目录
[1. 如何准确识别数据变化](#1. 如何准确识别数据变化)
[2. "删除"操作的处理](#2. “删除”操作的处理)
[3. 数据源缺乏有效的"变化标识"](#3. 数据源缺乏有效的“变化标识”)
[4. 性能瓶颈及对源系统的影响](#4. 性能瓶颈及对源系统的影响)
[5. 数据一致性的挑战](#5. 数据一致性的挑战)
[6. 增量机制的可靠性保障](#6. 增量机制的可靠性保障)
在现代企业中,数据往往分散在多个独立的业务系统中 ,这就出现了"数据孤岛":市场部门无法及时获取销售数据,管理者难以看到统一的业务全景,手工整合报表不仅效率低下,更易出错,严重影响了决策的速度与准确性。
可以说,正是为了解决数据分散、标准不一、整合困难这一核心痛点,ETL技术应运而生。它通过抽取、转换、加载这一套系统化流程,将各种数据源进行清洗、整合和汇集,进而为企业的数据分析和商业智能打下坚实可靠的基础。
本文就从ETL增量抽取会遇到的问题、方法和充分利用这项技术三个方面一一详解,带你深入理解它。
一、增量抽取会遇到哪些实际问题?
理想情况下,增量抽取逻辑清晰明了。但在真实的项目环境中,你会遇到一系列具体且棘手的问题。如果不能妥善处理,增量抽取流程可能变得脆弱,甚至引发比全量抽取更复杂的数据一致性问题。
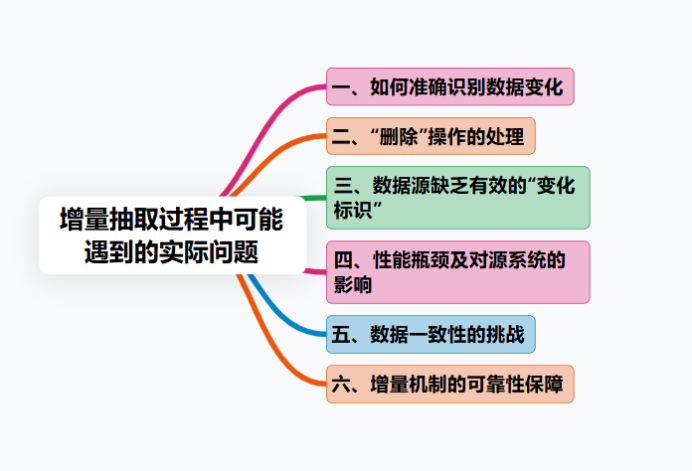
1. 如何准确识别数据变化
这是最根本的挑战。你如何精确地知道哪些记录是新增的?哪些被修改了?哪些又被删除了?如果源系统没有提供一个可靠的、能标识数据变化的字段,那么这项任务会变得异常困难。
2. "删除"操作的处理
新增和修改操作相对容易追踪,但一条记录在源系统被物理删除后,你如何能感知到?许多识别变化的方法(如依赖时间戳)无法捕获删除操作。这条被删除的记录会悄无声息地消失,导致数据仓库中残留着无效的"僵尸数据",造成严重的数据不一致问题。你懂我意思吗?这是数据质量的一个重大隐患。
3. 数据源缺乏有效的"变化标识"
你可能期望源表有一个设计良好的字段,但现实是,许多遗留系统并未考虑这种需求;或者,即便存在这个字段,也可能由于开发规范不严格,未在数据更新时及时维护它,导致其数据不可靠。
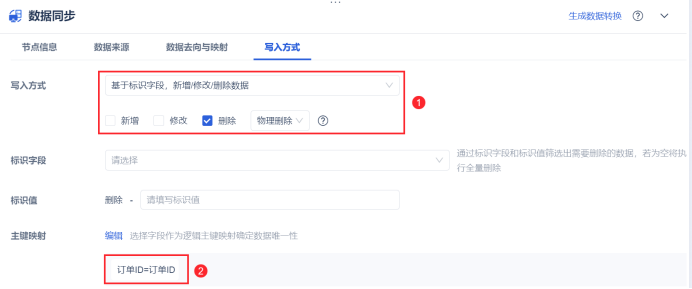
接入数据源之后怎么保证及时更新和可靠性?
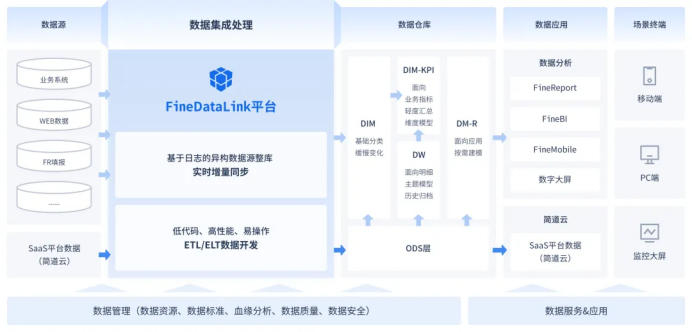
可以利用先进的数据集成工具 ,比如我工作经常用到的FineDataLink ,可以选择标识字段,进行新增,修改或删除,最终映射出更新后可靠的数据源。这款工具链接我放在这里了,大家可以上手试试:https://s.fanruan.com/8hhzn(复制到浏览器打开)
4. 性能瓶颈及对源系统的影响
即便源表有时间戳字段,但如果你直接对一个数亿行的表执行这样的查询,这个查询本身就可能对源系统的生产数据库造成巨大压力,甚至会影响线上业务的正常运营!
5. 数据一致性的挑战
在ETL作业执行期间,源系统的数据可能还在持续变化,这可能导致你抽取的数据快照处于不一致的状态。
比如,你可能漏掉某次恰好在你抽取过程中发生的更新,或者捕获到的关联数据在时间点上存在偏差。但FineDataLink能实现数据实时增量同步,这种问题就不会产生。
6. 增量机制的可靠性保障
这里要注意,你的增量逻辑是否足够健壮?
举个例子:
如果某次抽取任务意外失败,在任务恢复后,你的机制能否正确处理失败期间积累的数据变更,确保既不丢失数据,也不引入重复数据?
看到这里,你可能会觉得问题比预想的要复杂,这正是我们需要系统化方法和严谨设计的原因。
二、如何进行增量抽取?
接下来,我们就来探讨几种主流的增量抽取方法。我一直强调,没有一种方法可以称为"最佳",关键在于选择最适合你当前数据源特性和约束条件的方案。
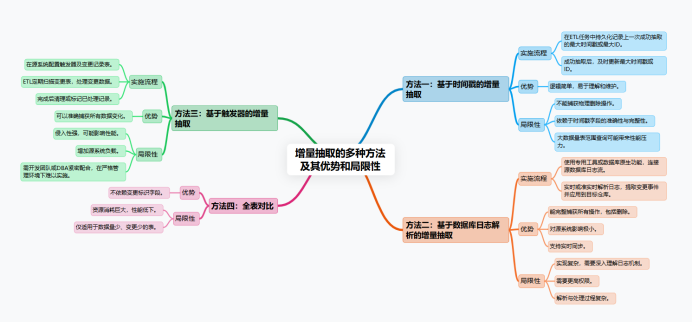
方法1:基于时间戳的增量抽取
这是最直观、应用最广泛的方法之一。它要求源表必须包含一个可靠的、随数据插入和更新而自动变更的时间戳字段,或者一个严格单调递增的ID字段。
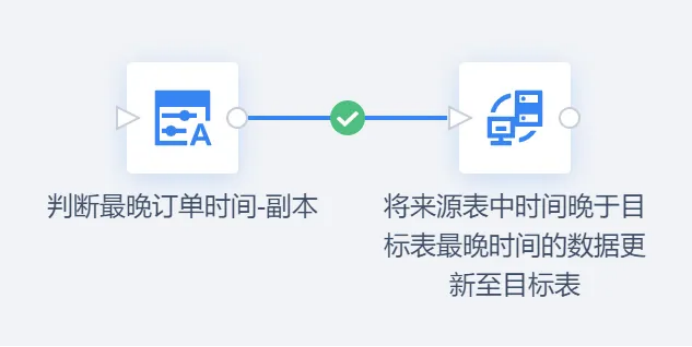
实施流程:
在ETL任务中,持久化记录上一次成功抽取到的最大时间戳或最大ID值;成功抽取后,及时更新记录的最大时间戳或ID值。
优势:逻辑简单,易于理解和维护。
局限性:
- 无法直接捕获物理删除操作。
- 完全依赖于时间戳字段的准确性和完整性。
- 在大数据量表上执行范围查询可能存在性能压力。
方法2:基于数据库日志解析的增量抽取
这是一种更高效、对源系统影响更小,并能捕获所有变更类型的方法。通过解析数据库的二进制日志来获取所有的数据变更事件。
实施流程:
借助专用工具或数据库原生功能,连接到源数据库的日志流;实时或准实时地解析日志,提取结构化的变更事件;将这些变更事件应用到目标数据仓库中。
就比如你在FineDataLink的实时采集任务上设置条件,就能在右边的任务栏中实时看到运行状态。
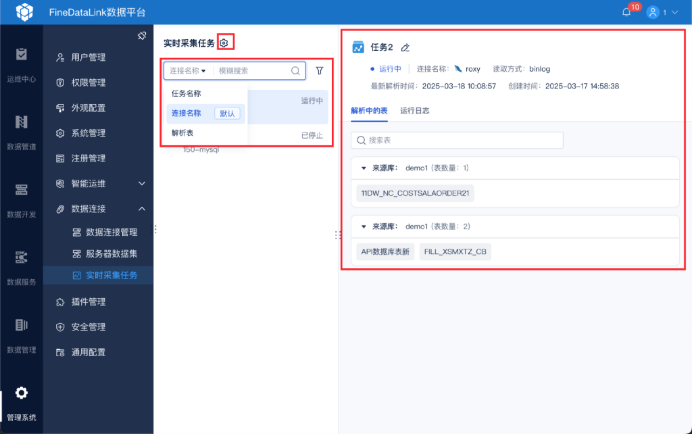
优势:
- 能完整捕获所有数据操作,包括删除,这是其核心优势;
- 对源系统性能影响极低,因为它是读取日志,而非直接查询业务表;
- 支持实时数据同步。
局限性:
- 技术实现复杂度较高,需要深入理解数据库日志机制;
- 通常需要更高的数据库访问权限;
- 日志解析和数据处理本身具有一定复杂性。
方法3:基于触发器的增量抽取
这是一种在数据库层实现、可靠性高但侵入性较强的方法。
在源数据库的表上创建触发器。当发生INSERT、UPDATE等操作时,触发器会自动将变更的数据写入到一张专用的"变更记录表"中。
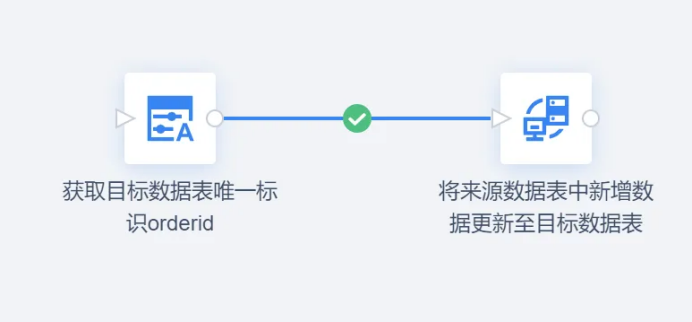
实施流程:
- 在源系统创建数据库触发器及对应的变更记录表。
- ETL进程定期扫描这张变更记录表,获取待处理的变更数据。
- 处理完成后,清理或标记已处理的记录。
**优势:**能够准确捕获所有类型的数据变化。
局限性:
- 对源系统侵入性强,需要在生产数据库上创建对象,可能对线上业务性能产生额外开销。
- 增加了源数据库的负载。
- 通常需要源系统开发团队密切配合,在管理严格的环境中可能不容易实施。
方法4:全表对比
这是一种资源消耗大、仅在特定场景下考虑的方法。
通过对比源表和目标表的全部数据或关键字段的哈希值,来识别差异。
**优势:**不依赖任何额外的变更标识字段。
局限性:
- 性能代价极高,计算和I/O开销巨大。
- 仅适用于数据量非常小且变更极少的表。
简单来说,方法的选择是一个权衡的过程:如果源表有可靠的时间戳,方法一通常是首选;如果需要完整捕获删除操作且技术条件允许,方法二是更优的选择;当外部限制严格时,才考虑方法三或四。
三、如何利用好ETL增量抽取?
掌握了方法原理,只是第一步。要构建一个稳定、可靠、高效的增量抽取流程,还需要遵循一系列最佳实践。
**1.深入进行源头调研,审慎选择方案。**在设计阶段,务必与源系统的负责人或DBA充分沟通,明确以下关键点------
表结构详情:是否存在可靠的字段?
数据库环境:类型、版本,是否支持并允许日志解析?
数据规模:数据总量和每日变更频率的估算。
权限与规范:是否允许创建触发器或直接查询生产库?
基于这些事实依据进行决策,最适合当前客观约束的方案,就是最好的方案。
2.构建完善的监控与告警体系。一个健壮的增量抽取系统必须配备全面的监控。
FineDataLink就具备这种健全的监控体系,你看,你直接在管理系统的磁盘运维上就能设置监控预警条件,一旦触发预警条件,系统就会立刻开启预警,并通过短信、平台或邮箱的形式发出警告。
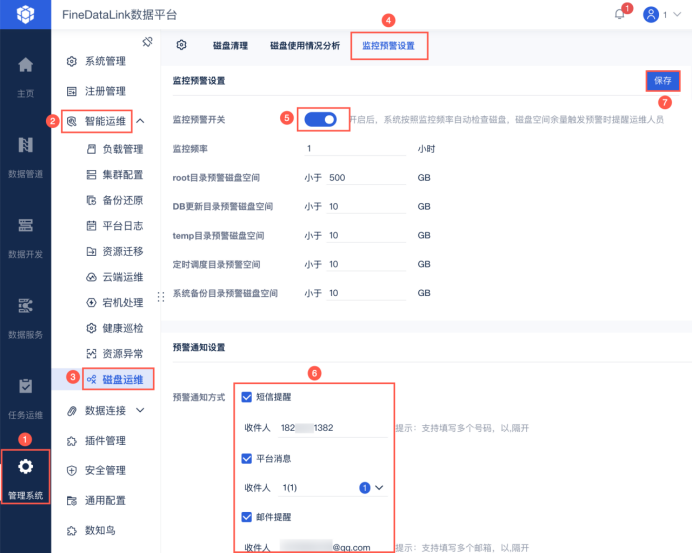
监控处理延迟:数据从产生到入库的延迟是否在可接受范围内?这里要注意,延迟增长往往是系统异常的早期信号。
监控数据量波动:单次抽取的数据量是否在合理预期内?数量的异常暴增或锐减可能预示着逻辑错误。
设立可靠的检查点:必须持久化并妥善管理每次抽取的状态信息。这是确保任务失败后能准确重启、避免数据丢失或重复的基石。
3.重点攻克"删除"与"更新"的处理。
对于删除操作,如果采用基于时间戳的方法,通常建议在目标表采用"软删除"策略,通过更新此状态来标记记录失效,而非进行物理删除。
对于更新操作,需要根据业务需求明确处理策略。在数据仓库中,这常涉及"缓慢变化维"的概念。
4.开展全面且充分的测试。增量抽取的逻辑远比全量复杂,因此测试必须覆盖各种场景。
功能测试:模拟完整的新增、修改、删除操作,验证ETL流程能否正确捕捉和处理。
性能压力测试:使用与生产环境同量级的数据进行测试,确保流程不会成为系统瓶颈。
容错与恢复测试:模拟任务中途失败,验证重启后能否从断点准确恢复,数据是否完整。
总结
所以说,增量抽取绝不是设置一个简单的条件就能完美解决的,它是一个涉及数据源理解、技术选型权衡和流程稳定性设计的系统工程。
我一直强调,在数据工程领域,系统的稳定性和可靠性远比追求单一速度指标更为重要。你说对不?