Spring Cloud Hystrix 用于处理分布式系统的延迟和故障,它通过提供断路器、fallback机制和其他服务保护措施,帮助提高系统应对失败的能力,并防止连锁故障的发生,从而提升整个系统的弹性。
但是,Netflix 已经宣布停止对 Hystrix 的开发,进入了维护模式,所以新项目更推荐使用 Sentinel 、 Resilience4j 等替代方案。不过,由于 Hystrix 的成熟度和广泛的社区支持,许多项目仍然在使用,所以我们仍可以了解 Hystrix 的设计思想。
主要特性
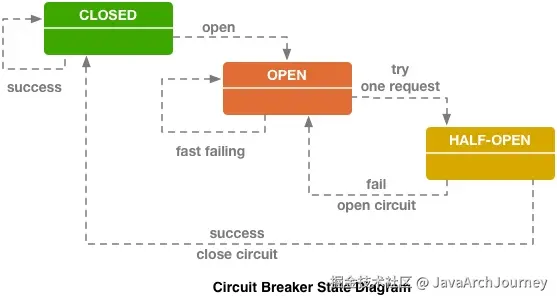
- 断路器模式:Hystrix 实现了断路器模式,能够监控并处理请求的失败与延迟。当某个服务的错误率超过一定的阈值时,断路器会打开以阻止后续请求继续访问该服务,通过这种快速失败的方式避免系统因依赖不可用的服务而被拖垮。同时,断路器会在一段时间后半开以探测服务是否恢复,若成功则关闭断路器以恢复正常的业务逻辑调用。
- 资源隔离:Hystrix 通过线程池或信号量对每个依赖进行资源隔离,确保任何一个依赖出现问题不会影响到其他依赖以及整个应用程序。
- Fallback(回退/兜底)机制:当请求失败或者被断路器阻止时,可以提供一个备用的响应,即 fallback 方法。这使得即使依赖的服务不可用,也能给用户提供一些有用的信息,而不是完全失败。
- 请求缓存:支持为单个请求提供缓存,减少重复请求带来的负载,同时也能提高响应速度。
- 请求合并:可以将多个相同类型的请求合并成一个请求发送给服务端,以减少网络和服务端的压力。
- 实时监控:Hystrix 提供了一个仪表盘,可以实时查看各个依赖服务的健康状况,包括请求的成功、失败、拒绝等统计信息。
核心原理
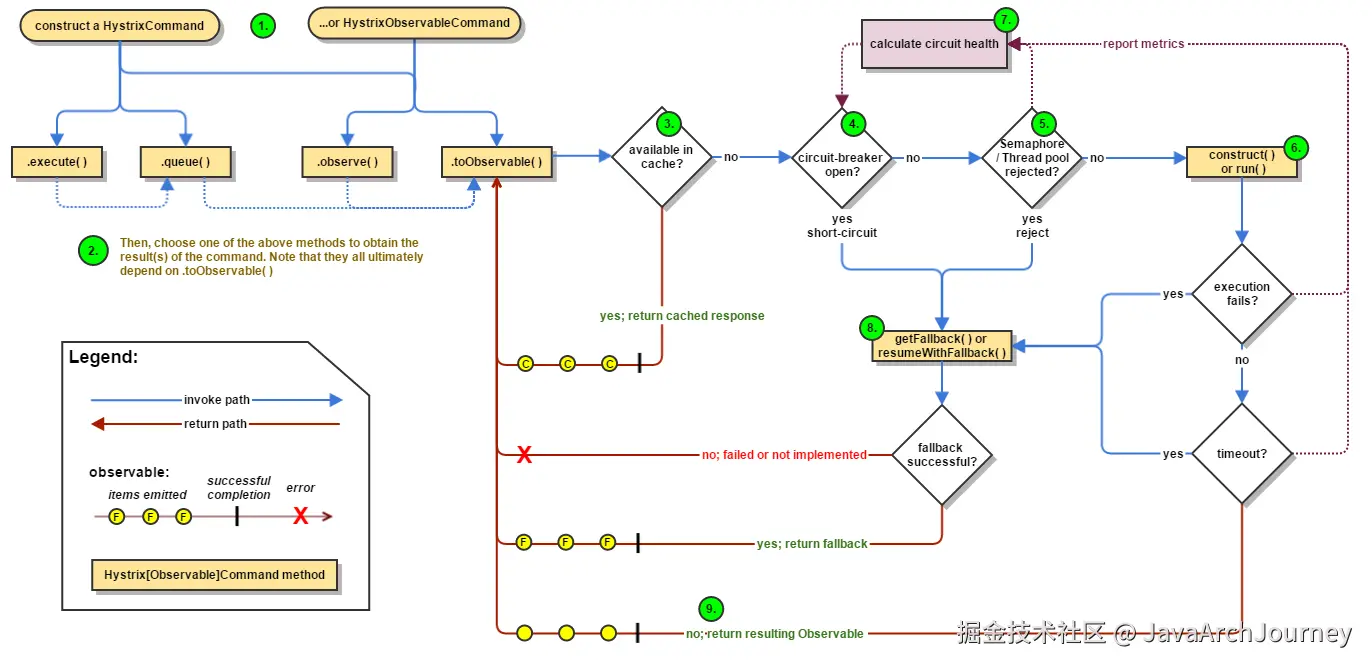
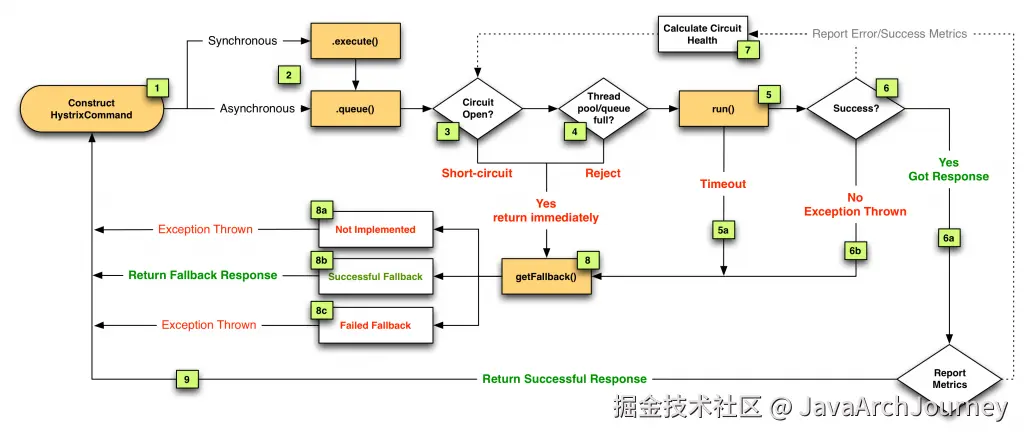
Hystrix 的基本处理流程:
- 构建 Hystrix 命令 :每个依赖服务调用都被包装成一个 Hystrix 命令对象(继承自
HystrixCommand或HystrixObservableCommand类)。这一步骤是使用 Hystrix 的起点。 - 检查缓存:在执行命令之前,Hystrix 会先检查是否有可用的缓存响应。如果有,并且缓存策略允许,那么直接返回缓存结果而不会实际执行命令。
- 断路器判断:Hystrix 使用断路器模式来阻止请求流向可能失败的服务。如果断路器是打开状态(表示服务不可用),则请求不会被转发,而是直接跳到第 6 步执行回退逻辑。
- 线程池/信号量资源检查:如果断路器是关闭状态,Hystrix 会检查负责该命令的线程池或信号量是否还有剩余资源。如果没有足够的资源,命令将立即拒绝并转向第 6 步。
- 执行命令:如果资源检查通过,Hystrix 将执行命令。如果命令执行成功,则返回正常响应;如果发生错误或者超时,将会进行相应的异常处理。
- 回退机制:如果命令执行过程中出现任何问题(包括但不限于超时、短路、失败等),Hystrix 会尝试执行回退逻辑(fallback 方法)。回退逻辑可以是返回一个默认值、抛出异常或其他定制行为。
- 记录度量指标:无论命令执行的结果如何,Hystrix 都会记录相关的度量信息,如成功、失败、超时等事件,这些数据会被用来决定断路器的状态。
- 更新断路器状态:基于收集到的度量指标,断路器可能会从关闭状态切换为打开状态,或者在一段时间后尝试半开状态以测试下游服务是否恢复。