Data-Juicer 完整安装与使用教程

概述
Data-Juicer 是一个大规模数据预处理工具,专门为大型语言模型(LLM)设计。它提供了丰富的数据处理操作符和可视化工具,帮助用户高效地清洗、分析和处理训练数据。
环境准备
1. 安装 Miniconda
如果系统中尚未安装 Conda,首先安装 Miniconda:
bash
# 下载 Miniconda 安装脚本
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-latest-Linux-x86_64.sh
# 静默安装到用户目录
bash Miniconda3-latest-Linux-x86_64.sh -b -p $HOME/miniconda3
# 初始化 Conda
~/miniconda3/bin/conda init bash
# 使配置生效
source ~/.bashrc解释:
-b参数表示批处理模式,无需交互-p指定安装路径conda init bash将 Conda 添加到 shell 环境变量中
2. 配置 Conda 清华镜像
为了加速国内下载速度,配置 Conda 使用清华镜像源:
bash
cat > ~/.condarc << 'EOF'
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
EOF解释:这个配置将 Conda 的默认源替换为国内镜像,显著提升包下载速度。
3. 创建专用环境
bash
# 创建 Python 3.10 环境
conda create -n dj-dev python=3.10 -y
# 激活环境
conda activate dj-dev解释:创建独立的 Conda 环境可以避免与系统其他 Python 包的版本冲突。
4. 配置 pip 镜像
bash
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple安装 Data-Juicer
1. 下载源码
bash
# 从 GitHub 克隆仓库
git clone https://github.com/modelscope/data-juicer.git
cd data-juicer或者下载 ZIP 包上传到服务器后解压。
2. 解决依赖冲突
在安装过程中可能会遇到 numpy 版本冲突,先安装指定版本的 numpy:
bash
conda install -c conda-forge numpy=1.26.4 pip -y问题背景:Data-Juicer 1.4.3 依赖 numpy<2.0.0 且 >=1.26.4,而其他包如 thinc 8.3.6 依赖 numpy>=2.0.0,这会导致版本冲突。提前安装指定版本可以避免此问题。
3. 安装 Data-Juicer
bash
# 以开发模式安装
pip install -e .-e 参数表示以可编辑模式安装,对源码的修改会立即生效。
验证安装
1. 检查安装状态
bash
pip show py-data-juicer
# 或查看详细文件
pip show -f py-data-juicer应该能看到 dj-analyze, dj-install, dj-process 等脚本。

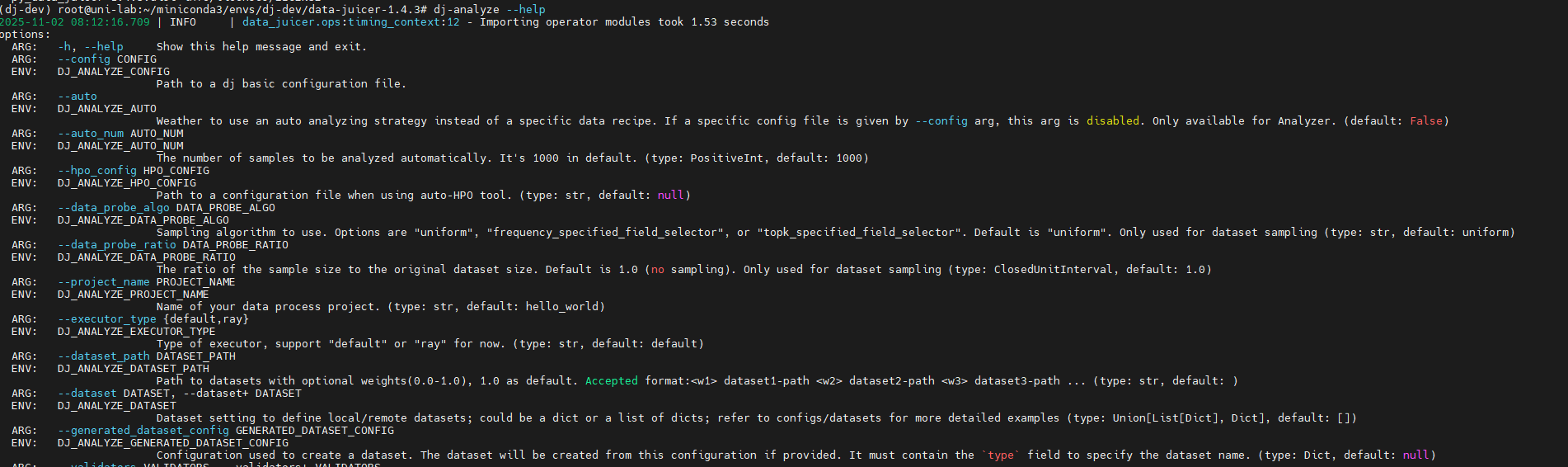
2. 测试命令行工具
bash
# 在 dj-dev 环境中执行
dj-analyze --help
dj-install --help
dj-process --help注意:首次运行时会自动安装缺失的依赖(如 torch),这是正常现象。系统会检测 GPU 环境并自动安装相应的 CUDA 版本。
启动 Data-Juicer Agent (UI界面)
Data-Juicer 提供了丰富的 Web UI 界面,可以通过 Streamlit 启动。
单个模块启动
进入对应模块目录启动:
bash
# 进入主应用目录
cd /root/miniconda3/envs/dj-dev/data-juicer-1.4.3/
streamlit run app.py
# 或进入特定模块目录
cd /root/miniconda3/envs/dj-dev/data-juicer-1.4.3/demos/data_visualization_op_effect/
streamlit run app.py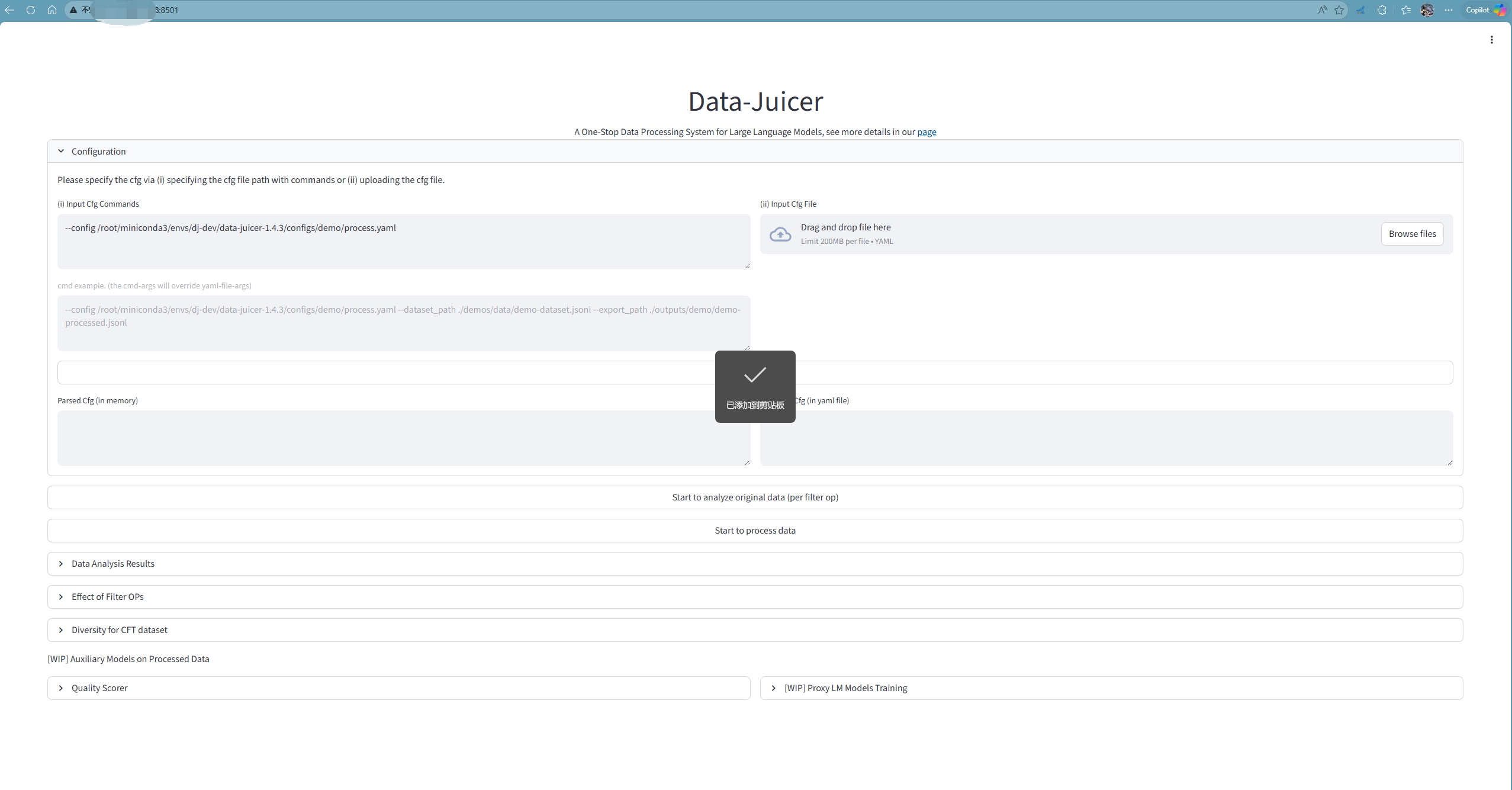
后台启动
bash
# 前台启动(默认端口8501)
streamlit run app.py
# 后台启动,日志保存到文件
nohup streamlit run app.py > agent.log 2>&1 &
# 指定端口启动
streamlit run app.py --server.port 8502批量启动多个模块
创建启动脚本 /root/start_dj_modules.sh:
bash
#!/bin/bash
# 一键启动 DataJuicer Agent + 多个 Streamlit 模块后台运行
# 每个模块独立日志和端口
# 激活 conda 环境
source ~/miniconda3/etc/profile.d/conda.sh
conda activate dj-dev
# 创建日志目录
mkdir -p /root/dj_logs
# 定义模块路径和端口
declare -A modules
modules["agent"]="/root/miniconda3/envs/dj-dev/data-juicer-1.4.3/app.py:8501"
modules["op_effect"]="/root/miniconda3/envs/dj-dev/data-juicer-1.4.3/demos/data_visualization_op_effect/app.py:8502"
modules["statistics"]="/root/miniconda3/envs/dj-dev/data-juicer-1.4.3/demos/data_visualization_statistics/app.py:8503"
modules["diversity"]="/root/miniconda3/envs/dj-dev/data-juicer-1.4.3/demos/data_visualization_diversity/app.py:8504"
# 启动模块函数
start_module() {
local path=$1
local port=$2
local name=$3
local log_file="/root/dj_logs/${name}.log"
echo "Starting $name on port $port, logging to $log_file"
nohup streamlit run "$path" --server.port "$port" > "$log_file" 2>&1 &
sleep 2 # 等待 2 秒,避免同时启动冲突
}
# 遍历模块启动
for name in "${!modules[@]}"; do
entry=${modules[$name]}
IFS=':' read -r path port <<< "$entry"
start_module "$path" "$port" "$name"
done
echo "All DataJuicer modules started."
echo "Check logs in /root/dj_logs/"给脚本添加执行权限并运行:
bash
chmod +x /root/start_dj_modules.sh
./root/start_dj_modules.sh检查运行状态
bash
# 检查所有 Streamlit 进程
ps -ef | grep streamlit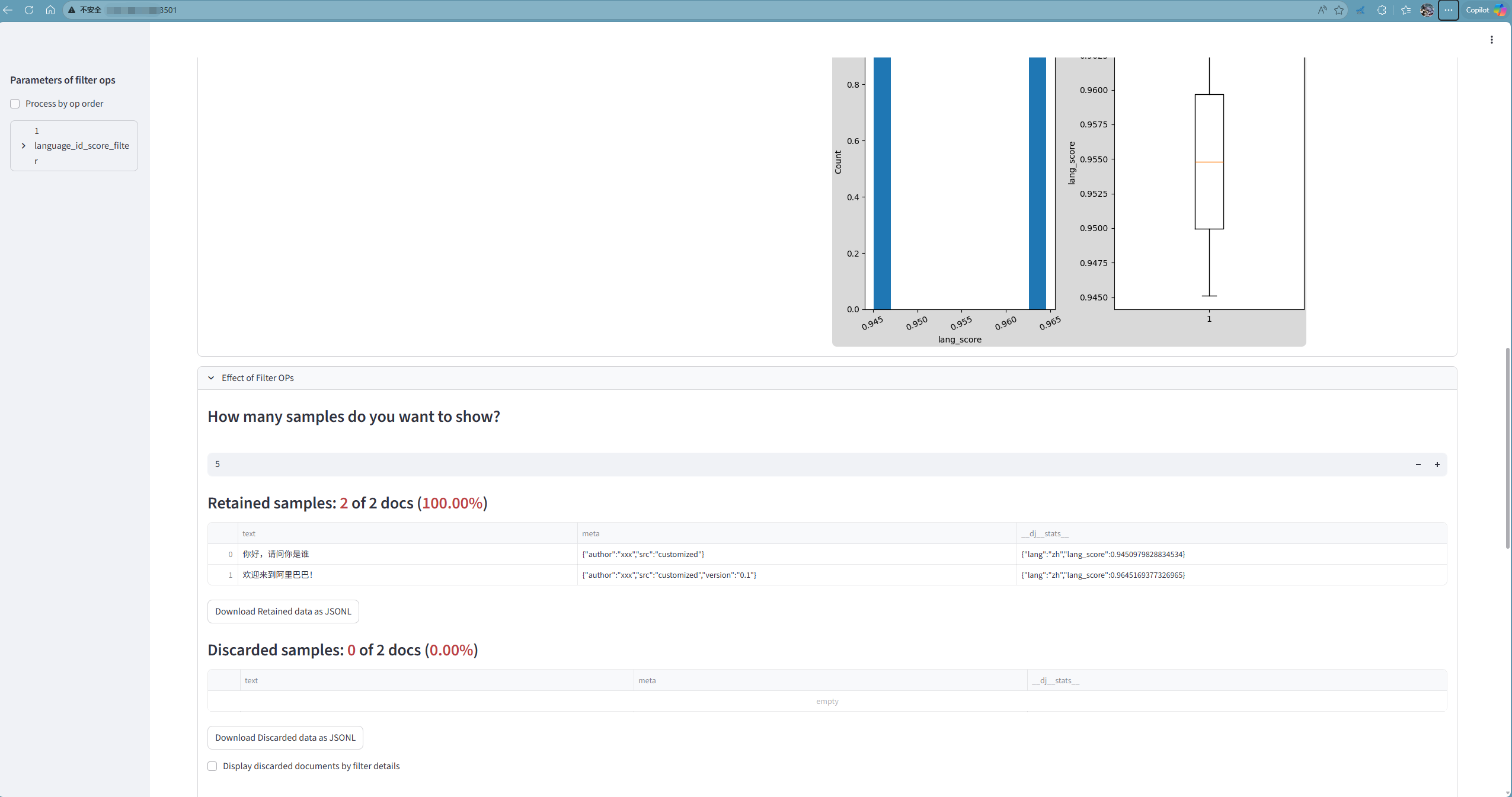
可用模块介绍
启动后可以通过相应端口访问以下模块:
主要模块
- 主应用 (端口8501): 综合数据处理界面
- 算子效果可视化 (端口8502): 显示不同 Filter 算子在各种阈值下的效果
- 统计信息可视化 (端口8503): 分析数据集获得多达13种统计信息
- 词法多样性可视化 (端口8504): 分析 CFT 数据集的动词-名词结构
其他功能模块
- 数据集样例 (data): 包含样例数据集
- 初探索 (overview_scan): 介绍基本概念和功能
- 数据处理回路 (data_process_loop): 分析和处理数据集
- 处理 CFT 中文数据: 演示指令跟随微调数据的处理流程
- 处理预训练科学文献类数据: 以 arXiv 数据为例
- 处理预训练代码类数据: 以 Stack-Exchange 数据为例
- 文本质量打分器: 提供3种文本质量评估方法
- 按语言分割数据集: 按语言拆分数据集
- 数据混合: 从多数据集采样合并
故障排除
常见问题1: numpy 版本冲突
如果安装时出现依赖冲突,手动安装指定版本:
bash
conda install -c conda-forge numpy=1.26.4 pip -y常见问题2: 首次运行缓慢
首次运行 dj-analyze --help 等命令时会自动安装 torch 等依赖,这是正常现象。
常见问题3: 端口被占用
如果默认端口8501被占用,使用 --server.port 参数指定其他端口。
总结
通过本教程,您已经成功:
- 安装了 Miniconda 并配置了国内镜像
- 创建了独立的 Python 环境
- 安装并验证了 Data-Juicer
- 学会了如何启动 Web UI 界面
- 了解了各个功能模块的作用