note
- 相关讨论:SFT为啥比RL更容易导致遗忘
- RL的本质就是一个sampling based 的优化过程,我们有一个分布,采样得到的轨迹有的reward大,有的reward小,那么我们就增大采reward大的轨迹的概率,减小采reward小的轨迹的概率。这个过程中我们希望模型更新要足够稳健,不能过于激进。
- 打个比方,比如投资股票,如果看到某只股票突然猛涨或者猛跌就立马追涨杀跌,那么这样的策略大概率是很难稳定的获利的。所以PPO比之前的RL算法效果好的一个最本质的原因就是clip掉了那些有很大reward涨落的轨迹,让模型的优化更加稳定。
- 所以从这个角度看,RL这个算法天然地就会限制LLM模型后训练之后和之前的差别(更像是分布的锐化,而非参数空间的巨大改变),所以遗忘现象没有普通的sft严重也是很合理的事情了。
- 《Does RLVR enable LLMs to self-improve》论文发现:
- RLVR 后模型的能力完全在基础模型的能力范围内,只是搜索效率提高了,能更高效地找到问题的解。而基础模型不能解决的问题,RLVR 的模型一样不能解决。
- 在 @1 的时候,RL 模型的表现都会好于基模,但是随着 K 的增大,和基模的表现越来越接近,直到在 K 较大时 RL 被基模超越。而且这个结论对于各种 RL 方法(PPO/GRPO等),在各种评估测试集(数学、代码、视觉推理),各种模型大小上面都适用。
文章目录
一、研究背景
论文:Does RLVR enable LLMs to self-improve?
- 研究问题:这篇文章探讨了强化学习(RL)在提升大型语言模型(LLMs)推理能力方面的潜力,特别是是否超越了基础模型的推理能力。
- 研究难点:该问题的研究难点包括:如何准确评估LLMs的推理能力边界,以及现有的RLVR方法是否能够引入新的推理模式。
- 相关工作:该问题的研究相关工作包括OpenAI的o1模型、DeepSeek-R1等,这些工作展示了LLMs在复杂逻辑任务中的显著进步,但对其推理能力的提升机制尚不明确。
(1)可验证奖励:首先,定义了一个LLM生成序列 y = ( y 1 , ... , y T ) y = (y_1, \ldots, y_T) y=(y1,...,yT),并引入一个确定性验证器 V \mathcal{V} V,返回二进制奖励 r ∈ { 0 , 1 } r \in \{0, 1\} r∈{0,1},其中 r = 1 r = 1 r=1 当且仅当模型的最终答案完全正确。
RL的目标是最大化期望奖励:
J ( θ ) = E x ∼ D E y ∼ π θ ( ⋅ ∣ x ) \[ r ] J(\theta) = \mathbb{E}_{x \sim \mathcal{D}} \left \\mathbb{E}_{y \\sim \\pi_{\\theta}(\\cdot\|x)} \[r \right] J(θ)=Ex∼DEy∼πθ(⋅∣x)\[r]
其中 D \mathcal{D} D 是提示的分布。
(2)RLVR算法:使用近端策略优化算法,其目标函数为:
L CLIP = E min ( r t ( θ ) A t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A t ) \mathcal{L}_{\text{CLIP}} = \mathbb{E} \left \\min \\left( r_t(\\theta) A_t, \\operatorname{clip} \\left( r_t(\\theta), 1-\\epsilon, 1+\\epsilon \\right) A_t \\right) \\right LCLIP=Emin(rt(θ)At,clip(rt(θ),1−ϵ,1+ϵ)At)
其中:
- r t ( θ ) = π θ ( y t ∣ x , y < t ) π θ old ( y t ∣ x , y < t ) r_t(\theta) = \dfrac{\pi_\theta (y_t \mid x, y_{<t})}{\pi_{\theta_{\text{old}}} (y_t \mid x, y_{<t})} rt(θ)=πθold(yt∣x,y<t)πθ(yt∣x,y<t)
- A t A_t At 是由价值网络 V ϕ V_\phi Vϕ 估计的优势
(3)评估指标:采用 pass@k 指标来评估推理能力边界,定义为如果任意一个样本通过验证,则问题视为解决。平均 pass@k 反映了模型在 k 次尝试内解决问题的问题比例。
二、相关现象
RLVR 后模型的能力完全在基础模型的能力范围内,只是搜索效率提高了,能更高效地找到问题的解。而基础模型不能解决的问题,RLVR 的模型一样不能解决。
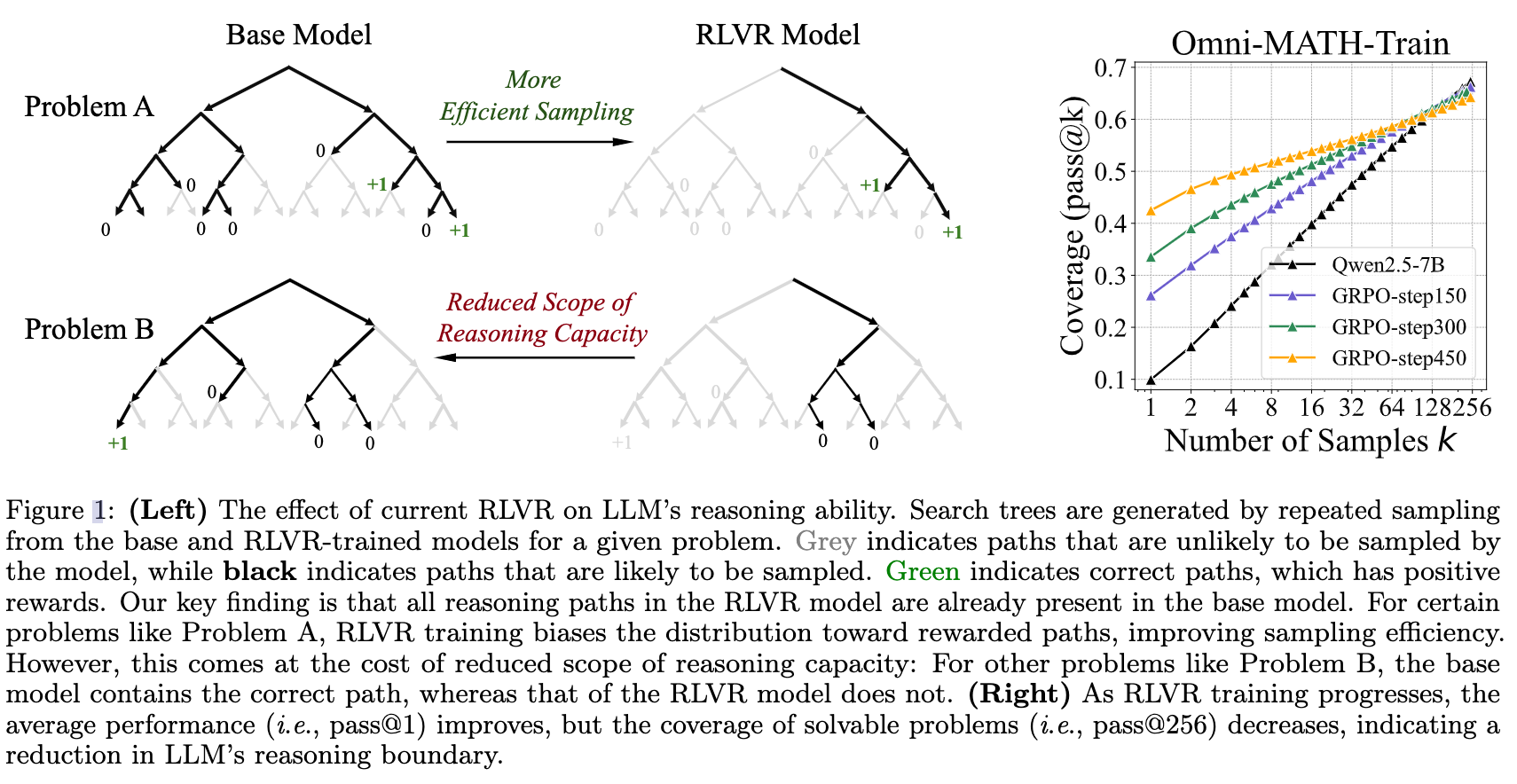
三、实验结论
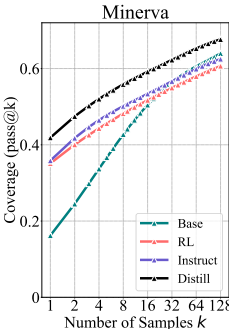
(1)数学推理:在小k值(如k=1)时,RL训练模型表现优于基础模型,但随着k值的增加,基础模型在所有基准上均超过RL训练模型。这表明RLVR增加了正确样本的采样概率,但缩小了可解问题的覆盖范围。
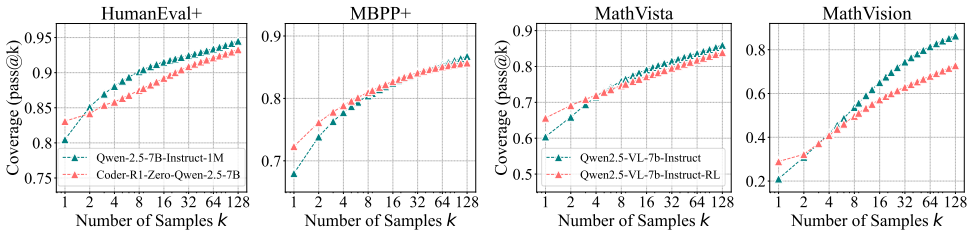
(2)编程推理:与数学推理类似,RLVR在编程任务中也表现出小k值时的优势,但随着k值的增加,基础模型的表现更好。
(3)视觉推理:在视觉推理任务中,RLVR的效果与数学和编程任务一致,基础模型在可解问题上的覆盖范围更广。
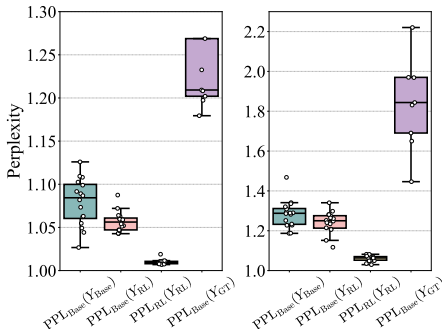
(4)准确性分布分析:RLVR训练后,模型的高准确性频率增加,低准确性频率减少,但出现了更多无法解决的问题。
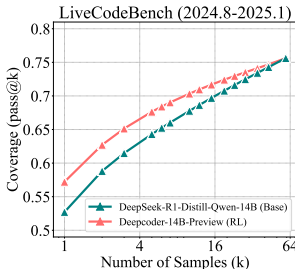
(5)蒸馏对比:蒸馏模型在pass@k曲线上显著高于基础模型,表明蒸馏能够引入新的推理模式,扩展模型的推理能力。
Reference
1 Does RLVR enable LLMs to self-improve