本地服务器端部署基于大模型的通用OCR项目------dots.ocr
dots.ocr相关介绍
dots.ocr 是一个强大的多语言文档解析器 ,它在一个单一的视觉-语言模型中统一了布局检测和内容识别 ,同时保持良好的阅读顺序。尽管其基础是紧凑的1.7B参数LLM,但它实现了最先进的(SOTA)性能。
强大的性能: dots.ocr 在OmniDocBench上实现了文本、表格和阅读顺序的SOTA性能,同时在公式识别方面达到了与Doubao-1.5和gemini2.5-pro等更大模型相当的结果。
多语言支持 : dots.ocr 对低资源语言展示了强大的解析能力,在我们内部的多语言文档基准测试中,在布局检测和内容识别方面都取得了决定性的优势。
统一且简单的架构: 通过利用单一的视觉-语言模型,dots.ocr 提供了一个比依赖复杂多模型流水线的传统方法更简洁的架构。通过简单地改变输入提示即可在任务之间切换,证明VLM可以与传统的检测模型如DocLayout-YOLO相比达到有竞争力的检测结果。
高效且快速的性能: 基于紧凑的1.7B LLM构建,dots.ocr 比许多基于更大基础的高性能模型提供了更快的推理速度。
本地服务器端部署
项目先决条件:
该项目官方要求的pytroch为2.7、vllm为0.9.1 ,并且由于该项目依赖于flash-attn==2.8.0.post2,该包的编译安装依赖于cuda版本为12.8,所以,需要项目需要较新版本的英伟达显卡驱动与CUDA12.8(要求是12.8)
第一步:安装cuda12.8与CUDNN8.9.7
下载地址依次是:
python
https://developer.nvidia.com/cuda-12-8-0-download-archive?target_os=Linux&target_arch=x86_64&Distribution=Ubuntu&target_version=22.04&target_type=runfile_local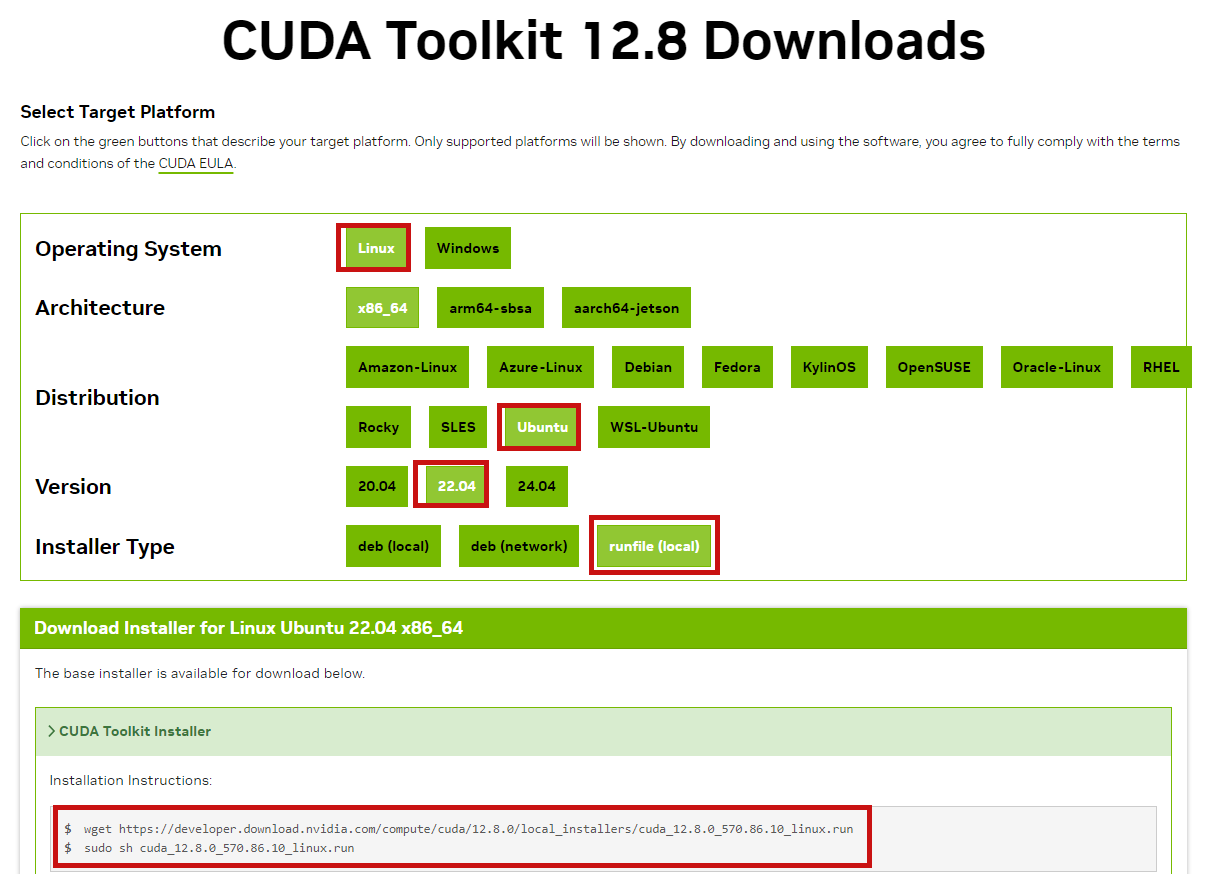
Ubutnu命令行运行如下指令:
下载cuda12.8
python
wget https://developer.download.nvidia.com/compute/cuda/12.8.0/local_installers/cuda_12.8.0_570.86.10_linux.run安装cuda12.8
python
# 赋予权限
chmod +x cuda_12.8.0_570.86.10_linux.run
# 执行安装
./cuda_12.8.0_570.86.10_linux.run修改~/.bashrc文件
python
vim ~/.bashrc将如下内容添加到文件中
python
export CUDA_HOME=/usr/local/cuda-12.8
export PATH=$CUDA_HOME/bin:$PATH
export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH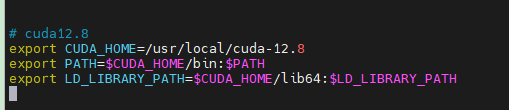
修改完后,执行如下指令以生效:
python
source ~/.bashrc确保nvcc可以被找到
python
which nvcc
nvcc -V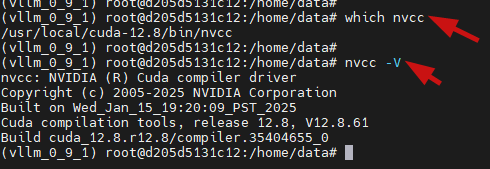
下载cudnn8.9.7
python
https://developer.nvidia.com/rdp/cudnn-archive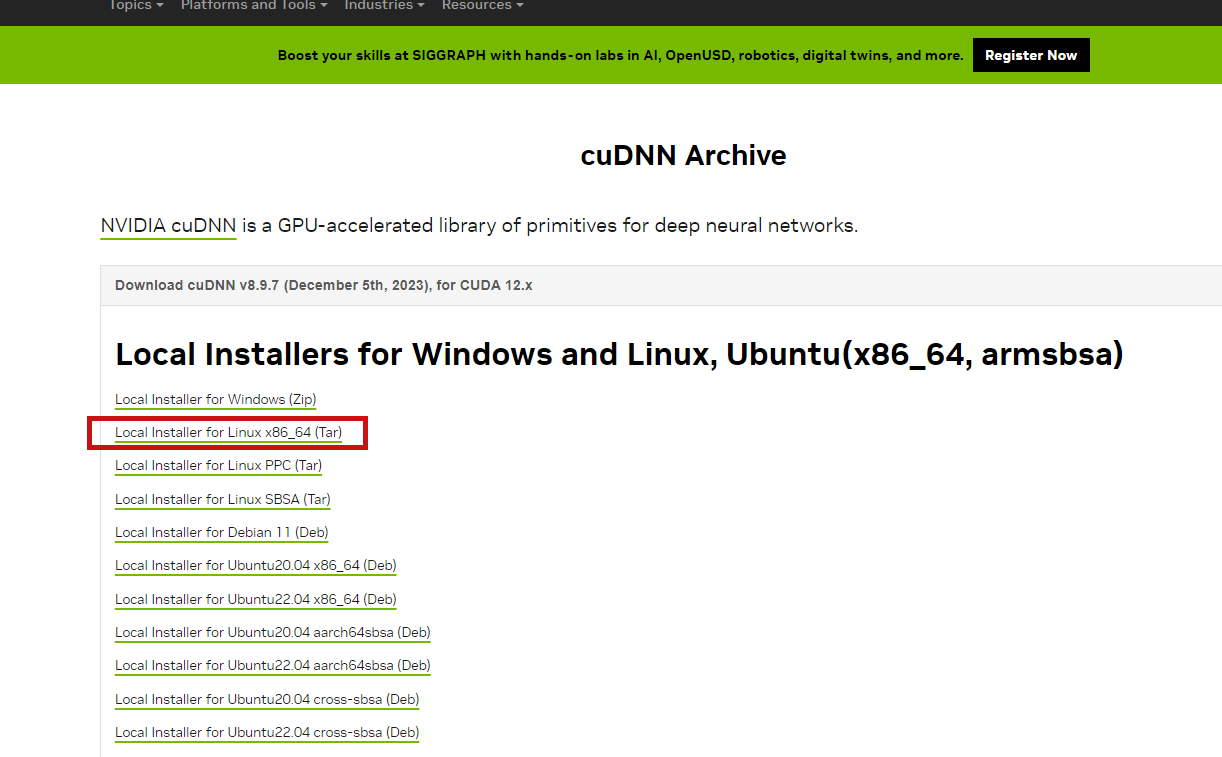
python
# 解压压缩包文件
tar -xvf cudnn-linux-x86_64-8.9.7.29_cuda12-archive.tar.xz拷贝文件并授权
python
cd cudnn-linux-x86_64-8.9.7.29_cuda12-archive
sudo cp include/cudnn*.h /usr/local/cuda-12.8/include/
sudo cp lib/libcudnn* /usr/local/cuda-12.8/lib64/
sudo chmod a+r /usr/local/cuda-12.8/include/cudnn*.h /usr/local/cuda-12.8/lib64/libcudnn*验证是否成功
python
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
第二步:创建项目所需的依赖环境
安装好Miniconda后,执行如下指令创建虚拟环境
python
# 创建
conda create -n vllm_0_9_1 python=3.12
# 激活
conda activate vllm_0_9_1下载项目代码
python
git clone https://github.com/rednote-hilab/dots.ocr.git安装依赖库
python
# 进入到项目目录内
cd dots.ocr
# 执行如下语句
pip install torch==2.7.0 torchvision==0.22.0 torchaudio==2.7.0 --index-url https://download.pytorch.org/whl/cu128 --default-timeout=100
pip install vllm==0.9.1 --default-timeout=100 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install -e . --default-timeout=100 -i https://pypi.tuna.tsinghua.edu.cn/simple模型下载
cd到此项目的同级目录下,创建目录用于存放模型
python
# 官方要求目录名称必须以DotsOCR
mkdir DotsOCR
python
# 进入到DotsOCR目录下,执行如下
modelscope download --model rednote-hilab/dots.ocr --local_dir ./第三步:启动项目
python
export hf_model_path=/home/googosoft/DotsOCR
export PYTHONPATH=$(dirname "$hf_model_path"):$PYTHONPATH
sed -i '/^from vllm\.entrypoints\.cli\.main import main$/a\
from DotsOCR import modeling_dots_ocr_vllm' `which vllm`
# 启动模型
CUDA_VISIBLE_DEVICES=0 vllm serve ${hf_model_path} \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.95 \
--chat-template-content-format string \
--served-model-name model \
--trust-remote-code运行上述指令可能会出现以下报错:
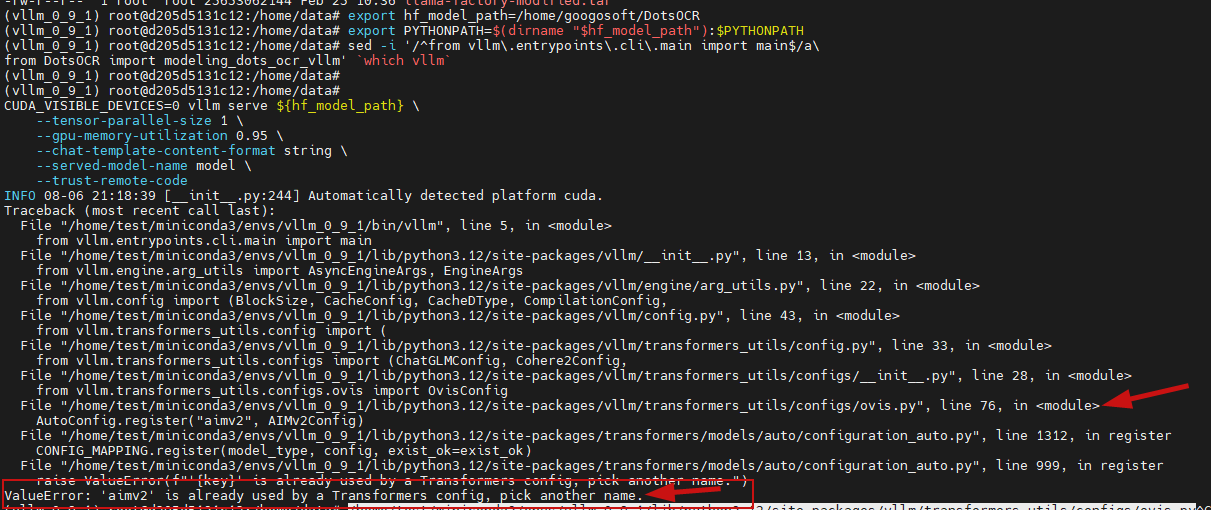
解决方案是修改对应的文件内容:
python
vim /home/test/miniconda3/envs/vllm_0_9_1/lib/python3.12/site-packages/vllm/transformers_utils/configs/ovis.py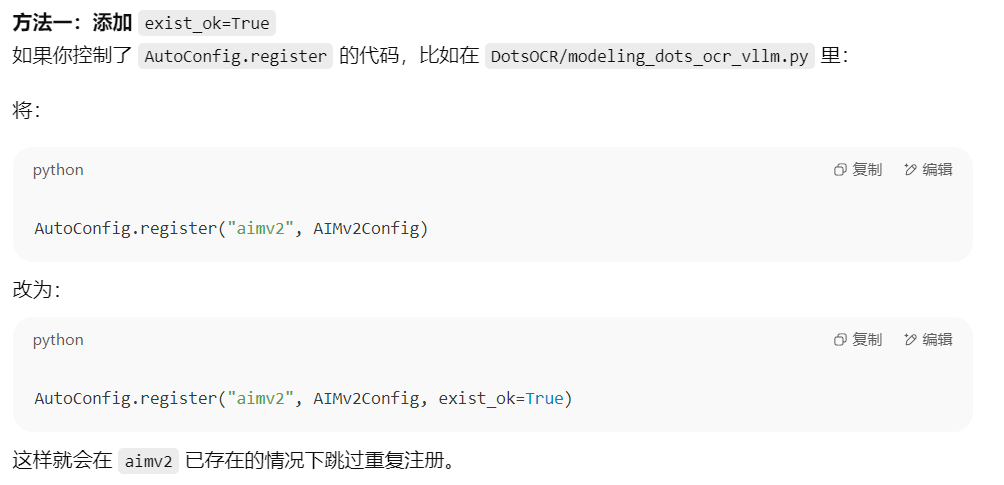
python
AutoConfig.register("aimv2", AIMv2Config, exist_ok=True)再次运行,便可启动项目