逻辑分片 tablet 和 副本
Tablet 是表的逻辑分片。一张表可以有多个 Tablet,每个 Tablet 有 replication_num 个副本, 默认3个 replication。StarRocks 采用多版本并发控制(MVCC)技术,通过复制这些多版本数据的物理副本,保证版本修复的高效进行。StarRocks是以 tablet 这个维度进行数据的管理。
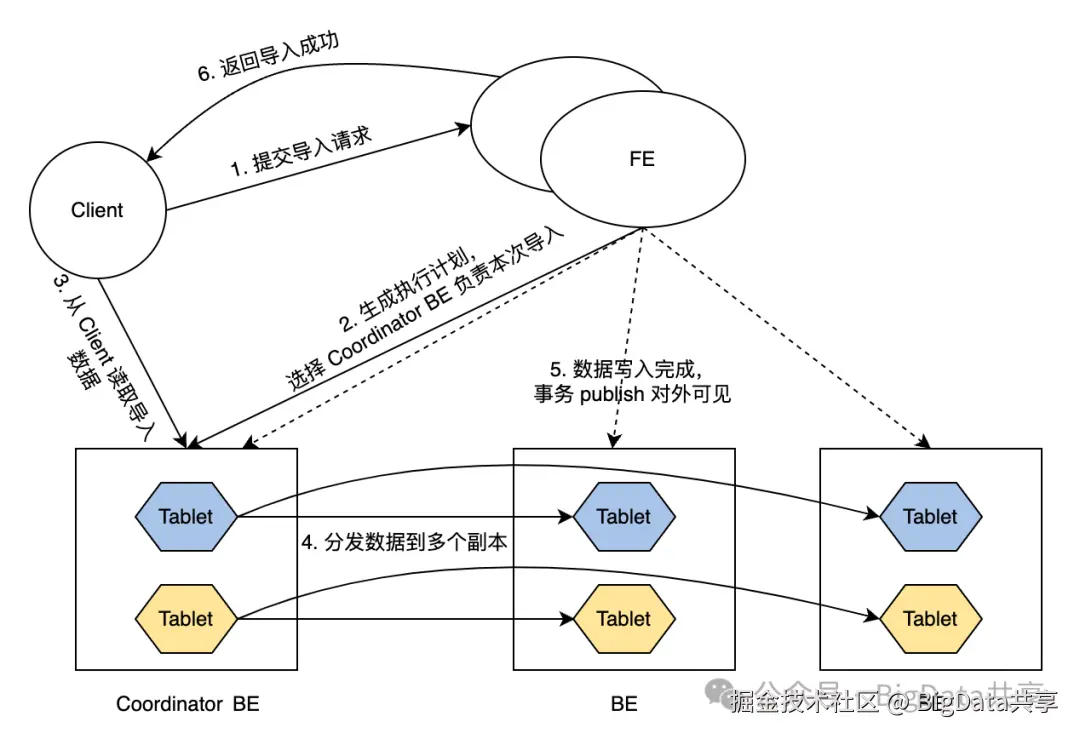
数据导入事务的常规流程如下:
- 客户端提交导入请求至 FE。
- FE 节点选择一个 BE 节点作为该导入事务的 Coordinator BE 节点,并为该事务生成执行计划。
- Coordinator 节点从客户端读取要导入的数据。
- Coordinator 节点将数据分发到所有副本的 Tablet 中。
- 数据导入并存储到所有 Tablet 后,FE 将导入的数据变为可见。
- FE 向客户端返回导入成功。
tablet的运维
一.通过统计信息查看 SHOW PROC '/statistic';
1.查看集群所有tablet的状态
sql
SHOW PROC '/statistic';
2.进一步查看某个db下tablet的状态
sql
SHOW PROC '/statistic/14104';
二.通过 SHOW TABLET 查看
1.查看某个table下的tablet,可以根据字段条件进行过滤;
sql
show tablet from table_xx limit 10;
2.查看某个tablet的信息
sql
show tablet 232081 \G
三.通过 SHOW PROC '/dbs/xx'
可以通过 SHOW PROC '/dbs/xx' 一级一级往下查看;
xml
SHOW PROC '/dbs/<DbId>/<TableId>/partitions/<PartitionId>/<IndexId>/<TabletId>';tablet对应到BE物理文件的存储
对应到BE节点上物理文件的存储,tablet对应的存储路径是在 be.conf 里的 storage_root_path 配置的目录下,相关的 tablet 数据就存在 ${storage_root_path}/data 下
tablet是逻辑分片概念,具体到物理文件存储则是segment文件,文件以及目录层级如下:
shard_id/tablet_id/schema_hash/rowset_id + "_" + segment_id + ".dat"

replication的运维命令
1.查看表所有副本的状态,可以根据条件进行过滤;
sql
ADMIN SHOW REPLICA STATUS FROM table_xx;2.查看表所有副本的分布情况,可以根据条件进行过滤;
sql
ADMIN SHOW REPLICA DISTRIBUTION FROM table_xx;replication的修复和均衡
副本的修复和均衡的处理逻辑都在TabletScheduler类中,该类是运行在FE节点上的一个后台定期调度线程;修复和均衡分别对应场景 1 和 场景 2;
- 场景 1:后端节点宕机,需要尽快修复受影响的 Tablet 副本。某些 Tablet 需要高优先级修复,允许抢占式调度。
- 场景 2:新增后端节点,需要将副本迁移到新节点以平衡集群负载。
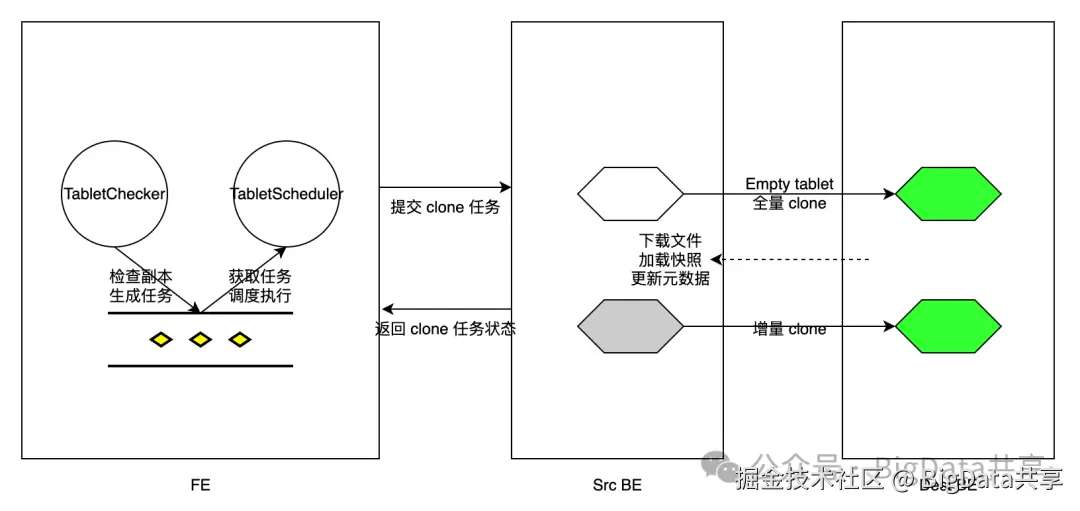
1.查看等待执行的调度任务
sql
SHOW PROC '/cluster_balance/pending_tablets';2.查看正在运行的调度任务
sql
SHOW PROC '/cluster_balance/running_tablets';3.查看已结束的调度任务
sql
SHOW PROC '/cluster_balance/history_tablets';一张表tablet的数量
分桶的数量就是tablet的数量,tablet的数量=每个分区下的bucket数的总和。StarRocks会自动分桶,也可以在创建表的时候手动设置分桶:DISTRIBUTED BY HASH(event_time) BUCKETS 10
通过 show partitions from table_xx;查看每个分区下的分桶情况
如:创建表手动设置分桶数,DISTRIBUTED BY HASH(event_time) BUCKETS 2,每个分区下就是2个 bucket;如果没有分区,总共就2个bucket;

write_buffer_size
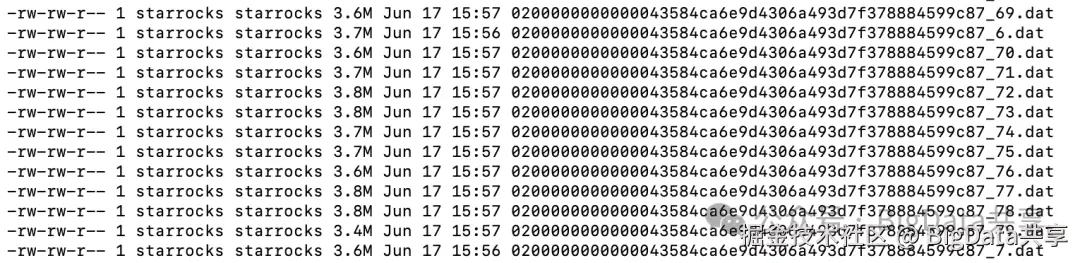
write_buffer_size 决定了 MemTable 的大小,默认是 104857600,即100MB。StarRocks写数据的时候通过delta_writer.cpp::write() 往内存 _mem_table 写数据,内存数据写满或满足其他条件就会 flush 到磁盘生成segment 文件。
使用默认write_buffer_size=100MB,批量导入数据,_mem_table flush 生成的segment文件大小如下:
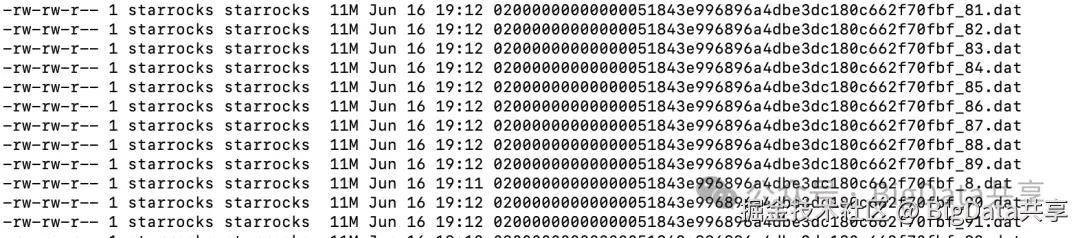
测试调整write_buffer_size=300MB,批量导入数据,_mem_table flush 生成的segment文件大小如下:
具体 delta_writer 写入 _mem_table 如下
scss
Status DeltaWriter::write(const Chunk& chunk, const uint32_t* indexes, uint32_t from, uint32_t size) {
SCOPED_THREAD_LOCAL_MEM_SETTER(_mem_tracker, false);
RETURN_IF_ERROR(_check_partial_update_with_sort_key(chunk));
// Delay the creation memtables until we write data.
// Because for the tablet which doesn't have any written data, we will not use their memtables.
if (_mem_table == nullptr) {
// When loading memory usage is larger than hard limit, we will reject new loading task.
if (!config::enable_new_load_on_memory_limit_exceeded &&
is_tracker_hit_hard_limit(GlobalEnv::GetInstance()->load_mem_tracker(),
config::load_process_max_memory_hard_limit_ratio)) {
return Status::MemoryLimitExceeded(
"memory limit exceeded, please reduce load frequency or increase config "
"`load_process_max_memory_hard_limit_ratio` or add more BE nodes");
}
_reset_mem_table();
}
auto state = get_state();
if (state != kWriting) {
auto err_st = get_err_status();
// no error just in wrong state
if (err_st.ok()) {
err_st = Status::InternalError(
fmt::format("Fail to prepare. tablet_id: {}, state: {}", _opt.tablet_id, _state_name(state)));
}
return err_st;
}
if (_replica_state == Secondary) {
return Status::InternalError(fmt::format("Fail to write chunk, tablet_id: {}, replica_state: {}",
_opt.tablet_id, _replica_state_name(_replica_state)));
}
if (_tablet->keys_type() == KeysType::PRIMARY_KEYS && !_mem_table->check_supported_column_partial_update(chunk)) {
return Status::InternalError(
fmt::format("can't partial update for column with row. tablet_id: {}", _opt.tablet_id));
}
Status st;
ASSIGN_OR_RETURN(auto full, _mem_table->insert(chunk, indexes, from, size));
_last_write_ts = butil::gettimeofday_s();
_write_buffer_size = _mem_table->write_buffer_size();
if (_mem_tracker->limit_exceeded()) {
VLOG(2) << "Flushing memory table due to memory limit exceeded";
st = _flush_memtable();
_reset_mem_table();
} else if (_mem_tracker->parent() && _mem_tracker->parent()->limit_exceeded()) {
VLOG(2) << "Flushing memory table due to parent memory limit exceeded";
st = _flush_memtable();
_reset_mem_table();
} else if (full) {
st = flush_memtable_async();
_reset_mem_table();
}
if (!st.ok()) {
_set_state(kAborted, st);
}
return st;
}writer的实例
一个 tablet 对应一个 delta_writer 实例,也就是分桶数决定写并发。
在 StarRocks 中,每个 tablet 通常对应一个 delta_writer 实例。delta_writer 是 StarRocks 数据写入流程中的核心组件,负责将数据写入到特定的 tablet 中。每个 tablet 都会有一个独立的 delta_writer 实例来管理其数据写入操作,包括内存缓冲、数据刷新到磁盘以及保证数据一致性等。
compaction的 max_segment_file_size
提高查询性能:
- Compaction 将多个小文件合并成更大的文件,减少文件数量,从而降低元数据管理和文件扫描的开销。
- 合并后的文件数据更集中,减少磁盘 I/O,提升查询效率,尤其对扫描大量数据的查询效果显著。
优化存储空间:
-
通过合并和删除冗余数据(如历史版本、重复数据或已删除的数据),减少存储占用。
-
针对频繁的增删改操作,compaction 清理无效数据,释放空间。
compaction后的segment文件大小由参数 max_segment_file_size 控制,默认是1GB

调整成256MB,生成的segment文件大小不超过256MB
不同的压缩算法比较
StarRocks 支持四种数据压缩算法:LZ4、Zstandard(或 zstd)、zlib 和 Snappy。 这些数据压缩算法在压缩率和压缩/解压缩性能上有所不同。 通常来说,这些算法的压缩率排名如下:zlib > Zstandard > LZ4 > Snappy。其中,zlib 拥有较高的压缩比。但由于数据高度压缩,使用 zlib 算法的表,其导入和查询性能会受到一定程度的影响。而 LZ4 和 Zstandard 算法具有较为均衡的压缩比和解压缩性能。
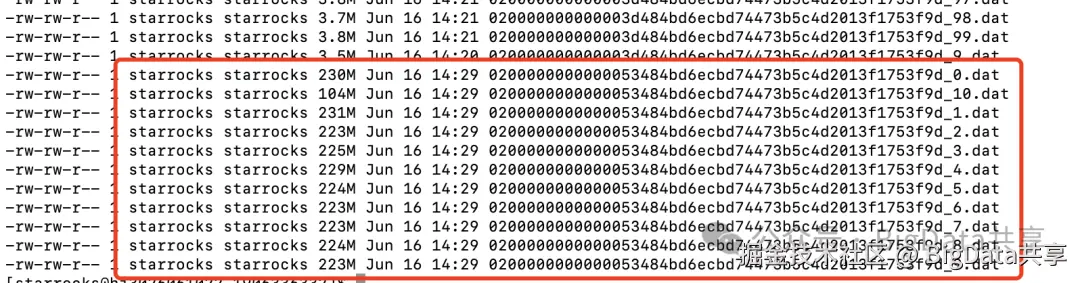
对比条数相同的 bucket 文件
使用zlib压缩,compaction后的文件大小 893+847+504=2244MB


使用snappy压缩,compaction后的文件大小 935+884+526=2345MB

 更多大数据干货,欢迎关注我的微信公众号---BigData共享
更多大数据干货,欢迎关注我的微信公众号---BigData共享