共同一作:洪翔宇,清华大学电子系大四本科生,曾获清华大学蒋南翔奖学金等,曾在NeurIPS,EMNLP,NAACL等顶级会议上发表论文。姜澈,清华大学电子系博士三年级在读,主要研究方向为LLM Interpretebility,LLM Agent,曾在NeurIPS,ICML,EMNLP,NAACL等顶级会议上发表论文。
随着大型语言模型在各类任务中展现出卓越的生成与推理能力,如何将模型输出精确地追溯到其内部计算过程,已成为 AI 可解释性研究的重要方向。然而,现有方法往往计算代价高昂、难以揭示中间层的信息流动;同时,不同层面的归因(如 token、模型组件或表示子空间)通常依赖各自独立的特定方法,缺乏统一且高效的分析框架。
针对这一问题,来自清华、上海 AI Lab 的研究团队提出了全新的统一特征归因框架------DePass(Decomposed Forward Pass)。
该方法通过将前向传播中的每个隐藏状态分解为多个可加子状态,并在固定注意力权重与 MLP 激活的情况下对其逐层传播,实现了对 Transformer 内部信息流的无损分解与精确归因。借助 DePass,研究者能够在输入 token、注意力头、神经元乃至残差流子空间等多个层面上进行归因分析,为机制可解释性研究提供了统一而细粒度的新视角。

-
论文标题:DePass: Unified Feature Attributing by Simple Decomposed Forward Pass
-
论文链接: arxiv.org/pdf/2510.18...
问题分析:
现有归因方法的局限性
现有的归因方法大致可以分为以下几类:
-
基于噪声消融和激活修补的方法: 这些方法通过直接对模型的所有模块施加噪声或修补激活值来分析模型行为,但计算成本高昂,且难以洞察中间信息流。
-
基于梯度的归因方法: 这类方法在理论上面临挑战,难以提供细粒度的解释。
-
基于模型近似或抽象的方法: 虽然部分方法能够与人类认知对齐,但通常无法达到细粒度的组件级别(如神经元或注意力头),且非保守的近似可能会损害归因的可信度。
DePass:
一种全新的归因框架
DePass 通过将隐藏状态 X 分解为自定义的加性组件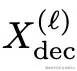 ,并在固定注意力分数与 MLP 激活值的条件下传播这些组件,实现了对模型行为的精确且细粒度的归因。
,并在固定注意力分数与 MLP 激活值的条件下传播这些组件,实现了对模型行为的精确且细粒度的归因。
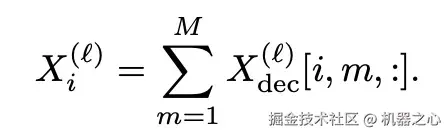
在具体实现上:
- 对于 Attention 模块: DePass 冻结注意力分数后,将各组件的隐藏状态经过线性变换,再根据注意力权重加权累加至对应组件,实现对信息流的精确分配。
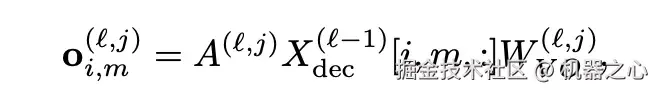
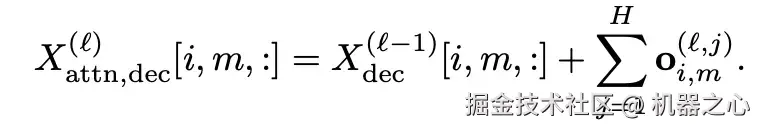
- 对于 MLP 模块: 则将其视作以神经元为单位的键值存储库(key-value store),通过不同组件对 key 激活值的贡献程度,将对应的 value 有效地划分至同一 token 的不同组件中。下式中的
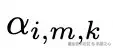 代表神经元 k 的输出分配到组件 m 上的权重。
代表神经元 k 的输出分配到组件 m 上的权重。
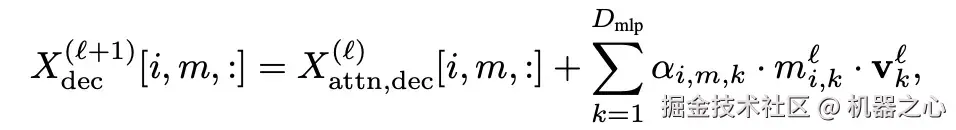
实验验证:
DePass 的有效性
DePass 提供了一个统一的归因框架,支持在输入 token、注意力头、神经元以及残差流子空间等多个层面进行一致归因,无需修改模型结构或依赖任务特定近似,并可自然衔接人类推理及稀疏字典学习(如 SAE)等方法。研究团队在 token 级、模型组件级和子空间级归因任务上验证了 DePass 的有效性:
Token-Level DePass------输出归因到输入:精准识别驱动预测的核心证据
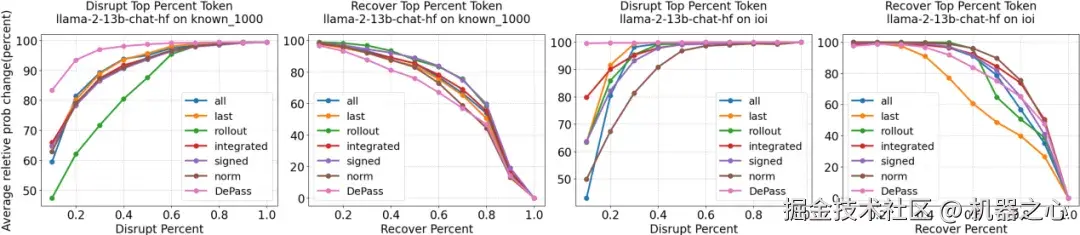
我们首先在输出到输入 token 的归因任务上验证了 DePass 的表现,目标是评估每个输入 token 对模型最终输出的实际贡献。
在「Disrupt-top」实验中,移除 DePass 判定最关键的 tokens 会导致模型输出概率急剧下降,表明其捕捉到了真正驱动预测的核心证据;而在「Recover-top」实验中,DePass 保留的极少量 tokens 依然能高度恢复模型判断。这表明 DePass 能够更忠实地刻画模型内部的信息流动与输入贡献关系,实现高可信度的 token 级归因分析。
Token-Level DePass------子空间归因到输入:追踪子空间信号的 token 来源
DePass 不仅能在 token 层面追踪预测依据,还能精准定位哪些输入 token 激活了模型中「特定方向/特定语义子空间」的信号(例如「truthfulness」方向),从而识别出影响模型判断的关键来源(如误导性信息),并显著提升模型的可控性与可解释性。
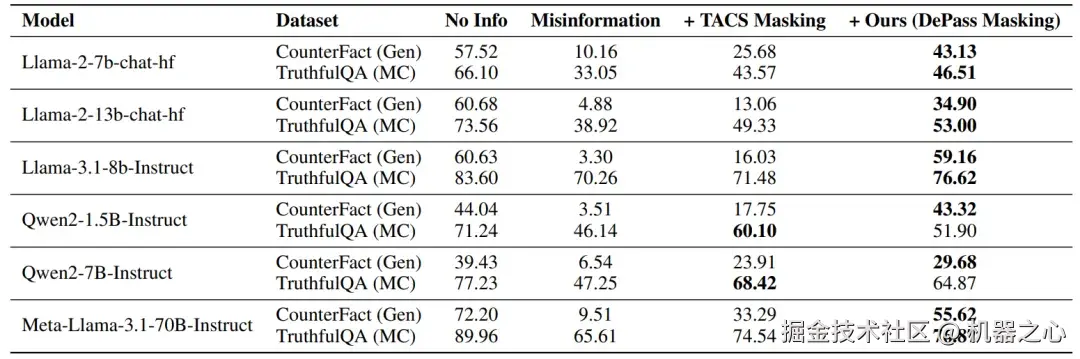
在事实性任务中,团队利用 DePass 将「虚假信息子空间」拆解后,进一步将其激活分配到每个输入 token。归因结果清晰揭示了哪些词触发了模型的错误方向。基于这些 token 进行定向遮罩后,模型在 CounterFact 上的事实性准确率从约 10% → 40%+ 大幅提升,显著优于现有 probe-based masking 方法。
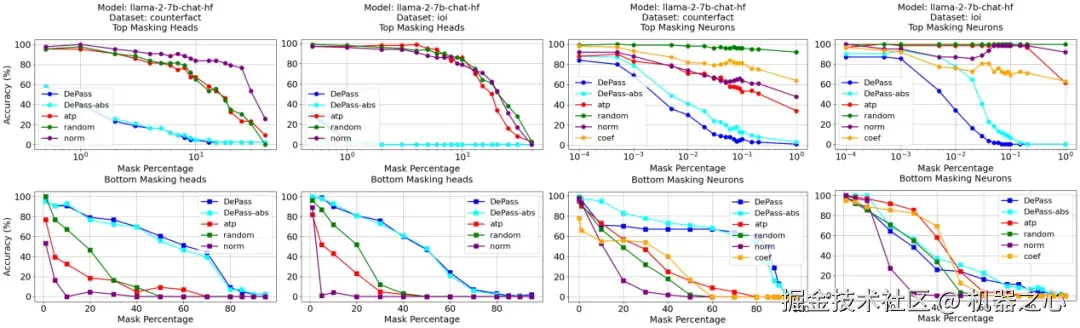
Model-Component-Level DePass------模型组件级归因:观察注意力头与 MLP 神经元的实际功能
DePass 能直接量化每个注意力头与 MLP 神经元对预测的真实贡献,在遮罩实验中显著优于梯度、激活等传统重要性指标。
当遮罩 DePass 判定的「重要组件」(Top-k Masking)时,模型准确率下降更快;当仅保留「最不重要组件」(Bottom-k Masking)时,模型性能保持得更好。这说明 DePass 识别的组件重要性具备更高的敏感性、完备性、因果性,在 IOI 与 CounterFact 等任务上均显著超越 AtP、Norm 等主流归因指标。
Subspace-Level DePass------子空间级归因
DePass 还可以用于研究隐状态中不同子空间之间的相互作用,以及这些子空间对最终输出的影响。我们以语言子空间(language subspace)为例进行分析。
我们训练了一个语言分类器,并将其权重方向作为语言子空间的基向量。随后,将中间层的隐状态分别投影到语言子空间与其正交语义子空间中;两部分隐状态在网络中分别独立传播至最终层,并通过 LM Head 解码,以观察其对应输出。
-
语言子空间: 经 t-SNE 显示形成清晰的语言聚类(如英文/法文/德文),体现语言特征集中分布。
-
语义子空间: 独立解码结果跨语言一致,例如无论输入语言为何,都会生成相同的事实答案(如「Dutch」)。
这一结果说明 DePass 能忠实保留并传播子空间的功能属性,为跨语言解释和语义分解提供了全新视角。

(左)对 token 在语言子空间上的投影进行 t-SNE 可视化。(右)针对不同多语言提示语,从语言子空间与语义子空间中解码得到的前五个 token
总结
DePass 作为一种基于分解前向传播的 Transformer 解释框架,兼具简洁性与高效性。通过冻结并分配注意力得分和 MLP 激活,DePass 实现了无损的加性分解,可无缝适配各种 Transformer 架构。
实验结果表明,DePass 在多层次粒度的归因分析中具有更高的忠实性。我们期望 DePass 能成为机制可解释性研究中的通用工具,推动社区在更广泛的任务与模型上探索其潜力与应用。