准备做一个AI大模型应用项目,一开始计划使用 Redis 进行会话记忆存储,真正到手才发现官方还没有提供 Redis 会话记忆的实现,网上也没有太多好的总结,所以准备自己做一篇博客,也算是对于自己学习的总结和分享。
为什么选择Redis存储消息历史
- 高性能:毫秒级读写,非常适合对话场景
- 数据结构丰富,适合建模对话流程
- 跨服务共享对话上下文(分布式好)
- 实时性与易扩展性好
- 易于实现限流与过期策略
文章的大概结构
1.Spring AI 有关源码分析
2.具体实践:可以看完直接应用
接下来开始正文
Spring AI 有关源码分析
我们在使用大模型对话时,都是通过 ChatClient 对象实现的 如下:
scss
@Bean
// public ChatClient chatClient(DeepSeekChatModel chatModel) {
public ChatClient chatClient(OllamaChatModel chatModel,ChatMemory chatMemory) {
return ChatClient.builder(chatModel)
.defaultSystem(JANE_DESC)//系统描述
.defaultAdvisors(
// chat请求的拦截器增强器
new SimpleLoggerAdvisor(),//DEBUG日志记录器
MessageChatMemoryAdvisor.builder(chatMemory).build()
)
.build();
}
AI写代码java
运行为了实现会话记忆的存储,我们需要加上 MessageChatMemoryAdvisor , Advisor 类似于一个拦截器,可以在请求前后介入,实现具体的功能,比如说 日志记录与权限校验,我们在这里实现的就是会话记忆的存储功能
MessageChatMemoryAdvisor
基本参数如下:
arduino
public final class MessageChatMemoryAdvisor implements BaseChatMemoryAdvisor {
private final ChatMemory chatMemory;
private final String defaultConversationId;
private final int order;
private final Scheduler scheduler;
***
}
AI写代码java
运行这是它的主要方法
kotlin
public Flux<ChatClientResponse> adviseStream(ChatClientRequest chatClientRequest, StreamAdvisorChain streamAdvisorChain) {
Scheduler scheduler = this.getScheduler();
Mono var10000 = Mono.just(chatClientRequest).publishOn(scheduler).map((request) -> {
return this.before(request, streamAdvisorChain);
});
Objects.requireNonNull(streamAdvisorChain);
return var10000.flatMapMany(streamAdvisorChain::nextStream).transform((flux) -> {
return (new ChatClientMessageAggregator()).aggregateChatClientResponse(flux, (response) -> {
this.after(response, streamAdvisorChain);
});
});
}
AI写代码java
运行可以看出这段代码主要的功能就是一个请求进来后,对请求分别进行前置 before 方法与后置 after 方法的调用
这是 before 的具体方法 在文章最后 我们再总结 before与 after 的作用,梳理流程
ini
public ChatClientRequest before(ChatClientRequest chatClientRequest, AdvisorChain advisorChain) {
String conversationId = this.getConversationId(chatClientRequest.context(), this.defaultConversationId);
List<Message> memoryMessages = this.chatMemory.get(conversationId);
List<Message> processedMessages = new ArrayList(memoryMessages);
processedMessages.addAll(chatClientRequest.prompt().getInstructions());
ChatClientRequest processedChatClientRequest = chatClientRequest.mutate().prompt(chatClientRequest.prompt().mutate().messages(processedMessages).build()).build();
UserMessage userMessage = processedChatClientRequest.prompt().getUserMessage();
this.chatMemory.add(conversationId, userMessage);
return processedChatClientRequest;
}
AI写代码java
运行功能如下:
1.从上下文中获取 ConversationId
2.调用 chatmemory 的get方法
3.调用 chatmemory 的add 方法
我们直接进入Chatmemory 分析有关的具体实现
ChatMemory
Chatmemory是一个接口,具体如下
arduino
public interface ChatMemory {
String DEFAULT_CONVERSATION_ID = "default";
String CONVERSATION_ID = "chat_memory_conversation_id";
default void add(String conversationId, Message message) {
Assert.hasText(conversationId, "conversationId cannot be null or empty");
Assert.notNull(message, "message cannot be null");
this.add(conversationId, List.of(message));
}
void add(String conversationId, List<Message> messages);
List<Message> get(String conversationId);
void clear(String conversationId);
}
AI写代码java
运行他只有一个实现类 MessageWindowChatMemory
具体方法如下
typescript
private MessageWindowChatMemory(ChatMemoryRepository chatMemoryRepository, int maxMessages) {
Assert.notNull(chatMemoryRepository, "chatMemoryRepository cannot be null");
Assert.isTrue(maxMessages > 0, "maxMessages must be greater than 0");
this.chatMemoryRepository = chatMemoryRepository;
this.maxMessages = maxMessages;
}
public void add(String conversationId, List<Message> messages) {
Assert.hasText(conversationId, "conversationId cannot be null or empty");
Assert.notNull(messages, "messages cannot be null");
Assert.noNullElements(messages, "messages cannot contain null elements");
List<Message> memoryMessages = this.chatMemoryRepository.findByConversationId(conversationId);
List<Message> processedMessages = this.process(memoryMessages, messages);
this.chatMemoryRepository.saveAll(conversationId, processedMessages);
}
public List<Message> get(String conversationId) {
Assert.hasText(conversationId, "conversationId cannot be null or empty");
return this.chatMemoryRepository.findByConversationId(conversationId);
}
public void clear(String conversationId) {
Assert.hasText(conversationId, "conversationId cannot be null or empty");
this.chatMemoryRepository.deleteByConversationId(conversationId);
}
AI写代码java
运行可以看出除了 process 方法之外,都是 chatMemoryRepository实现的具体方法
process源码如下,主要作用就是传入历史会话与最新用户会话,返回 需要传入给 AI 的上下文信息 ,包括最新的会话加上历史会话,当然在方法内部还有对信息的类型(如果有新System消息就删除原来的System,使用最新的)与数量的筛选(默认为20条)
ini
private List<Message> process(List<Message> memoryMessages, List<Message> newMessages) {
List<Message> processedMessages = new ArrayList();
Set<Message> memoryMessagesSet = new HashSet(memoryMessages);
Stream var10000 = newMessages.stream();
Objects.requireNonNull(SystemMessage.class);
boolean hasNewSystemMessage = var10000.filter(SystemMessage.class::isInstance).anyMatch((messagex) -> {
return !memoryMessagesSet.contains(messagex);
});
var10000 = memoryMessages.stream().filter((messagex) -> {
return !hasNewSystemMessage || !(messagex instanceof SystemMessage);
});
Objects.requireNonNull(processedMessages);
var10000.forEach(processedMessages::add);
processedMessages.addAll(newMessages);
if (processedMessages.size() <= this.maxMessages) {
return processedMessages;
} else {
int messagesToRemove = processedMessages.size() - this.maxMessages;
List<Message> trimmedMessages = new ArrayList();
int removed = 0;
Iterator var9 = processedMessages.iterator();
while(true) {
while(var9.hasNext()) {
Message message = (Message)var9.next();
if (!(message instanceof SystemMessage) && removed < messagesToRemove) {
++removed;
} else {
trimmedMessages.add(message);
}
}
return trimmedMessages;
}
}
}
AI写代码java
运行ChatMemoryRepository
这个接口有以下四个主要的方法,作用我已经在代码中标注
arduino
public interface ChatMemoryRepository {
List<String> findConversationIds();//查询所有的会话id
List<Message> findByConversationId(String conversationId);//查询一个会话的所有历史信息
void saveAll(String conversationId, List<Message> messages);//保存信息集合
void deleteByConversationId(String conversationId);//删除一个会话的所有信息
}
AI写代码java
运行官方默认有以下两种实现

这两种方法分别是利用
InMemoryChatMemoryRepository
基于Map<String, List> chatMemoryStore = new ConcurrentHashMap() ;实现内存上的消息存储
JdbcChatMemoryRepository
private final JdbcTemplate jdbcTemplate; 通过 JDBC 实现消息的存储,默认支持以下四种实现(都是关系型数据库)

所以我们只需要实现接口 ChatMemoryRepository 并实现具体的方法即可
具体实践
接上文内容我们创建一个仓库类实现 ChatMemoryRepository 接口
还有一个关键点就是我们一定要进行 Redis 的序列化配置, 我们要对 Message 对象进行操作和存储,不进行序列化就会导致存储二进制数据,难以理解与应用
RedisConfig 序列化配置
arduino
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory, ObjectMapper objectMapper) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(connectionFactory);//设置 Redis 连接工厂(负责创建与 Redis 的连接
// 键用字符串序列化器
template.setKeySerializer(new StringRedisSerializer());
template.setHashKeySerializer(new StringRedisSerializer());
// 值用 GenericJackson2JsonRedisSerializer(自动处理类型)
GenericJackson2JsonRedisSerializer serializer = new GenericJackson2JsonRedisSerializer(objectMapper);
template.setValueSerializer(serializer);
template.setHashValueSerializer(serializer);
template.afterPropertiesSet();
return template;
}
}
AI写代码java
运行键(Key)序列化器 用 StringRedisSerializer,保证 Redis key 是字符串,方便查看和操作。 值(Value)序列化器 使用 GenericJackson2JsonRedisSerializer,结合了 Jackson 的 ObjectMapper,可以自动将 Java 对象序列化为 JSON 存入 Redis,读取时自动反序列化回对应类型。
ChatMemoryRepository 实现类的撰写
首先确立 Redis 存储会话记忆的结构
具体结构
使用 Redis 中的 Set 存储所有活跃的会话 ID (set 去重复)
使用 List 存储每个会话的消息队列,实现多轮对话的持久化和快速访问。(有序)
还有需要注意的就是 Message 是一个接口,不同的实现子类构造方法也不同,需要注意
实现类
typescript
//自定义chatmemory
public class RedisChatMemoryRepository implements ChatMemoryRepository {
private final RedisChatMemoryRepositoryDialect dialect;
public RedisChatMemoryRepository(RedisChatMemoryRepositoryDialect dialect) {
this.dialect = dialect;
}
/**
* 查询所有的对话ID列表。
*
* @return 返回所有存在的对话ID集合。
*/
@Override
public List<String> findConversationIds() {
return dialect.findConversationIds();
}
/**
* 根据对话ID查询该对话下的所有消息。
*
* @param conversationId 对话的唯一标识ID。
* @return 返回该对话对应的消息列表。
*/
@Override
public List<Message> findByConversationId(String conversationId) {
return dialect.findByConversationId(conversationId);
}
/**
* 保存指定对话ID对应的消息列表,支持批量保存。
*
* @param conversationId 对话的唯一标识ID。
* @param messages 需要保存的消息列表。
*/
@Override
public void saveAll(String conversationId, List<Message> messages) {
dialect.saveAll(conversationId, messages);
}
/**
* 删除指定对话ID对应的所有消息。
*
* @param conversationId 需要删除的对话ID。
*/
@Override
public void deleteByConversationId(String conversationId) {
dialect.deleteByConversationId(conversationId);
}
}
AI写代码java
运行具体的实现类
typescript
//redis执行语句方法
@Slf4j
@Component
public class RedisChatMemoryRepositoryDialect {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@Autowired
private ObjectMapper objectMapper;
// Redis里存所有活跃会话ID的Set key,方便查找所有会话
private static final String JANE_CONVERSATION_KEY = "chat:conversation_ids";
// 每个会话消息列表的key前缀
private static final String JANE_MESSAGE_LIST_PREFIX = "chat:messages:";
/**
* 获取所有活跃会话ID
* Redis数据结构:Set(无序且唯一)
* 用于快速获取当前所有存在的会话ID
*/
public List<String> findConversationIds() {
Set<Object> members = redisTemplate.opsForSet().members(JANE_CONVERSATION_KEY);
return Optional.ofNullable(members)
.filter(m -> !m.isEmpty())
.map(m -> m.stream().map(Object::toString).collect(Collectors.toList()))
.orElse(Collections.emptyList());
}
/**
* 根据会话ID获取该会话的所有消息列表(多轮对话历史)反序列化
* Redis数据结构:List(有序)
* 按消息顺序返回,方便构造对话上下文
*/
public List<Message> findByConversationId(String conversationId) {
String key = JANE_MESSAGE_LIST_PREFIX + conversationId;
Long size = redisTemplate.opsForList().size(key);
if(size == null || size == 0L){
return Collections.emptyList();
}
List<Object> range = redisTemplate.opsForList().range(key, size-21, -1);
List<Message> messages = new ArrayList<>();
for(Object o:range){
String json = JSON.toJSONString(o);
try { // 从 JsonParser 中读取 JSON 数据,并将其反序列化为 JsonNode(树形结构)对象
JsonNode jsonNode = objectMapper.readTree(json);
messages.add(getMessage(jsonNode));
} catch (JsonProcessingException e) {
throw new RuntimeException("Error deserializing message", e);
}
}
return messages;
}
/**
* 将一个 JsonNode 转换成对应的 Message 子类实例。
* 根据 messageType 字段决定返回哪种 Message 类型,并提取 text 和 metadata 字段。
* 额外会在 metadata 中添加当前时间戳。
*
* @param jsonNode 传入的 JSON 树节点,包含 messageType、text、metadata 等字段
* @return 对应类型的 Message 对象实例(AssistantMessage、UserMessage、SystemMessage 或 ToolResponseMessage)
*/
private Message getMessage(JsonNode jsonNode) {
// 从 jsonNode 中获取 messageType 字段的文本内容,默认为 USER 类型
String type = Optional.ofNullable(jsonNode)
.map(node -> node.get("messageType")) // 取 messageType 字段节点
.map(JsonNode::asText) // 转为字符串
.orElse(MessageType.USER.getValue()); // 如果没有该字段,默认是 USER 类型
// 根据字符串转换为枚举类型 MessageType
MessageType messageType = MessageType.valueOf(type.toUpperCase());
// 从 jsonNode 中获取 text 字段的内容
String textContent = Optional.ofNullable(jsonNode)
.map(node -> node.get("text")) // 取 text 字段节点
.map(JsonNode::asText) // 转为字符串
// 如果 text 字段不存在,根据消息类型返回默认值:
// SYSTEM 和 USER 类型默认返回空字符串 "",其他类型返回 null
.orElseGet(() ->
(messageType == MessageType.SYSTEM || messageType == MessageType.USER)
? ""
: null);
// 从 jsonNode 中获取 metadata 字段并转换为 Map<String, Object>
Map<String, Object> metadata = Optional.ofNullable(jsonNode)
.map(node -> node.get("metadata")) // 取 metadata 节点
.map(node -> objectMapper.convertValue( // 用 Jackson ObjectMapper 转换成 Map
node, new TypeReference<Map<String, Object>>() {}))
.orElse(new HashMap<>()); // 如果没有 metadata 字段,返回空 Map
// 在 metadata 中加入当前时间戳,key 是 "timestamp",值是当前 ISO 格式时间字符串
if(!metadata.containsKey("timestamp")){
metadata.put("timestamp", Instant.now().toString());
}
// 根据不同的消息类型,构造对应的 Message 子类实例并返回
return switch (messageType) {
case ASSISTANT -> new AssistantMessage(textContent, metadata); // 助手消息
case USER -> UserMessage.builder().text(textContent).metadata(metadata).build(); // 用户消息
case SYSTEM -> SystemMessage.builder().text(textContent).metadata(metadata).build(); // 系统消息
case TOOL -> new ToolResponseMessage(List.of(), metadata); // 工具调用消息
};
}
/**
* 保存一批消息到指定会话中,追加到消息列表末尾
* Redis数据结构:List(右侧追加)
* 并且保证会话ID存在于会话ID集合中
*/
public void saveAll(String conversationId, List<Message> messages) {
if(CollectionUtils.isEmpty(messages)) return;
String key=JANE_MESSAGE_LIST_PREFIX+conversationId;
deleteByConversationId(conversationId);
redisTemplate.opsForSet().add(JANE_CONVERSATION_KEY, conversationId);
List<Message> filteredMessages = messages.stream()
.filter(Objects::nonNull)
.filter(m -> m.getText() != null && m.getMessageType() != null).toList();
List<Message> finalMessages = new ArrayList<>();
for(Message message:filteredMessages){
String json = JSON.toJSONString(message);
try {
JsonNode jsonNode = objectMapper.readTree(json);
finalMessages.add(getMessageWithTime(jsonNode,message.getMessageType(),message.getText()));
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}
redisTemplate.opsForList().rightPushAll(key, finalMessages.toArray());
int maxHistorySize = 100;
redisTemplate.opsForList().trim(key, -maxHistorySize, -1);
}
/**
* 在saveall操作时统一添加系统时间
* @param jsonNode
* @param messageType
* @param textContent
* @return
*/
private Message getMessageWithTime(JsonNode jsonNode,MessageType messageType,String textContent){
// 从 jsonNode 中获取 metadata 字段并转换为 Map<String, Object>
Map<String, Object> metadata = Optional.ofNullable(jsonNode)
.map(node -> node.get("metadata"))
.map(node -> objectMapper.convertValue(
node, new TypeReference<Map<String, Object>>() {}))
.orElse(new HashMap<>());
if(!metadata.containsKey("timestamp")){
metadata.put("timestamp", Instant.now().toString());
}
// 根据不同的消息类型,构造对应的 Message 子类实例并返回
return switch (messageType) {
case ASSISTANT -> new AssistantMessage(textContent, metadata); // 助手消息
case USER -> UserMessage.builder().text(textContent).metadata(metadata).build(); // 用户消息
case SYSTEM -> SystemMessage.builder().text(textContent).metadata(metadata).build(); // 系统消息
case TOOL -> new ToolResponseMessage(List.of(), metadata); // 工具调用消息
};
}
/**
* 删除指定会话的所有消息以及会话ID集合中的对应ID
* Redis数据结构:删除List + Set中元素
*/
public void deleteByConversationId(String conversationId) {
String key = JANE_MESSAGE_LIST_PREFIX + conversationId;
redisTemplate.delete(key);
redisTemplate.opsForSet().remove(JANE_CONVERSATION_KEY, conversationId);
}
}
最后就是在ChatClient所在配置类的配置
@Bean //参数在容器中自动获取,无需显式注入
public ChatMemoryRepository chatMemoryRepository(RedisChatMemoryRepositoryDialect dialect) {
return new RedisChatMemoryRepository(dialect);
}
@Bean
public ChatMemory chatMemory(ChatMemoryRepository chatMemoryRepository) {
return MessageWindowChatMemory.builder()
.chatMemoryRepository(chatMemoryRepository)
.maxMessages(20)
.build();
}
AI写代码java
运行这样就可以实现 Redis 的会话记忆存储
实际效果
Controller 配置如下
less
@RestController
@RequestMapping("/jane")
public class JaneController {
@Autowired
private ChatClient chatClient;
@RequestMapping(value="/chat",produces = "text/html;charset=utf-8")//浏览器会收到带 Content-Type: text/html;charset=utf-8 的响应,显示网页内容,不会乱码
public Flux<String> chat(@RequestParam("prompt") String prompt,
@RequestParam("chatId") String chatId){
// 该方法通过一系列链式调用来构建和发送用户提示,并获取响应内容
return chatClient.prompt() // 调用chatClient的prompt方法开始构建用户提示
.user(prompt) // 设置用户提示的内容为prompt
//你配置一次,多个 advisor 会"监听"自己关心的参数,然后各自执行自己的逻辑。
.advisors(a->a.param(ChatMemory.CONVERSATION_ID,chatId))//给请求的"增强器"传入一个参数
.stream() // 流式返回
.content(); // 从响应对象中提取内容并返回
}
}
AI写代码java
运行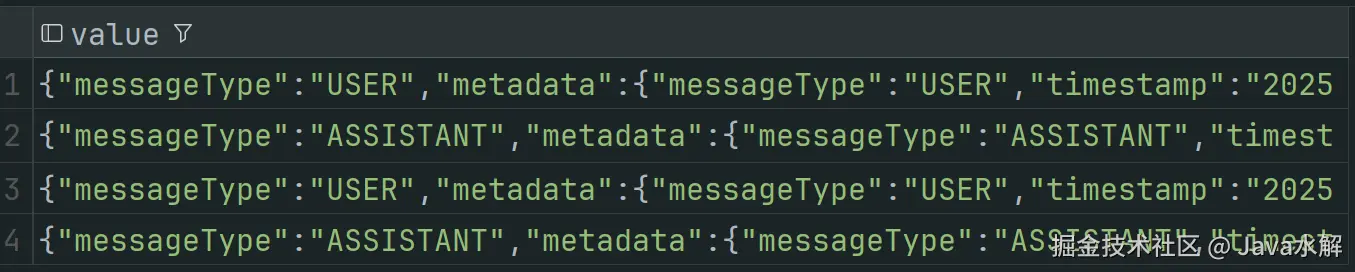
请求流程总结
浏览器将携带具体参数和语句的请求发送给服务器,MessageChatMemoryAdvisor 调用如下方法
kotlin
public Flux<ChatClientResponse> adviseStream(ChatClientRequest chatClientRequest, StreamAdvisorChain streamAdvisorChain) {
Scheduler scheduler = this.getScheduler();
Mono var10000 = Mono.just(chatClientRequest).publishOn(scheduler).map((request) -> {
return this.before(request, streamAdvisorChain);
});
Objects.requireNonNull(streamAdvisorChain);
return var10000.flatMapMany(streamAdvisorChain::nextStream).transform((flux) -> {
return (new ChatClientMessageAggregator()).aggregateChatClientResponse(flux, (response) -> {
this.after(response, streamAdvisorChain);
});
});
}
AI写代码java
运行实际上就是 before 与 after 方法,调用 before 方法时,从请求中获得用户传来的新的请求信息以及会话id,通过 chatmemory 对象调用 get 方法传入会话id 查询该会话下所有的历史会话信息,在get方法中实际上是通过this.chatMemoryRepository.findByConversationId(conversationId); 实现的,也就与我们刚刚编写的代码相接,之后把新消息接入到历史消息中组成一个新集合,将全新的消息集合作为参数创建一个新的请求,发向具体的AI模型路径
注意UserMessage userMessage = processedChatClientRequest.prompt().getUserMessage(); 这一行代码实际上是获得最新的用户消息也就是 UserMessage ,之后调用 add 方法,最终返回 新请求
ini
public ChatClientRequest before(ChatClientRequest chatClientRequest, AdvisorChain advisorChain) {
String conversationId = this.getConversationId(chatClientRequest.context(), this.defaultConversationId);
List<Message> memoryMessages = this.chatMemory.get(conversationId);
List<Message> processedMessages = new ArrayList(memoryMessages);
processedMessages.addAll(chatClientRequest.prompt().getInstructions());
ChatClientRequest processedChatClientRequest = chatClientRequest.mutate().prompt(chatClientRequest.prompt().mutate().messages(processedMessages).build()).build();
UserMessage userMessage = processedChatClientRequest.prompt().getUserMessage();
this.chatMemory.add(conversationId, userMessage);
return processedChatClientRequest;
}
AI写代码java
运行我们进入 add 方法中,先通过会话id获取所有的历史记录,之后通过 process 方法获取最新的指定数量的消息集合并保存,
saveAll方法会调用我们自己的实现,在这个方法具体实现中大家注意,每一次保存都需要删除 Redis 的重新插入,在默认内存方式存储时没有删除操作,官方 JDBC 实现时有删除操作,我们也需要,不然会导致消息重复添加
typescript
public void add(String conversationId, List<Message> messages) {
Assert.hasText(conversationId, "conversationId cannot be null or empty");
Assert.notNull(messages, "messages cannot be null");
Assert.noNullElements(messages, "messages cannot contain null elements");
List<Message> memoryMessages = this.chatMemoryRepository.findByConversationId(conversationId);
List<Message> processedMessages = this.process(memoryMessages, messages);
this.chatMemoryRepository.saveAll(conversationId, processedMessages);
}
AI写代码java
运行之后进入 after 方法中,先获取收到的 assistantMessages 对象,之后的操作也是调用上面的 add 方法,存储最新的大模型回复的消息
scss
public ChatClientResponse after(ChatClientResponse chatClientResponse, AdvisorChain advisorChain) {
List<Message> assistantMessages = new ArrayList();
if (chatClientResponse.chatResponse() != null) {
assistantMessages = chatClientResponse.chatResponse().getResults().stream().map((g) -> {
return g.getOutput();
}).toList();
}
this.chatMemory.add(this.getConversationId(chatClientResponse.context(), this.defaultConversationId), (List)assistantMessages);
return chatClientResponse;
}
AI写代码java
运行