VPT
- 核心思想:冻结backbone,在encoder的输入中
引入额外可学习的token,微调这些token和decoder部分,避免直接调整backbone。 - 两种方法:Deep和Shallow
只有第一层的prompt token是可以学习的参数

每一层 transformer layer的prompt token都是可以学习的参数

VPT的应用
- VIT模型
- SWIN transformer,这个有点不同,没有cls token。
VPT on hierarchical Transformers. We extend VPT to Swin 52, which employs MSA within local shifted windows and merges patch embeddings at deeper layers. For simplicity and without loss of generality, we implement VPT in the most straightforward manner: the prompts are attended within the local windows, but are ignored during patch merging stages. The experiments are conducted on the ImageNet-21k supervised pre-trained Swin-Base. VPT continues to outperform other parameter-efficient fine-tuning methods (b, c) for all three subgroups of VTAB Tab. 2, though in this case Full yields the highest accuracy scores overall (at a heavy cost in total parameters).
VPT的探究
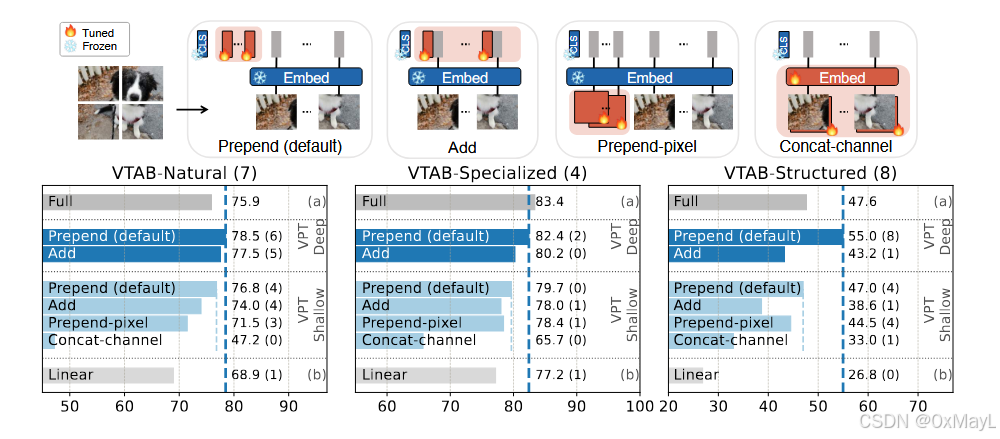
prompt的位置
- 结论:就是作为独立的输入最好
- 1:直接单独作为输入的一部分,与patch embedding分开
- 2:与patch embedding进行累加
- 3:在embedding,前加入prompt
- 4:在embeddingprompt作为一个通道加入
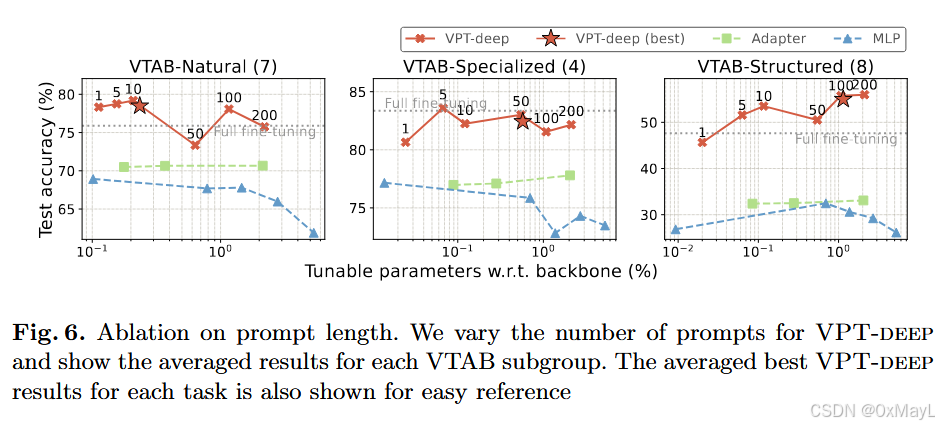
prompt length
- 可以看到10~100这个区间 最合适。