindow。
- 在入口
- 阶段二:后台加载
- 在
StartWindow显示后,通过QTimer.singleShot(50, ...)触发一个initialize_full_app函数。 - 在这个函数里,才开始执行所有我们之前优化的懒加载流程:
import config,import tools, 创建主窗口MainWindow等。 - 当一切准备就绪后,
show()主窗口,并close()启动窗口。
- 在
python
# main.py 的核心逻辑
if __name__ == "__main__":
# 阶段一:只做最少的事
app = QApplication(sys.argv)
splash = StartWindow()
splash.show()
# 安排阶段二在事件循环开始后执行
QTimer.singleShot(50, lambda: initialize_full_app(splash, app))
sys.exit(app.exec())这个方案为用户提供了即时反馈。双击图标,启动画面几乎瞬间出现。用户知道程序已经响应了,之后的所有加载都在这个友好的界面下进行,极大地改善了用户体验。
结语
这次长达数天的性能优化之旅,像一次对代码的深度"考古"。它让我深刻理解到,好的软件设计,不仅仅是实现功能,更在于对结构、性能和用户体验的持续关注。回顾整个过程,我总结出几点感悟:
- 数据驱动,刨根问底:没有性能剖析,一切优化都是空谈。
- 懒惰是美德:在启动阶段,"按需加载"是最高设计原则。不要在用户需要之前,准备任何东西。
- 理解
import的代价:它不是免费的。大文件和长导入链会累积成显著的编译成本。 - 模块化与单一职责:拆分"大杂烩"模块,是解决性能和维护性问题的根本途径。
- 善用语言的动态特性 :
importlib,ast,__getattr__等工具,虽然不常用,但在解决复杂加载问题时,它们是能创造奇迹的"瑞士军刀"。
项目源码见: github.com/jianchang51...