
前言

随着国产化信创的推进,cloudera产品逐渐被国产大数据平台替换,从一个运维角度来说其实是不太愿意看到这种情况,虽说底层都是hadoop那一套,但是各个厂商集成后的产品还是有很大差别的,或多或少都加入了自研产品。
作为使用方角度,通过了解底层hadoop集群搭建的过程还是有很大程度上能够更快的适应各个厂商的集群的。
下面分享一下自己的搭建过程,因为是完全搭建好才分享的,所以步骤可能会有漏掉,实际步骤会有些许出入.
下面各个组件版本是经过大量编译、部署并验证基础场景SQL 操作没有问题后才最终确认其兼容版本,除了sqoop抽取关系型数据库到hbase有点问题,其他操作均未发现问题.
最后希望能帮助到有想集成hadoop且会免费开源产品的那些人吧,hadoop集成的产品真没必要五花八门! 下面步骤内容仅限测试练习使用!

版本介绍

系统版本: centos7
组件版本:
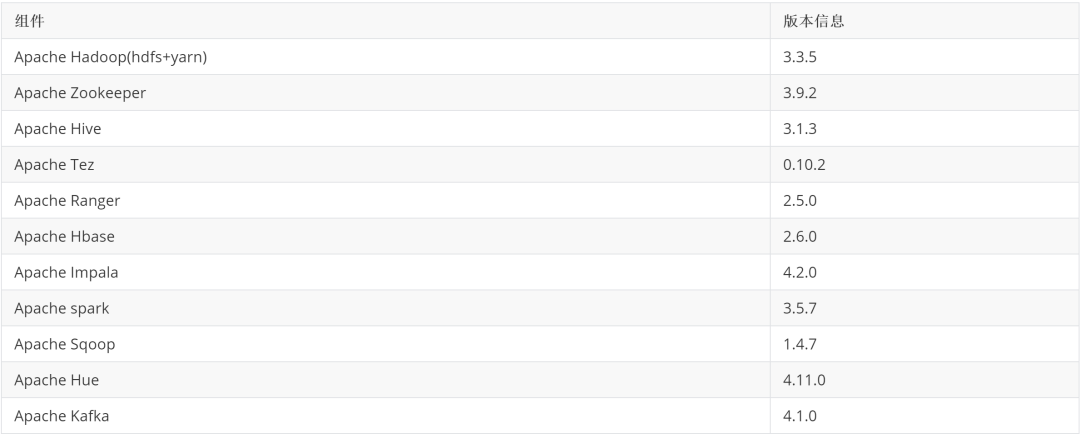
 kafka4.x 版本可以像flink一样独立部署hadoop集群外.因为它不再依赖zk。下面给出集成好的基础功能截图后续会逐个分享各个组件部署过程。
kafka4.x 版本可以像flink一样独立部署hadoop集群外.因为它不再依赖zk。下面给出集成好的基础功能截图后续会逐个分享各个组件部署过程。

机器列表

192.168.242.230 apache230.hadoop.com
192.168.242.231 apache231.hadoop.com
192.168.242.232 apache232.hadoop.com

功能实现

zookeeper:

hadoop:
hive:
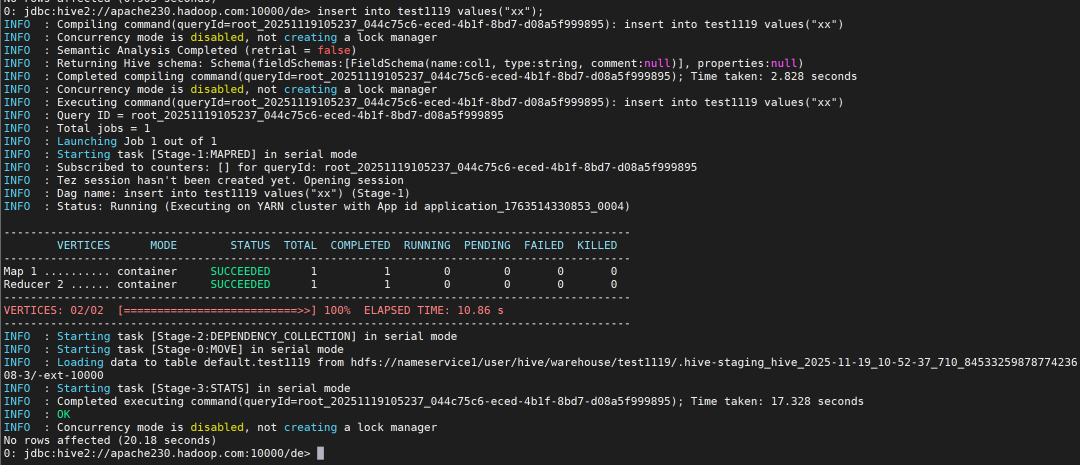
hbase:
impala:
ranger :
hue:
接下来介绍各个组件部署过程-此次文章主要为zookeeper
zookeeper
1.1 分发并解压到指定路径
makefile
分发至其他节点: ansible hadoopsrcclustero -m copy -a "src=/opt/softs/apache-zookeeper-3.9.2-bin.tar.gz dest=/opt/softs/"解压到指定路径: ansible hadoopsrccluster -m shell -a "tar -xf /opt/softs/apache-zookeeper-3.9.2-bin.tar.gz -C /opt/apache_v00/"修改名称: ansible hadoopsrccluster -m shell -a "mv /opt/apache_v00/apache-zookeeper-3.9.2-bin /opt/apache_v00/apache-zookeeper-3.9.2"1.2 配置文件设置
nginx
#创建数据目录:ansible hadoopsrccluster -m shell -a "mkdir -p /opt/apache_v00/apache-zookeeper-3.9.2/data/zookeeper"#复制配置文件模板ansible hadoopsrccluster -m shell -a "cd /opt/apache_v00/apache-zookeeper-3.9.2/conf/ && cp zoo_sample.cfg zoo.cfg"配置好后的zoo.cfg配置内容为:
ini
tickTime=2000initLimit=10syncLimit=5dataDir=/opt/apache_v00/apache-zookeeper-3.9.2/data/zookeeperclientPort=2181autopurge.purgeInterval=1server.1=192.168.242.230:2888:3888server.2=192.168.242.231:2888:3888server.3=192.168.242.232:2888:3888进行分发
nginx
ansible hadoopsrcclustero -m copy -a "src=/opt/apache_v00/apache-zookeeper-3.9.2/conf/zoo.cfg dest=/opt/apache_v00/apache-zookeeper-3.9.2/conf"1.3 Myid文件设置
bash
#apache23[0-2].hadoop.com分别执行:echo '1' > /opt/apache_v00/apache-zookeeper-3.9.2/data/zookeeper/myidecho '2' > /opt/apache_v00/apache-zookeeper-3.9.2/data/zookeeper/myidecho '3' > /opt/apache_v00/apache-zookeeper-3.9.2/data/zookeeper/myid1.4 配置环境变量
三台节点均执行:
bash
cat > /etc/profile.d/apache_v00.sh <<'EOF'export ZOOKEEPER_HOME=/opt/apache_v00/apache-zookeeper-3.9.2export PATH=$PATH:$ZOOKEEPER_HOME/binEOFsource /etc/profile.d/apache_v00.sh1.5 启动zookeeper
nginx
ansible hadoopsrccluster -m shell -a "zkServer.sh start"1.6 连接测试
apache
zkCli.sh -server 192.168.242.230:2181