Linux 的 Namespace、CGroups 和 UnionFS 三大技术支撑了 Docker 的实现。
在 Linux 系统中,namespace 是在内核级别以一种抽象的形式来封装系统资源的,通过将系统资
源放在不同的 namespace 中,来实现资源隔离的目的。设置了不同 namespace 的程序,就可以
享有彼此独立的一份系统资源。
Linux 中当前可用的命名空间如下:
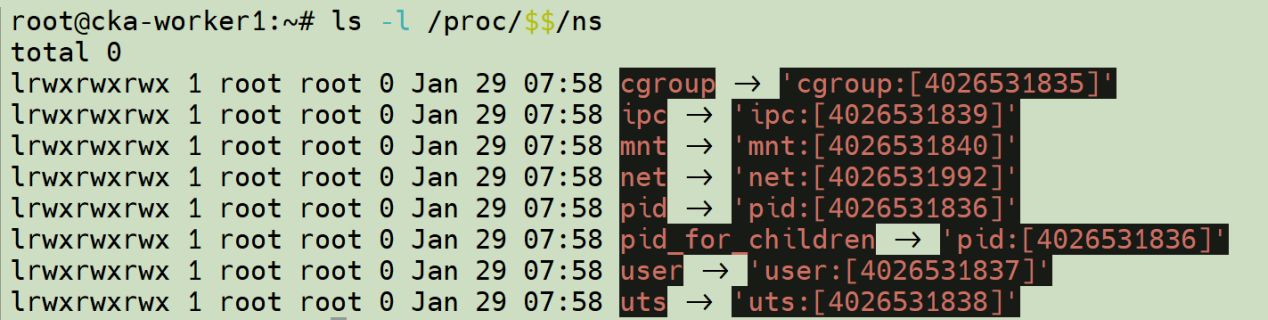
当前系统使用到的命名空间有,cgroupns:隔离 CGroup 视图。ipcns: 隔离进程间通信资源。
mntns: 隔离文件系统挂载点。netns: 隔离网络资源。pid ns: 隔离进程 ID。user ns: 隔离用户
和用户组 ID。uts ns: 隔离主机名和域名。pid_for_children: 当前进程的子进程将继承的 PID ns。
下面通过从非管理账户 user1 的角度来具体理解命名空间的工作原理。
首先配置 user1 用户的 sudo 免密,并添加 dockers 组,这组操作请自行完成。
以 user1 用户登录新的会话,运行一个名字 conns 的 alpine 容器

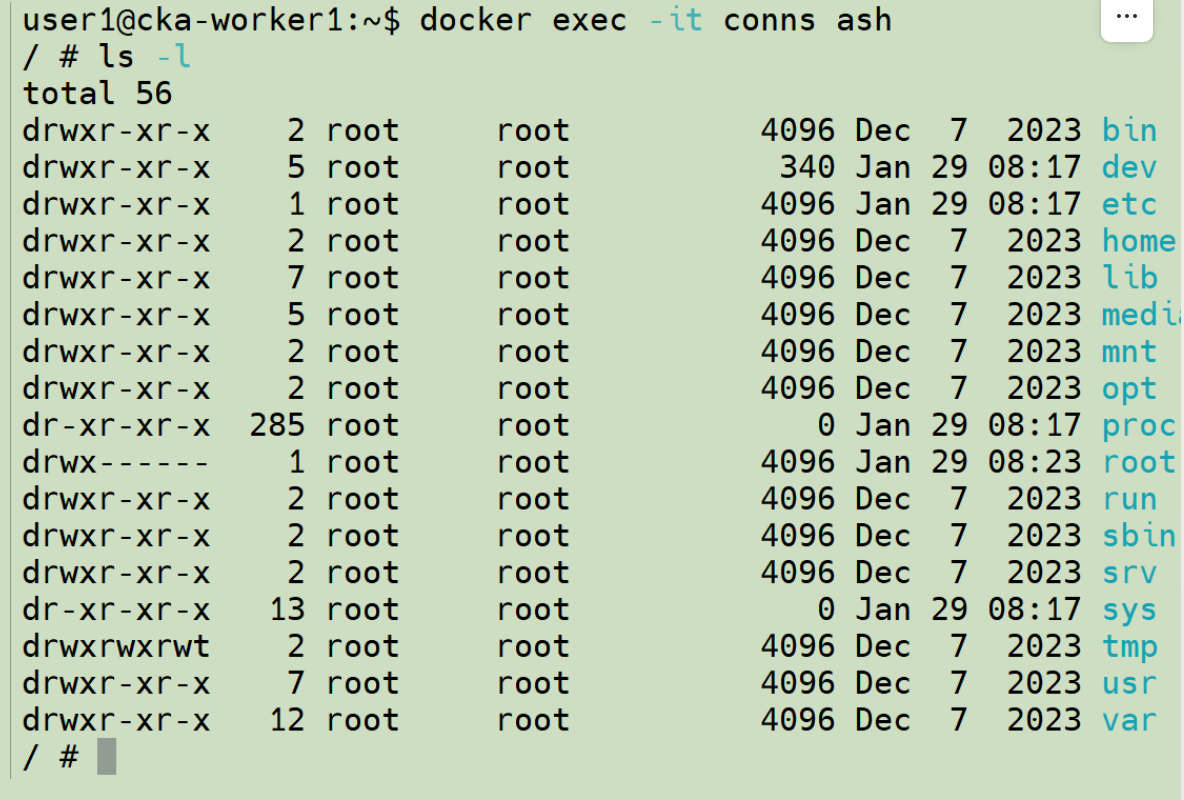
我们知道,conns 容器包含有一个精简但完整的文件系统:
将 conns 容器的文件系统导出,在当前目录创建一个 rootfs 目录,并将导出的 conns 文件系统解压到这个目录:

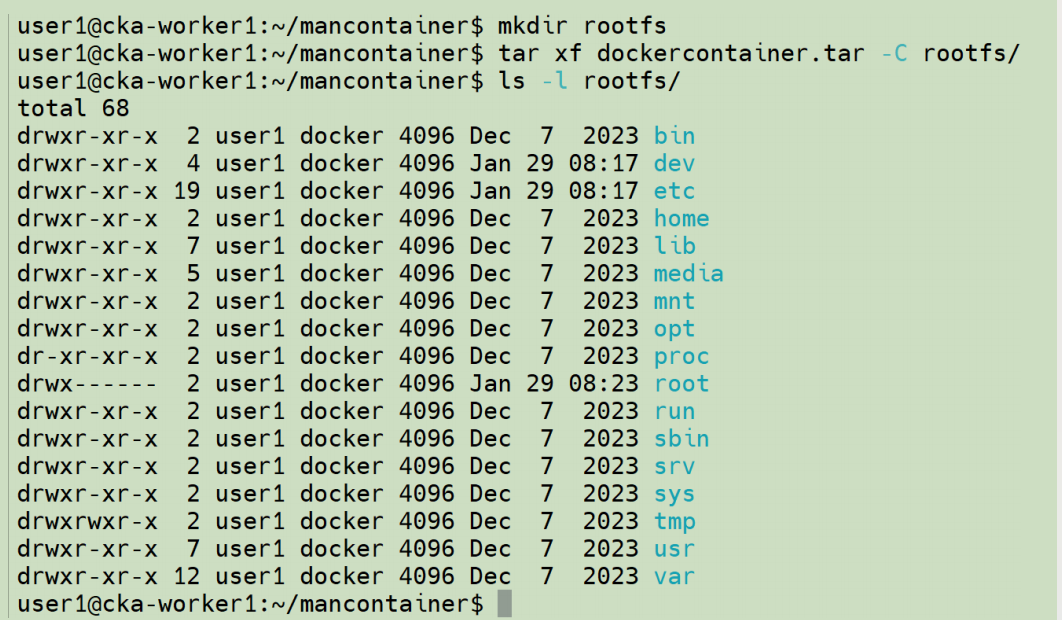
这么做的目的就是要手工创建一个资源隔离的类似容器对象。
接下来使用 chroot 命令把当前 shell 的 root 切换到刚创建的文件系统。
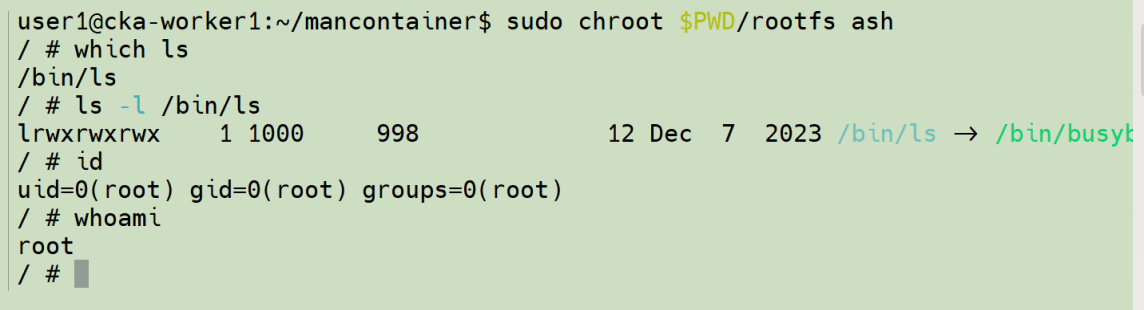
好了,新的文件系统好像是独立的 root 文件系统,但是看 ip link 命令显示的网络信息:
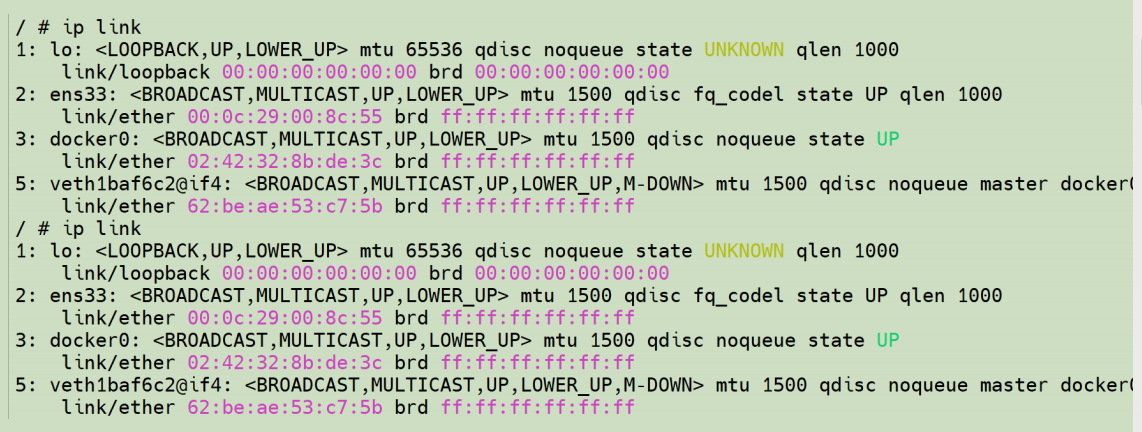
再看系统进程信息:
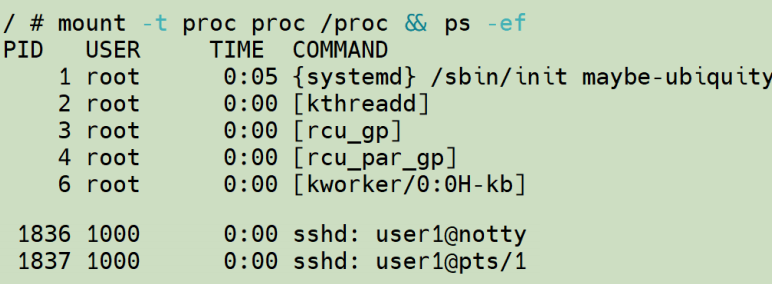
可以发现,除了挂载点之外的网络、进程等资源在"模拟容器"中都能看到,这些资源没有隔离
回到 user1 用户,使用 unshare 命令隔离出一组新的命名空间集合。unshare 命令用于创建一个
新 ns 集合,并在其中启动一个 Bash shell,实现资源隔离,这是 Linux 容器技术的基础之
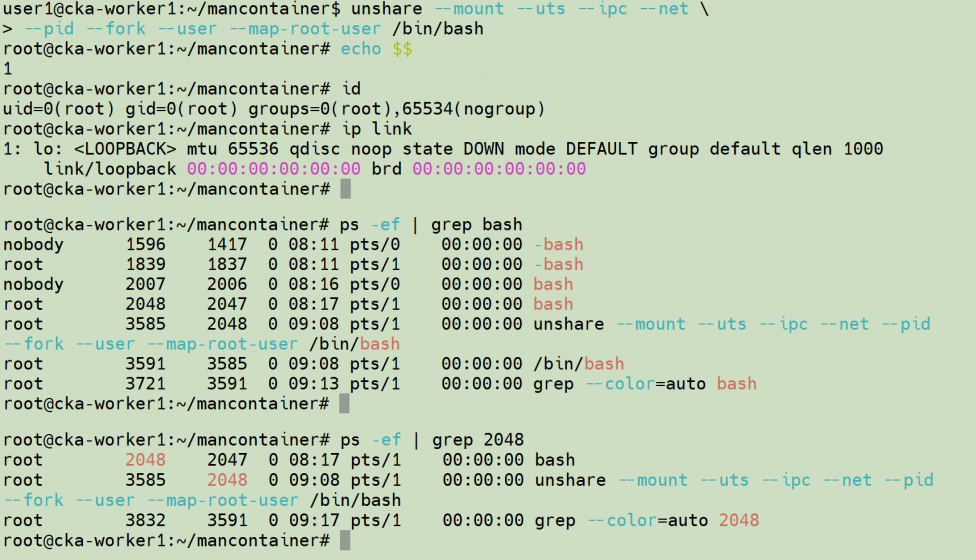
特别要说明的是,如果此时我们在其他终端上检查主机中的进程时,会看到,即使上面的用户 root, 在进程之外,也是在普通用户 user1 的凭据下执行的:
unshare --map-root-user 创建了一个新的 User 命名空间 ,将容器内的 root 映射到主机上的普通用户 user1。因此,主机看到的进程凭据是映射后的 user1,而非真实的 root。

回到"模拟容器"环境,如果想要显示当前正在运行的进程,结果先显示的是主机中的所有进程:
因为,ps 命令依赖 /proc 文件系统获取进程信息。默认情况下,新创建的 PID 命名空间并未挂载独立的 /proc ,因此仍读取主机全局的 /proc,导致看到所有进程。因此需要将 procfs 虚拟文件系统挂载到 当前的/proc 目录,就可在新的 PID 命名空间中实现进程的隔离:
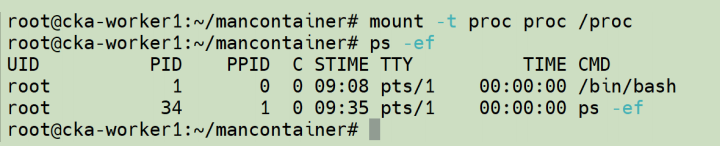
继续,我们在容器外部创建一个网络设备并将其放入命名空间:
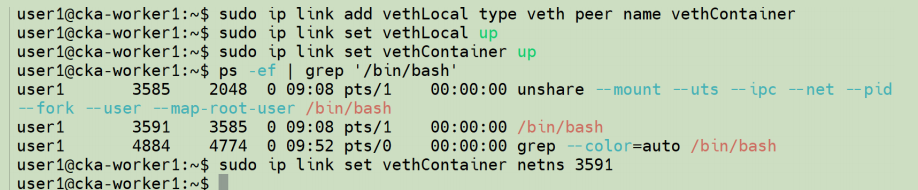
回到"模拟容器"环境,会看到有一个新的网络设备出现了:

【docker】namespace 命名空间
小白不想白a2025-08-07 23:09
相关推荐
编程序的员19 分钟前
使用OpenTelemetry来监控GoLang应用羑悻的小杀马特1 小时前
把随身WiFi改成网盘聚合器:中兴F50挂载本地存储+夸克网盘实战Yana.nice9 小时前
Linux 只保留 30 天内日志(find命令删除日志文件)2601_9605679612 小时前
电商套图自动化效率的工程量化分析——从逐张生成到批量套图的架构演进吳所畏惧13 小时前
宝塔面板Redis密码修改指南:SSH命令修改 vs 面板UI界面修改,哪个更靠谱?张忠琳13 小时前
【NVIDIA】 NVIDIA Container Toolkit v1.19.1 — OCI 模块超深度分析之三HiDev_13 小时前
【非标自动化】2、认识元器件(确定目标)Zhang~Ling14 小时前
从 fopen 到 struct file:从零开始拆解 Linux 文件 I/O爱写代码的森14 小时前
蒙三方库 | harmony-utils之FileUtil文件重命名与属性查询详解Elastic 中国社区官方博客15 小时前
将你的 Grafana Kubernetes 仪表板迁移到 Elastic Observability:相同的 PromQL,30 倍更快的查询