0 序言
LSM-tree作为现代数据库 NewSQL 存储引擎 的核心,以顺序写 和异地更新 大幅提升写入性能,解决了B-tree在写放大 和磁盘碎片上的瓶颈。
本文意在解析
LSM-tree的Memtable、SSTable与WAL机制,揭示读写流程 和合并策略 (Leveled与Tiered Compaction),并探讨其性能抖动 和SSD寿命 挑战。理解LSM-tree原理就可以在实际系统中进行权衡与优化。
1 概述: LSM-Tree
B-tree到LSM-tree
- 其实这俩都是数据库存储引擎 绕不过去的树。
B-tree更加早期,也是传统关系型数据库中所广泛应用,像是MySQL InnoDB和SQL server都有他的身影。
B-tree 数据结构其实很优雅的,B for Balanced, 所以其特点简明扼要就是自平衡,而通过自平衡有效地减少了磁盘IO。之后更是被发扬光大,演变出来很多分支,比如我们常说的B+树。
- 这棵树是讲数据按照顺序存储在树节点 中,每一个节点上边都有一定的key和pointer。而Key代表这顺序,
pointer则是指向子节点的路牌。这样就可以快速定位到目标数据,减少磁盘IO。
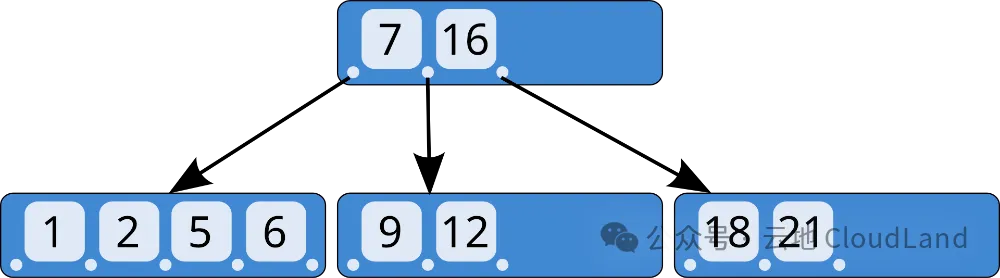
- 但是每一个解决方案都像是硬币,都是两面的。数据不是一成不变的,在不断的数据操作时,节点会分裂,一变2之后,从【内存】flush到【硬盘】的时候就很有可以变得不连续。并且在大量更改的时候,除了会造成写放大 ,同样也会因为【磁盘】循环写入产生不连续。
随着大量的key和pointer的产生,真正的数据存储空间 被压缩。而
LSM-tree则就是为了解决这些问题的。
LSM(Log-Structured Merge Tree, 结构化的日志合并树)核心的解决方案是: 通过【顺序写】替代【随机写】,最小化的控制碎片的产生,提升数据密度。
而且【顺序写】也是对【硬盘】特别是【HDD(机械硬盘)】更加友好的使用方式。
LSM-Tree 的提出: 1篇经典论文
LSM Tree(Log-Structured Merge Tree)的概念最早由Patrick O'Neil等人在1996年的经典论文《The Log-Structured Merge-Tree (LSM-Tree)》中提出。这篇论文在数据库存储领域 具有里程碑意义,为现代NoSQL/NewSQL数据库和分布式存储系统奠定了重要的理论基础。
核心思想
LSM Tree的核心思想是将【随机写入】转换为【顺序写入】,从而充分利用【磁盘】的【顺序访问性能优势】。传统的
B+Tree结构在处理大量【写入操作】时,由于需要维护树结构的【平衡性】,往往产生大量的【随机 I/O 操作】,导致【性能瓶颈】。
LSM Tree 通过以下设计解决了这个问题:
- 分层存储架构:将数据分为内存层(C₀)和磁盘层(C₁),新数据首先写入内存,然后批量刷写到磁盘
- 顺序写入优化:所有磁盘写入都是顺序的,避免了随机 I/O 的性能损失
- Rolling Merge (滚动)算法:通过后台的合并过程,将小文件逐步【合并】为大文件,保持数据的有序性
理论创新
- 论文的主要理论贡献包括:
- 性能分析模型 :提供了
LSM Tree与B+Tree的数学性能对比模型- 写入成本分析:
• B+Tree 写入成本:O(log_B N) 次随机 I/O
• LSM Tree 写入成本:O(1) 次顺序 I/O + 后台合并成本
Rolling Merge算法:设计了高效的多路归并算法,确保数据的有序性和查询效率
历史影响
- 这篇论文的影响深远,为后来的许多知名系统提供了理论基础:
- BigTable:Google 的分布式存储系统,采用了 LSM Tree 的核心思想
- LevelDB/RocksDB:广泛使用的嵌入式存储引擎
- Cassandra、HBase:流行的 NoSQL 数据库系统
- 现代时序数据库:如 InfluxDB、TimescaleDB 等
LSM-Tree 的工作原理与执行流程
- 在
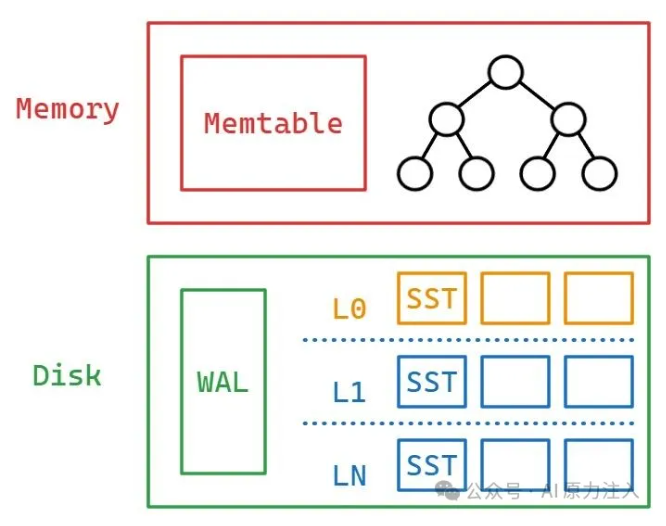
LSM-tree有3个部分:
- Memtable:Memory Mutable Table = 内存可变表
- SSTable:Sorted String Table = 有序字符串表
- WAL:Write-Ahead Log = 预写日志
而其执行流程也并不是那么的复杂晦涩,基本上下边这一张图就可以够清楚。
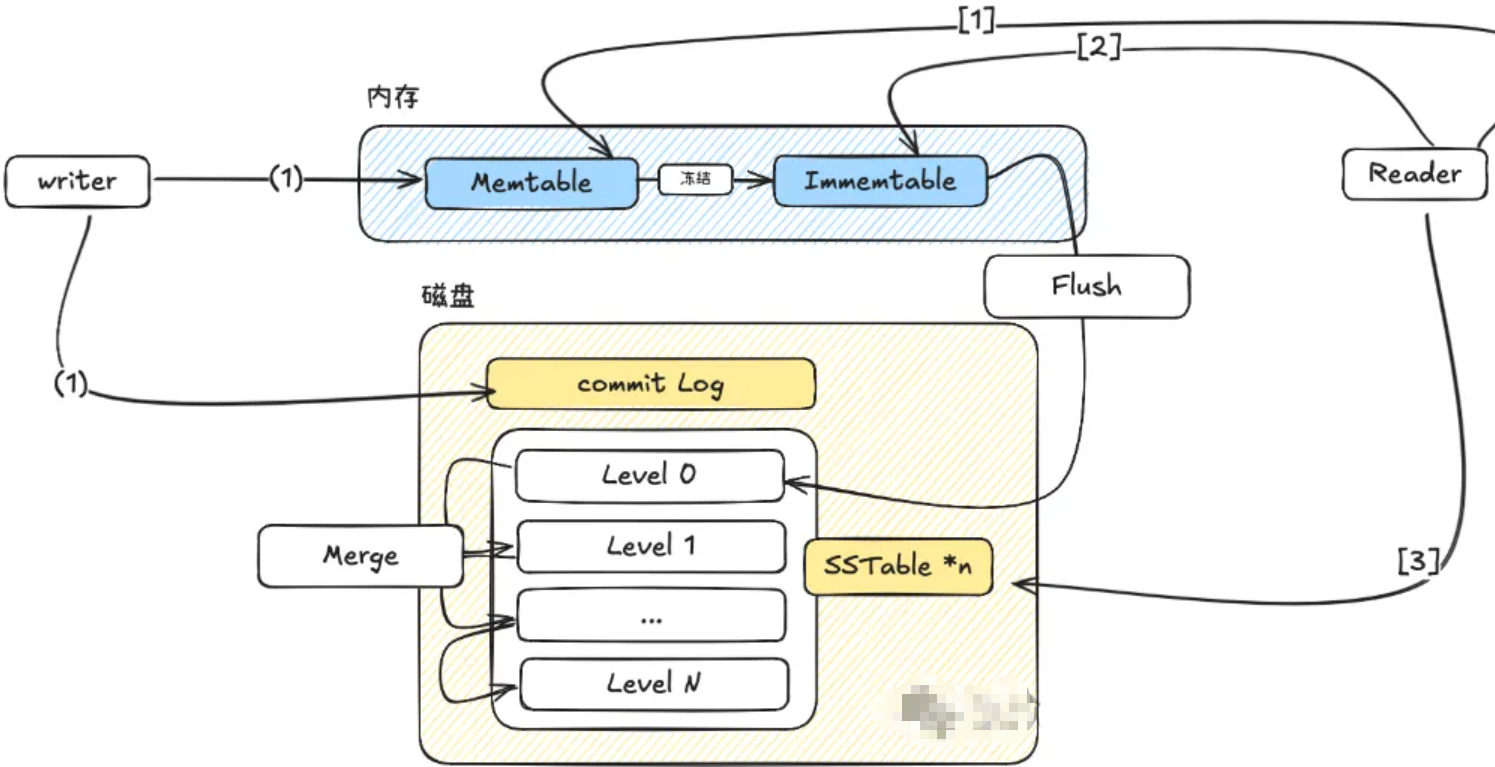
LSM tree的数据落在内存和硬盘上。因地制宜,【内存】进行速度快但易失,【硬盘】慢速但可以持久。
- 【内存部分】:分为
MemTable和Immutable Memtable,而最大区别其实就是字面意思的【可变】和【不可变】。- 【磁盘部分】**是
level based的SSTable。而其设计核心思想就是序列 ,
SSTable内部是顺序存放 ,多个 SSTable 也是如此,Level越小表示这数据越新。而
commit log,换个名字大家应该更加熟悉就是WAL(Write-Ahead Log)。当数据写入
Memtable的同时,也会写到WAL中。虽然都是顺序写入 的而且是【同时写入】的,但是一个位于内存 ,一个则是位于磁盘。
简单来讲,此组件就是Design for crash的,当系统崩溃重启 的时候进行重放操作 ,使得Memtable和Immemtable中没有持久化到磁盘的数据不会丢失,这个基本都是各个数据库的基操了。
- 【系统内部执行的操作】主要是2个 Flush 和 Merge。
【数据的流动方向】是从
MemTable写满到Immemtable,然后 Flush 到【磁盘】中的SSTable; 而多个SSTable数量达到某一个阈值之后会Merge成下一级的SSTable。
写操作 : In-Place(本地更新) / Out-of-Place(异地更新) / 数据记录版本标记(version) / RUM 三角理论
-
一般来讲,写操作的套路有两个,
In-place和out-of-place,分别是【本地更新】和【异地更新】。 -
B-tree数据是in-place,更新数据的时候直接就回去修改原始的记录。
- 优点
这样做的好处 就是可以提供很高的【查询效率】 ;而且直接本地写不会占用其他的**【存储空间】** ,所以**【空间利用率】**高。
- 缺点
但是【写放大 】的问题也是同时出现的,每一次你需要找到这条数据,然后进行更新,所以每一次都会有一次
IO,而且是随机 的,这样就会导致写操作变慢。
LSM-tree,相反,就是out-of-place,【异地更新】的,说白了就是不会修改源文件、源记录。
修改的和新的数据都会放到新的空间,结合
version标签表示出这个是新的值。这样做就不会有【随机 IO】 的出现。所以就提供了更好的【写效率】。
但是代价就是【度放大】和【空间放大】。
- 这几个放大也不是笔者杜撰的,是有一个理论支撑的叫做
RUM。而且和CAP一样,也是一个三角关系。
也就是说
Read Overhead(读放大)/Update Overhead(写放大)和Storage Overhead(空间放大)这三个只能满足两项。所以两种方式,换句话说就是你要读友好还是写友好。
在LSM中,MemTable的CUD三种操作写操作过程都是CT上是一致的,无非就是插入一条数据。而且它位于【内存】且大小一般控制在一个非常小的范围(大多是64KB)所以是一个非常快的过程。
当真的写满了之后,就会转变成
Immemtable。通过另外的现成进行 flush 到【硬盘】完成持久化,同时对应的
commit log(WAL) 就会被删除了。
所以,稳定且快速的写入是 LSM-tree 的【最大特点】。
读操作
- 读数据 ,其实一个重要的工作是查找到数据的位置。
从写入的方式 我们可以看出来,如果一条数据被更新了多次,那么它可能会位于不同的
SSTable甚至是Memtable中 。而最新版本的数据 才是有用的,所以这个现象也就是上边说的【空间放大】,一条数据存储了【不同版本】或者说【不同的副本】,而【老的版本】其实已经过时了。
而【空间放大】之后,
LSM-tree中其实是按照从新到旧的顺序进行查找 的,命中之后 才会结束整个的查找流程。
- 具体的顺序是:
- 先从
Memtable找,miss 了到Immemtable中,miss 之后从最低到最高,一个 level 一个 level 的从SSTable中查找。- 而当涉及到
SSTable的时候,也不会把整个SSTable导入到【内存】中,而是把SSTable的元数据 放进去,然后通过Bloom filter快速确定这个SSTable是不是存在这条数据。如果存在的话,才会通过二分法 的方式确定数据在这个
SSTable的哪个block中,然后再将这个Block的数据记录放到【内存】中进行查找。由于这种查找方式,【读放大】也产生了。
- 不同的
LSM-tree实现的数据库有着不同的解决方案,所以,也有一些为这个问题提出的解决方案,我把他叫做 【3C】:
Compression(压缩) :这个是最直观的方法,通过压缩 减少容量。Cache(缓存) : 因为SSTable是不变的,如果想要提高性能的话,我们可以把它放到内存中缓存。Compaction(合并) : 也就是将多个SSTable合并成一个,删除一些重复的数据或者已经删除的数据,这样空间也可以降下来。而你也会发现【合并】也是贯穿着
LSM-tree最终落地的关键一环。
合并操作
- 而以上所讲的
Compaction其实是属于Leveled Compaction。
精确一点讲,就是合并 之后的下一级
SST文件 兼职范围互不重叠且内部有序,这样便于做【二分查找】。还有一种合并的方式叫做
Tiered Compaction,虽然也是当某一层累计的数据超过【预设的阈值】之后进行【合并】,但是不会像Leveled一样进行精确的键值操作 。所以,【合并效率】更加高。
- 2种合并的方式,一般都是在系统中同时给到用户选择的。
Leveled主要应对的是【度要求高】且【空间敏感】的情景。因为做了旧版本清除,避免了大量【冗余数据】,在一定程度上缓解了【空间放大】的问题,但是【合并操作复杂】,对【系统资源压力】较大。- 而
Tiered则是适合【写入密集型】的场景,因为合并的时候【不严格去重】。所以,当用户查询的时候可能会访问多个文件,【读性能】就没有那么好,而且【空间冗余度】高,长期以往会造成【数据碎片化】。简单来说,就是读密集 ,选
Leveled;写密集 就选Tiered。
无银弹
LSM-tree的优势 ,其实同时也是它的劣势,整个系统都建立在【后台合并】这个关键任务上。
这有点像现在的消费观,早享受后痛苦,先消费后还款。
虽然短期你可以获得极致的写效率 ,但是【后边合并】的时候你会面临着后期复杂的操作 ,在
flush和Compaction发生的时候,压力一下子就上来了,【控制性能的抖动】是一个很大的挑战。
- 合并操作 带来
CPU、IO和内存 的【瞬时飙升】,会让你系统的响应时间短时间内骤增,而且时间窗口是我们很难去控制的。
而针对一些时效性很强的操作 更加致命,比如说银行的对账,因为业务的特殊性,必须限时完成,而如果真的出现抖动,甚至是业务休克,那将是灾难。
- 按照【写频率】我们可以分为三级:
- 纯读:这类的话影响比较小。
- 低频写 ,可以停业的服务:我们可以规划一个维护窗口,在窗口下集中合并
- 高频读写,无窗口:这类业务基本就是一不小心就"炸号"了,犹如悬岩边开车。
除此之外,SSD寿命 也是一个很大的问题,因为Compaction会造成大量的"额外"写入操作 ,就会增加硬件更换的成本。
所以,对于SRE团队来讲,能不能实施监控归并 ,提前预测 将要来临的【性能抖动】,能不能【手动绑定执行计划】,【快速修复】可能出现的慢SQL,这些是很大的挑战。
整体架构设计
- LSM Tree 采用分层存储架构,将数据按照【访问频率】和【时间特征】进行【分层管理】:
txt
写入优化策略:
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ 随机写入请求 │───→│ 内存缓冲区 │───→│ 顺序刷盘 │
│ │ │ (MemTable) │ │ (SSTable) │
│ 用户写入操作 │ │ 内存中排序存储 │ │ 磁盘顺序写入 │
└─────────────────┘ └─────────────────┘ └─────────────────┘分层存储架构设计
- LSM Tree 采用分层存储架构,每一层都有明确的设计目标:
txt
┌─────────────────────────────────────────────────────────────┐
│ 内存层 (Memory Layer) │
│ ┌─────────────────┐ ┌──────────────────┐ │
│ │ Active MemTable │ │Immutable MemTable│ │
│ │ (可写) │ │ (只读) │ │
│ │ 64MB 阈值 │ │ 等待刷盘 │ │
│ └─────────────────┘ └──────────────────┘ │
└─────────────────────────────────────────────────────────────┘
│
▼ 刷盘操作
┌─────────────────────────────────────────────────────────────┐
│ 磁盘层 (Disk Layer) │
│ │
│ Level 0: ┌──────┐ ┌──────┐ ┌──────┐ ┌──────┐ │
│ │SST-1 │ │SST-2 │ │SST-3 │ │SST-4 │ (可重叠) │
│ └──────┘ └──────┘ └──────┘ └──────┘ │
│ │ │
│ ▼ Compaction │
│ Level 1: ┌──────┐ ┌──────┐ ┌──────┐ │
│ │SST-5 │ │SST-6 │ │SST-7 │ (无重叠) │
│ └──────┘ └──────┘ └──────┘ │
│ │ │
│ ▼ Compaction │
│ Level 2: ┌──────┐ ┌──────┐ │
│ │SST-8 │ │SST-9 │ (无重叠,更大) │
│ └──────┘ └──────┘ │
└─────────────────────────────────────────────────────────────┘LSM Tree 整体系统架构
- 为了更好地理解 LSM Tree 各组件之间的协作关系,下面展示完整的系统架构图:
txt
┌─────────────────────────────────────────────────────────────────────────────────┐
│ LSM Tree 整体系统架构 │
│ │
│ ┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐ │
│ │ 客户端接口 │ │ 读写协调器 │ │ 版本管理器 │ │
│ │ ┌─────────────┐ │ │ ┌─────────────┐ │ │ ┌─────────────┐ │ │
│ │ │ PUT/GET/DEL │ │ │ │ 读写路由 │ │ │ │ MVCC 控制 │ │ │
│ │ │ 批量操作 │ │ │ │ 并发控制 │ │ │ │ 快照管理 │ │ │
│ │ │ 范围查询 │ │ │ │ 一致性保证 │ │ │ │ 事务支持 │ │ │
│ │ └─────────────┘ │ │ └─────────────┘ │ │ └─────────────┘ │ │
│ └─────────────────┘ └─────────────────┘ └─────────────────┘ │
│ │ │ │ │
│ └───────────────────────┼───────────────────────┘ │
│ │ │
│ ┌────────────────────────────────┼────────────────────────────────────────┐ │
│ │ 核心存储引擎 │ │ │
│ │ ▼ │ │
│ │ ┌─────────────────────────────────────────────────────────────────┐ │ │
│ │ │ 内存层 (Memory Layer) │ │ │
│ │ │ │ │ │
│ │ │ ┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐ │ │ │
│ │ │ │ Active MemTable │ │Immutable MemTable│ │ WAL日志(磁盘) │ │ │ │
│ │ │ │ ┌─────────────┐ │ │ ┌─────────────┐ │ │ ┌─────────────┐ │ │ │ │
│ │ │ │ │ SkipList │ │ │ │ SkipList │ │ │ │ 顺序日志 │ │ │ │ │
│ │ │ │ │ 64MB 阈值 │ │ │ │ 等待刷盘 │ │ │ │ 持久化保证 │ │ │ │ │
│ │ │ │ │ 可读写 │ │ │ │ 只读状态 │ │ │ │ 崩溃恢复 │ │ │ │ │
│ │ │ │ └─────────────┘ │ │ └─────────────┘ │ │ └─────────────┘ │ │ │ │
│ │ │ └─────────────────┘ └─────────────────┘ └─────────────────┘ │ │ │
│ │ └─────────────────────────────────────────────────────────────────┘ │ │
│ │ │ │ │
│ │ ▼ 刷盘操作 (Flush) │ │
│ │ ┌─────────────────────────────────────────────────────────────────┐ │ │
│ │ │ 磁盘层 (Disk Layer) │ │ │
│ │ │ │ │ │
│ │ │ Level 0: ┌──────┐ ┌──────┐ ┌──────┐ ┌──────┐ │ │ │
│ │ │ │SST-1 │ │SST-2 │ │SST-3 │ │SST-4 │ (可重叠) │ │ │
│ │ │ │+BF │ │+BF │ │+BF │ │+BF │ │ │ │
│ │ │ └──────┘ └──────┘ └──────┘ └──────┘ │ │ │
│ │ │ │ │ │ │
│ │ │ ▼ Compaction │ │ │
│ │ │ Level 1: ┌──────┐ ┌──────┐ ┌──────┐ │ │ │
│ │ │ │SST-5 │ │SST-6 │ │SST-7 │ (无重叠) │ │ │
│ │ │ │+BF │ │+BF │ │+BF │ │ │ │
│ │ │ └──────┘ └──────┘ └──────┘ │ │ │
│ │ │ │ │ │ │
│ │ │ ▼ Compaction │ │ │
│ │ │ Level 2: ┌──────┐ ┌──────┐ │ │ │
│ │ │ │SST-8 │ │SST-9 │ (无重叠,更大) │ │ │
│ │ │ │+BF │ │+BF │ │ │ │
│ │ │ └──────┘ └──────┘ │ │ │
│ │ │ │ │ │
│ │ │ 注:BF = Bloom Filter,每个 SSTable 都包含布隆过滤器 │ │ │
│ │ └─────────────────────────────────────────────────────────────────┘ │ │
│ └────────────────────────────────────────────────────────────────────────┘ │
│ │
│ ┌─────────────────────────────────────────────────────────────────────────┐ │
│ │ 后台服务层 (Background Services) │ │
│ │ │ │
│ │ ┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐ │ │
│ │ │ Compaction 引擎 │ │ 监控诊断 │ │ 资源管理 │ │ │
│ │ │ ┌─────────────┐ │ │ ┌─────────────┐ │ │ ┌─────────────┐ │ │ │
│ │ │ │ 触发策略 │ │ │ │ 性能指标 │ │ │ │ 内存控制 │ │ │ │
│ │ │ │ 调度算法 │ │ │ │ 健康检查 │ │ │ │ I/O 限流 │ │ │ │
│ │ │ │ 并发控制 │ │ │ │ 告警机制 │ │ │ │ 线程池管理 │ │ │ │
│ │ │ └─────────────┘ │ │ └─────────────┘ │ │ └─────────────┘ │ │ │
│ │ └─────────────────┘ └─────────────────┘ └─────────────────┘ │ │
│ └─────────────────────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────────────────────┘基于 LSM-Tree 构建的数据库系统
- DynamoDB
- RocksDB
- TiDB
- OceanBase
- RisingWave
- InfluxDB / OpenGemini : 借鉴了 LSM-Tree 的设计思想,自研了 TSM-Tree
Z FAQ for LSM-Tree
Q: InfluxDB 的数据库存储引擎 TSM 是否借鉴了 LSM-Tree 的设计?二者有何区别?
- 结论:
TSM(Time-Structured Merge Tree)存储引擎明确借鉴了LSM-Tree(日志结构合并树 )的核心设计思想,但针对时序数据的特性 做了深度定制优化,并非简单复用LSM-Tree通用架构。
二者的核心关联是 "日志 + 分层合并存储 ",核心差异是
TSM为时序场景(高写入、高查询、时间有序、标签维度)做了针对性设计。
TSM 对 LSM-Tree 核心思想的借鉴
LSM-Tree 的核心设计是"牺牲部分读性能,换取极高的写入吞吐量",其核心逻辑是:
- 写入数据先写日志(WAL)保证持久化,再写入内存中的有序结构(MemTable);
- 内存结构达到阈值后,异步刷盘为不可变的磁盘文件(SSTable);
- 后台线程对磁盘文件进行分层合并(Compaction),减少查询时的文件扫描次数。
TSM(Time-Structured Merge Tree)作为 InfluxDB 的核心存储引擎,完全继承了这一"日志+内存+分层合并"的核心框架,具体对应关系:
| LSM-Tree 核心组件 | TSM 引擎对应组件 | 作用一致点 |
|---|---|---|
| WAL(Write-Ahead Log) | WAL(Write-Ahead Log) | 写入前先落盘,防止内存数据丢失,保证崩溃恢复 |
| MemTable | TSM MemTable | 内存中有序存储数据,支持快速写入和查询 |
| SSTable(Sorted String Table) | TSM File | 内存刷盘后的不可变磁盘文件,按关键维度排序 |
| Compaction | TSM Compaction | 合并小文件为大文件,消除冗余数据,优化查询效率 |
可以说,TSM 的"骨架"完全基于 LSM-Tree 的设计思想------通过"内存缓冲+异步刷盘+后台合并"解决时序数据的"高写入"痛点(时序场景中写入通常是读的10~100倍,且写入顺序基本按时间递增)。
TSM 与通用 LSM-Tree 的核心区别(时序场景定制)
通用 LSM-Tree(如 LevelDB、RocksDB 所用)面向"key-value 通用存储",而 TSM 面向"时序数据"(结构为:measurement + tags → 时间序列(TS)→ 时间戳+字段值),因此在数据模型、排序方式、文件结构、合并策略、查询优化等层面做了深度定制,核心差异如下:
1. 数据模型与排序键:从"单一key"到"时序维度键"
- 通用 LSM-Tree :排序键是单一的
key(如字符串、字节数组),数据模型是扁平的 key-value 对,不感知数据语义; - TSM :排序键是"时序复合键 ",即
(measurement, tags, field) → 时间戳,核心特点:- 先按"measurement+tags+field"分组(对应一条唯一的时间序列 TS);
- 同一条 TS 内部按"时间戳"递增排序。
这一设计完全匹配时序数据的查询场景(通常按"标签过滤+时间范围"查询,而非随机 key 查询)。
2. 文件结构:按时间序列"垂直分区",优化时序查询
通用 LSM-Tree 的 SSTable 是"水平存储"------不同 key 的数据混合存储在同一个文件中,查询时需扫描文件中的 key 范围;而 TSM File 是"垂直分区+时间分片"的混合结构:
- TSM File 结构 :
- 每个 TSM File 只存储"部分时间序列"的"一段连续时间范围"数据(如某100条 TS 的2025-11-01至2025-11-02数据);
- 文件内部分为:索引区(记录 TS 对应的时间范围和数据偏移)、数据区(按 TS 分组存储,同 TS 的时间戳+字段值紧凑排列)。
- 优势:查询时先通过"标签过滤"定位目标 TS,再通过时间范围定位对应的 TSM File,无需扫描无关文件和无关 TS 的数据,查询效率比通用 LSM-Tree 高一个量级(尤其适合多维度标签过滤+时间范围查询)。
3. 压缩策略:时序数据专属压缩,比通用压缩更高效
时序数据的特点是"同一条 TS 的时间戳递增、字段值可能有连续性"(如温度、CPU 使用率),TSM 针对性设计了压缩算法:
- 时间戳压缩:存储时间戳的"差值"(如前一个时间戳是1630000000,下一个是1630000001,仅存1),而非完整时间戳;
- 字段值压缩:根据字段类型(数值、字符串)选择不同算法(如数值用 Delta+RLE 压缩,重复值仅存计数);
- 通用 LSM-Tree:压缩算法是通用的(如 Snappy、LZ4),不感知时序数据的语义,压缩比和效率远低于 TSM(TSM 压缩比通常是通用 LSM-Tree 的2~5倍)。
4. 合并策略(Compaction):按"时间+TS 分组"合并,而非仅按 key 范围
通用 LSM-Tree 的 Compaction 是"按 key 范围分层合并"(如 LevelDB 的 Level 0 到 Level 1 按 key 有序合并),目的是减少查询时的文件扫描层数;而 TSM 的 Compaction 有两个核心目标:
- 合并同 TS 的分散数据:将同一条 TS 分散在多个小 TSM File 中的数据合并为一个大文件,减少查询时的文件 IO;
- 清理过期数据:时序数据通常有 TTL(如保留7天),Compaction 时直接删除过期数据,无需额外的删除操作;
- 差异:TSM 的 Compaction 不依赖"分层",而是基于"TS 分组+时间范围"的主动合并,更贴合时序数据的生命周期管理。
5. 写入优化:针对"时间递增+批量写入"场景,写入吞吐量更高
时序数据的写入通常是"批量、时间递增、多 TS 并发写入"(如采集器每秒批量上报上千条 TS 的数据),TSM 做了两点关键优化:
- 内存 MemTable 按 TS 分组存储:写入时先按"measurement+tags+field"哈希到对应的 MemTable 分区,避免内存中数据无序;
- 批量刷盘:MemTable 满后,按 TS 分组批量刷盘为 TSM File,而非单条刷盘,减少磁盘 IO 次数;
- 通用 LSM-Tree:写入是"单条 key-value 写入 MemTable",批量写入效率低,且无法利用时序数据的"时间递增"特性优化。
总结:TSM 是"LSM-Tree 思想+时序场景定制"的产物
| 对比维度 | 通用 LSM-Tree(如 LevelDB/RocksDB) | TSM 引擎(InfluxDB) |
|---|---|---|
| 设计目标 | 通用 key-value 存储,均衡读写 | 时序数据存储,优化高写入+高查询(标签+时间范围) |
| 数据模型 | 扁平 key-value 对 | measurement+tags → TS → 时间戳+字段值 |
| 排序键 | 单一 key | (measurement, tags, field) + 时间戳 |
| 文件结构 | 水平存储,混合不同 key 数据 | 垂直分区,按 TS+时间范围分组存储 |
| 压缩策略 | 通用压缩(Snappy/LZ4) | 时序专属压缩(时间戳 Delta+字段值 RLE) |
| Compaction 目的 | 减少查询层数,消除冗余 key | 合并同 TS 数据+清理过期数据 |
| 核心优势 | 通用性强,支持随机读写 | 写入吞吐量高、查询(标签+时间)快、压缩比高 |
| 适用场景 | 通用存储(如缓存、配置存储) | 时序数据(监控、日志、IoT 采集) |
TSM 借了 LSM-Tree"日志+内存+合并"的"壳",但为时序数据重新设计了"核"------从数据模型、文件结构到压缩、合并策略,全流程贴合时序场景的特性,因此比通用 LSM-Tree 更适合存储和查询时序数据。
Y 推荐文献
- 《The Log-Structured Merge-Tree》 (经典论文)
O'Neil, P., Cheng, E., Gawlick, D., & O'Neil, E. (1996). The log-structured merge-tree (LSM-tree). Acta Informatica, 33(4), 351-385.
- 《Bigtable: A distributed storage system for structured data》 (经典论文)
Chang, F., Dean, J., Ghemawat, S., Hsieh, W. C., Wallach, D. A., Burrows, M., ... & Gruber, R. E. (2008). Bigtable: A distributed storage system for structured data. ACM Transactions on Computer Systems, 26(2), 1-26.
X 参考文献
https://github.com/brianxiadong/java-lsm-tree
含: 1. LSM Tree 经典论文简介 / 2. LSM Tree 核心原理与组件实现 / 3. LSM Tree 操作流程详解
含: SSTable(Sorted String Table) 文件格式设计 / WAL (Write-Ahead Log) 机制 / Compaction 合并策略 /