今年,文本生成领域迎来了从自回归(Auto-Regressive)向扩散语言模型(Diffusion LM)的重要范式转变。然而,长序列训练的不稳定性一直是制约扩散模型发展的核心痛点。上下文窗口限制使得模型在处理复杂的数学推理、编程任务,尤其是需要深度推理的「慢思考」场景时,显得捉襟见肘。
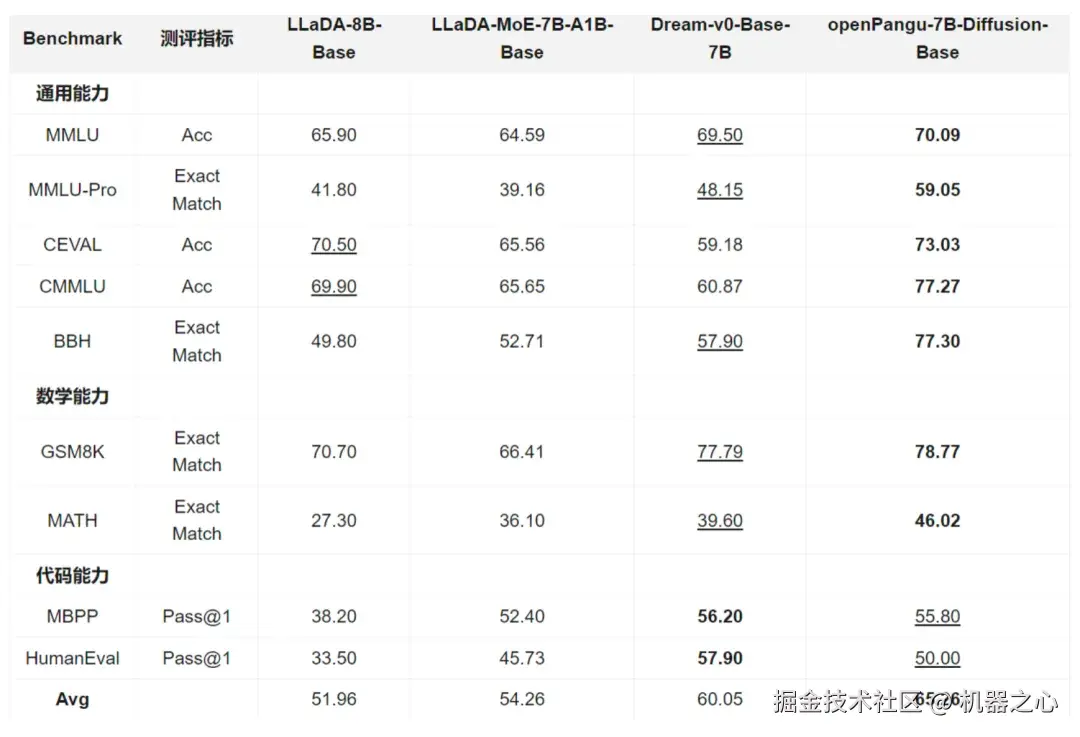
华为近日正式发布 openPangu-R-7B-Diffusion,基于openPangu-Embedded-7B 进行少量数据(800B tokens)续训练,成功将扩散语言模型的上下文长度扩展至 32K。
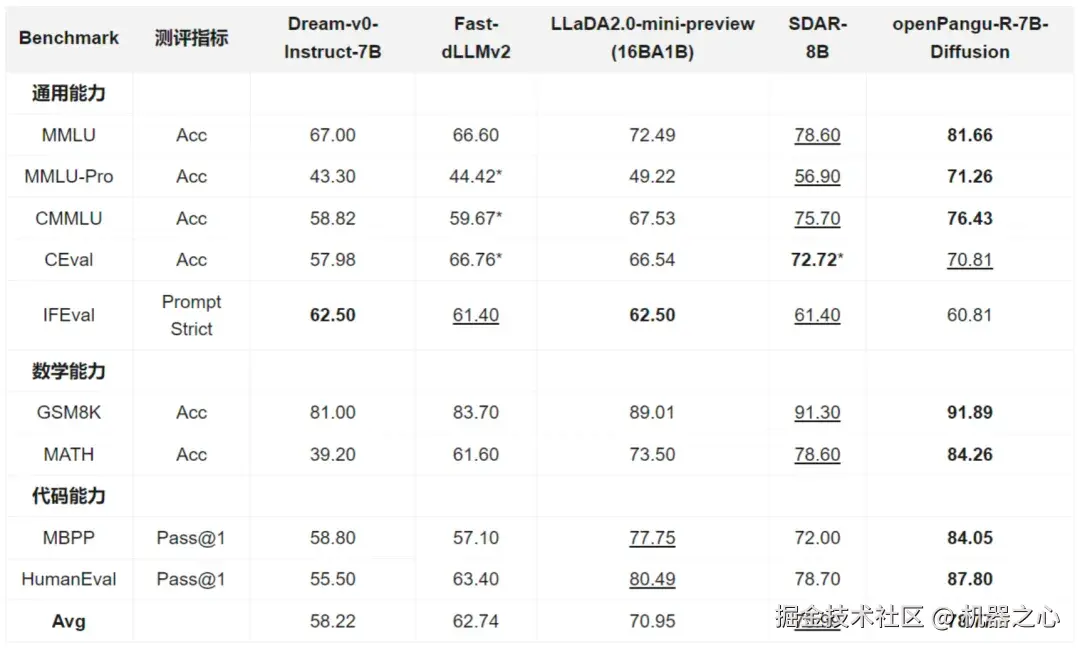
在「慢思考」能力的加持下,该模型在多个权威基准中创下了 7B 参数量级的全新 SOTA 纪录:
-
多学科知识(MMLU-Pro):超越 16B 参数量的 LLaDA 2.0-mini-preview 22%。
-
数学推理(MATH):得分 84.26,大幅领先同类模型。
-
代码生成(MBPP):得分 84.05,展现出卓越的逻辑泛化能力。
-
Base模型链接:ai.gitcode.com/ascend-trib...
-
慢思考模型链接:ai.gitcode.com/ascend-trib...
接下来,我们将深入解析这款模型背后的技术革新。
- 架构创新:
前文因果注意力掩码,自回归到 BlockDiffusion 的无缝迁移
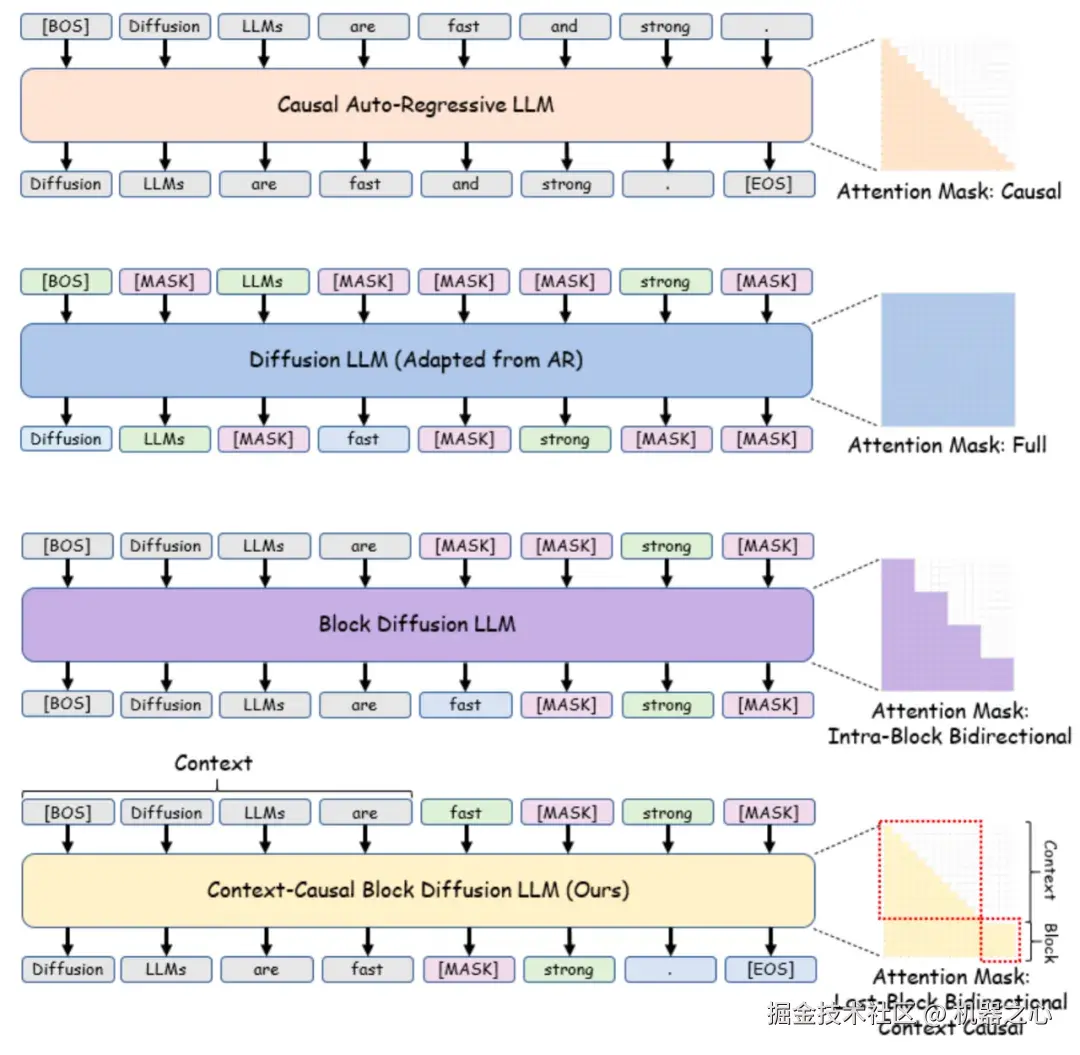
openPangu-R-7B-Diffusion 在注意力机制上并未沿用传统扩散模型(如 LLaDA)的全注意力(Full Attention),也未采用 SDAR 或 Fast-dLLMv2 的分块掩码(Block Attention),而是创新性地融合了自回归的前文因果注意力掩码(Causal Attention Mask)。
这一设计从根本上解决了架构适配难题:
-
消除适配壁垒:以往将自回归模型适配至扩散模型,往往需要 Attention Mask Annealing 或 Shift Operation 等复杂操作来弥合差异。而 openPangu-R-7B-Diffusion 通过保留前文的因果注意力特性,使得模型仅需从「预测 Next Token」转变为「预测 Next Block 中的 Mask Token」,极大地降低了适配成本。
-
兼容性最大化:该设计让模型能够自然继承自回归模型的预训练知识,为长窗口训练打下坚实基础。
- 训练与推理:双模式解码与效率倍增
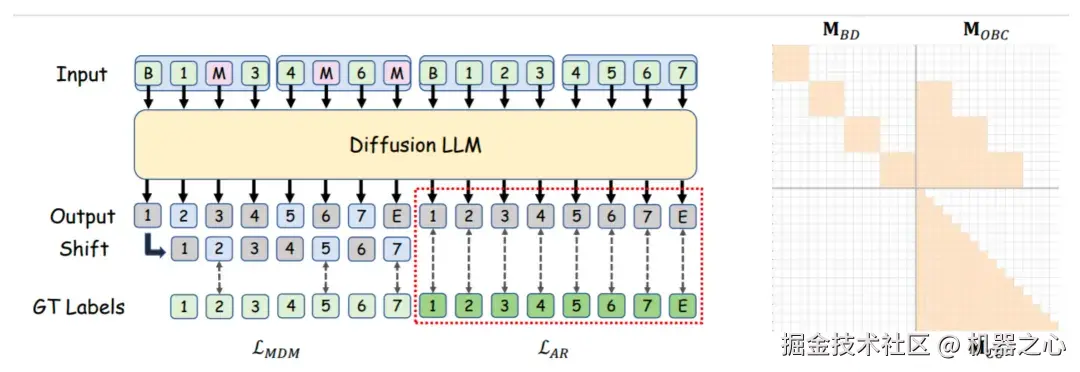
在训练策略上,openPangu-R-7B-Diffusion 延续了 BlockDiffusion 的思路(拼接带掩码的 Block 与无掩码的 Context),但进行了关键优化:
-
Context 利用率 100%:传统方法往往忽略无掩码 Context 部分的 Loss 计算,导致一半的数据被浪费。openPangu-R-7B-Diffusion 则将这部分数据用于标准的自回归 Next Token Prediction 训练。
-
双模式解码:这种训练方式赋予了模型「自回归 + 扩散」的双重解码能力。用户可以通过不同的采样设置,灵活权衡生成质量与速度。
-
极致性能:模型完整保留了变长推理与 KV-Cache 特性。在并行解码模式下,其速度最高可达自回归解码的 2.5 倍。
可视化实测:亲眼见证「慢思考」与扩散生成的融合
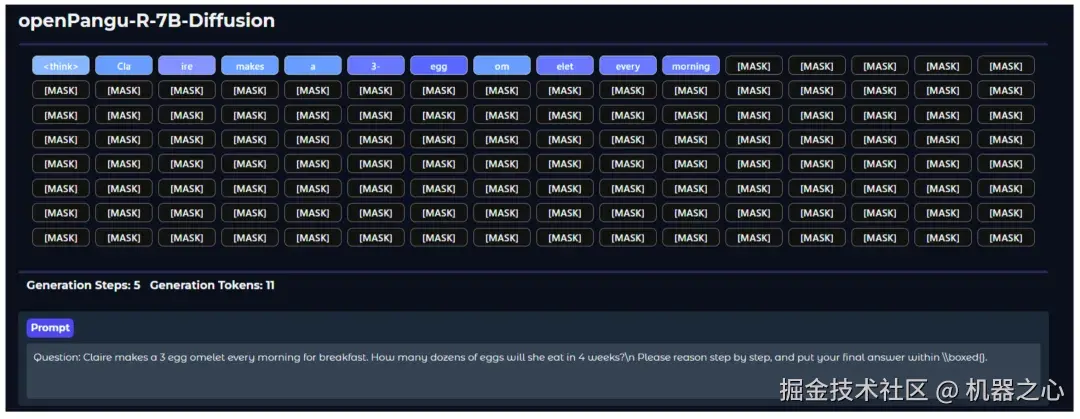
为了更直观地展示 openPangu-R-7B-Diffusion 的工作机制,我们对模型的推理过程进行了可视化处理。
在输入一道经典的数学逻辑推理题(Claire 的煎蛋问题)后,我们可以清晰地观察到扩散语言模型的独特生成方式:模型并非像传统自回归模型那样「逐词蹦出」,而是在 4 个生成步数(Generation Steps)内,并行地将多个 MASK 噪声逐步去噪还原为 、Claire、makes 等清晰的语义 Token。
图中首位的 Token 尤为关键,它标志着模型正在启动我们前文提到的 「慢思考」模式。这种结合了扩散并行生成与深度思维链(Chain-of-Thought)的能力,正是 openPangu-R-7B-Diffusion 能够在数学和编程基准上大幅超越同类模型的核心原因。
结语:开启扩散语言模型的新篇章
openPangu-R-7B-Diffusion 的发布,不仅仅是一个新模型的开源,更是对「扩散模型能否处理复杂长文本」这一难题的有力回应。凭借其创新的因果注意力掩码架构,它成功证明了扩散模型不仅可以「快」(并行解码),更可以「深」(32K 长文与慢思考)。
值得一提的是,openPangu-R-7B-Diffusion 的训练、推理及评测全流程均在昇腾 NPU 集群上完成,有力证明了国产算力在以前沿扩散语言模型领域的强劲实力。