本文较长,建议点赞收藏,以免遗失。更多AI大模型开发 学习视频/籽料/面试题 都在这>>Github<<
在人工智能领域,RAG(Retrieval-Augmented Generation,检索增强生成) 是一种革命性的技术框架,它将大规模语言模型(LLM)与外部知识检索能力相结合,显著提升模型在问答、对话等任务中的准确性与可靠性。简单来说,RAG通过动态检索相关知识来增强生成过程,让AI的回答既有创造力又具备事实依据 。
一、RAG的核心原理与技术架构
1. RAG的定义与目标
RAG的本质是 "检索技术+LLM提示" (In-Context Learning)。其核心目标是通过外部知识检索解决LLM的三大局限:
- 知识局限性:传统LLM依赖于训练数据,无法实时更新知识 。
- 幻觉问题:模型可能生成无事实依据的内容 。
- 数据安全:避免敏感数据直接写入模型参数 。
2. 工作流程
RAG分为四步闭环流程:
- 知识库整理:将文档(文本、表格、图像等)分块(Chunking),并提取关键信息 。
- 向量嵌入与索引 :使用嵌入模型(如
BAAI/bge-large-zh)将文本转为向量,存储至向量数据库(如Milvus) 。 - 检索增强:用户提问时,从数据库召回相关文档(Top-K),经重排序(如FlagReranker)筛选最匹配内容 。
- 生成响应:将检索结果作为上下文输入LLM(如GPT、DeepSeek),生成最终回答 。
示例:医疗问答中,输入"布洛芬用量",RAG先检索药品说明书,再生成"成人一次1片,每日2次"的精准回答 。
二、RAG的分类与演进
根据技术复杂度,RAG可分为三类:
| 类型 | 特点 | 应用场景 |
|---|---|---|
| Naive RAG | 基础"索引-检索-生成"流程 | 简单文本问答 |
| Modular RAG | 支持分块优化、检索前后处理 | 多格式数据整合 |
| Agentic RAG | 结合智能体工具链,动态调用外部API | 复杂推理任务(如医疗诊断) |
三、RAG的实践案例:医疗智能问诊
关键实现步骤:
- 数据分块 :用
MarkdownHeaderTextSplitter按标题层级切分医学文献(如NCCN指南) 。 - 向量化:嵌入模型生成784维向量,Milvus数据库存储索引 。
- 意图识别:LLM解析用户问题,调用RAG模块或SQL工具(如查询患者病历) 。
- 生成优化:微调LLM(如DeepSeek-R1),使用LoRA适配器提升领域适应性 。
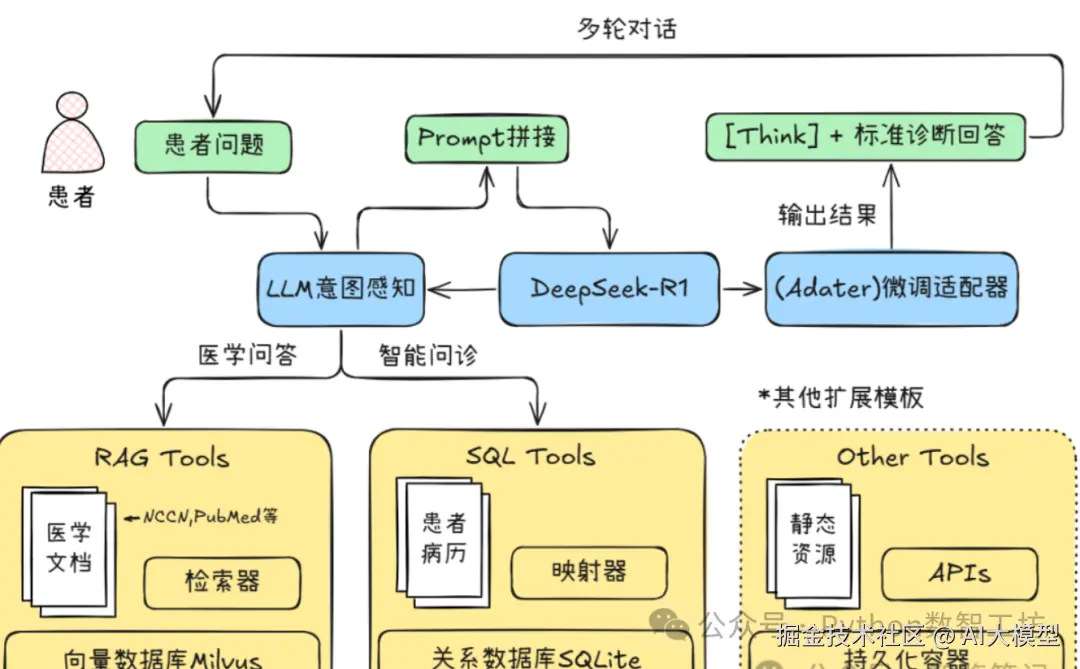
*智能问诊系统架构图:结合静态知识库与动态患者数据 *
四、RAG的评估与优化方向
评估指标:
- 检索质量:命中率(HR)、平均倒数排名(MRR) 。
- 生成质量:BLEU分、ROUGE-N(基于Ragas框架) 。
优化策略:
- 检索增强:
-
- 混合检索:稠密向量+稀疏检索(BM25) 。
- 图索引:构建实体关系网络提升相关性 。
- 生成优化:
-
- 上下文重排:按注意力机制优化文档顺序 。
- 微调+RLHF:人工标注数据强化事实性 。
结语:RAG的核心价值
RAG通过动态知识检索与生成模型的协同,实现了 "质量进,质量出" (Quality In, Quality Out)的智能响应 。无论是医疗问诊、客服系统还是企业知识库,RAG都能显著提升输出的准确性与可解释性。随着Agentic RAG等进阶架构的发展,其将在复杂场景中发挥更大潜力。
这里给大家准备了AI大模型开发 学习视频/籽料/面试题 学习文档都在这>>Github<<