| 数据库类型 | 存储引擎 | 数据结构 | 源码位置 |
|---|---|---|---|
| tidb | RockDB | LSM树 | https://github.com/facebook/rocksdb |
| mongodb | WiredTiger | B 树/LSM树 | https://github.com/wiredtiger/wiredtiger |
| TDengine | TSDB | BRIN | https://github.com/taosdata/TDengine |
1、tidb存储引擎概览
LSM树数据结构描述LSM树(Log Structured Merged Tree)
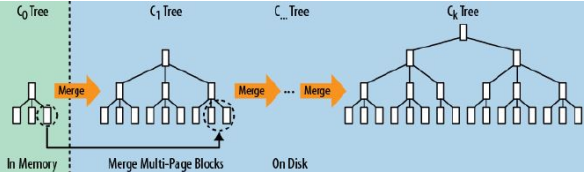
- LSM树是一个横跨内存和磁盘的,包含多颗"子树"的一个森林。
- LSM树分为Level 0,Level 1,Level 2 ... Level n 多颗子树,其中只有Level 0在内存中,其余Level 1-n在磁盘中。
- 内存中的Level 0子树一般采用排序树(红黑树/AVL树)、跳表或者TreeMap等这类有序的数据结构,方便后续顺序写磁盘。
- 磁盘中的Level 1-n子树,本质是数据排好序后顺序写到磁盘上的文件,只是叫做树而已。
- 每一层的子树都有一个阈值大小,达到阈值后会进行合并,合并结果写入下一层。
- 只有内存中数据允许原地更新,磁盘上数据的变更只允许追加写,不做原地更新。
LSM树详述:https://zhuanlan.zhihu.com/p/415799237
RocksDB内存结构描述
MemTable
MemTable是一个内存数据结构,他保存了落盘到SST文件前的数据。他同时服务于读和写------新的写入总是将数据插入到memtable,读取在查询SST文件前总是要查询memtable,因为memtable里面的数据总是更新的。一旦一个memtable被写满,他会变成不可修改的,并被一个新的memtable替换。一个后台线程会把这个memtable的内容落盘到一个SST文件,然后这个memtable就可以被销毁了。并且在flush的过程中,会完成数据的压缩
RocksDB默认实现方式是SkipList,适用于范围查询和插入,但是如果是其他场景,RocksDB也提供了另外两种实现方式。具体区别可参考https://github.com/facebook/rocksdb/wiki/MemTable
a vector memtable:适用于批量载入过程,每次新增元素都会追加到之前的元素后,当MemTable的数据被刷入L0时,数据会按之前的顺利刷入SST file
a prefix-hash memtable:适用于带有指定前缀的查询,插入和scanImmutable Memtable
所有的写操作都是在memtable进行,当memtable空间不足时,会创建一块新的memtable来继续接收写操作,原先的内存将被标识为只读模式,等待被刷入sst。在任何时候,一个CF中,只存在一块active memtable和0+块immutable memtable。刷入时机有以下三个条件来确定:
write_buffer_size 设置一块memtable的容量,一旦写满,就标记为只读,然后创建一块新的。
max_write_buffer_number 设置memtable的最大存在数(active 和 immutable 共享),一旦active memtable被写满了,并且memtable的数量大于max_write_buffer_number,此时会阻塞写操作。当flush操作比写入慢的时候,会发生这种情况
min_write_buffer_number_to_merge 设置刷入sst之前,最小可合并的memtable数,例如,如果设置2,只有当 immutable memtable数量达到2的时候,会被刷入sst,数量为1的时候,则永远不会被刷入。
RocksDB 写入数据描述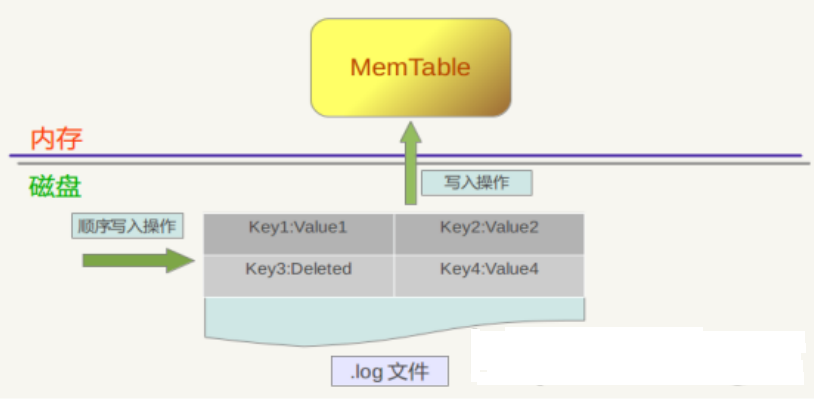
写操作包含两个具体步骤:
首先是将这条KV记录以顺序写的方式追加到log文件末尾,因为尽管这是一个磁盘读写操作,但是文件的顺序追加写入效率是很高的,所以并不会导致写入速度的降低。
第二个步骤是:如果写入log文件成功,那么将这条KV记录插入内存中的Memtable中,Memtable只是一层封装,其内部其实是一个Key有序的SkipList列表,插入一条新记录的过程也很简单,即先查找合适的插入位置,然后修改相应的链接指针将新记录插入即可。完成这一步,写入记录就算完成了,所以一个插入记录操作涉及一次磁盘文件追加写和内存SkipList插入操作,这是为何RocksDB写入速度如此高效的根本原因。
删除操作与插入操作相同,区别是,插入操作插入的是Key:Value值,而删除操作插入的是"Key:删除标记",并不真正去删除记录,而是后台Compaction的时候才去做真正的删除操作。
RocksDB 读取数据描述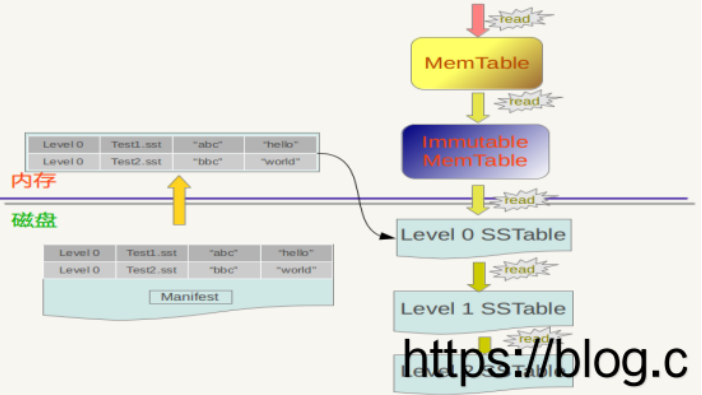
RocksDB首先会去查看内存中的Memtable,如果Memtable中包含key及其对应的value,则返回value值即可;如果在Memtable没有读到key,则接下来到同样处于内存中的Immutable Memtable中去读取,类似地,如果读到就返回,若是没有读到,那么会从磁盘中的SSTable文件中查找。
总的读取原则是这样的:首先从属于level 0的文件中查找,如果找到则返回对应的value值,如果没有找到那么到level 1中的文件中去找,如此循环往复,直到在某层SSTable文件中找到这个key对应的value为止(或者查到最高level,查找失败,说明整个系统中不存在这个Key)。
相对写操作,读操作处理起来要复杂很多。RocksDB为了提高读取速递,增加了读cache和Bloomfilter。
2、mongodb存储引擎概览
mongodb目前的默认引擎WiredTiger的默认数据结构是B树,创建LSM树的集合需要指定
db.createCollection(
"test",
{ storageEngine: { wiredTiger: {configString: "type=lsm"}}}
)
B树数据结构描述B 树的非叶结点也可以存储数据,所以查询一条数据所需要的平均随机 IO 次数会比 B+ 树少,使用 B 树的 MongoDB在单条记录的等值查询场景性能优于B+树。
LSM 树的写入性能是 B 树的 1.5 ~ 2 倍;LSM 树的读取性能是 B 树的 1/6 ~ 1/3;wiredtiger官方提供的两种数据结构的测试对比 https://github.com/wiredtiger/wiredtiger/wiki/Btree-vs-LSM
WiredTiger数据组织方式这种数据组织结构分为两部分:
in-memory page: 内存中的数据页(page)
disk extent: 基于磁盘文件的偏移量的范围存储WiredTiger 内存中的 page 是一个松散自由的数据结构,而磁盘上的 extent 只是一个变长的序列化后的数据块,这样做的目的(设计目标)有以下几点:
内存中的 page 松散结构可以不受磁盘存储方式的限制和 The FIX Rules 规则的影响,可以自由的构建 page 无锁多核并发结构,充分发挥 CPU 多核的能力。
可以自由的在内存 page 和磁盘 extent 之间实现数据压缩,提高磁盘的存储效率和减少 I/O 访问时间。
WiredTiger内存中的数据页(b树数据结构)WiredTiger 数据组织方式就是 in-memory page 加 block-extent。先来对它内存部分的 in-memory page(内存数据页,简称为 page)来做分析。
WiredTiger 引擎中的 page 分以下几类:
row internal page: 行存储 b-tree 的索引页
row leaf page:行存储 b-tree 的数据页
column internal page: 列存储 b-tree 的索引页
column fix leaf page:列存储 b-tree 的定长数据页
column var leaf page: 列存储 b-tree 的变长数据页因为 MongoDB 主要是使用行存储,所以在这里主要分析 row leaf page 这个结构和原理,结构图如下:
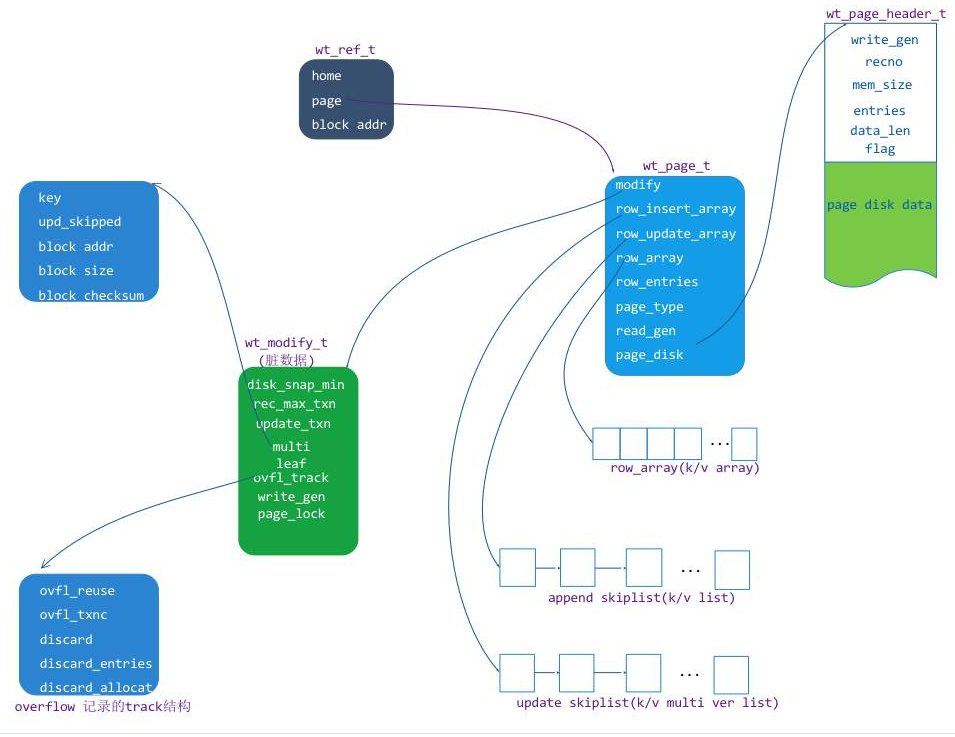
上图中主要有以下几个单元:
wt_page:内存中的 page 结构对象,page 的访问入口。
wt_modify:page 的修改状态信息,主要包含脏页标示、当前更新事务 ID 和 page 的 insert lock等。
row_array:磁盘上原有 row 的位置索引数组,主要用于页内检索。
row_insert_array:一个增加 kv(insert k/v)的跳表对象数组
row_update_array:一个在 row 基础上做更新(update k/v)的 value mvcc list对象素组。
page_disk: 从磁盘上读取到的 extent 数据缓冲区,包含一个 page_header 和一个数据存储缓冲区(disk data)
page disk data:存储在磁盘上的 page k/v cell 行集合数据更新和插入示例:
我们通过一个实例来说明,假如一个 page 存储了一个 0,100 的 key 范围,磁盘上原来存储的行 key=2, 10 ,20, 30 , 50, 80, 90,他们的值分别是value = 102, 110, 120, 130, 150, 180, 190。在 page 数据从磁盘读到内存后,分别对 key=20 的 value 进行了两次修改,两次修改的值是分别 402,502。对 key = 20 ,50 的 value 做了一次修改,修改后的 value = 122, 155,后有分配 insert 了新的 key = 3,5, 41, 99,value = 203,205,241,299。
那么在内存中的 page 就是如下图组织数据的:
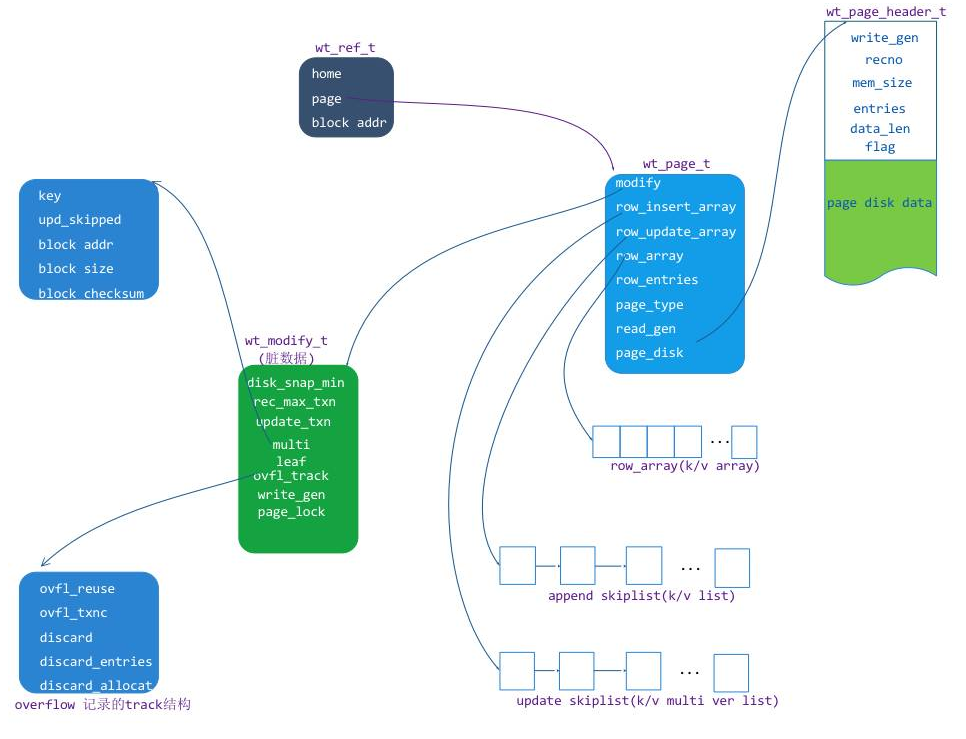
row_array 的长度是根据 page 从磁盘中读取出来的行数确定的,每个数组单元(wt_row)存储的是这个 kv row 在 page_disk_data 缓冲区偏移的位置和编码方式(这个位置和编码方式在 WT 上定义成一个 wt_cell 对象,在后面的 K/V cell章节来分析),通过这个信息偏移位置信息就可以访问到这一样在 disk_data缓冲区中的 K/V 内容值。
每一个 wt_row 对象在 row_update_array 数组中对应一个 mvcc list 对象,mvcc_list 与 wt_row 是一一对应的,mvcc list 当中存储对 wt_row 修改的值,修改的值包括值更新和值删除,是一个无锁单向链表。
相邻的两 wt_row 之间可能不是连续的,他们之间可以插入新的单元,例如 row1(key = 2) 和 row2(key=10) 可以插入 3 和 5,这两个 row 之间需要有一个排序的数据结构(WT用 skiplist 数据结构)来存储插入的 K/V,就需要一个 skiplist 对象数组 page_insert_array与row array对应。这里需要说明的是 图6 当中红色框当中的 skiplist8,它是用于存储 row1(key=2) 范围之前的 insert 数据,图6 中如果有 key =1 的数据 insert,那么这个数据会新增到 skiplist8 当中。
那么 上图 中 row 与 insert skiplist 的对应关系就是:
row1 之前的范围对应 insert 是 skiplist8
row1 和 row2之间对应的 insert 是 skiplist1
row2 和 row3之间对应的 insert 是 skiplist3
...
row7 之后的范围对应的 insert 是 skiplist7wt_row 结构
从上面对应 page 的整体分析来看在 WT 的 page 中,row 对象是整个 row leaf page 的关键结构,row 其实就是 K/V 位置的描述值(kv_pos),它的定义:
wt_row{
uint64 kv_pos;//这个值是在page读入内存时根据KV存储在page_disk的位置确定的
}这个 kv_pos 的对应的数据有对应的 K/V 存储位置信息,kv_pos 表示这个 K/V 的值有三种方式,结构如下图:
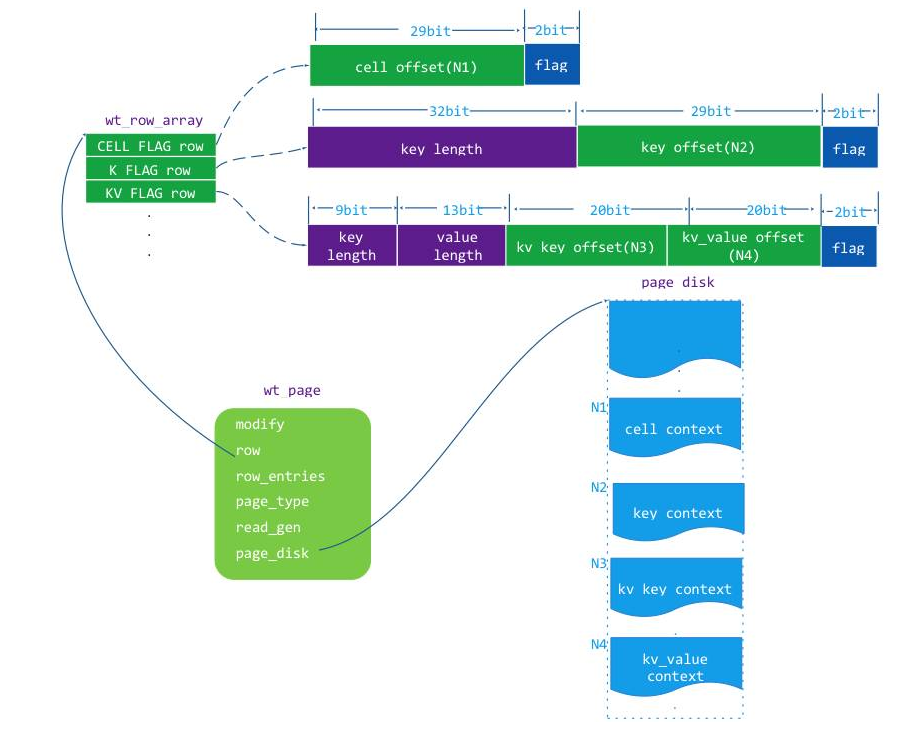
上图中的 wt_row 对应的空间上都有 2 个 bit 的 flag,这个 flag 的值:
CELL_FLAG: 0x01,表示这个 row 用 cell 对象来 k/v 标示存储位置的,因为 key 和 value 的值有可能很大,一个 page 存储不下,这个时候引入 cell 只是存储这些超长值对应的 overflow page 的索引值(extent adress)。
K_FLAG:0x02,表示这个 row 只标示了 k/v 中 key 的存储位置,但是 value 比较大,value 是 CELL_FLAG 方式标示位置存储的,因为 value 的 CELL 是紧跟在 key 存储的位置后面,找到 key 就能读取 value 的 cell 并找到 value。
KV_FLAG:0x03,表示这个 row 同时标示了 k/v 中 key 和 value 的存储位置。Cell 结构
Cell 是一个值 key 或者 value 信息被序列化后的数据块,cell 在磁盘上和在内存中内容是一致的,它是根据值(key 或者 value)内容、长度、值类型序列化构建的。在内存中 cell 是存储在 page_disk 缓冲区中,在磁盘上是存储在 extent body 上,在读取 cell 的时候需要根据 cell 数据内容进行反序列化得到一个 cell_unpack 内存结构对象,让后再根据这个 cell_unpack 对象中的内容来读取这个值(key 或者 value)。以下是它们之间的结构关系:
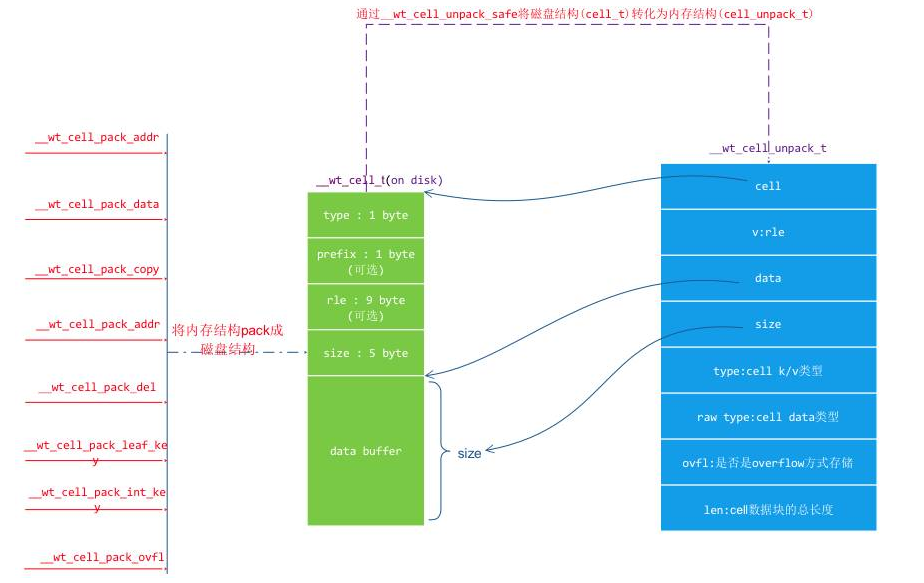
那么在 row 对象中的 CELL_FLAG row、K_FLAG row 和 KV_FLAG row 对应的值是怎么产生的呢?
其实是在 page 的数据从磁盘读到内存中时,先会对整个 page_disk 按照 cell 为单位转化成 cell_unpack,并根据 cell_unpack 中的信息构造 row 的这三种格式,这样做的目的是让能生成 K_FLAG /KV_FLAG 的 row 在每次被访问的时候不需要去做这个过程的转化,加快访问速度。
内存中的修改
内存中的 row 对象主要是为了帮助 page 数据从磁盘上载入到内存中后建立查询索引,而 page 数据被载入内存后除了查询读以外,还会对其进行修改行为(增删改),对于修改行为 WT 并没有在 row 内存结构上进行操作,而是设计两个结构,一个是针对 insert 操作的 insert_skiplist,一个针对删改操作的 mvcc list。关于这两个对象结构与 row 之间的关系在 图6 中有过描述。在这里重点来分析它们的内部构造和运行原理。
跳表(skiplist)
从前面的介绍知道 page 在内存中存储新增的 k/v 时采用的是 skiplist 数据结构,在 WiredTiger 中不仅仅这个地方使用了 skiplist,在其他需要快速查询和增删的地方基本上都使用了 skiplist,了解 skiplist 的原理有利于理解 WiredTiger 的实现。skiplist 其实是个多层链表,层级越高越稀疏,最底层是个普通的链表。
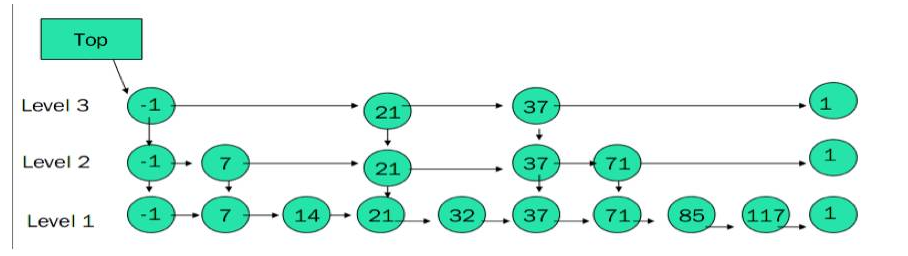
skiplist 原理参看 https://en.wikipedia.org/wiki/Skip_list
skiplist 实现参看 https://github.com/yuanrongxi/wb-skiplist
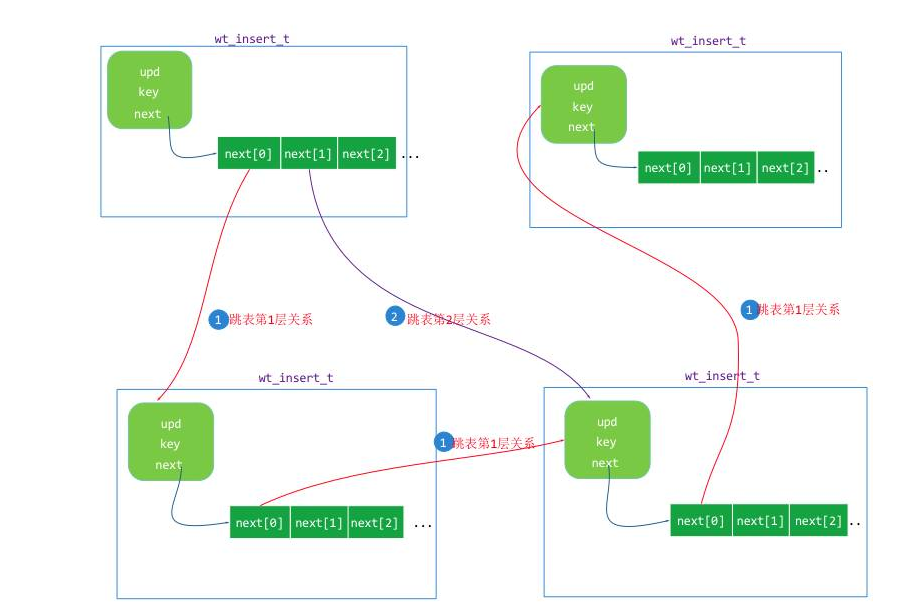
新增的 K/V 结构
WiredTiger 中 insert_skiplist 实现时是结合了它本身的 k/v 内存结构来实现的,WT 基于skiplist定义了一个 wt_insert 的 k/v 跳表单元结构,定义如下:
wt_insert{
key_offset://存储key的缓冲区偏移
key_size://key的长度
value://存储值的mvcc list的头单元,一个wt_update结构对象
next[]://skiplist的各层的下一个单元指针
key_data[]://存储key的缓冲区
}insert_skiplist 的结构示意图:
WiredTiger 为什么选用 skiplist 来作为新增记录的数据结构?主要是几个方面的考虑:
skiplist 实现起来简单,而且可以根据使用场景因地制宜的和 K/V 在内存做比较结合。
skiplist 复杂度为 O(log n),可以在内存中管理大量 k/v 的增删改查操作,而且 skiplist 在内存中按照 key 大小排序的,可以进行范围查找。
skiplist 在增删操作时可以不排斥读操作,也就是说一个线程在读 skiplist 时不需要检查 skiplist 的 write_lock,相当于无锁读,这实现增加了 skiplist 的读并发。修改的 value
WiredTiger 引擎在 insert 一个 k/v 时,key 值是存储在 wt_insert 中,那么它的 value 存储在什么地方?
在 wt_insert 结构中有一个 wt_update 类型的 value 说明,这个结构其实就是来存储内存中各个修改版本的 value 值的链表对象,也就是提到的 MVCC list 链表。在 图6 中也有提到 row 更新的时候,会向 row_update_array 对应的 mvcc list 当中加入更新的值单元(wt_update),这个结构的定义如下:
wt_update{
txnid://产生修改的事务ID
next ptr://链表的下一个wt_update单元指针
size://value值长度
value[]://存储value的缓冲区
}size = 0,表示这个是一个删除 k/v 的修改。

整个链表在平常情况下只会进行 append 操作,而且每次 append 都是在链表头的位置,这样做的目的是为了整个链表的无锁读写操作。这里涉及无锁读好理解,只要做到无锁 append 就可以做到无锁读。mvcc list 无锁 append 采用的是 CPU 的 CAS 操作来完成,大致的步骤如下:
先将需要 append 的单元(new_upd)的 next 指针指向 list header 对应的单元(header_upd),并记录 list_header 指针。
使用原子操作 CAS_SWAP 将 list header 设置成为 new_upd,CAS_SET 设置期间如果没有其他线程先以它完成设置,那么本次 append 就完成。如果有其他线程先以它设置,那么本次设置失败,进入第 3 步。
用 memory barrier 读取 list_header 的指针,重复第 1 步。第 2 步的判断是否有其他线程先以自己设置 list_header 的依据就是 CAS_SWAP 时 list_header 的值不是自己读取到值。关于这个过程更多的细节可以去了解GCC 编译器的 __sync_val_compare_and_swap 函数功能和实现。
overflow page
WiredTiger 支持是支持超大的 K/V,key 和 value 的值最大可以到 4GB(其实不到 4G,大概是 4GB - 1KB,因为除了数据外还需要存储 page 头信息)。
WiredTiger 通过定义一种叫做 overflow page 来存储超出 leaf page 最大存储范围的超大 k/v。超大的 k/v 在 insert 到 leaf page 还是存储在 insert_skiplist 当中,只有当这个 leaf page 进行存盘的时候,WT 会对超出 page 允许的最大空间的 k/v 值用单独的 overflow page 来存储,overflow page 在磁盘文件中有自己单独的 extent。
那么什么时候在内存中会出现 overflow page 呢?在用于 overflow page 的 leaf page 从磁盘上读入内存中时会构建对应的 overflow page内存对象。overflow page 本身的结构很简单,就是一个 page_header 和一个 page_disk 缓冲区。leaf page 与 overflow page 之间通过 row cell 信息来关联,cell 里面存有这个 overflow page 的 extent address 信息。
为了对 overflow page 的快速访问,WT 定义了一个的 skiplist(extent address与overflow page内存对象映射关系)来缓存内存中的 overflow page 内存对象,对 overflow page 的读流程如下:
先 cell_unpack 对应的 cell,获取到 overflow page 的 extent addr
使用 extent address 在 overflow page 缓存 skiplist 查找 overflow page 是否已经读入内存,已经读入内存,返回对应的 overflow page 读取者,如果没有进入第 3 步.
根据 extent address 信息从磁盘文件中将 overflow page 的信息读入内存,并构建一个 overflow page 加入到 skiplist 当中。最后返回读入的 overflow page 对象给读取者。这里提到的 extent address 参考下面的 extent addresss 结构章节。
Page 的页内检索
WiredTiger 实现松散的内存 page 结构为的就是能快速检索和修改,也使得数据在内存中的组织方式更加自由。不管是读还是修改,需要依赖 page 的页内检索,在读取或者修改某个 k/v 值前需要根据对应的 key 在 page 内部做一次检索来定位 k/v 的位置,而整个页内检索的核心参考轴是通 row_array 这个数组做二分查找来定位的。
在这里还是以 图6 来进行说明,假设需要在 图6 中查找 key=41 的值,步骤如下:
先通过二分法在 row_array 定位到存储 key = 41 的对象 row4
定位到 row4 后先匹配 row key 与检索的 key 是否匹配,如果匹配,在 row4 对应的 mvcc list(upd4)中读取可以访问的值。如果不匹配,在其对应的 insert_skiplist 进行查找
用 key = 41 在跳表 skiplist4 进行查找,定位到 value = 241,返回。因为都是 row_array/insert_array/update_array 数组一一对应的查找,而且这些数组的在发生修改时也不会发生改变,所以不需要对其进行锁保护,insert_skiplist 和 mvcc list 都是支持修改时无锁读取的(这个在分析这两个结构时已经说明过),所以说整个检索过程是无锁的。
如果是增删改(insert/delete/update)操作,也是先用检索过程找到对应修改的位置,再进行对应修改。如果是 insert,或获取 wt_modify 中的 page_lock 来串行化 insert 操作,如果是对值进行 update/delete,只是在 mvcc list 无锁增加一个修改后的值即可(这个过程在上面已经分析过)。
Disk extent 结构
Page 在磁盘上文件上对应的结构叫做 extent。其实它就是磁盘文件上的一块区域。
在 WT 引擎中,每一个索引对应一个文件,文件中按照 page 写入的大小和当前文件被使用的空间来确定写入的位置和写入的长度,写入的位置(offset)和写入的长度(size)被命名成 extent,并且将 extent 的位置信息(extent address)记录到一个索引空间中。
Extent 由三部分构成,他们分别是
page header:记录当前数据页的状态信息
block header: extent 存储的头信息,主要存有数据的 chucksum 和长度等。
extent data:存储的数据,是一个 cell 数据集合.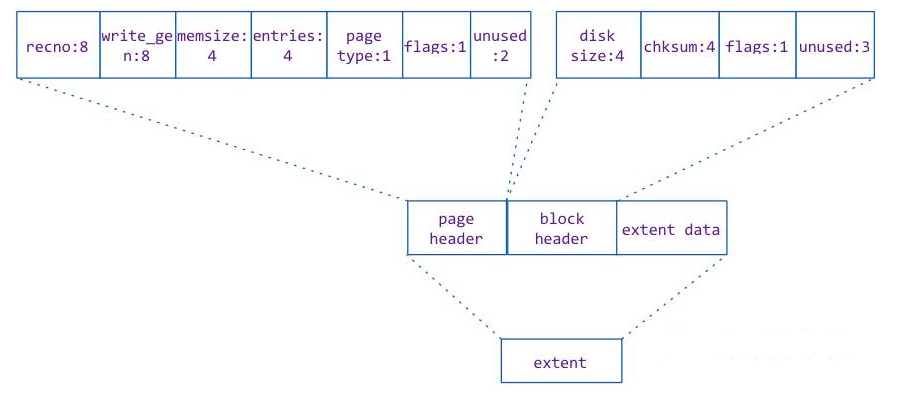
page header 在 page 的内存对象中,对应的是 page_disk 的头信息部分 wt_page_header,他们的内容是完全一致的。page header 包含当前 page 的记录实例数(entries)、page类型(row leaf page/internal page等),在 page 数据载入内存时需要用这些数据来构建 page 内存对象。
Block header 中的 checksum 是 extent data 的数据 checksum,也是 extent address 中的 checksum。用于 extent 读入内存时做合法性校验。
Extent address
Extent address 用于索引 extent 的信息,它作为一个数据条目存在一个特殊的索引 extent 中(关于这个特殊的索引 extent 在后续的磁盘 I/O 篇来详细分析)。
这里主要分析下它的内部构造和定义,extent address 中有三个值:
offset:extent 在 btree 文件中的偏移位置
size:extent 的长度
chucksum:extent 的 checksum, 用 page header/block header/extent data 整体计算得到的 checksum,用于判断 extent 的合法性。这三个值是序列化后作为 extent address 条目存储的。
Extent data
Extent data 是真正存储 page 数据的地方,它是 page 中所有 k/v cell 的集合。Page 数据从内存存入磁盘时,会将每个 k/v pair 用 cell_pack 函数转化成一个 key cell 和一个 value cell 存入序列化缓冲区中。这个缓冲区的数据写入到 extent 中就是 extent data,存储结构如下图:

Page 的磁盘读写
btree 索引管理的最小单元是 page,那么从磁盘到内存的读操作和从内存到磁盘的写操作都是以 page 为单位来读写。
在 WT 引擎中从磁盘读取一个页到内存的操作叫做 in-memory,从内存 page 写入磁盘的操作叫做 reconcile。in-memory 过程就是将 extent 从磁盘文件中读取出来转换成内存 page ,而 reconcile 操作就是将内存中的 page 转换成 extent 写入到磁盘上,reconcile 过程会造成 btree page 的分裂。
读写序列图如下:
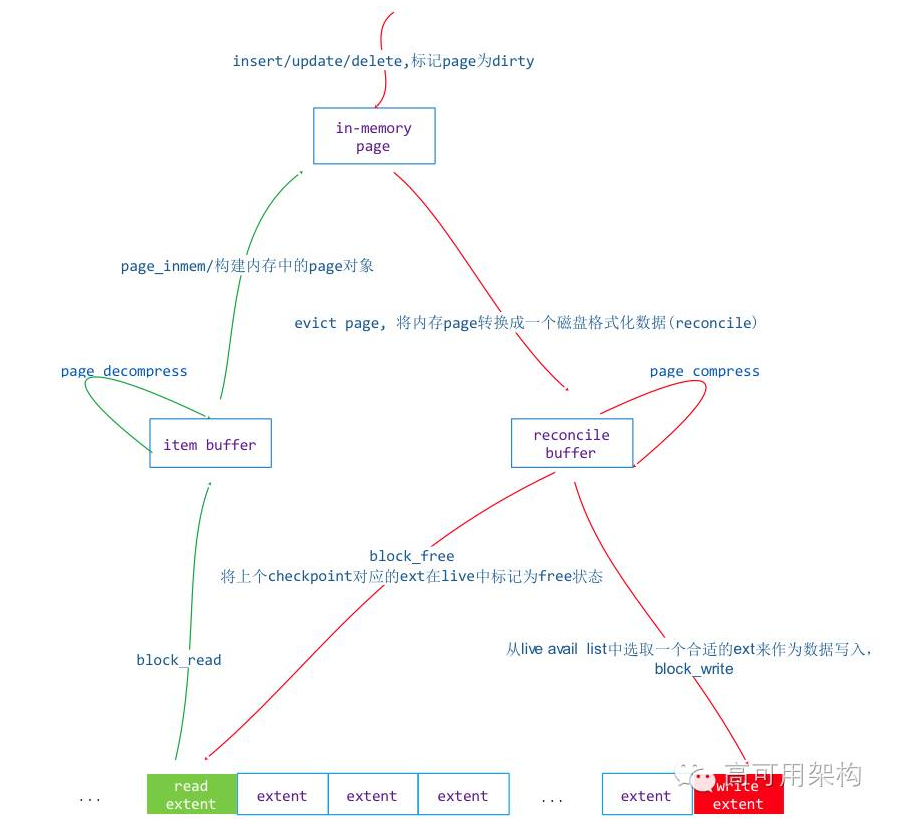
读过程(in-memory)
Page 的读过程是磁盘到内存的过程,步骤如下:
根据 btree 索引上的 extent address 信息,从 btree 对应的文件中读取这个 extent 到内存缓冲区中。
通过读取的 extent 数据生成 checksum,并与 extent address 中的 checksum 校验合法性。
根据 btree 配置的 meta 信息判断是否开启压缩,如果没有压缩直接到第 5 步,如果有压缩进行第 4 步。
根据配置的压缩算法信息获取 WT 支持的 compressor 对象,并对 extent data 做解压缩。
通过 wt_page_header 信息构建内存中的 page 对象。
通过 wt_page_header 的 entries 数对整个 page_disk_data 遍历,按照 cell 的信息逐行构建 row_array、insert_array 和 update_array。如果读入的 page 包含 overflow page,overflow page 并不会在这个过程中读取到内存中,而是在访问它的时候读取到内存中的,这个过程只会读取 overflow page 对应的 extent address 作为 row 对象的内容。在 overflow page 一节分析过 overflow page 的读取过程。
写过程(reconcile)
写过程比较复杂,page 的写过程如果 page 的内存空间过大会对 page 做 split 操作,对于超过 page 容忍的大 K/V 会生成 overflow page。整个写过程步骤如下:
按照 row_array 为轴,扫描整个 row_array/upate_array 和 insert_array,将 k/v 内存中的值生成 cell 对象,并将其存入一个缓冲区(rec buffer)中。
判断这个缓冲区是否超出了配置的 page_max_size,如果超过了,进行 split 操作。
对单个 key 或者 value 超过 page_max_size,生成一个 overflow page,并将 overflow page 对应的 extent address 生成 cell。
重复 1 ~ 3 步直到所有的 k/v cell 都写入到 rec buffer 中。
假如 btree 配置了数据压缩项,在 WT 引擎中查找压缩对象,并用这个压缩对象对 rec buffer 进行数据压缩得到 data buffer,如果没有配置压缩跳过这一步(data buffe = rec buffer)。
根据 page 对象中的 wt_page_header 的信息将它对应的信息写入到 data buffer 头位置。根据 btree 文件的偏移和空间状态产生一个 extent,计算 data buffer 的 checksum,并将 data buffer 填充到 extent data 当中。
根据 extent 的信息填充 block_header,将整个 externt 写入到 btree 的文件当中并返回 extent address。
Page 压缩
通过 page 的读写过程分析知道这两个过程如果配置了压缩,就需要调用压缩解压缩操作。WT 实现压缩和解压缩是通过一个外部自定义的插件对象来实现的,下面是这个对象的接口定义
__wt_compressor{
compress_func();//压缩接口函数
pre_size_func();//预计算压缩后数据长度接口函数
decompress_func();//解压缩接口函数
terminate_func();//销毁压缩对象,有点像析构函数
};WT 提供 LZO/ZIP/snappy 这几个压缩算法,也支持自定义压缩算法,只要按照上面的对象接口实现即可。要让 WT 支持压缩算法,需要在 WT 启动时通过 wiredtiger_open 加载压缩算法模块,例子如下:
wiredtiger_open(db_path, NULL, "extensions=[/usr/local/lib/libwiredtiger_zlib.so]",&connection);然后在 WT 引擎创建表时可以配置压缩启用压缩配置即可,例如:
session->create(session, "mytable", "block_compressor=zlib");WT 的插件式压缩非常灵活和方便,MongoDB 默认支持 ZIP 和 snappy 压缩,4.2以后开始支持zstd(Facebook开源,压缩速率极大提升),在 MongoDB 创建 collection 时是可以进行选择压缩算法。
① mongodb 默认的 snappy 压缩算法压缩比约为 2.2-4.5 倍
② zlib 压缩算法压缩比约为 4.5-7.5 倍(本次迁移采用 zlib 高压缩算法)
| 压缩算法 | 真实数据量 | 真实磁盘空间消耗 |
|---|---|---|
| snappy | 3.5T | 1-1.8T |
| zlib | 3.5T | 0.5-0.7T |
优化建议
WiredTiger 引擎采用内存和磁盘上不同的结构来实现 page 的数据组织,目标还是让内存中的 page 结构更加方便在 CPU 多核下的增删查改的并发操作,精简磁盘上的 extent 结构,让磁盘上的表空间管理不受内存结构的影响。基于 extent(偏移 + 数据长度)的方式也让 WiredTiger 引擎的数据文件结构更简便,可以轻松实现数据压缩。
然而这种内存和磁盘上结构不一致的设计也有不好的地方,数据从磁盘到内存或者从内存到磁盘需要多次拷贝,中间还需要额外的内存作为这两种结构的临时缓冲区,在物理内存不足的情况下会让 swap 问题雪上加霜,性能会急剧下降,这个在测试样例里面有体现。所以要让 WiredTiger 引擎发挥好的性能,尽让配备更大物理内存给它使用。
MongoDB 3.2 版本已经将 WiredTiger 作为默认引擎,我们在使用 MongoDB 时一般不会对 WiredTiger 做配置,这可能会有些业务场景发挥不出 WiredTiger 的优势。MongoDB 在创建 collection 时可以对 WiredTiger 的表做配置,格式如下:
db.createCollection("<collectionName>", {storageEngine: {
wiredtiger: {configString:"<option>=<setting>,<option>=<setting>"}}});不同的业务场景是可以配置进行不同的配置。
如果是读多写少的表在创建时我们可以尽量将 page size 设置的比较小 ,比如 16KB,如果表数据量不太大(<2G),甚至可以不开启压缩。那么 createCollection 的 configString 可以这样设置:
"leaf_value_max=8KB,os_cache_max=1GB"如果这个读多写少的表数据量比较大,可以为其设置一个压缩算法,例如:
"block_compressor=zlib, internal_page_max=16KB,leaf_page_max=16KB,leaf_value_max=8KB"如果是写多读少的表,可以将 leaf_page_max 设置到 1MB,并开启压缩算法,也可以为其制定操作系统层面 page cache 大小的 os_cache_max 值,让它不会占用太多的 page cache 内存,防止影响读操作。
优化参数说明:
| 参数名称 | 默认配置值 | 含义 |
|---|---|---|
| allocation_size | 4KB | 磁盘上最小分配单元 |
| memory_page_max | 5MB | 内存中允许的最大page值 |
| internal_page_max | 4KB | 磁盘上允许的最大internal page值 |
| leaf_page_max | 32KB | 磁盘上允许的最大leaf page值 |
| leaf_key_max | 1/10*leaf_page 0 | leaf page上允许的最大key值 |
| leaf_value_max | 1/2*leaf_page 64M | leaf page上允许的最大value值 |
| split_pct | 75% | reconciled的page的分割百分比 |
3、TDengine存储引擎概览
内存中数据组织形式:SkipList
SkipList:其实跳表就是在普通单向链表的基础上增加了一些索引,而且这些索引是分层的
Skip需要更新的部分比较少,锁的东西也更少,而诸如AVL树插入过程中可能需要多次旋转,导致插入效率较低
(1)查找操作
示意图如下:

比如我们要查找key为19的结点,那么我们不需要逐个遍历,而是按照如下步骤:
从header出发,从高到低的level进行查找,先索引到9这个结点,发现9 < 19,继续查找(然后在level2这层),查找到21这个节点,由于21 > 19, 所以结点不往前走,而是level由2降低到1
然后索引到17这个节点,由于17 < 19, 所以继续往后,索引到21这个结点,发现21>19, 所以level由1降低到0
在结点17上,level0索引到19,查找完毕。
如果在level==0这层没有查找到,那么说明不存在key为19的节点,查找失败
(2)插入操作
示意图如下:
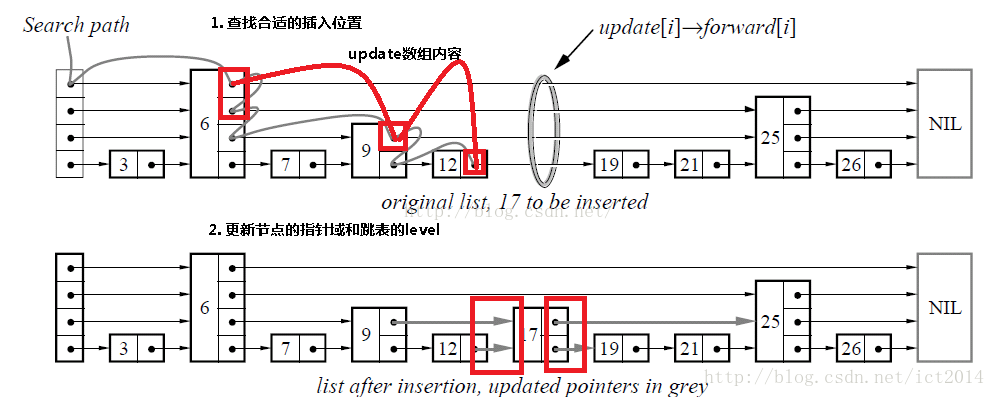
其实插入节点的关键就是找到合适的插入位置,即从所有小于待插入节点key值的节点中,找出最大的那个,所以插入节点的过程如下:
查找合适的插入位置,比如上图中要插入key为17的结点,就需要一路查找到12,由于12 < 17,而12的下一个结点19 > 17,因而满足条件
创建新结点,并且产生一个在1~MAX_LEVEL之间的随机level值作为该结点的level
调整指针指向
落盘:
TSDB 内存中的时序数据为行存储,为了便于查询和乱序数据的处理,内存中建立了一个 SkipList 作为内存索引:

TSDB 内存中的数据积累到一定量时,会触发落盘。在落盘时,时序数据由行存储形式转化为列存储形式,并维护 BRIN 索引,引入 LAST 文件和 SUB-BLOCK 机制处理文件碎片化。列存储形式如下图所示:
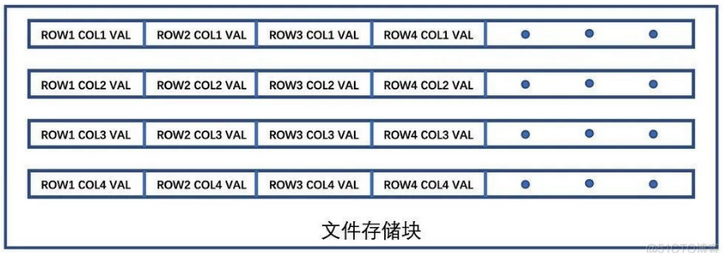
列式存储:每一列都是一种数据类型,这样就可以使用针对数据类型的压缩方法将数据压缩;一次磁盘定位顺序读取,加快查询。
磁盘中数据组织形式:Block Range INdex
Block Range INdex:即数据块范围的索引,它的设计初衷是为了解决当数据表极其庞大时的迅速扫描问题。
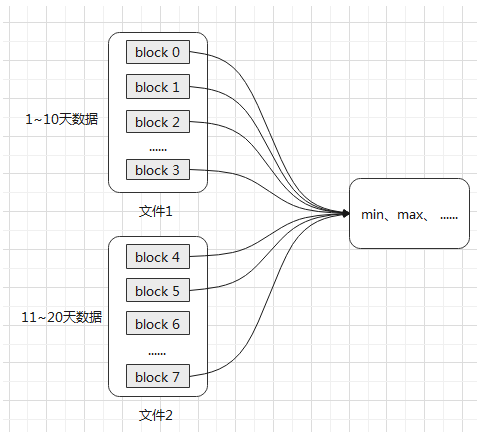
BRIN索引是先排除不再范围内的数据块,一旦找到包含目标数据的数据块范围之后,采用位图扫描获取相应数据行。
TDengine:每个数据文件(.data 结尾)都有一个对应的索引文件(.head 结尾),该索引文件对每张表都有一数据块的摘要信息,记录了每个数据块在数据文件中的偏移量,数据的起止时间等信息,以帮助系统迅速定位需要查找的数据
工作流程:
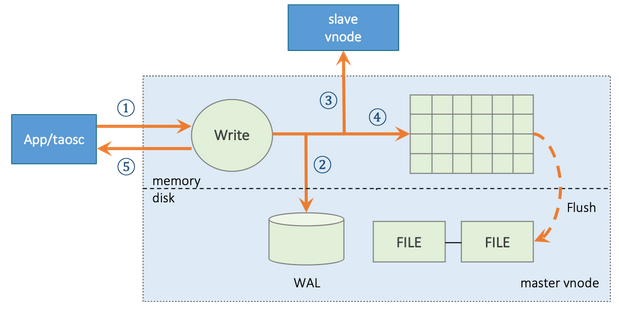
(1)master vnode 收到应用的数据插入请求,验证OK,进入下一步;
(2)如果系统配置参数 walLevel 大于 0,vnode 将把该请求的原始数据包写入数据库日志文件 WAL。如果 walLevel 设置为 2,而且 fsync 设置为 0,TDengine 还将 WAL 数据立即落盘,以保证即使宕机,也能从数据库日志文件中恢复数据,避免数据的丢失;
(3)如果有多个副本,vnode 将把数据包转发给同一虚拟节点组内的 slave vnodes, 该转发包带有数据的版本号(version);
(4)写入内存,并将记录加入到 skip list;
(5)master vnode 返回确认信息给应用,表示写入成功。
(6)如果第 2、3、4 步中任何一步失败,将直接返回错误给应用。
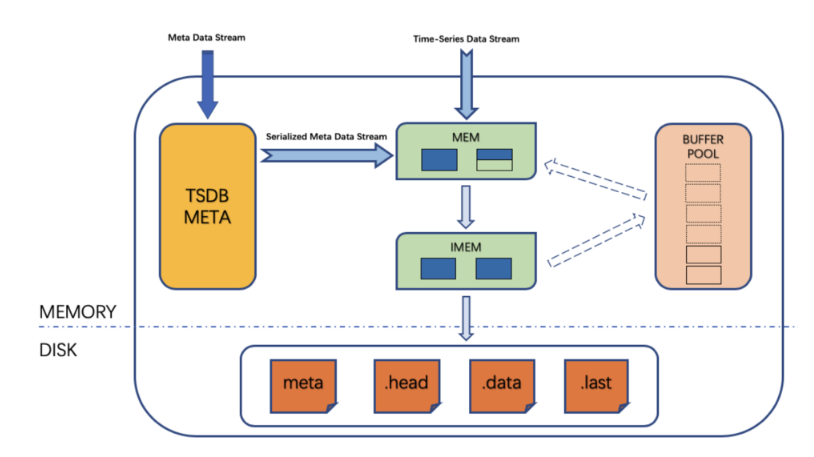
写入与读取示意图:
(1)TSDB 启动时会事先分配一个 BUFFER POOL 作为写入缓冲(默认16 MB*6=96 MB),缓冲区块大小和个数可配,区块个数可修改。
(2)META 数据和时序数据从缓冲块申请写入空间,写入引擎向 BUFFER POOL 申请缓冲区块,写满的缓冲区块占总缓冲区块的1/3时触发落盘操作。
(3)落盘时,缓冲区块中的数据写入到 META 等文件中,落盘结束后缓冲区块归还给 BUFFER POOL,形成循环机制。
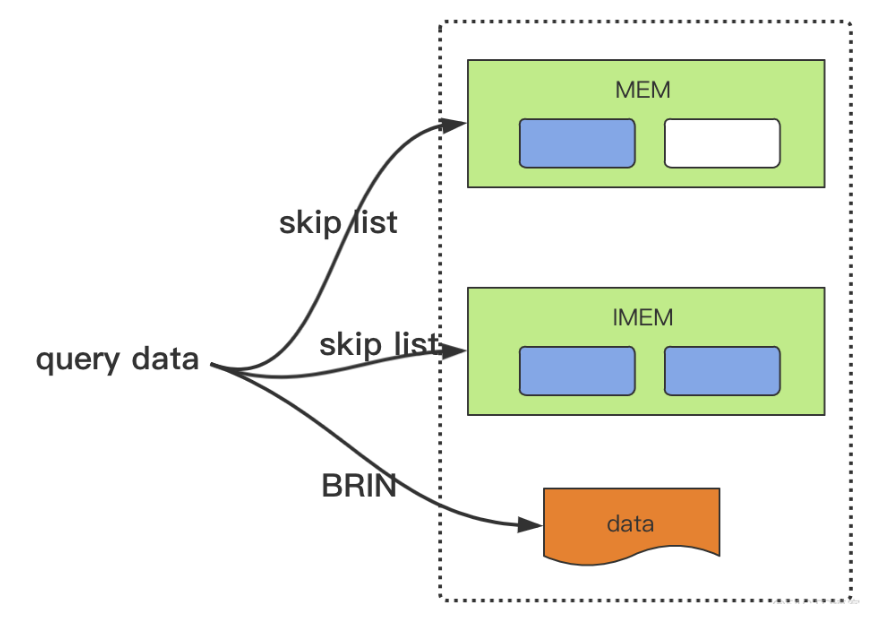
(4)查询时,对 MEM,IMEM 以及数据文件中的数据进行合并查询。
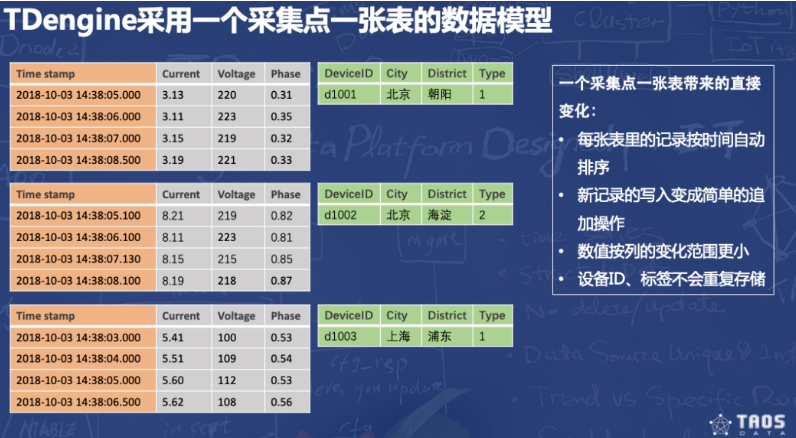
业务使用设计:一个数据采集点(设备)一张表的策略
(1)由于不同数据采集点产生数据的过程完全独立,每个数据采集点的数据源是唯一的,一张表也就只有一个写入者,这样就可采用无锁方式来写,写入速度就能大幅提升。
(2)一个设备一张表,就保证了一张表插入的数据是有时序保证的(不同设备由于网络的原因,到达服务器的时间无法控制,是完全乱序的),这样数据插入操作就变成了一个简单的追加操作,插入性能大幅度提高。
(3)一个数据采集点的数据是以块为单位连续存储的。如果读取一个时间段的数据,它能大幅减少随机读取操作,成数量级的提升读取和查询速度。
(4)一个数据块内部,采用列式存储,对于不同数据类型,采用不同压缩算法,而且由于一个数据采集点的采集量的变化是缓慢的,压缩率更高。
数据分片设计:虚拟节点(vnode)
(1)为更好的支持数据分片、负载均衡,防止数据过热或倾斜,数据节点被虚拟化成多个虚拟节点(vnode)。每个 vnode 都是一个相对独立的工作单元,是时序数据存储的基本单元,具有独立的运行线程、内存空间与持久化存储的路径。一个 vnode 包含一定数量的表(数据采集点)。
(2)如何打散表到vnode中:以下3个参数决定
maxVgroupsPerDb: 每个数据库中能够使用的最大vnode个数(单个副本),默认为64;
minTablesPerVnode: 每个vnode中必须创建的最小表数,即是说这是第一轮建表用的步长(就是满多少表写下一个vnode),默认1000;
tablelncStepPerVnode:每个vnode中超过最小表数后的递增步长(即是后续满多少表写下一个vnode),默认1000。
说明:在第一个vnode中,表数量从0开始逐渐递增,随着数量达到minTablesPerVnode后,开始创建下一个vnode并继续在其中建表。之后,重复该过程直到vnode数量达到maxVgroupsPerDb。之后,TDengine将回到第一个vnode继续创建新表,在补充每个vnode的表数达到tablelncStepPerVnode数量后,后续以tablelncStepPerVnode为步长继续在vnode中依次创建表,直到建完全部表。