java 面试八股这一篇就够之java集合篇
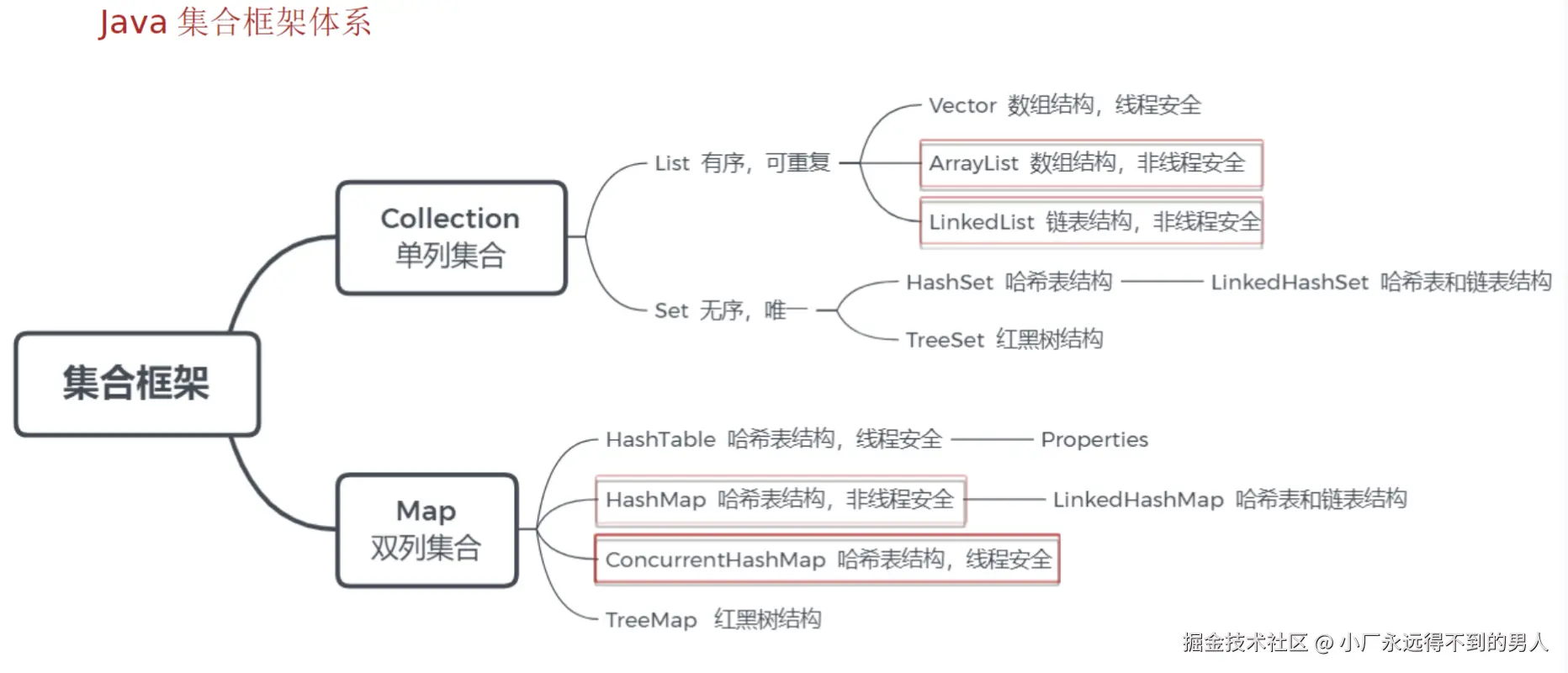
常见集合是每次面试必考的面试题,下面我们先进行梳理一下java集合框架:
问1: ArrayList 底层的实现原理是什么?
-
ArrayList 底层是用动态的数组实现的
-
ArrayList 初始容量为 0,当第一次添加数据的时候才会初始化容量为 10
-
ArrayList 在进行扩容的时候是原来容量的 1.5 倍,每次扩容都需要拷贝数组
-
ArrayList 在添加数据的时候
- 确保数组已被初始化(size != 0)之后还要看下一个数据
- 计算新的容量,如果当前数组已使用长度 + 1 后的值大于当前的数组长度,则调用 grow 方法扩容(原来的 1.5 倍)
- 准备好新的数组或者在原数组之后,将新元素添加到 size++ 的位置上。
- 这同时也是线程不安全。
- 返回添加成功布尔值。
问2:ArrayList list=new ArrayList (10) 中的 list 扩容几次?
/**
-
构造一个具有指定初始容量的空列表。
-
参数:initialCapacity - 列表的初始容量
-
抛出:IllegalArgumentException - 如果指定的初始容量为负
*/
public ArrayList (int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object initialCapacity;
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException ("Illegal Capacity:"+
initialCapacity);
}
}
参考回答:
该语句只是声明和实例了一个 ArrayList,指定了容量为 10,未扩容,这次使用的是有参构造,直接指定了容量,所以是没有扩容。
问3:如何实现数组和list相互转换?
- 数组转 List ,使用 JDK 中 java.util.Arrays 工具类的 asList 方法
- List 转数组,使用 List 的 toArray 方法。无参 toArray 方法返回 Object 数组,传入初始化长度的数组对象,返回该对象数组
实现源码:

面试官再问:
用 Arrays.asList 转 List 后,如果修改了数组内容, list 受影响吗
答:
Arrays.asList 转换 list 之后,如果修改了数组的内容, list 会受影 响,因为它的底层使用的 Arrays 类中的一个内部类 ArrayList 来构造的集合,在这个集合的构造器中,把我们传入的这个集合进行了包装而已,最终指向的都是同一个内存地址。
List 用 toArray 转数组后,如果修改了 List 内容,数组受影响吗?
答:
list 用了 toArray 转数组后,如果修改了 list 内容,数组不会影 响,当调用了 toArray 以后,在底层是它是进行了数组的拷贝,跟 原来的元素就没啥关系了,所以即使 list 修改了以后,数组也不受 影响
问4:ArrayList 和 LinkedList 的区别是什么?
1. 底层数据结构
- ArrayList 是动态数组的数据结构实现
- LinkedList 是双向链表的数据结构实现
2. 操作数据效率
- ArrayList 按照下标查询的时间复杂度 O(1) 【内存是连续的,根据寻址公式】, LinkedList 不支持下标查询
- 查找(未知索引): ArrayList 需要遍历,链表也需要链表,时间复杂度都是 O(n)
- 新增和删除
- ArrayList 尾部插入和删除,时间复杂度是 O(1) ;其他部分增删需要挪动数组,时间复杂度是 O(n)
- LinkedList 头尾节点增删时间复杂度是 O(1) ,其他都需要遍历链表,时间复杂度是 O(n)
3. 内存空间占用
- ArrayList 底层是数组,内存连续,节省内存
- LinkedList 是双向链表需要存储数据,和两个指针,更占用内存 4. 线程安全
- ArrayList 和 LinkedList 都不是线程安全的
- 如果需要保证线程安全,有两种方案:
- 返回添加成功布尔值。
- 在方法内使用,局部变量则是线程安全的
- 使用线程安全的 ArrayList 和 LinkedList
ini
List<Object> syncArrayList = Collections.synchronizedList(new ArrayList<>());
List<Object> syncLinkedList = Collections.synchronizedList(new LinkedList<>());问5:hashmap相关
1. 说一下 HashMap 的实现原理?
bash
● 底层使用 hash 表数据结构,即数组 +(链表 | 红黑树)
● 添加数据时,计算 key 的 hash 值确定元素在数组中的下标
➢ key 相同则替换
➢ 不同则存入链表或红黑树中
获取数据通过 key 的 hash 计算数组下标获取元素2. HashMap 的 jdk1.7 和 jdk1.8 有什么区别?
● JDK1.8 之前采用的拉链法,数组 + 链表
● JDK1.8 之后采用数组 + 链表 + 红黑树,链表长度大于 8 且数组长度大于 64 则会从链表转化为红黑树3.HashMap 的 put 方法的具体流程?
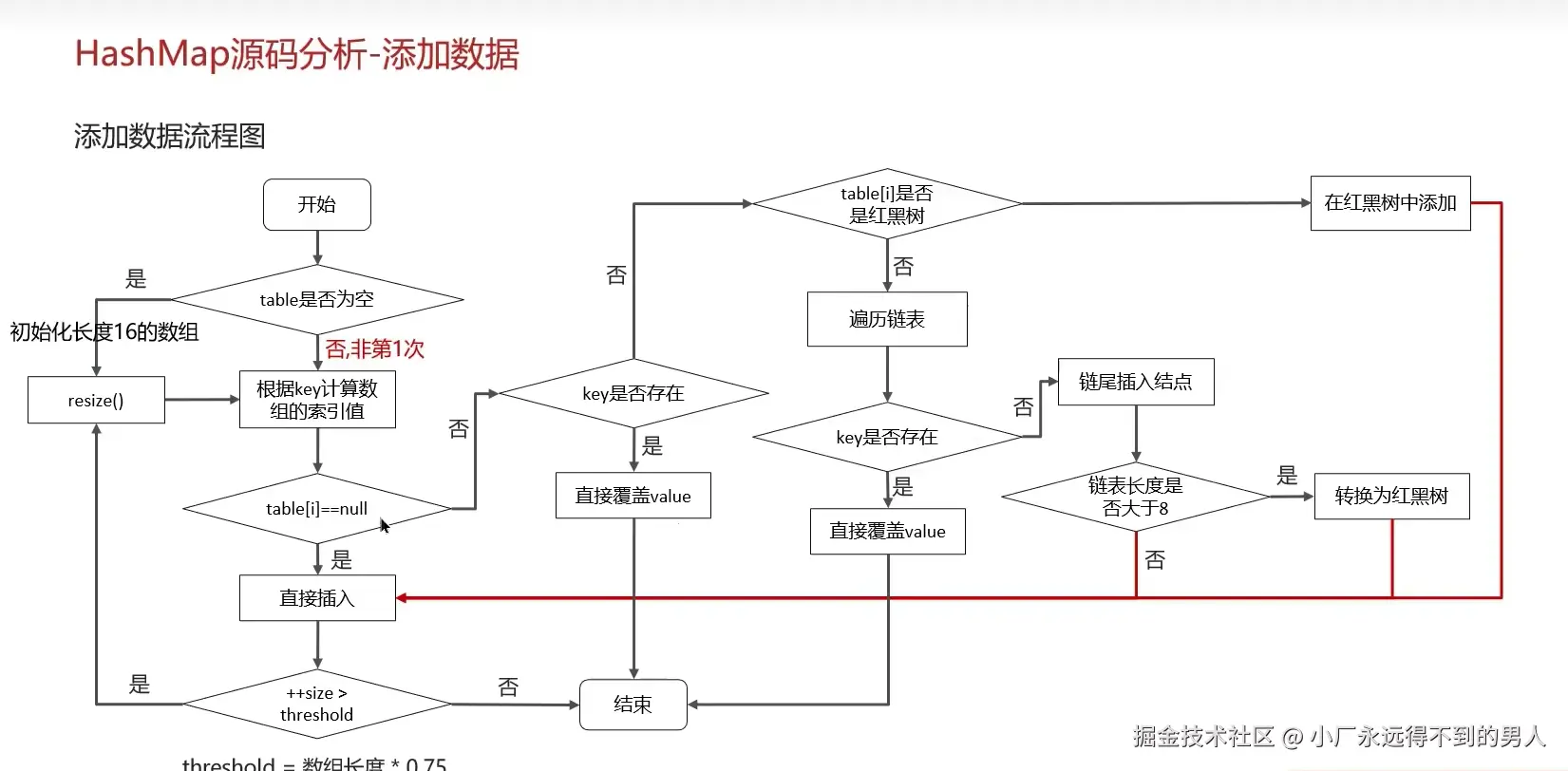
3.1. 判断键值对数组 table 是否为空或为 null,否则执行 resize () 进行扩容(初始化)
3.2. 根据键值 key 计算 hash 值得到数组索引
3.3. 判断table[i] == null,条件成立,直接新建节点添加
3.4. 如果table[i] == null不成立:
(1)判断 table i 的首个元素是否和 key 一样,如果相同直接覆盖 value 。
(2) 判断 table i 是否为 treeNode(即是否是红黑树),如果是红黑树,则直接在树中插入键值对
(3) 遍历 table i(链表),在尾部插入数据;然后判断链表长度是否大于 8,若大于 8 则把链表转 换为红黑树,在红黑树中执行插入操作;遍历过程中若发现 key 已存在,直接覆盖 value
3.5. 插入成功后,判断实际存在的键值对数量 size 是否超过最大容量 threshold(数组长度 0.75),如果超过,进行扩容
4 . hashMap 的寻址算法?
- 计算对象的 hashCode()
- 再进行调用 hash() 方法进行二次哈希, hashcode 值右移 16 位再异 或运算,让哈希分布更为均匀
- 最后 (capacity -- 1) & hash 得到索引
5. 为何 HashMap 的数组长度一定是 2 的次幂?
-
计算索引时效率更高:如果是 2 的 n 次幂可以使用位与运算代替取模
-
扩容时重新计算索引效率更高: hash & oldCap == 0 的元素留在原来位置 ,否则新位置 = 旧位置 + oldCap
6.hashmap 在1.7情况下的多线程死循环问题
在 jdk1.7 的 hashmap 中在数组进行扩容的时候,因为链表是头插法,在进行数据迁移的过程中,有可能导致死循环。
比如说,现在有两个线程 线程一:读取到当前的 hashmap 数据,数据中一个链表,在准备扩容时,线程二介入
线程二:也读取 hashmap ,直接进行扩容。因为是头插法,链表的顺序会进行颠倒过来。比如原来的顺序是 AB ,扩容后的顺序是 BA ,线程二执行结束。
线程一:继续执行的时候就会出现死循环的问题。
线程一先将 A 移入新的链表,再将 B 插入到链头,由于另外一个线程的原因, B 的 next 指向了 A ,所以 B->A->B, 形成循环。
当然, JDK 8 将扩容算法做了调整,不再将元素加入链表头(而是保持与扩容前一样的顺序),尾插法,就避免了 jdk7中死循环的问题