部署 whisper-asr-webservice 指南
whisper-asr-webservice 是一个将 Whisper 模型封装为 HTTP API 服务的项目,以下是详细的部署方法:
- 准备工作
确保你的系统已安装:
Docker 和 Docker Compose
NVIDIA 驱动和 nvidia-docker(如需 GPU 加速)
- 快速部署(使用 Docker)
方法一:直接使用预构建镜像
bash
docker run -d --gpus all \
-p 9000:9000 \
-e ASR_MODEL=medium \
-v ~/whisper_models:/root/.cache/whisper \
onerahmet/openai-whisper-asr-webservice:latest方法二:使用 Docker Compose
创建 docker-compose.yml 文件:
yml
version: '3.8'
services:
whisper-api:
image: onerahmet/openai-whisper-asr-webservice:latest
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
ports:
- "9000:9000"
environment:
- ASR_MODEL=medium # 可选: tiny, base, small, medium, large
- ASR_LANGUAGE=zh # 可选: 指定默认语言
volumes:
- whisper_cache:/root/.cache/whisper
volumes:
whisper_cache:然后运行:
bash
docker-compose up -d- 从源码构建部署
如果你想自定义构建:
bash
git clone https://github.com/ahmetoner/whisper-asr-webservice.git
cd whisper-asr-webservice构建镜像
docker build -t whisper-service .运行
docker run -d --gpus all -p 9000:9000 -e ASR_MODEL=large whisper-service
git clone https://github.com/ahmetoner/whisper-asr-webservice.git
cd whisper-asr-webservice
# 构建镜像
docker build -t whisper-service .
# 运行
docker run -d --gpus all -p 9000:9000 -e ASR_MODEL=large whisper-service
# 报错则换命令执行(显卡驱动限制导致)
docker run -d --runtime=nvidia -p 9000:9000 -e ASR_MODEL=large whisper-service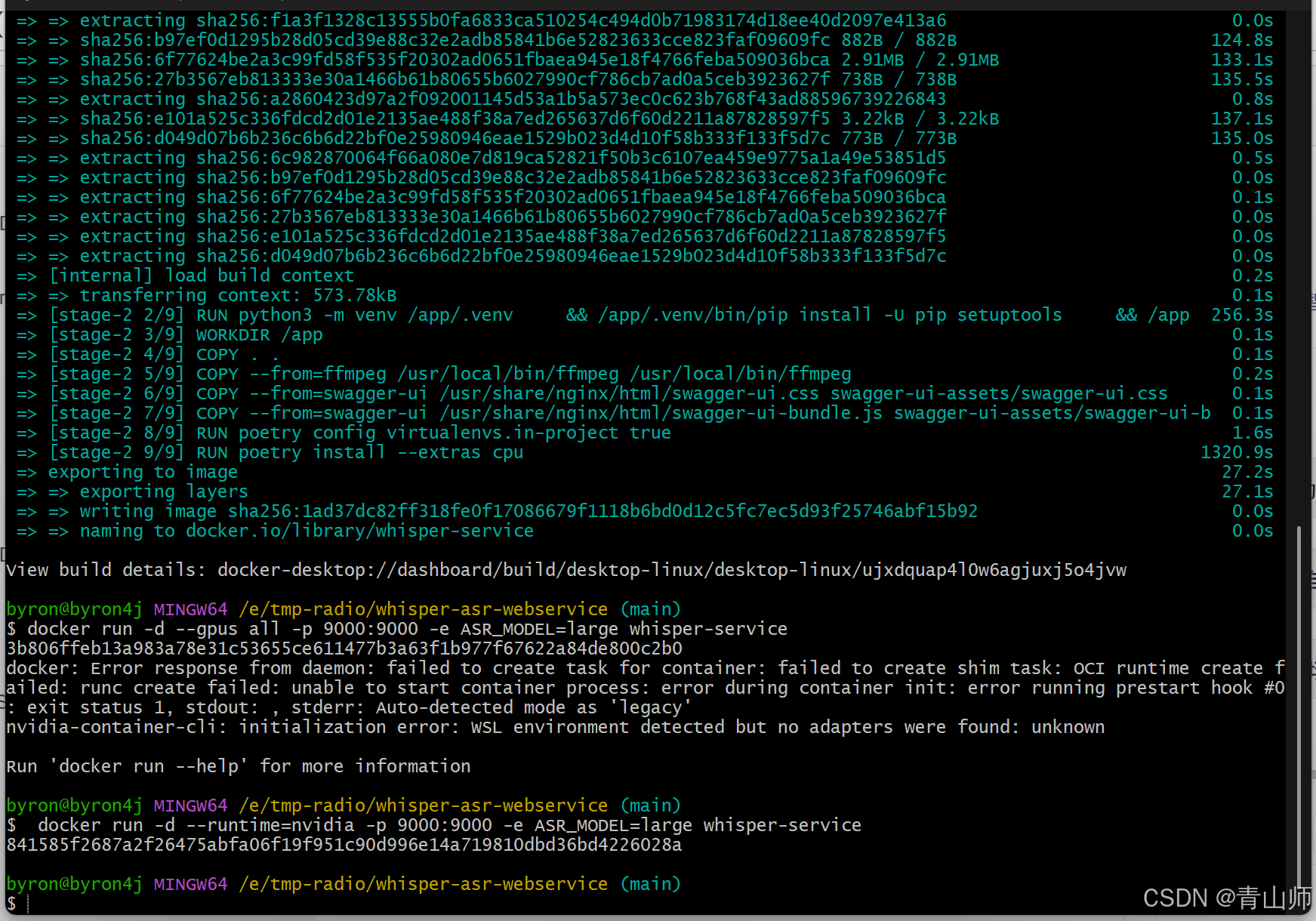
- 使用 API
服务启动后提供以下端点:
POST /asr - 语音识别
bash
curl -X POST -F "audio_file=@audio.mp3" http://localhost:9000/asr-
GET /models - 获取可用模型
-
GET /languages - 获取支持语言
示例 Python 调用:
python
import requests
url = "http://localhost:9000/asr"
files = {"audio_file": open("audio.mp3", "rb")}
response = requests.post(url, files=files)
print(response.json())- 高级配置
可以通过环境变量配置:
变量名 说明 默认值
ASR_MODEL 模型大小 (tiny,base,small,medium,large) small
ASR_LANGUAGE 默认语言代码 (如 zh, en) auto
ASR_DEVICE 计算设备 (cuda 或 cpu) cuda
ASR_COMPUTE_TYPE 计算类型 (int8, float16 等) 根据设备自动选择
- 注意事项
首次运行会自动下载模型文件,medium/large 模型较大需要耐心等待
中文识别建议使用 medium 或 large 模型
对于生产环境,建议:
添加认证中间件
使用 Nginx 反向代理
设置资源限制
- 扩展部署
对于 Kubernetes 部署,可以使用类似的配置,确保正确配置 GPU 资源请求。
如需更复杂的部署方案,可以 fork 项目并根据需要修改代码,特别是 app/main.py 中的 API 逻辑。