Post-train 的分类
- SFT
- DPO
- online RL
以下是后训练(Post-train)中三种主流方法的对比表格,涵盖核心定义、优化目标、数据需求、优缺点及典型应用场景:
| 分类 | 核心定义 | 优化目标 | 数据需求 | 优点 | 缺点 | 典型应用场景 |
|---|---|---|---|---|---|---|
| SFT(监督微调) | 在预训练模型基础上,使用人工标注的高质量指令-响应对数据进行微调,让模型学习特定任务的输出格式和知识。 | 最小化模型输出与标注数据的交叉熵损失,使模型生成符合人类预期的"标准答案"。 | 依赖高质量的人工标注数据(如指令-响应对),数据规模通常较小(数万至数十万样本)。 | 1. 训练简单稳定,易实现; 2. 能快速对齐基础任务格式; 3. 对计算资源要求较低。 | 1. 难以捕捉复杂的人类偏好(如安全性、相关性); 2. 泛化能力有限,对未见过的指令可能生成错误结果。 | 基础对话系统、特定任务指令对齐(如翻译、摘要)、模型快速适配新领域。 |
| DPO(直接偏好优化) | 跳过显式奖励模型训练,直接通过人类偏好数据(如"更好/更差"的样本对)优化策略,将偏好建模嵌入模型损失函数。 | 最大化模型生成"偏好样本"的概率,同时通过KL约束保持与参考模型(如SFT模型)的分布接近。 | 需要人类标注的偏好对数据(如(x,y好,y差)(x, y_{\text{好}}, y_{\text{差}})(x,y好,y差)),数据规模中等。 | 1. 省去奖励模型训练,简化流程; 2. 训练稳定性优于传统RLHF; 3. 对域内任务拟合效果好。 | 1. 依赖高质量偏好标注,标注成本高; 2. 域外泛化能力较弱; 3. 难以处理复杂奖励信号。 | 对齐人类偏好的对话模型(如ChatGPT后期优化)、内容生成质量提升(如文本、图像)。 |
| Online RL(在线强化学习) | 模型在与环境交互中实时生成样本,基于实时反馈(奖励)动态更新策略,无需依赖预收集的静态数据集。 | 最大化累积奖励,通过探索不同生成路径找到最优策略,同时平衡"探索"与"利用"。 | 无需预收集数据,依赖实时奖励信号(可来自benchmark、人类反馈或其他评估器)。 | 1. 能适应动态环境和复杂奖励; 2. 域外泛化能力强; 3. 可持续优化策略。 | 1. 训练复杂,需设计高效探索机制; 2. 计算成本高(实时生成与反馈); 3. 可能存在奖励黑客风险。 | 动态任务优化(如文本到图像生成的细节控制)、需要推理能力的任务(如数学解题、代码生成)。 |
关键区别总结:
- 数据依赖 :SFT和DPO依赖静态标注数据 ,Online RL依赖实时反馈;
- 优化粒度:SFT关注"正确输出",DPO关注"相对偏好",Online RL关注"全局最优策略";
- 适用阶段 :SFT通常作为后训练的基础步骤,DPO和Online RL用于进一步优化偏好对齐和复杂任务能力。
Alignment in Diffusion 的分类
- 这里是 DPO, Online RL for diffusion 的分类,不包括 SFT。
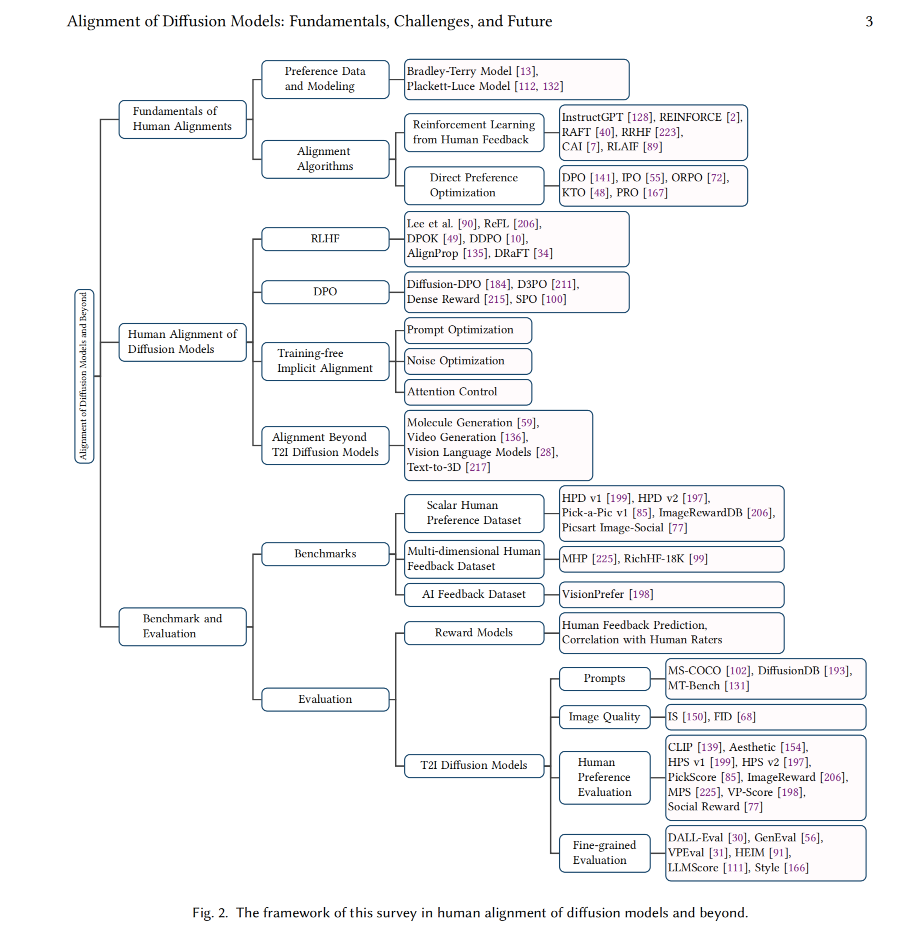
上图来源于 https://github.com/xie-lab-ml/awesome-alignment-of-diffusion-models