【博客标题】
Kafka 全景入门:从诞生背景到生产实战,一文讲透核心架构、特性以及与RabbitMQ的对比
一、为什么要读这篇文章?
如果你正在调研消息中间件,或者刚接触 Kafka 却被「Broker / Partition / Consumer Group / Offset」等概念绕晕,那么这份课堂级笔记刚好能帮你把碎片化的知识点串成体系。
博客思维导图:
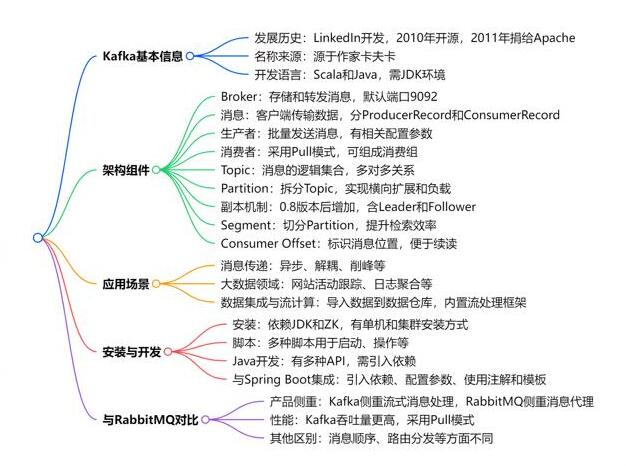
二、Kafka 的诞生故事:业务倒逼技术
- 背景
2010 年前后的 LinkedIn 每天要处理 7 万亿条实时数据,早期点对点集成、ActiveMQ 都扛不住,经常阻塞。 - 结果
LinkedIn 自研 Kafka,并于 2011 年捐给 Apache,名字取自小说家 卡夫卡(Franz Kafka)。 - 启示
业务复杂度 → 技术挑战 → 技术突破,这套逻辑在今天做架构选型时依旧适用。
三、Kafka 到底是什么?
官方给的定位是 "分布式流处理平台",不仅仅是一个消息队列(MQ)。它同时扮演 3 个角色:
- 消息引擎:高吞吐、低延迟发布/订阅
- 存储系统:消息持久化到磁盘,可重放
- 流处理平台:自带 Kafka Streams API,可做实时计算
四、核心概念速记(面试高频)
| 概念 | 一句话解释 |
|---|---|
| Broker | Kafka 服务器节点,默认端口 9092 |
| Topic | 逻辑队列,消息的一级分类 |
| Partition | 对 Topic 做水平分片,解决扩展 & 并发 |
| Replica | 每个 Partition 的多份拷贝,保证高可用 |
| Leader / Follower | 读写只走 Leader,Follower 异步同步 |
| Segment | Partition 再按文件切分,便于检索与清理 |
| Consumer Group | 一组消费者并行消费,Partition 只能被同组内一个实例占用 |
| Offset | 消息在 Partition 中的"下标",由 Consumer 自己维护(老版本在 ZK,现存在 __consumer_offsets Topic) |
五、常见使用场景
- 消息传递:异步、解耦、削峰,比 RabbitMQ 吞吐量更高
- 网站活动追踪:点击流实时上报 → 推荐系统
- 日志聚合:Logstash / Filebeat → Kafka → ELK
- 运营指标监控:CPU、内存、贷款放款数据实时看板
- 流式 ETL:Kafka Connect + Kafka Streams → Hadoop / HBase / Elasticsearch
- 数据同步:Canal 伪装 MySQL Slave 订阅 Binlog → Kafka → 下游系统
六、十分钟快速安装(CentOS 示例)
-
前置
JDK 8+、ZooKeeper(单节点或集群) -
下载
kafka_2.13-3.2.0.tgz(2.13 是 Scala 版本,3.2.0 才是真正 Kafka 版本) -
启动
bash# 启动自带 ZK(仅测试) bin/zookeeper-server-start.sh -daemon config/zookeeper.properties # 启动 Kafka bin/kafka-server-start.sh -daemon config/server.properties -
常用脚本
kafka-topics.sh创建/查看 Topickafka-console-producer.sh命令行发送kafka-console-consumer.sh命令行消费kafka-consumer-groups.sh查看消费进度kafka-manager/kafka-eagle可视化管理
七、Java 原生 API 速览
1. Producer 关键点
properties
bootstrap.servers=broker1:9092,broker2:9092
acks=all # 高可靠
retries=3
batch.size=16384
linger.ms=52. Consumer 关键点
properties
group.id=your-group
enable.auto.commit=true
auto.offset.reset=earliest
max.poll.records=5003. 代码片段
java
// 生产者
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
producer.send(new ProducerRecord<>("topicA", key, value));
// 消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("topicA"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
records.forEach(r -> System.out.printf("offset=%d, value=%s%n", r.offset(), r.value()));
}八、Spring 生态集成
1. Spring for Apache Kafka
- 依赖:spring-kafka
- Template:KafkaTemplate<K,V> 一行发送
- Listener :
@KafkaListener注解消费 - 配置 :
application.yml统一写生产者和消费者属性
2. Spring Boot 示例
yaml
spring:
kafka:
bootstrap-servers: 192.168.8.147:9092
producer:
retries: 1
batch-size: 16384
consumer:
group-id: boot-group
auto-offset-reset: earliest九、Kafka vs RabbitMQ:一张图看懂选型
| 维度 | Kafka | RabbitMQ |
|---|---|---|
| 定位 | 流处理平台 | 消息代理 |
| 吞吐量 | 百万级 TPS | 万级 TPS |
| 延迟 | 毫秒级 | 亚毫秒级 |
| 消息顺序 | Partition 级顺序 | 队列级顺序 |
| 路由灵活性 | Topic/Partition 简单路由 | Exchange + Binding 丰富 |
| 消息留存 | 可配置持久化,支持重放 | 消费完即删除 |
| 高级特性 | 流处理、Connect、MirrorMaker | 延迟队列、优先级、死信队列 |
| 适用场景 | 大数据、日志、流计算 | 业务解耦、事务、复杂路由 |
一句话总结:
高吞吐 + 流处理 选 Kafka;复杂路由 + 低延迟 + 高级 MQ 特性 选 RabbitMQ。
十、学习路线 & 资料
- 官方文档 :
http://kafka.apache.org/documentation
https://kafka.apachecn.org (中文翻译) - 书籍:《Kafka 权威指南》《深入理解 Kafka》
- 可视化:Kafka Manager、Kafka Eagle
- 实战 :
- 用 Canal + Kafka 同步 MySQL → Elasticsearch
- Kafka Streams 实时统计 UV
- 搭建 3 Broker + 3 ZooKeeper 伪分布式集群
十一、启示
Kafka 的成功告诉我们:
"技术不是拍脑袋出来的,是被业务痛点逼出来的。"
当你面对海量数据、高并发、实时计算需求时,Kafka 大概率能救你于水火;但如果你只是想解耦下单和库存,RabbitMQ 可能更简单直接。希望这篇总结能让你在选型、面试、实战中都游刃有余。