在信息爆炸和任务复杂度日益提升的今天,单一 AI 工具已难以胜任深度研究的挑战。字节跳动开源的 DeerFlow 是一个集成多智能体、支持端到端自动化的研究框架,让语言模型不再孤军奋战。它像一支训练有素的 AI 团队,协作完成搜索、分析、代码执行、报告生成等复杂任务,显著提升研究效率与质量。无论你是科研人员、开发者,还是内容创作者,DeerFlow 都可能成为你通往智能研究新时代的关键利器。
引言
在人工智能飞速发展的今天,大语言模型(LLM)正以前所未有的速度改变着我们的工作和生活方式。然而,面对海量的信息和复杂的任务,如何高效地进行深度研究,并从中提炼出有价值的洞察,成为了摆在研究人员和开发者面前的一大挑战。传统的单一AI工具往往难以应对这种复杂性,而多智能体系统则被认为是解决这一难题的关键。
正是在这样的背景下,字节跳动推出了其开源力作------DeerFlow。DeerFlow,全称为"深度探索与高效研究流程"(Deep Exploration and Efficient Research Flow),它不仅仅是一个简单的LLM封装,更是一个模块化、可扩展、且具备人机协作能力的多AI智能体框架。它将语言模型、搜索引擎、网络爬虫、代码执行以及文本转语音等多种功能巧妙地融合在一起,旨在自动化端到端的研究流程,帮助用户从繁琐的信息收集和整理工作中解脱出来,专注于更有价值的"智能工作"。
本文将深入探讨 DeerFlow 的核心概念、独特优势、架构设计以及应用,无论你是AI领域的从业者、研究员,还是希望将AI能力融入自身工作流的开发者,相信DeerFlow都能带来全新的视角和无限可能。
DeerFlow 核心概念与多智能体架构
DeerFlow 的核心在于其创新的多智能体协作机制。它打破了传统单一模型处理复杂任务的局限,通过协调多个具备特定功能的AI智能体,共同完成深度研究的各个环节。这种设计不仅提高了任务处理的效率和准确性,也使得整个研究过程更加透明和可控。
核心概念
- 深度探索与高效研究流程 (Deep Exploration and Efficient Research Flow): 这是 DeerFlow 名称的由来,也明确了其核心目标------帮助用户进行深入、全面且高效的研究。
- 模块化多智能体框架: DeerFlow 的设计理念是将复杂的深度研究任务分解为多个子任务,并由不同的专业智能体负责。每个智能体都专注于其特定领域,例如信息检索、代码执行、报告撰写等,并通过协作完成整体目标。
- 人机协作 (Human-in-the-Loop): DeerFlow 并非一个完全自主的"黑箱"系统。它强调人类的参与和反馈,允许用户在研究过程中进行干预、调整方向或修正智能体的决策,确保研究结果符合人类的预期和特定需求。
- 端到端自动化: 从最初的用户查询到最终的多模态研究成果(如报告、播客、演示文稿),DeerFlow 旨在实现整个研究流程的自动化,极大地节省了用户的时间和精力。
多智能体架构详解
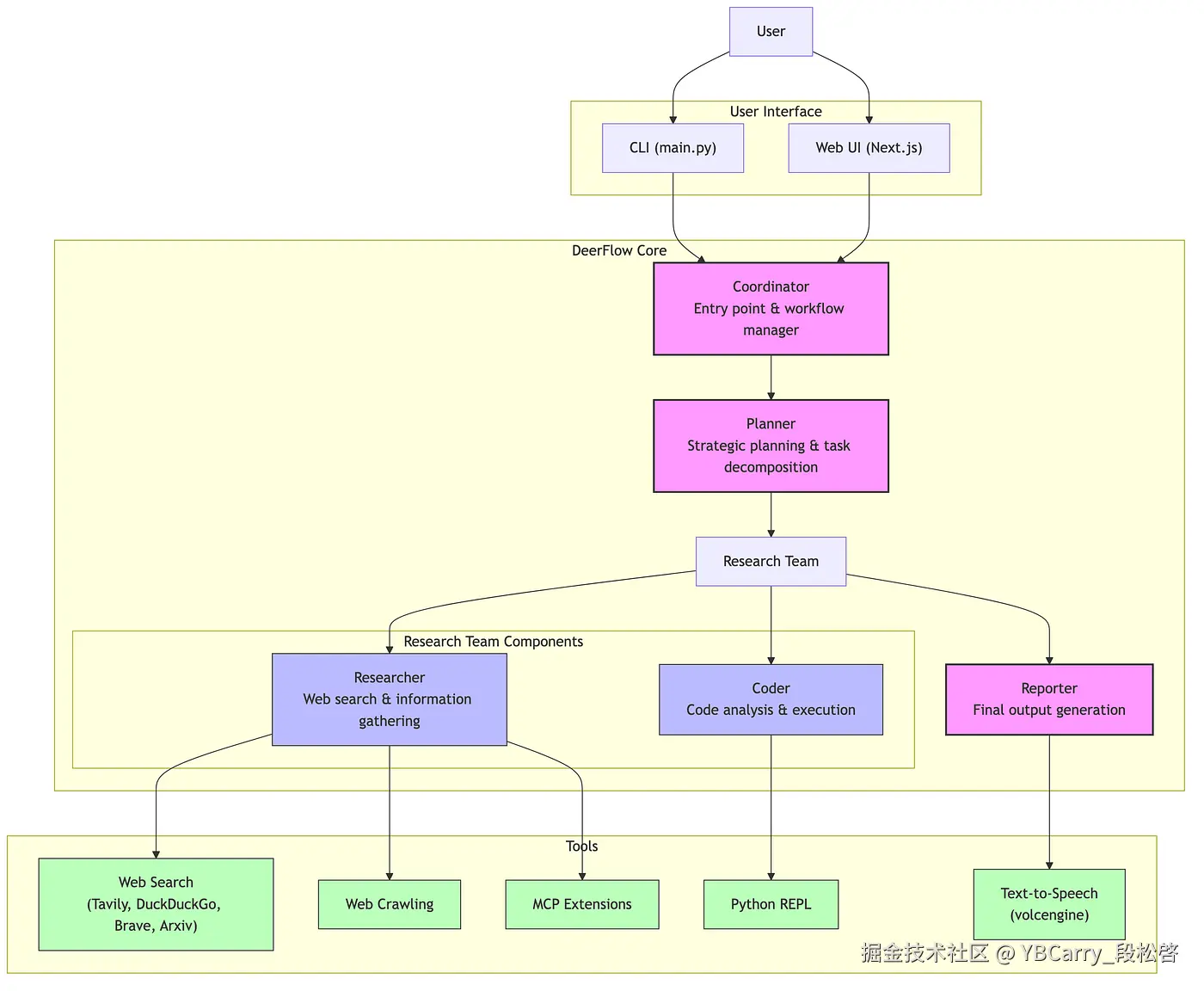
DeerFlow 的强大功能得益于其精心设计的模块化多智能体架构。该架构基于 LangGraph 构建,LangGraph 是一种灵活且可追溯的状态机架构,用于管理智能体之间的协作和数据流。以下是 DeerFlow 架构中的主要组成部分和它们各自的角色:
1. 协调器 (Coordinator)
协调器是整个 DeerFlow 系统的"大脑"和"指挥官"。它负责接收用户的初始研究查询,并将其传递给规划者。协调器的主要职责是:
- 任务接收: 接收来自用户的研究请求。
- 启动规划: 启动规划引擎,开始整个研究流程。
- 任务分发: 根据规划者的指示,将不同的子任务分发给相应的智能体。
2. 规划者 (Planner)
规划者是 DeerFlow 的"战略家"。它负责将用户提出的复杂研究问题分解为一系列逻辑性的、可执行的子任务,并制定详细的研究路线图。规划者的关键功能包括:
- 问题分解: 将宏观的研究问题拆解为更小、更具体的子问题。
- 路径规划: 决定研究的步骤和顺序,包括何时进行信息收集、何时进行数据分析、何时生成报告等。
- 循环决策: 判断是否需要回溯以获取更多信息,或者是否可以继续推进到报告生成阶段。
3. 研究团队 (Research Team)
研究团队是 DeerFlow 执行具体研究任务的核心力量,它由多个专业智能体组成,各司其职,协同作战:
- 研究员 (Researcher): 这是信息收集的"先锋"。研究员智能体负责执行网络搜索、利用网络爬虫工具(如 Jina)从网页中提取相关内容,并调用各种API(如 Tavily, Brave Search, DuckDuckGo, Arxiv)来获取所需数据。它确保了研究信息的广度和深度。
- 程序员 (Coder): 程序员智能体是数据分析和验证的"专家"。它能够执行 Python 代码片段,进行数据处理、统计分析、运行模拟或验证引用。这使得 DeerFlow 不仅仅停留在文本信息的处理,还能深入到数据和代码层面进行分析。
- 报告员 (Reporter): 报告员智能体是信息整合和呈现的"艺术家"。它利用大型语言模型(LLM)将研究员和程序员收集、分析的所有信息进行总结、归纳,并生成结构化、人类可读且可由AI进一步编辑的报告、演示文稿或播客脚本。它确保了最终输出的质量和可理解性。
4. 工具与集成 (Tools & Integrations)
DeerFlow 的强大功能离不开其丰富的工具集和灵活的集成能力。它利用 LangGraph 来管理智能体之间的状态和通信,并支持与多种外部工具和平台的无缝对接:
- 搜索与爬虫工具: 支持 Tavily、Brave Search、DuckDuckGo、Arxiv 等主流搜索API,以及 Jina 等网络爬虫工具,确保信息来源的广泛性。
- 语言模型集成: 通过 LiteLLM 支持包括 OpenAI 兼容模型在内的多种大型语言模型,以及各类开源模型,为智能体提供强大的语言理解和生成能力。
- 文本转语音 (TTS): 集成 volcengine TTS 等工具,能够将最终的文本报告转换为高质量的音频,方便用户以播客等形式消费研究成果。
- 演示文稿生成: 利用 marp-cli 等工具生成 PowerPoint 幻灯片,提供多样化的输出形式。
- 外部系统连接: 易于连接到 Notion 或自定义数据库等外部系统,方便用户管理和利用研究数据。
通过这种精巧的多智能体架构,DeerFlow 能够模拟人类研究员的工作流程,将复杂的深度研究任务分解、执行、整合,并最终以多模态的形式呈现,极大地提升了研究效率和成果质量。
DeerFlow 的关键特性与独特优势
DeerFlow 不仅仅是一个多智能体框架,它还集成了多项关键特性,使其在深度研究和自动化领域脱颖而出,为用户带来了显著的优势。
1. 强大的端到端研究自动化能力
DeerFlow 能够实现从用户查询到最终成果的完整自动化流程。这意味着用户只需提供一个研究问题,DeerFlow 就能自动完成信息收集、数据分析、内容整合和多模态输出。例如,它可以自动撰写报告、总结论文、生成播客甚至制作演示文稿,极大地解放了研究人员的双手,让他们能够专注于更高层次的思考和决策。
2. 灵活的即插即用工具集成
DeerFlow 提供了丰富的工具集成能力,支持多种主流的搜索 API(如 Tavily、Brave Search、DuckDuckGo、Arxiv)和网络爬虫工具(如 Jina)。更重要的是,它设计上具备高度的可扩展性,允许用户轻松集成自定义 API 或模型。这种灵活性使得 DeerFlow 能够适应不同领域和场景的研究需求,确保其始终能够获取最新、最全面的信息。
3. 强调人机协作的"人机互动反馈"机制
与一些完全自主但缺乏透明度的系统不同,DeerFlow 将"人机互动反馈"(Human-in-the-Loop)作为其核心设计理念。用户可以实时审查智能体的推理过程,了解它们是如何做出决策的;也可以在任何阶段进行干预,调整研究方向,甚至纠正智能体的错误。这种机制不仅增强了系统的透明度和可控性,也确保了研究结果能够精准地符合用户的意图和领域特定的目标,尤其在需要高精度和人类监督的科研环境中显得尤为重要。
4. 多样化的多模态输出形式
DeerFlow 不仅仅局限于文本输出。它能够生成多种形式的研究成果,以满足不同用户的需求:
- 结构化报告: 生成 Notion 风格的精炼报告,支持 Markdown 格式,方便用户进行后续编辑和分享。
- 演示文稿: 利用 marp-cli 等工具自动生成 PowerPoint 幻灯片,为用户提供便捷的展示方式。
- 播客与音频: 集成 volcengine TTS 等文本转语音技术,将研究报告转换为高质量的播客风格音频,极大地拓展了研究成果的传播和消费方式。
5. 开发者友好与高度可定制性
DeerFlow 为开发者提供了友好的开发环境和高度的可定制性。它支持 Python 3.12+ 和 Node.js 22+,开发者可以:
- 修改代理图: 根据具体需求调整智能体之间的协作流程和逻辑。
- 集成新工具: 轻松将新的搜索工具、API 或自定义模型集成到框架中。
- 灵活部署: 支持在云端和本地环境中部署系统,满足不同规模和安全需求的应用场景。
框架中还包含了预配置的管道和示例用例,使得无论是初学者还是经验丰富的开发者,都能够快速上手并进行二次开发。
DeerFlow 实操指南
DeerFlow 作为一款开源框架,其安装和运行过程相对直观。本节提供详细的步骤,帮助在本地环境中快速搭建 DeerFlow,并开始深度研究之旅。
1. 环境准备
在安装 DeerFlow 之前,请确保满足以下先决条件:
- Python: 版本 3.12 或更高。建议使用
pyenv或conda等工具管理 Python 版本。 - Node.js: 版本 22 或更高(用于 Web UI)。
- Git: 用于克隆 DeerFlow 的 GitHub 仓库。
- pip: Python 包管理器,通常随 Python 一同安装。
- 虚拟环境 (推荐): 为了隔离项目依赖,强烈建议为 DeerFlow 创建一个独立的 Python 虚拟环境。
- API 密钥 (可选): 访问大型语言模型(LLMs,如 OpenAI、Anthropic 或其他开源模型如 LLaMA)和可选的网络搜索 API(如 Tavily、Brave、SerpAPI)需要相应的 API 密钥。需要在
.env文件中配置这些密钥。
2. 安装流程
请按照以下步骤进行安装:
步骤 1:克隆 DeerFlow 仓库
首先,打开终端或命令行工具,使用 Git 克隆 DeerFlow 的官方仓库:
bash
git clone https://github.com/bytedance/deer-flow.git
cd deer-flow步骤 2:设置 Python 虚拟环境 (推荐)
进入 deer-flow 目录后,创建并激活一个 Python 虚拟环境:
bash
python -m venv venv
source venv/bin/activate # macOS/Linux
# 或者在 Windows 上使用:.\venv\Scripts\activate步骤 3:安装 Python 依赖
激活虚拟环境后,安装 DeerFlow 所需的 Python 依赖。这些依赖包括 LangChain、LangGraph 以及用于网络搜索和代码执行的其他库:
bash
pip install -r requirements.txt步骤 4:安装 Node.js 依赖 (用于 Web UI)
如果计划使用 DeerFlow 的 Web 用户界面,需要安装 Node.js 依赖。首先进入 web 目录,然后运行 npm install:
bash
cd web
npm install
cd .. # 返回到项目根目录步骤 5:配置环境变量
在 deer-flow 项目的根目录下,创建一个名为 .env 的文件,并添加 API 密钥和相关设置。例如:
ini
OPENAI_API_KEY=your_openai_key
TAVILY_API_KEY=your_tavily_key
LANGCHAIN_API_KEY=your_langchain_key请根据实际使用的 LLM 和搜索服务提供商替换 your_openai_key 等占位符。有关更多配置选项(如模型选择或代理设置),参考 DeerFlow 的官方文档。
3. 运行 DeerFlow
完成安装和配置后,可以运行 DeerFlow 的核心 Python 框架或启动其 Web UI。
运行核心 Python 框架
在项目根目录下,直接运行 main.py 文件:
bash
python main.py这将启动 DeerFlow 的核心逻辑,可以通过命令行与它进行交互或运行预设的示例。
运行 Web UI
如果安装了 Web UI 依赖,可以在 web 目录下启动 Web 用户界面:
bash
cd web
npm startWeb UI 启动后,可以通过浏览器访问 http://localhost:3000 来探索 DeerFlow 的图形界面,并进行交互式操作。
4. 验证安装
为了验证 DeerFlow 是否成功安装并正常运行,可以尝试运行其包含的示例管道,例如 example_research.py,它演示了一个基本的研究任务,如比较地标信息。
故障排除
如果在安装或运行过程中遇到问题,请检查以下几点:
- 确保所有依赖项与 Python 和 Node.js 版本兼容。
- 查看 DeerFlow GitHub 仓库的 Issues 部分,那里通常会列出常见错误及其解决方案。
- 对于云部署,请参考官方文档配置环境,例如使用 Docker 或 Kubernetes。
结论与展望
字节跳动开源的 DeerFlow 框架,无疑为大语言模型时代的深度研究和自动化领域带来了新的活力。它以其模块化的多智能体架构、灵活的工具集成、强调人机协作的设计理念、多样化的多模态输出能力以及活跃的开源社区支持,展现了超越传统单一 AI 工具的强大潜力。
DeerFlow 不仅仅是一个技术框架,它更代表了一种新的研究范式------通过智能体之间的协同工作,将复杂的研究任务分解、自动化,并最终以高效、透明和可控的方式呈现。这对于面临海量信息和复杂任务挑战的学者、企业和个人而言,无疑是一个福音。
当然,作为一款新兴的开源项目,DeerFlow 仍面临着一些挑战,例如不同工具的集成复杂性、跨环境兼容性以及智能体偶尔可能出现的"幻觉"问题。然而,这些挑战也正是开源社区持续创新和改进的动力所在。
展望未来,随着大语言模型技术的不断演进和开源社区的蓬勃发展,我们有理由相信 DeerFlow 将会持续优化其强化学习能力,支持更多样化的 LLM,并集成更先进的可视化工具。它有望成为深度研究领域不可或缺的"瑞士军刀",赋能更多用户,推动 AI 技术在各行各业的深度应用。
DeerFlow 的兴起,也再次印证了开源 AI 的巨大潜力。通过民主化先进技术的访问,开源项目使得资源有限的组织和个人也能与行业巨头同台竞技,共同推动 AI 领域的创新和发展。我们期待 DeerFlow 在未来能够持续成长,为全球的研究者和开发者带来更多惊喜和价值。