本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。
在构建RAG(检索增强生成)系统时,文本分块质量直接影响知识检索精度与LLM输出效果。本文将深入解析五种分块策略的工程实现与优化方案。文中还会放一些技术文档,方便大家更好的理解RAG中常见的技术点。
一、分块技术为何成为RAG的核心瓶颈?
RAG系统的标准工作流包含三个关键阶段:
- 知识库构建:将文档分割为语义块 → 生成向量嵌入 → 存储至向量数据库
- 实时检索:将用户查询向量化 → 检索Top-K相关文本块
- 生成响应:将检索结果与查询拼接 → 输入LLM生成最终答案
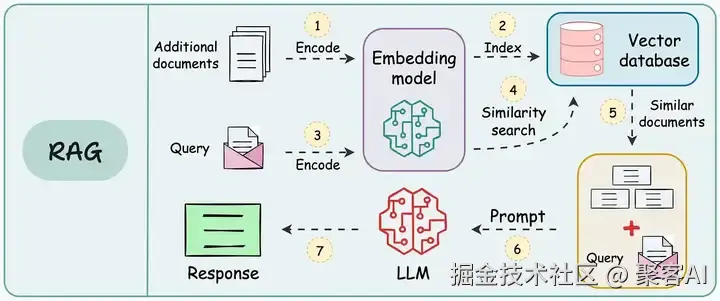
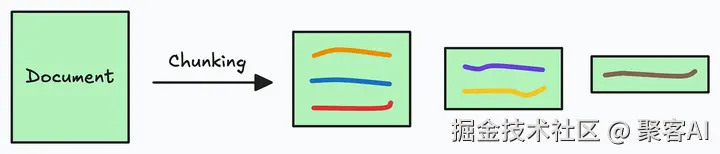
由于附加文档可能非常大,因此步骤 1 还涉及分块,其中将大文档分成较小/易于管理的部分。
此外,它提高了检索步骤的效率和准确性,这直接影响生成的响应的质量。接下来,我们就深入探讨RAG 的几大分块策略
二、五大分块策略深度解析
策略1:固定尺寸分块(Fixed-size Chunking)
生成块的最直观和直接的方法是根据预定义的字符、单词或标记数量将文本分成统一的段。
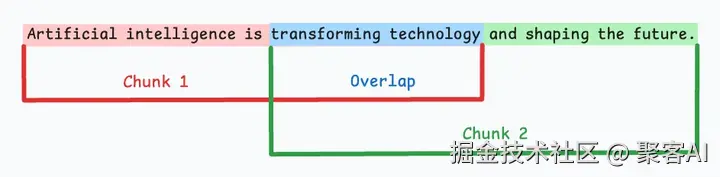
由于直接分割会破坏语义流,因此建议在两个连续的块之间保持一些重叠(上图蓝色部分)。
这很容易实现。而且,由于所有块的大小相同,它简化了批处理。
但有一个大问题。这通常会打断句子(或想法)。因此,重要的信息很可能会分散到不同的块中。
ini
# LangChain实现示例
from langchain.text_splitter import CharacterTextSplitter
splitter = CharacterTextSplitter(
chunk_size=500,
chunk_overlap=50, # 关键重叠区
separator="\n"
)
chunks = splitter.split_documents(docs)策略2:语义分块(Semantic Chunking)
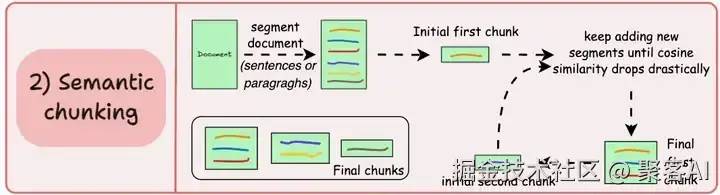
根据句子、段落或主题部分等有意义的单位对文档进行细分。
接下来,为每个片段创建嵌入。
假设我从第一个片段及其嵌入开始。
- 如果第一个段的嵌入与第二个段的嵌入具有较高的余弦相似度,则这两个段形成一个块。
- 这种情况一直持续到余弦相似度显著下降。
- 一旦发生这种情况,我们就开始新的部分并重复。
输出可能如下所示:

与固定大小的块不同,这保持了语言的自然流畅并保留了完整的想法。
由于每个块都更加丰富,它提高了检索准确性,进而使 LLM 产生更加连贯和相关的响应。
一个小问题是,它依赖于一个阈值来确定余弦相似度是否显著下降,而这个阈值在不同文档之间可能会有所不同。
ini
# 基于SBERT的语义边界检测
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
def semantic_chunking(sentences, threshold=0.85):
chunks = []
current_chunk = [sentences[0]]
for i in range(1, len(sentences)):
emb1 = model.encode(current_chunk[-1])
emb2 = model.encode(sentences[i])
sim = cosine_similarity(emb1, emb2)
if sim > threshold:
current_chunk.append(sentences[i])
else:
chunks.append(" ".join(current_chunk))
current_chunk = [sentences[i]]
return chunks策略3:递归分块(Recursive Chunking)
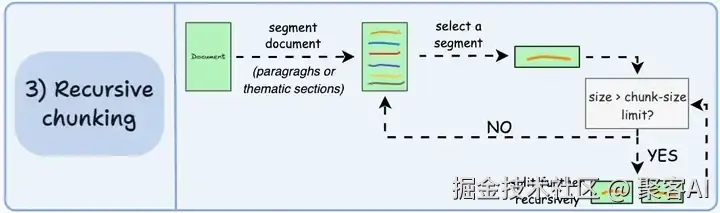
首先,根据固有分隔符(如段落或章节)进行分块。
接下来,如果每个块的大小超出了预定义的块大小限制,则将其拆分成更小的块。但是,如果块符合块大小限制,则不再进行进一步拆分。
输出可能如下所示:

如上图:
- 首先,我们定义两个块(紫色的两个段落)。
- 接下来,第 1 段被进一步分成更小的块。
与固定大小的块不同,这种方法还保持了语言的自然流畅性并保留了完整的想法。然而,在实施和计算复杂性方面存在一些额外的消耗。
策略4:文档结构分块(Structure-based Chunking)
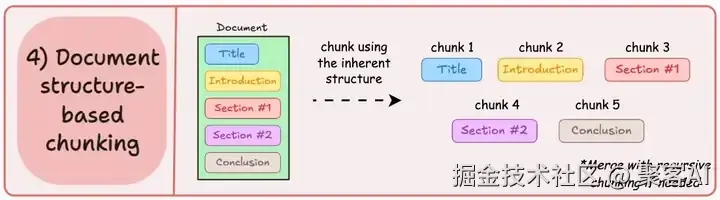
它利用文档的固有结构(如标题、章节或段落)来定义块边界。这样,它就通过与文档的逻辑部分对齐来保持结构完整性。
输出可能如下所示:

也就是说,这种方法假设文档具有清晰的结构,但事实可能并非如此。
此外,块的长度可能会有所不同,可能会超出模型令牌的限制。您可以尝试使用递归拆分进行合并。
python
# 基于BeautifulSoup的HTML结构解析
from bs4 import BeautifulSoup
def html_chunking(html):
soup = BeautifulSoup(html, 'html.parser')
chunks = []
for section in soup.find_all(['h1', 'h2', 'h3']):
chunk = section.text + "\n"
next_node = section.next_sibling
while next_node and next_node.name not in ['h1','h2','h3']:
chunk += str(next_node)
next_node = next_node.next_sibling
chunks.append(chunk)
return chunks策略5:LLM智能分块(LLM-based Chunking)

既然每种方法都有优点和缺点,为什么不使用 LLM 来创建块呢?
可以提示 LLM 生成语义上孤立且有意义的块。
显然,这种方法将确保较高的语义准确性,因为 LLM 可以理解超越简单启发式方法(用于上述四种方法)的上下文和含义。
唯一的问题是,它是这里讨论的所有五种技术中计算要求最高的分块技术。
此外,由于 LLM 通常具有有限的上下文窗口,因此需要注意这一点。
bash
# GPT-4提示词设计
你是一位专业文本分析师,请根据语义完整性将以下文档分割为多个段落块:
要求:
1. 每个块包含完整语义单元
2. 最大长度不超过512token
3. 输出JSON格式:{"chunks": ["text1", "text2"]}
文档内容:{{document_text}}三、分块策略选型矩阵
每种技术都有其自身的优势和劣势。我个人建议语义分块在很多情况下效果很好,但同样,您需要进行测试。
选择将在很大程度上取决于内容的性质、嵌入模型的功能、计算资源等。
| 维度 | 固定尺寸 | 语义分块 | 递归分块 | 结构分块 | LLM分块 |
|---|---|---|---|---|---|
| 处理速度 | ★★★★★ | ★★★☆☆ | ★★★★☆ | ★★★★☆ | ★★☆☆☆ |
| 语义保持度 | ★★☆☆☆ | ★★★★★ | ★★★★☆ | ★★★★☆ | ★★★★★ |
| 非结构化文档适应性 | ★★★☆☆ | ★★★★☆ | ★★★★☆ | ★☆☆☆☆ | ★★★★★ |
| 实现复杂度 | ★☆☆☆☆ | ★★★☆☆ | ★★★☆☆ | ★★★☆☆ | ★★☆☆☆ |
| 计算资源需求 | ★☆☆☆☆ | ★★★☆☆ | ★★☆☆☆ | ★★☆☆☆ | ★★★★★ |
好了,相信你们对RAG分块策略有了一个更深的认识,这里我再分享一个我整理的关于RAG检索增强的技术文档给大家,粉丝朋友自行领取《RAG检索增强技术文档》。如果本文对你有所帮助,记得分享给身边有需要的朋友,我们下期见。