自己的原文哦~https://blog.51cto.com/whaosoft/11686340
#DriveArena
首个高保真闭环生成仿真平台DRIVEARENA是首个为高保真度闭环模拟系统设计的驾驶agent,用于在真实场景中进行导航。DRIVEARENA具有灵活、模块化的架构,可无缝交换其核心组件:交通管理器(Traffic Manager),这是一种能够在全球任何街道地图上生成逼真车流的交通模拟器;以及World Dreamer,这是一个具有无限自回归特性的高保真条件生成模型。这种强大的协同作用使任何能够处理现实世界图像的驾驶agent都能够在DRIVEARENA的模拟环境中进行导航。agent通过世界梦想家生成的图像感知周围环境并输出轨迹。这些轨迹被输入到交通管理器中,以实现与其他车辆的逼真交互并产生新的场景布局。最后,最新的场景布局被传回World Dreamer,从而延续模拟循环。这一迭代过程促进了在高度逼真的环境中的闭环探索,为在不同且具挑战性的场景中开发和评估驾驶agent提供了一个宝贵的平台。DRIVEARENA标志着在利用生成图像数据构建驾驶模拟平台方面取得了重大飞跃,为闭环自动驾驶提供了新见解。
代码链接:https://github.com/PJLab-ADG/DriveArena
DRIVEARENA与现有自动驾驶方法和平台在交互性和逼真度方面的比较。交互性表示平台对车辆的控制程度,范围从开环、不可控闭环到可控闭环。逼真度反映了驾驶场景的真实性,从下到上分为:仅交通流、不现实场景、现实场景和多样场景。DRIVEARENA独特地占据了右上方的位置,是第一个为所有车辆生成多样交通场景和环视图像并具有闭环可控性的模拟平台。
当前领域背景
近几十年来,自动驾驶(AD)算法取得了飞速发展,从模块化流程发展到端到端模型和知识驱动方法。尽管这些算法在各种基准测试中表现出色,但在使用回放的开环数据集进行评估时,仍存在重大挑战,掩盖了它们在现实世界中的有效性。公共数据集虽然提供了真实的驾驶数据、真实的传感器输入和交通行为,但本质上偏向于简单的直线行驶场景。在这种情况下,agent只需保持当前状态即可获得看似良好的表现,从而使在复杂情况下评估实际驾驶能力变得复杂。此外,在开环评估中,agent的当前决策不会影响执行或后续决策,这阻止了它反映现实世界驾驶场景中的累积错误。此外,记录的数据集具有静态特性,其他车辆无法对自车的行为做出反应,这进一步阻碍了在动态、真实世界条件下对自动驾驶算法进行评估。
如图1所示,这里对现有的自动驾驶方法和平台进行了分析,发现其中大多数都不足以进行高保真度的闭环模拟。理想情况下,作为xx智能的一部分,agent应在闭环环境中进行评估,在该环境中,其他agent会对自车(ego vehicle)的行为做出反应,而自车也会相应地接收到变化的传感器输入。然而,现有的模拟环境要么无法模拟传感器输入,要么与现实世界存在显著的领域差异,这使得算法难以无缝集成到现实世界中,从而对闭环评估构成了巨大挑战。我们认为,模拟器不仅应紧密反映现实世界的视觉和物理特性,还应在探索性闭环系统中促进模型的持续学习和进化,以适应各种复杂的驾驶场景。为实现这一目标,建立一个符合物理定律并支持交互功能的高保真模拟器至关重要。
因此,我们推出了DRIVEARENA,这是一款基于条件生成模型的开创性闭环模拟器,用于训练和测试驾驶agent。具体而言,DRIVEARENA提供了一个灵活的平台,可以与任何基于摄像头输入的驾驶agent集成。它采用模块化设计,自然支持每个模块的迭代升级。DRIVEARENA由交通管理器(Traffic Manager)和基于自回归生成的"世界梦想家"(World Dreamer)组成。交通管理器可以在全球任何道路网络上生成逼真的交互式交通流,而World Dreamer是一个具有无限自回归能力的高保真条件生成模型。驾驶agent应根据"World Dreamer"生成的图像做出相应的驾驶动作,并将这些动作反馈给交通管理器以更新环境中车辆的状态。新的场景布局将返回给"World Dreamer"进行新一轮的模拟。这一迭代过程实现了驾驶agent与模拟环境之间的动态交互。具体贡献如下:
**高保真闭环模拟:**我们提出了首个针对自动驾驶的高保真闭环模拟器DRIVEARENA,该模拟器能够提供逼真的周围图像,并与现有的基于视觉的驾驶agent无缝集成。它能够紧密反映现实世界的视觉和物理特性,使agent能够以闭环方式持续学习和进化,适应各种复杂的驾驶场景。
**可控性和可扩展性:**我们的交通管理器(Traffic Manager)可以动态控制场景中所有车辆的移动,并将道路和车辆布局输入给World Dreamer。"World Dreamer"利用条件扩散框架以稳定且可控的方式生成逼真的图像。此外,DRIVEARENA支持使用全球任何城市的道路网络进行模拟,能够创建具有不同风格的各种驾驶场景图像。
模块化设计: 驾驶agent(Driving Agent)、交通管理器(Traffic Manager)和World Dreamer通过网络接口进行通信,构建了一个高度灵活且模块化的框架。这种架构允许使用不同的方法替换每个组件,而无需特定的实现。作为这些参与者的竞技场,DRIVEARENA促进了基于视觉的自动驾驶算法和驾驶场景生成模型的全面测试和改进。
DRIVEARENA框架
如图2所示,提出的DRIVEARENA框架包含两个关键组件:一个是作为后端物理引擎的交通管理器(Traffic Manager),另一个是作为现实世界图像渲染器的World Dreamer。与传统方法不同,DRIVEARENA不依赖于预建的数字资产或重建的3D道路模型。相反,交通管理器能够适应OpenStreetMap(OSM)格式中任何城市的道路网络,这些网络可以直接从互联网下载。这种灵活性使得在不同城市布局上进行闭环交通模拟成为可能。
交通管理器接收自动驾驶agent输出的自车轨迹,并管理所有背景车辆的移动。与依赖扩散模型来进行图像生成和车辆运动预测的世界模型方法不同,我们的交通管理器采用显式的交通流生成算法。这种方法能够生成更广泛的不常见且可能不安全的交通场景,同时也便于实时检测车辆之间的碰撞。
"World Dreamer"能够生成逼真的camera图像,这些图像与交通管理器的输出精确对应。此外,它还允许用户自定义提示来控制生成图像的各种元素,如街景风格、一天中的时间和天气状况,从而增强了生成场景的多样性。具体来说,它采用了一种基于扩散的模型,该模型利用当前的地图和车辆布局作为控制条件来生成环视图像。这些图像作为端到端驾驶agent的输入。鉴于DRIVEARENA的闭环架构,扩散模型需要保持生成图像中的跨视图一致性和时间一致性。
当前帧生成的多视图图像被输入到端到端自动驾驶agent中,该agent可以输出自车(ego vehicle)的运动情况。随后,将规划的自车轨迹发送给DRIVEARENA进行下一步的模拟。当自车成功完成整个路线、发生碰撞或偏离道路时,模拟结束。完成后,DRIVEARENA执行全面的评估过程,以评估驾驶agent的能力。
值得注意的是,DRIVEARENA采用了分布式模块化设计。交通管理器(Traffic Manager)、World Dreamer和自动驾驶(AD)agent通过网络使用标准化接口进行通信。因此,DRIVEARENA并不强制要求World Dreamer或自动驾驶agent的具体实现方式。我们的框架旨在为这些"参与者"提供一个"竞技场",促进端到端自动驾驶算法和真实驾驶场景生成模型的全面测试和改进。
方法介绍
1)Traffic Manager
大多数现有的真实驾驶模拟器依赖于公共数据集中有限的布局,缺乏动态环境的多样性。为了应对这些挑战,我们利用LimSim作为底层交通管理器来模拟动态交通场景,并为后续的环境生成生成道路和车辆布局。LimSim还提供了一个用户友好的前端图形用户界面(GUI),该界面直接显示鸟瞰图(BEV)地图以及来自World Dreamer和驾驶agent的结果。
我们的交通管理器能够实现交通流中多辆车的交互式模拟,包括全面的车辆规划和控制。我们采用了一个层次化的多车决策和规划框架,该框架对流中的所有车辆进行联合决策,并通过高频规划模块迅速响应动态环境。该框架还融入了合作因子和轨迹权重集,在社交和个人层面为交通中的自动驾驶车辆引入了多样性。
此外,动态模拟器支持从OpenStreetMap获取任何城市的各种自定义高清地图,便于构建多样化的道路图以进行便捷的模拟。交通管理器控制所有背景车辆的移动。对于主体车辆(即自动驾驶车辆本身),提供两种不同的模拟模式:开环和闭环。在闭环模式下,驾驶代理为主体车辆进行规划,交通管理器则使用agent输出的轨迹来相应地控制主体车辆。在开环模式下,驾驶agent生成的轨迹并不实际用于控制主体车辆;相反,交通管理器以闭环方式保持控制。
2)World Dreamer
与最近使用神经辐射场(Neural Radiance Fields, NeRF)和3DGS(3D Gaussian Splatting)从记录的视频中重建环境的自动驾驶生成方法不同,我们设计了一个基于扩散的World Dreamer。它利用来自交通管理器的地图控制条件和车辆布局来生成几何和上下文上准确的驾驶场景。框架具有以下几个优势:(1)更好的可控性。生成的场景可以通过交通管理器中的场景布局、文本提示和参考图像来控制,以捕捉不同的天气条件、光照和场景风格。(2)更好的可扩展性。框架可以适应各种道路结构,而无需事先对场景进行建模。理论上,通过利用OpenStreetMap的布局,支持为世界上任何城市生成驾驶场景。
在图3中展示了基于扩散的"World Dreamer"。在稳定的扩散流程的基础上,"World Dreamer"利用了一个有效的条件编码模块,该模块可接受包括地图和车辆布局、文本描述、相机参数、自我姿态和参考图像在内的多种条件输入,以生成逼真的环视图像。考虑到对于驾驶agent而言,确保跨不同视图和时间跨度的合成场景一致性至关重要,这里借鉴了29的灵感,集成了一个跨视图注意力模块,以保持不同视图之间的一致性。此外,采用了一种图像自回归生成范式来强制时间一致性。这种方法使"World Dreamer"不仅能够最大限度地保持生成视频的时间一致性,还能在无限流中生成任意长度的视频,为自动驾驶模拟提供了极大的支持。
条件编码。先前的工作将鸟瞰图(BEV)布局作为条件输入来控制扩散模型的输出,这增加了网络学习生成几何和上下文准确的驾驶场景的难度。本工作提出了一种新的条件编码模块来引入更多的指导信息,这有助于扩散模块生成高保真度的环视图像。具体来说,除了使用与29类似的条件编码器对每个视图的相机姿态、文本描述、3D目标边界框和BEV地图布局进行编码外,还明确地将地图和目标布局投影到每个相机视图上,以生成更准确的车道和车辆生成指导的布局画布。具体来说,文本嵌入是通过使用CLIP文本编码器对文本描述进行编码获得的。每个相机的参数(其中K、R、T分别代表相机内参、旋转和平移)和3D边界框的8个顶点通过傅里叶嵌入编码为和。2D BEV地图网格使用与29中相同的编码方法获得嵌入。然后,将高清地图和3D边界框的每个类别分别投影到图像平面上,以获得地图canvas和边界框canvas。这些canvases被连接起来以创建layout canvas。最后,通过条件编码网络对layout canvas进行编码,得到最终的特征。
此外,这里还引入了一个参考条件来提供外观和时间一致性指导。在训练过程中,随机从过去的L帧中提取一帧作为参考帧,并使用预训练的CLIP模型从多视图图像中提取参考特征。编码后的参考特征隐含了语义上下文,并通过交叉注意模块整合到条件编码器中。为了使扩散模型能够感知到自车的运动变化,还将自车相对于参考帧的姿态编码到条件编码器中,以捕捉背景的运动变化趋势。相对姿态嵌入通过傅里叶嵌入进行编码。通过整合上述控制条件,我们可以有效地控制周围图像的生成。
自回归生成。为了促进在线推理和流式视频生成,同时保持时间一致性,我们开发了一个自回归生成流程。在推理阶段,之前生成的图像和相应的相对自车姿态被用作参考条件。这种方法引导扩散模型生成当前周围图像,以增强一致性,确保与先前生成的帧之间的过渡更加平滑和连贯。
本文中我们设计的只是World Dreamer的一个简单实现。我们还验证了将自回归生成扩展到多帧版本(使用多个过去帧作为参考并输出多帧图像)以及添加额外的时间模块可以提高时间一致性。
3)Driving Agent
最近的工作已经证明了在公共数据集上进行开环评估以证明驾驶agent规划行为的挑战,这主要是由于所呈现的驾驶场景过于简单。虽然一些研究已经使用如CARLA等模拟器进行了闭环评估,但这些模拟与现实世界的动态环境之间仍存在外观和场景多样性的差异。为了弥补这一差距,DRIVEARENA提供了一个真实的模拟平台,并配备了相应的接口,供基于camera的驾驶agent进行更全面的评估,包括开环和闭环测试。此外,通过改变输入条件(如道路和车辆布局),DRIVEARENA可以生成极端情况,并促进这些驾驶agent在分布外场景下的评估。不失一般性,我们选择了一个具有代表性的端到端驾驶agent,即UniAD在DRIVEARENA中进行开环和闭环测试。UniAD利用周围图像来预测自车和其它agent车辆的运动轨迹,这可以无缝地与我们动态模拟器的API集成以进行评估。此外,感知输出(如3D检测和地图分割)有助于提升我们环境中生成场景的现实性验证。
4)自车控制模式与评估指标
DRIVEARENA 本质上支持驾驶agent的"闭环"仿真模式。即,系统采用agent在每个时间步长输出的轨迹,基于该轨迹更新自车的状态,并模拟背景车辆的动作。随后,它生成下一个时间步长的多视图图像,从而保持连续的反馈闭环。此外,认识到一些自动驾驶agent在开发过程中可能无法进行长期闭环仿真,DRIVEARENA 还支持"开环"仿真模式。在这种模式下,交通管理器将接管自车的控制,而自动驾驶代理输出的轨迹将被记录下来以供后续评估。
在开环和闭环模式下,从结果导向的角度全面评估自动驾驶agent的性能至关重要。受 NAVSIM 和 CARLA 自动驾驶排行榜的启发,DRIVEARENA 采用两种评估指标:PDM 分数(PDMS)和 Arena 驾驶分数(ADS)。
PDMS(路径偏差和速度匹配分数),最初由 NAVSIM提出,用于评估每个时间步长输出的轨迹。遵循 PDMS 的原始定义,该定义综合了以下子分数:
其中,惩罚包括与道路使用者无碰撞(NC)和可行驶区域合规性(DAC),以及包括自我进展(EP)、碰撞时间(TTC)和舒适度(C)的加权平均数。我们对DRIVEARENA进行了小幅修改:在NC评分中,我们不区分"过错方"碰撞;在EP评分中,我们使用交通管理器的自车路径规划器作为参考轨迹,而不是预测驾驶员模型。在模拟结束时,将所有模拟帧的最终PDM分数进行平均。
对于开环模拟,PDMS直接作为自动驾驶agent的评估指标。然而,对于在"闭环"模拟模式下运行的驾驶agent,这里采用了一个更全面的指标,称为Arena Driving Score (ADS),该分数结合了轨迹PDMS和路线完成度:
其中,Rc ∈ 0, 1 表示路线完成度,定义为agent完成的路线距离百分比。由于"闭环"模拟会在agent与其他道路使用者发生碰撞或偏离道路时终止,因此ADS为区分agent的驾驶安全性和一致性提供了一个合适的指标。
实验对比
图5. 不同提示和参考图像对相同场景影响的展示。该图展示了DRIVEARENA为同一个30秒模拟序列生成的四个不同的图像序列,每个序列都使用了不同的提示和参考图像。所有序列都严格遵循给定的道路结构和车辆控制条件,保持跨视图的一致性。值得注意的是,这四个序列在天气和光照条件上呈现出显著的差异,但在整个30秒的过程中都始终如一地保持了各自独特的风格。点击此处查看视频演示。
.
#CLIP视觉感知
还能怎么卷?模型架构改造与识别机制再升级
近年来,随着计算机视觉与自然语言处理技术的飞速发展,CLIP(Contrastive Language-Image Pre-training)模型作为一种强大的跨模态预训练模型,其应用与研究领域不断拓展。为了进一步提升CLIP模型在处理复杂任务时的效能与精度,众多研究团队致力于对传统的CLIP模型进行多维度、深层次的改进,旨在增强其特定领域的能力,比如增强CLIP在少样本分类任务上的泛化能力、细化CLIP的视觉识别区域、强化CLIP对图像内容的关注而非对图像非内容特征的关注、优化图像-文本跨模态对齐等能力。
在具体实施上,这些改进大多聚焦于CLIP的视觉编码器和文本编码器的改造。例如,通过对编码器的注意力池化层进行参数微调,可以使其更加适应特定任务的需求;引入多模态通道则可以增强模型在处理跨模态信息时的灵活性和鲁棒性;改造最终回归层则可以直接优化模型的输出性能;而改进输入数据的方式,如为模型提供伪标签或预先增强图像、文本数据,则可以从源头上提升模型的学习效率和效果。这些改造包括但不限于以下几个方面:
- 编码器改造:对CLIP的视觉和文本编码器进行结构调整或参数优化,以提高特征提取的能力。
- 注意力机制优化:通过微调注意力池层的参数或引入新的注意力模式,增强CLIP对关键视觉信息的捕捉。
- 多模态通道融合:在CLIP中引入多模态融合技术,如使用交叉注意力机制,以加强图像和文本之间的信息交流。
- 回归层调整:改造CLIP的最终回归层,以更好地适应不同任务的需求,如分类、检测或分割。
- 输入数据改进:为CLIP输入经过预处理或增强的数据,提供伪标签以指导学习,或通过数据增强提高模型的鲁棒性。
- 正则化技术:应用各种正则化技术,如Dropout、权重衰减等,以防止模型过拟合,并提高其泛化能力。
- 损失函数设计:设计新颖的损失函数,以更好地反映任务特性,促进模型在特定方向上的性能提升。
本文精心梳理了数篇前沿研究,这些研究聚焦于如何通过创新策略改进传统的CLIP模型,以显著增强其处理复杂任务的能力。从优化少样本分类的泛化性到细化视觉识别精度,再到深化图像内容与文本之间的跨模态对齐,每一篇都为我们揭示了CLIP模型潜力的新边界。接下来就让我们一起看看CLIP模型还能如何被进一步强化与拓展吧!
使用语义感知微调增强 Few-shot CLIP
关键词:CLIP的视觉编码器注意力池层参数微调
文章总结
文章提出了一种名为Semantic-Aware FinE-tuning (SAFE)的新方法,旨在通过微调CLIP模型的视觉编码器中的特定部分来增强其在 Few-shot场景下的表现。文章首先指出,在少样本(few-shot)微调过程中,直接采用预训练的CLIP模型可能导致灾难性遗忘和过拟合。此外,预训练的参数可能并不完全适合所有下游任务。CLIP的视觉编码器包含一个独特的注意力池层,该层对密集特征图执行空间加权求和 。由于密集特征图中包含了丰富的语义信息,文章认为应该根据下游任务的具体需求来调整这些特征的权重。为了解决上述问题,文章提出了SAFE方法。这一方法在训练过程中微调注意力池层的参数,目的是让模型能够专注于对当前任务更为重要的语义特征。 例如,在宠物分类任务中,模型应更多地关注耳朵和眼睛,而不是车辆分类任务中可能更关注的侧镜。在推理阶段,**SAFE采用了一种残差混合技术,结合了经过微调的注意力池层和原始注意力池层的特征。这样做可以整合来自少样本的特定知识和预训练模型的先验知识。**SAFE方法不仅独立有效,还可以与现有的适配器方法(如SAFE-A)兼容,进一步提升CLIP在少样本分类任务中的表现。文章通过在11个基准数据集上的广泛实验,证明了SAFE和SAFE-A方法在1-shot和4-shot设置下均显著优于现有最佳方法。
模型解析
该文章改进CLIP在少样本分类任务上的泛化能力的关键在于微调了CLIP视觉编码器中的注意力池层 的参数,使其更加适用于当前任务,并且整合了微调后的和原始注意力池层。传统的CLIP模型的视觉编码器主要包含以下几类层: 视觉特征提取层(包括卷积层、激活层、归一化层、残差连接)、注意力池层(这是CLIP特有的层,它使用多头注意力机制来对密集特征图进行空间加权求和,生成能够捕捉图像全局上下文信息的特征表示) 、池化层(用于降低特征的空间维度,从而减少参数数量和计算量,同时使特征检测更加鲁棒)、全连接层(在卷积神经网络的末端,用于将学习到的特征映射到最终的输出,例如类别概率)。文章对注意力池层进行的参数微调是基于CLIP在池化层之前的密集特征的有意义的语义属性,从而促使模型根据特定的下游任务关注不同的语义信息。
具体来说,CLIP独特的注意力池层利用了Transformer的多头注意力机制。注意池层内部的操作如下:通过线性层Linearq将全局平均特征F映射到query q,通过线性层Lineark和Linearv将每个空间位置的密集特征F映射到key-value对。然后,注意池层通过缩放后的点积注意(dot-product attention)得到输入的密集特征的空间加权和,再输入线性层Linearc。注意池层的输出是整个图像的综合表示,可以捕获密集特征映射中的关键语义,用于视觉识别。简而言之,注意池化层对密集特征中的各种空间语义赋予不同的权重,通过加权和的方法将特征池化。
另外在推理过程中,文章将微调后的注意池层与原始注意池层进行残差混合,将预训练得到的先验知识与Few-shot知识结合起来,从而避免了在少样本任务上微调可能导致的灾难性遗忘问题。
Alpha-CLIP:关注你想重点关注的部分,看这篇就够了
关键词:在CLIP输入中引入新通道
文章总结
对比语言-图像预训练 (CLIP) 在从不同任务的图像中提取有价值的内容信息方面发挥着至关重要的作用。它对齐文本和视觉模式来理解整个图像,包括所有细节,甚至是那些与特定任务无关的细节。然而,为了更精细地理解和控制图像的编辑,关注特定的感兴趣区域变得至关重要,这些区域可以被人类或感知模型指示为点、蒙版或框。为了满足这些要求,我们引入了 Alpha-CLIP,**这是 CLIP 的增强版本,带有辅助 Alpha 通道,用于建议关注区域,并通过构建的数百万个 RGBA 区域文本对进行微调。Alpha-CLIP不仅保留了CLIP的视觉识别能力,而且能够精确控制图像内容的重点。**它在各种任务中都表现出了有效性,包括但不限于开放世界识别、多模态大型语言模型和条件 2D/3D 生成。它具有很大的潜力,可以作为图像相关任务的多功能工具。
模型解析
文章介绍了一个名为Alpha-CLIP的模型,它是Contrastive Language-Image Pre-training (CLIP)的一个增强版本,**主要改进在于增加了一个辅助的Alpha通道,用于指示模型应该关注图像中的特定区域。**以下是对Alpha-CLIP模型架构的总结:
- Alpha通道引入:Alpha-CLIP在传统的RGB图像通道基础上增加了一个Alpha通道,该通道作为一个蒙版(mask),可以用来指定图像中的感兴趣区域(Region of Interest, RoI)。Alpha通道的值范围从0(完全透明,表示背景)到1(完全不透明,表示前景)。
- 数据生成管道:为了训练Alpha-CLIP,研究者设计了一个数据生成管道,利用现有的图像和标注数据,结合Segment Anything Model (SAM) 和多模态大型模型(如BLIP-2)生成了数百万个RGBA区域文本对。Alpha-CLIP通过这些RGBA区域文本对进行微调。在微调过程中,保持CLIP文本编码器固定,只训练图像编码器,特别是新引入的Alpha卷积层,以及随后的Transformer块。
- Alpha-CLIP的图像编码器在结构上进行了细微的修改,以接受额外的Alpha通道输入。在Vision Transformer (ViT) 结构中,Alpha通道通过一个与RGB卷积层平行的Alpha卷积层进行处理。在训练Alpha-CLIP时,采用了特定的数据采样策略,以偶尔用原始图像-文本对替换生成的RGBA-文本对,并设置Alpha通道为全1,以保持对全图的识别能力。
总结来说,Alpha-CLIP通过对CLIP模型的扩展,引入了Alpha通道来指定图像中的关注区域,并通过大量RGBA区域文本对的微调,实现了对图像特定内容的精确控制和强调,同时保持了CLIP的原有视觉识别能力。
CLIP-VG:基于Self-paced课程学习,使CLIP实现视觉定位
关键词:改造CLIP最终回归层来实现视觉定位,self-paced式端到端优化
文章总结
视觉定位 (VG, Visual Grounding) 是视觉和语言领域的一个关键主题,它将由文字表达描述的特定区域定位在图像中。为了减少对手动标记数据的依赖,已经开发了无监督视觉定位技术,以使用伪标签来定位区域。然而,现有无监督方法的性能高度依赖于伪标签的质量,这些方法总是遇到多样性有限的问题。为了利用视觉和语言预训练模型来解决视觉定位问题,并合理利用伪标签,我们提出了CLIP-VG,这是一种新方法,可以对带有伪语言标签的CLIP进行self-paced课程学习。 我们提出了一种简单而高效的端到端网络架构 ,以实现CLIP到视觉定位的迁移学习。**基于CLIP架构,进一步提出单源和多源self-paced课程算法,该算法可以逐步找到更可靠的伪标签来学习最优模型,从而实现伪语言标签的可靠性和多样性之间的平衡。**在单源和多源场景下,该方法在RefCOCO/+/g数据集上的表现明显优于目前最先进的无监督方法,改进幅度为6.78%至 10.67%和 11.39%至 14.87%分别。其结果甚至优于现有的弱监督视觉定位方法。此外,我们的方法在完全监督的环境中也具有竞争力。
模型解析
- CLIP-VG采用了一个简单而高效的纯Transformer编码器架构 ,该架构只需要调整少量参数,以最小的训练资源实现CLIP模型向视觉定位任务的迁移。为了防止灾难性遗忘,并保持CLIP的泛化能力,CLIP的编码器参数在训练过程中被冻结,只有与Transformer相关的少量参数被更新和优化。最后使用回归多层感知器(MLP)作为最终的回归层,用于预测文本描述所指的视觉区域的边界框(bounding box)。
- 单源伪标签 是通过利用空间关系先验知识和由检测器提供的物体标签(包括类别和属性信息)合成的。多源伪标签 是利用了基于场景图生成的方法来生成伪关系标签,或使用基于图像描述的方法来生成伪字幕标签。在多源情况下,模型首先独立地为每个伪标签源学习一个初步的特定源视觉定位模型,然后根据每步的平均实体数量选择伪标签源,逐步从简单到复杂。在MSA中,提出了源特定可靠性(Source-specific Reliability, SR)和跨源可靠性(Cross-source Reliability, CR)的概念,以利用来自不同源的伪标签进行学习。
- 提出了单源(Single-source Self-paced Adapting, SSA)和多源(Multi-source Self-paced Adapting, MSA)self-paced课程学习算法 。这些算法逐步找到更可靠的伪标签,以提高定位性能。模型包括一个评估实例级质量的方案,通过学习一个初步的视觉定位模型作为可靠性测量器,使用特定的标签源来计算样本的可靠性,并构建可靠性直方图 (Reliability Histogram, RH)。基于修改的二进制搜索,设计了一个贪婪样本选择策略,以实现可靠性和多样性之间的最佳平衡。
总的来说,CLIP-VG模型通过self-paced课程学习的方式,有效地利用伪语言标签来提升视觉定位任务的性能,同时保持了模型的高效性和泛化能力。
RWKV-CLIP:强大的视觉语言表征学习
关键词:优化CLIP视觉、文本编码器
文章总结
对比语言-图像预训练 (CLIP) 通过使用从网站获得的图像-文本对扩展数据集,显着提高了各种视觉-语言任务的性能。本文从数据和模型架构的角度进一步探讨了CLIP。为了解决杂噪声数据的普遍存在问题并提高从互联网抓取的大规模图像文本数据的质量,我们引入了一个多样化的描述生成框架,该框架可以利用大型语言模型 (LLM) 从基于 Web 的文本、合成标题和检测标签中合成和提炼内容。**此外,我们提出了RWKV-CLIP,这是第一个由RWKV驱动的视觉语言表征学习模型,它将transformer的有效并行训练与RNN的高效推理相结合。**在各种模型尺度和预训练数据集上的综合实验表明,RWKV-CLIP是一个强大而高效的视觉语言表征学习,它在几个下游任务中实现了最先进的性能,包括线性探针、 零样本分类和零样本图像-文本检索。
模型解析
RWKV-CLIP由多个空间混合(Spatial Mixing)和通道混合(Channel Mixing)模块堆叠而成,通过这些模块实现对输入图像和文本的深入处理,从而优化视觉、文本特征的融合。
- 优化特征融合:在空间混合阶段,模型利用注意力机制进行全局的线性复杂度计算,强化特征在通道层级的交互。 输入数据通过四个并行线性层进行处理,以获得多头部的向量。利用双向偏移量增强特征在通道层级的交互,例如使用Q-Lerp和B-Lerp进行图像和文本的线性插值。在空间混合之后,模型通过通道混合模块进一步细化特征表示。
- **模型采用了RWKV单元,这是一种新型的RNN单元,旨在解决Transformer中的内存瓶颈和二次方计算复杂度问题。**RWKV单元通过高效的线性扩展保持了并行训练和鲁棒可扩展性。
为了提高大规模网络图像-文本数据的质量,引入多样化描述生成框架,利用大型语言模型(LLMs)合成和优化来自网络文本、合成字幕和检测标签的内容。RWKV-CLIP通过改进的编码器架构,实现了图像和文本之间的更优跨模态对齐。模型通过优化数据和模型架构,增强了对噪声数据的鲁棒性,尤其是在处理大规模网络数据时。
CLAP:如何将内容与风格隔离开?增强提示对比学习来帮你
关键词:改进CLIP编码器
文章总结
对比视觉语言模型(如CLIP)因其学习特征出色的泛化能力,在多种下游任务中获得了广泛关注。然而,这些模型学习的特征往往融合了内容和风格信息,这在一定程度上限制了其在分布变化下的泛化能力。为了克服这一局限性,文章采用因果生成视角来处理多模态数据,并提出结合数据增强的对比学习方法,以从原始表示中分离出内容特征 。为实现这一目标,文章首先探索了图像增强技术,并开发了一种方法将其无缝集成到预训练的CLIP类模型中,以提取纯粹的内容特征。**更进一步地,作者认识到文本数据固有的语义丰富性和逻辑结构,探索了文本增强的使用,以从风格特征中分离出潜在内容。**这使得CLIP类模型的编码器能够专注于潜在的内容信息,并通过预训练的CLIP类模型优化学习到的表示。通过在多个数据集上进行了广泛的实验,结果表明,在零样本和少样本分类任务上取得了显著改进,同时对各种扰动的鲁棒性也得到了增强。这些结果凸显了文章所提方法在优化视觉语言表示和推动多模态学习领域最新进展方面的有效性。
模型解析
文章提出了一种名为CLAP(Contrastive Learning with Augmented Prompts)的新方法,旨在通过对比学习和数据增强来分离视觉-语言模型中的内容和风格特征。
- 文章采用了因果生成模型来理解多模态数据(图像和文本)。在这个模型中,图像和文本数据被认为是通过不同的生成过程由共享的潜在空间中的潜在变量产生的。这个空间被分为两部分:一部分对应于内容变量 c ,另一部分对应于风格变量 s 。内容变量 c 被假设为决定样本标签 y 的因素。
- 为了分离内容和风格信息,文章探索了图像增强技术 。通过在潜在风格变量上应用软干预(soft interventions),可以生成增强的图像 ,其中内容信息保持不变而风格信息发生变化。作者开发了一种方法将图像增强技术集成到预训练的CLIP模型中。这是通过设计一个解耦网络(disentangled network)来实现的,该网络使用对比损失(contrastive loss)和图像增强来微调预训练的CLIP模型,从而提取内容特征。
- 鉴于文本数据的语义丰富性和逻辑结构,文章进一步探索了文本增强 。通过文本增强,可以在不改变内容的情况下改变风格因素,这有助于分离出潜在的内容。例如,将文本从"a photo of a dog"变换为"a sketch of a dog"在语言模态中是直接的,而在图像数据中实现类似的变换则具有挑战性。接着,文章提出了对比学习与增强提示CLAP方法 ,它使用预训练的文本编码器和文本增强来训练解耦网络。然后,将训练好的解耦网络转移到CLIP模型的图像编码器上,以提取内容表示。
总结来说,CLAP通过结合因果生成模型、图像和文本增强技术,以及对比学习,有效地从CLIP类模型中分离并提取了内容特征,从而提高了模型在多模态学习中的性能和鲁棒性。
关注你的近邻:免训练的开放词汇语义分割
关键词:通过在CLIP的视觉Transformer的自注意力中强制执行补丁定位实现密集预测
文章总结
尽管深度学习在密集视觉识别问题(如语义分割)上取得了显著进展,但传统方法仍受到固定类别集的限制。与此同时,诸如CLIP(对比语言-图像预训练)之类的视觉-语言基础模型在众多零样本图像级任务中展示了非凡的有效性,这得益于其强大的泛化能力。最近,一些研究工作探讨了将这些模型应用于开放词汇集语义分割(Open-Vocabulary Semantic Segmentation, OVSS)。然而,现有方法往往依赖于不切实际的监督式预训练或需要访问额外的预训练网络。本研究为无需训练的OVSS提出了一种强大的基线方法,称为邻域感知CLIP (Neighbour-Aware CLIP, NACLIP),这是一种针对此情景量身定制的CLIP简单适配方法。本文的方法在CLIP的视觉Transformer的自注意力中强制执行补丁定位 ,尽管这对于密集预测任务至关重要,但在OVSS文献中却被忽视了。通过融入有利于分割的设计选择,我们的方法在不需要额外数据、辅助预训练网络或广泛超参数调优的情况下,显著提高了性能,使其在现实世界应用中具有高度的实用性。我们在8个流行的语义分割基准上进行了实验,并在大多数情况下取得了最先进的性能。
模型解析
- 传统CLIP模型在自注意力模块中学习到的是空间不变性的特征,这对于图像级别的任务(如分类)是有益的,但对于密集预测任务(如语义分割)则不够。NACLIP通过引入空间一致性,改进了自注意力机制,使得模型能够更好地捕捉局部空间信息。
- NACLIP强制执行补丁(patch)在CLIP自注意力中的定位,这是通过修改自注意力模块来实现的,具体如下:(1)引入空间一致性:通过将高斯核(Gaussian kernel)添加到自注意力模块的注意力图中,增强了对每个补丁邻域的关注。(2)修改相似性度量:NACLIP使用基于键(key)向量的点积来计算相似度,而不是传统的基于查询(query)和键(key)的点积。
- 在NACLIP中,移除了CLIP模型中的CLS标记 ,因为在密集预测任务中,该标记对于提取有用的分割信息并不成功。此外,NACLIP简化了CLIP的视觉Transformer的最终编码器块,移除了最终编码器块的前馈网络(feed-forward network),因为其参数是为图像级别任务而非密集预测任务训练的。
通过这些改进,NACLIP能够更好地适应OVSS任务,特别是在没有额外训练数据或预训练网络的情况下,提高了模型对新类别的泛化能力。
天皓智联 开发板商城 视觉等相关设备
.
#SuperVINS
基于深度学习的SLAM前端改进框架拥抱"炼丹"
视觉惯性SLAM领域已经发展出众多突破性的工作,但它们在快速移动环境、弱纹理环境和光照不足的环境中仍存在一些限制。图1展示了经典几何特征和深度学习特征在SLAM中的应用对比。在黑暗环境中,很明显仅提取到有限数量的几何特征,导致地图点稀疏。这是因为传统方法依赖于低级几何特征,在处理复杂环境时存在固有的局限性。
低级几何特征不足以处理复杂环境。先进的深度学习方案可以通过学习和利用场景数据中的隐含特征信息来弥补这一限制。与固定算法模型不同,深度学习模型不需要显式表达这些信息。在SLAM领域,已经有几项结合深度学习算法的工作,这些工作可以分为三类:
- 将深度学习特征应用于视觉里程计:这种解决方案侧重于创建没有传感器融合或回环检测优化的视觉里程计。
- 采用端到端方法:用于视觉里程计,然而这种方法在解释其原理和实现令人满意的姿态估计和映射效果方面面临挑战。
- 将当前的三维重建技术与深度学习结合起来:结合显式或隐式的3D表示方法来感知环境,同时优化姿态。这种方法将场景表达融合到姿态估计中,然而它需要大量的计算能力,并且实时性能较差。
本文介绍的SuperVINS1提出了一种结合深度学习技术的视觉惯性SLAM系统。基于VINS-Fusion框架,这种方法在SLAM的前端和回环检测阶段利用深度学习特征点和描述子。与传统几何特征不同,深度学习特征能够更全面、更可靠地提取图像特征,使其在极端环境中表现尤为出色。此外,使用深度学习特征描述子提高了回环检测的准确性,使本文系统能够更精确地选择回环帧。主要贡献总结如下:
- 改进了VINS-Fusion框架。前端部分用深度学习特征点和描述子取代了原来的几何特征和LK光流跟踪算法,使用了深度学习特征匹配方法进行特征匹配。
- 为应对极端场景,将深度学习特征应用于整个SLAM系统。通过话题发布将深度学习特征有效结合到SLAM的前端和回环检测中。
- 单独训练了SuperPoint的词袋,并针对EuRoC、TUM和KITTI数据集训练了适用于这些数据集的深度学习词袋,为后续研究人员提供了实现回环检测方案的可行思路。
代码仓库链接:https://github.com/luohongk/SuperVINS
具体方法
系统概述
SuperVINS框架基于著名的视觉惯性SLAM框架VINS-Fusion。SuperVINS遵循与VINS-Fusion相同的架构设计,但在其基础上进行了优化和改进。具体流程如图3所示。算法的主要组件包括前端深度学习特征提取和跟踪、后端位置优化以及深度学习回环检测。深度学习特征提取有多种方案可选,这项工作可作为灵活替换深度学习方法的参考。此外提供了使用开源代码DboW3对SuperPoint和XFeat2特征进行词袋训练的示例。
首先,系统输入相机数据和IMU数据。系统利用SuperPoint和LightGlue对两个连续图像帧的特征进行匹配,同时进行预积分。在匹配过程中,使用RANSAC算法优化LightGlue的特征匹配结果。前端优化完成后,特征同时发送到负责回环检测的节点。SuperVINS构建关键帧,随后用于位置估计和优化。位置计算完成后,系统将关键帧的特征、位置和点云图传送到回环检测节点。回环检测节点使用DboW3进行特征检索并执行位图优化。该系统利用深度学习特征提取足够数量的特征点并提高特征匹配质量。相比传统几何特征,使用深度学习特征并通过匹配优化在整个SLAM系统中显著解决了在极端场景中遇到的各种挑战。
特征提取
SuperPoint特征提取网络框架能够提取图像的特征点和对应的描述子。主要过程是对输入图像进行编码,然后对特征点和描述子进行解码。解码以像素卷积的形式进行。整体框架如图2所示。
特征点检测网络作为一个编码器和解码器,对信息进行编码和解码。它为图像中的每个像素分配一个概率,表示其成为特征点的可能性。为了减少计算工作量,采用子像素卷积,因为解码器的计算量更大。类似地,描述子检测网络也作为一个解码器。它首先学习一个半稠密描述子,然后应用双三次插值算法获得完整描述子。最后,使用L2归一化以确保描述的单位长度。网络分为两个分支,损失函数也自然分为两个分支。为了简化训练过程,SuperPoint将两个分支的损失函数结合起来,作为最终损失函数。最终损失函数的具体公式如公式(1)所示:
其中, 是特征点的损失函数, 是描述子的损失函数,系数 用于平衡特征点损失函数和描述子损失函数的权重。
通过这种特征提取方法,SuperPoint能够在图像中准确定位特征点并生成高质量的描述子,为后续的特征匹配和SLAM过程提供坚实的基础。
特征匹配
LightGlue网络概述
LightGlue3是一种快速特征匹配方法。将LightGlue特征匹配方法与其他两种方法进行比较,如图4所示。LightGlue使用一个已经包含两组特征点和描述子的匹配网络,目标是输出图像A和图像B之间的一组对应点。然而,由于遮挡或不重复性,某些关键点可能没有匹配。为了解决这个问题,使用一个软分配矩阵来表示元素之间的关联程度。在这个匹配问题中,软分配矩阵用于表示图像中局部特征的匹配程度。LightGlue由多层组成,这些层在两组特征上操作。每一层由自注意力和交叉注意力单元组成,负责更新每个点的表示。在每一层,分类器决定是否执行推理,从而避免不必要的计算。最后,一个轻量级的头部计算表示集中的部分分配。LightGlue的整体框架如下,对网络细节进行简要介绍。
图像A和B在Transformer中使用自注意力和交叉注意力机制更新层次。每个单元基于从属于集合A,B}的源图像S的消息 更新状态 x_I\^i \\leftarrow x_I\^i + MLP(\[x_I\^im_{I \\leftarrow S\^i\]),其中\|表示向量堆叠。所有点在两张图像中并行计算。自注意力模块从同一图像S = I中提取信息。在交叉注意力单元中,每个图像从其他图像S = {A,B}/I中提取信息。消息m 通过注意力机制作为图像S中所有状态的加权平均值计算。
对于每个点i,当前状态 首先通过不同的线性变换分解为键向量 和查询向量 。然后,计算点i和j之间的注意力得分 。在这种情况下,图像I中的每个点查看另一张图像S中的所有点,并为每个元素计算一个键 ,但不计算查询。注意力得分可以用以下公式表示:
当且仅当两个点都被预测为可匹配点并且它们的相似度高于两张图像中的其他点时,点对(i, j)才有对应关系。损失函数设计如下公式(3):
损失函数公式描述了在训练过程中如何计算损失,以推动模型LightGlue尽早预测正确的对应关系。损失函数由三部分组成,对应于正确匹配和错误匹配的点。
-
计算正确匹配点(i, j) 的预测对应关系 的对数似然损失,其中l是层次信息, 是预测分配矩阵中的元素。
-
计算标记为不可匹配的点属于A的预测可匹配性得分 的对数似然损失,其中 是点i的可匹配性得分。
-
计算标记为不可匹配的点属于B的预测可匹配性得分 的对数似然损失,其中 是点j的可匹配性得分。
-
匹配优化策略
在优化匹配过程中,与传统视觉惯性里程计相比,使用深度视觉特征进行特征提取和匹配可以提取和匹配更多的点对,导致错误匹配点对的数量也增加。通过减小掩码半径来提取更多的匹配特征点对。掩码用于防止特征点过于集中,从而禁止在指定半径内存在其他匹配特征点对。通过减小掩码,可以获得更多、更密集的点对,为后续的RANSAC优化提供更多点对。RANSAC算法的阈值设定为一个非常低的值,施加严格的条件以确保正确匹配,并保证准确匹配点对的质量。
在LightGlue特征匹配网络结束后,需要从匹配结果中随机选择4对特征点,并对每对特征点进行对应匹配。每对特征点在归一化平面上有对应的匹配关系:。其中, 和 是归一化平面上的匹配点对应关系,是同质矩阵。有8个自由度,同时具有尺度等价性。每对匹配点可以生成两个约束方程,因此具有8个自由度的同质矩阵只需4对点对应关系即可求解。为了解决这个问题,构建了一个最小二乘问题。由于尺度等价性,可以直接设置 。接下来,基于同质矩阵计算第一帧图像中特征点在第二帧图像中的重投影坐标,然后比较重投影坐标与匹配特征点坐标之间的距离。如果距离小于某个阈值,则认为是正确匹配点对,否则认为是错误匹配,并记录正确点对的数量。重复多次循环计算同质矩阵和重投影像素点,每次循环后统计正确匹配点对的数量。将最大数量的正确匹配点对情况作为最终结果,去除错误匹配点对,输出正确匹配点对,从而实现特征点匹配筛选。
对于上图中的两幅图像,之前帧的误差投影到下一帧的重投影误差分别为0.2、0.25和0.3。然而,由于掩码半径较大,大多数点需要被消除。当重投影匹配阈值设为0.28时,共有11个点满足条件,这些点被标记为绿色,其重投影误差小于0.28。通过减小掩码半径,可以获得更多特征点。如图5下方的两幅图所示,绿色特征点的数量显著增加。如果阈值设为0.22,匹配精度提高,因为只有重投影误差小于0.22的点才被视为满足条件。在此阈值下,图5下方两幅图匹配时有22个点满足条件,被标记为绿色点,其重投影误差小于0.22。因此,这种优化确保提取足够的点,同时减少匹配点对之间的重投影误差。
回环检测
词袋模型是一种文本表示方法,也用于位置识别。在回环检测中,SuperVINS采用VINS-Fusion中的词袋回环检测方案,但有所不同。SuperVINS使用SuperPoint深度学习特征描述子和更高效的DBoW3。与VINS-Fusion的DBoW2相比,SuperVINS生成词袋的速度更快,并在回环检测过程中实时生成词袋向量。
要生成词袋,首先收集覆盖广泛场景的多样化图像集合,从这些图像中提取深度学习特征描述子,这些描述子将形成高度代表性的词袋。在正式的词袋回环检测中,统计当前关键帧中每个视觉词的出现次数。为了加速识别与输入图像最相似的候选项,词袋使用类似树形的层次索引结构。
这个方法允许SLAM系统在复杂和动态环境中有效地进行位置识别和回环检测,提高整体系统的鲁棒性和精度。
实验效果
总结
SuperVINS是一种利用深度学习改进VINS-Fusion的SLAM系统。在前端和回环检测中引入了SuperPoint和LightGlue,并成功在工程中实现了SuperVINS。为了训练词袋,对数据集进行了单独训练,并灵活实现了DBoW3词袋的训练。使用EuRoC数据集进行了完整的实验,并从定性和定量角度分析了原始算法和改进算法的结果。SuperVINS在各种极端场景下具有更高的定位精度和更强的鲁棒性。
.
#MetaUrban
UCLA出品!用于城市空间的xx人工智能仿真平台
公共城市空间的街道和广场可以为居住在城市中的市民提供各种各样的便捷服务从而适应如今丰富多彩的社会生活。各大城市中的公共空间具有非常不同且广泛的类型、形式和空间大小,包括街道、广场以及公园等各个区域。此外,它们也是日常交通和运输离不开的重要空间。这些重要的城市空间不仅为我们人类日常举办各种社会活动提供了机会,同时也为市民其提供各式各样的休闲娱乐活动。
近年来,随着机器人技术和xx人工智能技术的快速发展使得城市当中的公共区域空间不再是我们人类所独有的区域。比如:移动送餐机器人和电动轮椅已经开始与行人共享人行道、各种各样的机器狗和人形机器人最近也开始在街道上陆续出现,如下图所示。此外各种移动腿式机器人,如波士顿动力公司的机器狗和特斯拉的人形机器人也即将问世。所以在不久的将来极大概率将会出现未来的城市公共空间将由人类和xx人工智能的移动机器共享和共同居住的场景。所以,如果想要在城市空间的繁华街道上进行导航,一个至关重要的问题就是需要确保这些即将到来的移动机器的通用性和安全性。

仿真平台在实现xx人工智能的系统性和可扩展性训练以及在实际部署之前的安全评估方面发挥了至关重要的作用。然而,现有的大多数仿真模拟器主要聚焦于室内家庭环境或者室外的驾驶环境。然而,对于具有多样化布局和物体、行人变化动态复杂的城市空间的模拟探索较少。
基于上述提到的相关问题,本文提出了一个可以用于城市中的空间xx人工智能研究的组合模拟平台,称之为MetaUrban。此外,我们基于设计的MetaUrban仿真平台构建了一个大型的数据集MetaUrban-12K,该数据集包含了12800个训练场景以及1000个测试场景。同时,我们进一步创建了一个包含100个手工设计的从未见过的场景作为测试集来评估我们算法模型的泛化性。相关的实验结果表明,通过模拟环境的组合特性可以显著提高训练好的移动xx人工智能的通用性和安全性。
论文链接:https://arxiv.org/abs/2407.08725网络模型的整体架构&细节梳理
MetaUrban作为一个可以为xx人工智能在城市空间中生成无限训练和评估环境的模拟平台,在详细介绍其内部的各个技术实现细节之前,下图展示了MetaUrban模拟平台整体的生成流程。
MetaUrban模拟平台整体的生成流程
通过上图可以看出,MetaUrban可以根据提供的街区、道路以及人行道,从街区地图开始,通过划分不同的功能区规划地面布局,然后放置静态物体,最后填充动态智能体。此外,MetaUrban模拟器通过提出的三个关键核心设计来支持展示三种独特的都市空间特性。
- Hierarchical Layout Generation:层级布局生成设计可以无限的生成具有不同功能区划分和物体位置的多样性布局,这对于智能体的泛化性至关重要
- Scalable Object Retrieval:可扩展的目标检索利用全球城市场景数据来获取不同地方的真实世界对象分布,然后使用支持VLM的开放词汇搜索构建大规模、高质量的静态对象集。这对于专门针对城市场景的训练智能体有很大的帮助
- Cohabitant Populating:通过采用数字人来丰富行人和弱势道路使用者的外观、运动和轨迹,并整合其他智能体以形成生动的共存环境。这对于提高移动智能体的社会一致性和安全性至关重要
Hierarchical Layout Generation
由于考虑到场景布局的多样性,比如街区的连接和类别、人行道和人行横道的规格以及物体的放置,对于增强经过训练的智能体在公共空间中机动的泛化性至关重要。因此,我们在层级布局生成的设计当中,首先对街区类别进行采样并划分人行道和人行横道,然后分配各种物体,这样我们就可以得到具有任意大小和地图规格的无限城市场景布局。
如下图所示,我们一共设计了5种街区种类,分别是直路、交叉路口、环形交叉路口、环形交叉路口和T型路口。
如上图中的左图所示,我们将人行道划分为四个功能区建筑,分别是建筑区、临街区、空地区和装饰区。根据不同的功能区组合,我们进一步构建了7个典型的人行道模板(如上图的右侧所示)。如果想要形成一条人行道,我们可以先从模板中采样布局,然后为不同的功能区分配比例。对于人行横道而言,我们可以在每条道路的起止处提供候选,支持指定所需的人行横道或通过密度参数对其进行采样。最后,道路、人行道和人行横道可以以地形图为基底,形成不同的地面情况。
在确定好地面上的整体布局之后,我们可以在地面上放置不同的物体。在本文中,我们将物体分为三种类别
- 标准基础设施:标准的基础设施可以包括电线杆、树木和标志和定期沿道路放置的物品
- 非标准基础设施:非标准的基础设施可以包括建筑物、盆景和垃圾箱,随机放置在指定的功能区
- 杂物:杂物可以包括饮料罐、袋子和自行车,随机放置在所有功能区
根据上述的相关划分,我们可以通过指定对象池来获得不同的街道风格,同时通过指定密度参数来获得不同的紧凑度。下图展示了使用采样的地面平面图和对象位置放置的不同物体。
Scalable Object Retrieval
虽然层级布局生成的设计决定了场景的布局以及放置物体的摆放位置。但是,为了使训练后的智能体能够在由各种物体组成的现实世界中导航时具有通用性,放置什么物体同样至关重要。因此,我们首先从网络数据中获取真实世界的对象分布,然后通过基于VLM的开放词汇搜索模式从3D存储库中检索目标。整个流程灵活且可扩展:随着我们继续利用更多网络数据进行场景描述并将更多3D资产作为候选对象,检索到的对象可以缩放到任意大小。
由于城市空间具有独特的结构和物体分布,因此,我们设计了一种真实世界分布提取方法来获得一个描述城市空间中频繁出现的物体的描述池,如下图所示。
具体而言,我们首先利用现成的学术数据集CityScape以及Mapillary Vistas进行场景理解,以获得90个在城市空间中出现频率较高的物体列表。然而,由于上述数据集都是闭集,目标的种类数量是有限的。我们引入了两个开集数据集Google Street以及Urban planning description,用于实现从现实世界中获得更广泛的物体分布。最后,通过结合上述提到的数据集,我们可以构建现实世界的目标类别分布。
为了解决当前的大型3D存储库中存在的数据质量参差不齐、缺少可靠的属性注释以及大部分数据与城市场景无关的问题,我们引入了一种开放词汇搜索方法来解决这些问题,如上图中的右侧子图所示。具体而言,我们首先从Objaverse以及Objaverse-XL中得到目标投影后的多视图图像,然后,我们利用视觉语言模型的编码器分别从投影图像和对象描述池中的采样描述中提取特征,以计算相关分数。然后,我们可以获得相关分数达到阈值的目标对象。这种方法让我们获得了一个城市特定的数据集,其中包含10000个现实世界类别分布中的高质量对象。
Cohabitant Populating
接下来,我们将要介绍如何通过具有不同外观、运动和轨迹的智能体填充这些静态城市场景。我们在提出的MetaUrban模拟器中提供了两种人体动作,分别是日常动作和独特动作。其中,日常动作提供了日常生活中的基本人体动态,即直立、行走和跑步。独特动作是在公共空间中随机出现的复杂动态,例如跳舞和锻炼。对于人类和其他有日常活动的智能体,我们利用ORCA模型以及PR算法来仿真他们的轨迹。
MetaUrban-12K数据集
基于我们提出的MetaUrban模拟器我们构建了MetaUrban-12K的数据集,其中包括了12800个用于训练的交互式城市场景MetaUrban-train以及1000个用于测试的场景MetaUrban-test,下图展示了我们提出的MetaUrban-12K数据集中的一些信息统计。具体关于该数据集的相关详细信息可以参考论文原文。
实验部分
定量实验部分
在实验环节中,我们设计了城市场景中的两个常见任务来验证我们提出的MetaUrban模拟器,分别是点导航以及交互式导航任务。具体而言,在点导航任务当中,智能体的目标是在静态环境中导航到目标坐标,而无需访问预构建的环境地图。在社交导航任务中,智能体需要在包含移动智能体的动态环境中到达点目标。
在所有任务当中,智能体应该避免与其它环境中的智能体发生碰撞或者超出一定的阈值,实验中的智能体行动包括加速、减速以及转向。下表展示了点导航以及交互式导航的Benchmark。
通过上表的相关实验结果可以得出一些结论
- PointNav以及SocialNav任务还未得到很好的解决,基线实现的PointNav和SocialNav任务的最高成功率仅为66%和36%,这表明在MetaUrban组成的城市环境中完成这些任务非常困难。
- 在MetaUrban-12K数据集上训练的模型在未见过的环境中具有很强的泛化能力。在零样本测试的情况下,模型在PointNav和 SocialNav任务中仍可实现平均41%和26%的成功率。由于训练好的模型不仅可以泛化到未见过的物体和布局,还可以泛化到未见过的智能体,因此具有很好的表现性能。同时相关的实验结果也进一步的证明了,MetaUrban的组合特性支持覆盖大量复杂的城市场景,可以成功地增强训练模型的泛化能力
- 由于移动环境智能体的动态特性,SocialNav任务比PointNav任务更有难度。平均而言,从PointNav任务到SocialNav任务,成功率下降了15%,这表明动态智能体对训练好的智能体提出了重大挑战
- 在所有任务和设置当中,Safe RL模型取得了最佳表现,表明这些模型能够成功避免与行人和物体发生碰撞。然而,成功率会相应降低,这表明需要平衡复杂城市场景中智能体的安全性和有效性。
此外,为了评估使用MetaUrban生成的数据训练的智能体的泛化能力,我们比较了四种设置的成功率,相关结果汇总在下图的子图(a)中。设置1和设置2分别是在MetaUrban-train数据集上进行训练,在MetaUrban-test测试集和MetaUrban-unseen数据集上进行测试的结果。设置3和设置4是在MetaUrban-finetune上直接训练的结果,并在MetaUrban-finetune上对MetaUrban-train上的预训练模型进行微调的实验结果。
我们为了评估MetaUrban组合架构的扩展能力,我们在不同数量的生成场景上训练模型,如下图的子图(b)所示,随着我们加入更多场景进行训练,性能从12%显著提高到46%,证明了MetaUrban强大的扩展能力。
下图中的子图(c)和(d)展示了我们为了评估静态物体密度和动态环境智能体的影响,我们分别评估了它们在PointNav和 SocialNav任务中的不同比例,通过实验结果可以看出,随着静态物体和动态智能体的密度增加,训练和测试的成功率都会急剧下降,这表明智能体在面对城市场景中拥挤的街道时面临挑战。
定性实验部分
下图展示了我们提出的MetaUrban模拟器一些生成结果的可视化,详细的介绍请参考我们论文中的附录部分。
- 我们设计了五种典型的街道街区类别,分别是直路、弯道、交叉路口、T 型路口和环形交叉路口,可视化结果如下图所示
- 生成的静态场景下的可视化样例,对于每一行我们选择了四个视角来进行可视化
- 生成的动态场景下的可视化样例
结论
在本文中,我们提出了一种新颖的组合模拟器MetaUrban用于促进城市场景中的xx人工智能和机器人研究相关方向的研究。提出的MetaUrban模拟器可以生成具有复杂场景结构和行人及其他移动智能体多样化运动的无限城市环环境,希望本文提出的方法可以促进开源模拟器社区的进一步发展。
.
#Mobileye,越来越难了
Mobileye面临的,可能是一个越来越难的未来。
刚刚发布的财报中,Mobileye营收规模4.39亿美元,同比下降3%,净亏损8600万元,较上年同期增加超过2倍,调整后净利润7600万美元,同比也下降44%。
关键数据指标,并不理想。
尽管,由于Mobileye客户此前存货已经消耗的差不多了,第二季度整体情况较上个季度有显著提升,但Mobileye还是下调了包括营收、出货量以及经营利润在内的全年关键指标预期。
下调的理由是,近期的市场环境充满挑战性,这主要"与中国有关"。
简单来说,就是Mobileye分析,包括中国这个关键市场在内的全球主要主机厂,下调了出货量预期。
不过,Mobileye也在财报会上透露了一点点好消息,关于其下一代解决方案,基于EyeQ 6芯片开发的Mobileye Brian 6自动驾驶。
但这套系统对于Mobileye业务大规模的增益,要等到2026年,似乎有点远、有点不确定。
01 平淡的财务数据与下调的预期
先简单梳理一下Mobileye在今年第二季度的经营情况。
Mobileye部分财物信息
**财报显示,今年第二季度,Mobileye整体营收规模为4.39亿美元,同比下降3%;不过较上个季度的2.39亿美元增加了84%。**
对此Mobileye在财报中解释,与第一季度相比,一级客户手中的过剩库存消耗减少(这是由于在疫情期间下游客户为针对不稳定的芯片产业链而囤积的库存)。
同时Mobileye CEO Amnon Shashua还在财报会中表示,此前困扰其经营情况的客户库存问题已经基本得到了解决,这带来的一个影响是,Mobileye出货量的提升,与今年第一季度的360万套相比,Mobileye的EyeQ系列出货量强势增长110%,也就是达到756万套。
但与去年同期相比,这个出货量水平应该还没有完全恢复。Mobileye财报显示,其与EyeQ SoC相关的营收较去年同期减少10%。
当然不完全是坏消息,Mobileye在今年第二季度的平均系统价格,由去年同期的51.7美元上升到到第二季度的54.4美元。
**单价提升主要归功于高溢价的产品有所增长,比如Super Vision系统。可想而知,这与极氪的强势销量有很大关系。**
毛利率方面,今年第二季度为48%,较去年同期下降1.73个百分点。
Mobileye支出情况
在支出方面,Mobileye第二季度的运营支出总额为3.03亿美元,其中研发支出为2.56亿美元,较去年同期的2.11亿美元增加21.3%,占到支出的大头。
**最终落到盈利层面,财报显示,第二季度Mobileye净亏损8600万元,较上年同期增加超过2倍,调整后净利润7600万美元,同比也下降44%。**
整体来看,在过去几个月影响Mobileye经营情况最大的问题,过剩库存已经得到了基本解决,大部分的营业指标也基本恢复到去年同期的水平。
但是,在今年的全年预期上,Mobileye给出了一个不那么乐观的数字。
**Mobileye表示,预计今年全年EyeQ芯片的出货量将在2800万-2900万套;Super Vision系统的出货量预计为11万-13万套。预计全年营收16亿-16.8亿美元;调整后营业利润1.52亿-2.01亿美元。**
从销量到基本的财务数据,基本都出现了比较低预期情况。
作出如此的预期,主要出于几点考虑,基本都围绕中国市场:
首先是全球多家OEM大幅下调了今年下半年的产量预期;其次中国市场的主机厂今年下半年的订单,与上一次这些客户所表示的有所下降;最后则是除了中国之外的其他全球主要市场,大批量推出ADAS系统的延迟也将是一个不利因素。
Mobileye8月1日股价出现大跳水
预期不及此前市场的期待,Mobileye的股价也在最近几日出现大幅跳水。8月1日财报发布当天,Mobileye开盘报18.28美元股,下跌超过12%,在随后的8月2日,股价仍在继续下跌,截止到8月2日收盘已不足16美元/股。
02 Mobileye财报会,剧透未来技术
或许是给不太正面的财报数据来点好消息对冲一下,在财报会上,Amnon Shashua带来了Mobileye技术层面的一些剧透。
Mobileye首席执行官Amnon Shashua
具体来说,就是Mobileye Brain 6,一套基于EyeQ6的软件解决方案,在Amnon这里被看作是Mobileye自动驾驶技术的重大进步与革新,按照计划,这套方案将在今年12月进行披露。
据Amnon透露,Brain 6从几年前开始开发,一直是EyeQ6产品线的核心。这套混合AI骨干网络旨在解决大规模自动驾驶的复杂性和需求。
Amnon表示,在性能方面,Brain 6应用不同的生成式AI网络组合,应对自动驾驶的复杂情况,比如长尾问题和输入偏差泛化误差权衡,通过这种方法,Brain 6可以确保足够的性能和稳定性。
**最新的进展是,今年第二季度,Mobileye已经开始了在EyeQ6平台上大规模线上测试和模拟。**
**另外,这套方案也符合当下市场所追求的性价比要求。具体来说,Brain6 与 EyeQ6 的协调,可以使客户能够以MSRP(制造商建议零售价 ,这里可以简单类比或倒推为成本的概念)的50%提供无需眼睛监控(自动驾驶)产品。**
同时,这套基于纯视觉的方案,采用模块化架构,可以适配单独的感知层以及各类传感器的配置,以此满足不同主机厂和不同车型的搭载需求。
据了解,Brain 6的数据来源于与Mobileye合作的全球各大主机厂多年收集的数百PB数据支持,以此应对自动驾驶的复杂场景,并在全球不同地区保证统一的性能。
只言片语的技术讲解并不具备连贯性,所以Brain 6具体的技术细节要等到今年年底才能全部揭开。
Mobileye REM地图方案
按照我们的理解,不出意外的话,这将是一套纯视觉为基础的自动驾驶技术,同时Mobileye还透露该方案会有众包高精地图的参与。
不过,会不会采用当下比较火热的端到端大模型依然很不好说,毕竟在此之前,Mobileye在多次发声中,都始终对端到端持保留态度。
而Brain 6软件方案大规模上车产生增益,Mobileye将时间定在了2026年。
03 新技术,还是太慢了?
2026年,听起来还相当遥远,与Mobileye一贯给人的印象一样,总是慢人一步。
Mobileye产品规划
对比此前的EyeQ5和最近的EyeQ6,无一不是如此。尤其是算力层面,到EyeQ 5也不过24TOPS,同期英伟达的主推产品OrinX已经超过200TOPS。
后续的EyeQ6系列,最高176TOPS的算力,依然是一步慢、步步慢。
**软件层面也是如此,至少在当下,Mobileye还是上个阶段规则代码或者小模块的形式。至于竞争者,不管端到端是否会成为自动驾驶终极的解决方案,但至少已经有大部分玩家开始了尝试。**
小规模的落地也在近期出现。
至于效果,有业内人士告诉《赛博汽车》从理论上来讲,过去多个小模型层层传递的做法,天花板会越来越逼近,不管从技术还是成本上,都不会是理想的方案。
端到端大模型,从我们的实际体验来看,至少现在能看到的潜力会比上一代更优。
**Mobileye的新方案是否会比端到端更优,现在不好评论,而大规模验证,如Mobileye所言,要等到2026年。**
**但现在,Mobileye面临的已然是一个群狼环伺的局面。一方面大环境中短期的不利好;另一方面,在ADAS中低算力的市场上,Mobileye要面对的对手,已经越来越多了。**
比如拿下大算力市场又盯上下沉市场的英伟达,以及同样以中低算力见长的高通、德州仪器,和国内的地平线之类的厂商。
内外都说不上乐观,Mobileye的2026年,是否太拖沓了点?
.
#SA4D
首个基于4DGS分割任何事物的框架!
华科&华为&上交团队最新的工作《Segment Any 4D Gaussians》,主要应用于4D动态场景的分割任务,结合4DGS效果很惊艳~
建模、理解和重建现实世界在XR/VR中至关重要。最近3DGS方法在建模和理解3D场景方面取得了显著成功。同样,各种4D表示已经证明了捕捉4D世界动态的能力。然而,很少有研究关注4D表示中的分割。本文提出了Segment Any 4D Gaussians(SA4D),这是基于4D Gaussian分割4D数字世界中anything的首批框架之一。在SA4D中,引入了一个高效的时间identity特征场来处理高斯伪影,有可能从噪声和稀疏输入中学习精确的identity特征。此外,还提出了一种4D分割细化过程来消除伪影。我们的SA4D在4D高斯中在几秒钟内实现了精确、高质量的分割,并显示了去除、重新着色、合成和渲染高质量任何mask的能力。
项目主页:https://jsxzs.github.io/sa4d/
总结来说,本文的主要贡献如下:
- 我们重新表述了4D分割的问题,并提出了Segment-Any 4D Gaussians(SA4D)框架,以高效地将SAM提升到4D表示。
- 时间identity特征字段包括一个紧凑的网络,该网络从噪声特征图输入中学习高斯人的身份信息,并缓解高斯伪影。分割细化过程还提高了推理渲染速度,使场景操作更简单、更方便。
- SA4D使用RTX 3090 GPU在10秒内实现快速交互式分割,具有照片级逼真的渲染质量,并无缝实现高效的动态场景编辑操作,例如删除、重新着色和合成。
相关工作回顾
3D/4D表示。模拟真实世界的场景一直是学术界广泛研究的课题。提出了许多方法]来表示现实世界的场景并取得了显著的成功。NeRF及其扩展被提出,即使在稀疏、过曝的情况下,也能呈现高质量的新颖视图,并在许多下游任务中显示出巨大的潜力。基于网格的表示将NeRF的训练从几天加速到几小时甚至几分钟。几种方法也成功地对动态场景进行了建模,但在体渲染方面受到了影响。基于高斯Splatting(GS)的表示法在保持高训练效率的同时,将渲染速度实时化。使用高斯散斑对动态场景进行建模有几种方法:增量平移、时间扩展和全局变形。在本文中,我们选择全局变形GS表示4D-GS作为我们的4D表示,因为它拥有全局规范3D高斯作为其几何形状,并且能够对单目/多视图动态场景进行建模。变形的3D高斯图像的分割结果也可以很容易地转换为其他时间戳。
基于NeRF/高斯的3D分割。在3D高斯之前,许多研究已经将NeRF扩展到3D场景理解和分割。Semantic-NeRF首先将语义信息整合到NeRF中,并从嘈杂的2D标签中实现了3D一致的语义分割。然后,后续的研究通过引入实例建模但依赖于GT标签,开发了目标感知的隐式表示。为了实现开放世界场景理解和分割,有几种方法将2D基础模型中的2D视觉特征提取到辐射场中。然而,这些方法无法分割语义相似的目标。因此,一些方法采用了SAM令人印象深刻的开放世界分割能力。在分割过程之后,可以遵循修复过程来提取高质量的目标表示。从来没有,上述所有方法都局限于3D静态场景。然而,在4D表示上直接使用3D分割方法也可能陷入高斯漂移。我们的方法通过维护一个身份编码特征场来解决高斯漂移问题,该特征场模拟了语义信息的变形。
动态场景分割。很少有研究人员深入研究动态场景分割。NeuPhysics只允许对动态背景或静态背景进行完全分割。最近,4D Editor将DINO特征提取为混合语义辐射场,并对每帧进行2D-3D特征匹配和递归选择细化方法,以实现4D编辑。但是,编辑一帧需要1-2秒。此外,需要动态前景的地面真实掩模来训练混合语义辐射场。这些限制限制了它的实际适用性。在这项工作中,我们提出了一种新颖的4D分段任意框架,可以实现高效的动态场景编辑操作。例如重新着色、去除、合成。
准备工作
问题定义
由于之前很少有主要关注4D分割的工作,因此有必要重新制定。值得注意的是,4D表示在分割方面显示出其弱点,我们将4D分割定义如下:
问题:给定在数据集L上训练的任何基于变形的4D高斯表示O,问题是找到一个有效的解决方案A。目标应满足以下几个特征:
当在任何视图V处光栅化目标o时,的splatted图像应对应于真实ID分割:
Gaussian Grouping
Gaussian Grouping扩展了Gaussian Splatting,以连接重建和分割开放世界3D场景中的任何东西。它为每个高斯引入了一个新的参数,即identity编码,用于对3D-GS中的任何内容进行分组和分割。然后,这些身份编码与其他属性一起附加到3D高斯分布图上。类似于在3中渲染RGB图像,将3D高斯映射到特定的相机视图,并通过differential splatting算法S计算像素p的2D identity feature :
4D Gaussian Splatting
4D-GS扩展了3D-GS以有效地对动态场景进行建模,这些场景通过紧凑的表示O来表示4D场景。在时间戳t,3D高斯的时间和空间特征通过时空结构编码器进行编码:
然后,变形解码器D使用三个单独的MLP来计算高斯位置、旋转和缩放的变形:
为此,我们将4D-GS的出口流程定义为:
SA4D方法详解
整体框架
我们的关键见解是引入一种表示方法,对来自预训练基础模型V的时间语义信息进行编码,以帮助导出过程,因为4D-GS中的分割无法承受命题3。在SA4D中,我们对导出过程进行了如下改进:
Identity Encoding Feature Field
为了缓解floater,我们提出了一种identity特征场网络,用于在每个时间戳对身份特征进行编码。给定时间t和规范空间中3D高斯G的中心位置X作为输入,时间恒等特征场网络预测每个高斯的低维时变恒等特征e:
监督来自像素的identity,我们使用一个微小的卷积解码器和softmax函数来预测高斯identity f,如方程式(12)所示:
优化。由于很难访问GT 4D目标标签,我们无法用o来监督训练过程。因此,我们采用2D伪分割结果作为监督。
6中的3D正则化损失L3d被应用于进一步监督3D目标内和高度遮挡的高斯分布。
4D Segmentation Refinement
后处理。尽管时间身份特征场网络显示出对3D高斯时间身份特征进行编码的能力,但导出过程仍然受到严重遮挡和不可见高斯以及噪声分割监督的影响。为了得到一个更精确的G',它类似于o,我们采用了两步后处理。第一步是去除异常值,与4,6相同。然而,如2所述,在两个目标之间的界面上仍然存在一些模糊的高斯分布,它们不会或只会略微影响定量结果,但会影响几何体o'。因此,在第二步中,类似于2,我们利用2D分割监督Imask来消除这些模糊的高斯分布。具体来说,我们为每个高斯g分配一个掩模m渲染3D点掩模,并在2中应用mask投影损失:
Gaussian Identity Table。通过隐式身份编码场网络并在推理过程中逐帧执行后处理,对于场景编辑来说既耗时又不方便。因此,我们建议将每个训练时间戳的分割结果存储在高斯恒等式表M中,并采用推理过程中最接近的时间戳插值,如方程式(16)所示:
具体来说,训练后,用户可以输入目标ID。我们的方法根据目标的身份编码,在每个训练时间戳分割出属于该目标的4D高斯分布。最终分割结果存储在高斯恒等式表中。在大多数情况下,此过程可以在10秒内完成,并显著提高推理过程中的渲染速度。4D分割细化的细节在算法2中。
实验
动态场景编辑的效果如下:
消融结果的可视化:
限制
虽然SA4D可以在4D高斯中实现快速高质量的分割,但存在一些局限性,可以在未来的工作中加以探索。
- (1)与Gaussian Grouping类似,选择目标需要一个标识号作为提示,与"点击"或语言相比,这会导致选择所需目标的困难。
- (2)变形场无法在目标级别进行分解,因此需要整个变形网络参与分割和渲染过程。
- (3)不同视频输入之间的掩码身份冲突使得有效使用多视图信息变得困难。
- (4)与3D分割类似,由于3D高斯的特征,目标伪影仍然存在。
结论
本文提出了一种Segment-Any-4D高斯框架,以实现4D-GS中快速精确的分割。通过4D-GS和时间身份特征场网络,将不同时间戳下世界空间的语义监督转换为规范空间。时间身份特征域网络还解决了高斯漂移问题。SA4D可以渲染高质量的新颖视图分割结果,还支持一些编辑任务,如目标删除、合成和重新着色。
#SLAM的最终形态应该是什么样的?
建图:输入传感器数据,输出一个地图。不断输入新的数据,就会不断输出新的地图。
- 这个过程叫"建图"还是叫"训练",不重要。传感器数据就是很多的token,地图就是一张图。
- 地图也不必长的真的跟图一样,不必真的给人看,就是一堆数据或者一个模型。
定位:给定一个地图模型,输入传感器数据,输出该数据对应的pose。输入连续的数据,能输出连续的pose。
- 同样的,这个过程叫"定位"还是叫"推理",也不重要。
- 中间计算过程也不重要,跑滤波器/图优化还是跑模型推理,都无所谓。
- 连续性是重要的。输入时间上相邻的数据,输出也得在空间上相邻。
这大概是比较本质意义上的slam。
现在传统方法的难点是:
- 传统方法原理没啥变化,都在搞corner case。搞不定的就真搞不定,没什么解法。
- 传统方法没法随数据增长有明显的性能提升。
新方法的问题是:
- 不够通用,性能跟数据分布相关,而传统方法几乎是无限通用的,跟数据无关。
- 性能不够:在千元级别硬件上,建图至少要到100ms/帧,定位至少要在20ms/帧,才有可能落地。目前训练至少达不到,推理过程兴许可以。
- 不好解bug,出了问题只能多加数据,不像传统方法通常能给出根本原因,知道怎么调。
大部分新方法都处在比较尴尬的情况:传统方法搞的定的,他可能百分之七八十搞的定。传统方法搞不定的,他可能也是百分之六七十搞的定。但下游的应用通常期望你在搞的定的场景下百分之百搞得定,搞不定的场景可以不卖。
当然这一切原因很可能就是,单纯的,数据不够多,模型不够大,端上性能不够强,然后slam也没怎么搞过几十T带真值pose的数据,花个几百万去训的。没这个动力。
未来主流肯定是数据驱动的方法 。在滤波器人肉调那些噪声参数肯定比不上让GPU一口气帮你弄上几百万个数一块儿调(两者本质算是一回事)。
重建神器
我们找到了最具性价比的3D扫描仪,支持方便的二次开发,传感器有激光雷达、超高精度9DOF IMU、RTK、双广角相机、深度相机。
#自动驾驶大模型方案
视觉语言模型VLM工作一览,面向量产和研究~
视觉语言模型(Vision-Language Model, VLM) 正以其独特的跨模态理解与推理能力,成为赋能下一代自动驾驶系统的关键引擎。VLM的核心在于打通视觉与语言之间的壁垒,让自动驾驶不仅能"看见"道路,更能像人类一样"理解"场景、意图并进行深层次的推理。
在自动驾驶的复杂环境中,VLM展现出强大的应用潜力:
- 环境感知与深度理解: VLM能够超越传统视觉模型,结合相机图像或视频流,理解交通场景中的语义信息。例如,它不仅能识别物体是"车"或"人",更能理解"行人正在挥手示意过马路"、"前方车辆正在打开双闪可能抛锚"、"路牌上的文字是'学校区域减速慢行'"等复杂语义,为系统提供更丰富、更贴近人类认知的环境模型。
- 场景描述与决策解释: VLM可以将复杂的视觉场景转化为清晰的自然语言描述,为自动驾驶系统的决策提供可解释性。这不仅有助于开发调试(理解系统"为何"做出某个决策),也为乘客或监管者提供透明的驾驶意图说明(如"我正在变道以避开前方施工区域"),增强信任感。
- 复杂指令理解与交互: 面向未来的智能座舱和人车交互,VLM是实现自然语言交互的核心。乘客或远程监控员可以通过口语化指令(如"在下一个便利店门口靠边停一下"、"小心右边突然冲出来的自行车")与车辆沟通,VLM能准确理解意图并指导系统执行或预警。
CrashAgent
- 标题:CrashAgent: Crash Scenario Generation via Multi-modal Reasoning
- 链接:https://www.arxiv.org/abs/2505.18341
- 作者单位:卡内基梅隆大学、NVIDIA、西北大学
自动驾驶算法的训练与评估需要多样化的场景。然而,现有数据集主要包含人类驾驶员展示的正常驾驶行为,导致安全关键案例数量有限。这种通常被称为长尾分布的不平衡性,限制了驾驶算法从涉及风险或失效的关键场景中学习的能力------而这些场景对于人类高效提升驾驶技能至关重要。为生成此类场景,本文利用多模态大语言模型 (Multi-modal Large Language Models) 将事故报告转换为结构化场景格式,该格式可直接在仿真环境中执行。具体而言,本文提出了 CrashAgent,一个多智能体框架 (multi-agent framework),旨在解析多模态的真实世界交通事故报告,以生成道路布局以及自车(ego vehicle)和周围交通参与者的行为。本文从多个角度全面评估生成的碰撞场景,包括布局重建准确性、碰撞发生率和多样性。最终产生的高质量、大规模碰撞数据集将公开提供 (publicly available),以支持开发能够处理安全关键情况的自动驾驶算法。
算法概览:
主要实验结果:
CurricuVLM
- 标题:CurricuVLM: Towards Safe Autonomous Driving via Personalized Safety-Critical Curriculum Learning with Vision-Language Models
- 链接:https://arxiv.org/abs/2502.15119
- 项目主页:https://zihaosheng.github.io/CurricuVLM/
- 作者单位:美国威斯康星大学麦迪逊分校,普渡大学,谷歌
确保自动驾驶系统的安全仍然是一个关键挑战,尤其是在处理罕见但可能灾难性的安全关键场景时。虽然现有研究探索了为自动驾驶车辆(AV)测试生成安全关键场景,但如何有效地将这些场景纳入策略学习以增强安全性的工作仍然有限。此外,开发适应自动驾驶车辆不断演化的行为模式与性能瓶颈的训练课程在很大程度上尚未被探索。为应对这些挑战,本文提出了 CurricuVLM,一个利用视觉语言模型(VLMs) 为自动驾驶智能体实现个性化课程学习的新颖框架。本文的方法独特地利用了VLMs的多模态理解能力来分析智能体行为、识别性能弱点,并动态生成量身定制的训练场景以进行课程适应。通过对不安全驾驶情境的叙事描述进行综合分析,CurricuVLM执行深入推理以评估自动驾驶车辆的能力并识别关键行为模式。该框架随后合成针对这些已识别局限性的定制化训练场景,从而实现有效且个性化的课程学习。在Waymo Open Motion数据集上进行的大量实验表明,CurricuVLM在常规和安全关键场景下均优于最先进的基线方法,在导航成功率、驾驶效率和安全性指标方面均取得了卓越性能。进一步分析揭示,CurricuVLM可作为通用方法,与各种强化学习(RL)算法集成以增强自动驾驶系统。
算法概览:
主要实验结果:
From Accidents to Insights
- 标题:From Accidents to Insights: Leveraging Multimodal Data for Scenario-Driven ADS Testing
- 链接:https://arxiv.org/abs/2502.02025
- 作者单位:麦考瑞大学,北德克萨斯大学
自动驾驶系统(ADS)的快速发展亟需鲁棒的软件测试来确保安全性和可靠性。然而,自动化生成可扩展且具体的测试场景仍是重大挑战。当前基于场景的测试用例生成方法常面临场景不真实、车辆轨迹不准确等局限,主要源于数据提取过程中的地图信息丢失,以及缺乏有效机制缓解大语言模型(LLM)的幻觉问题。本文提出 TRACE(基于关键场景的ADS测试用例生成框架),通过利用多模态数据从真实车祸报告中提取高挑战性场景,以较少数据构建大量关键测试用例,显著提升ADS缺陷检测效率。结合上下文学习、思维链提示和自验证技术,本文利用LLM从事故报告中提取环境与路网信息;在车辆轨迹规划中,集成含地图信息和车辆坐标的数据作为知识库,构建具备路径规划能力的LLM模型 TraceMate。基于50份真实事故报告,本方法在MetaDrive和BeamNG仿真平台上成功测试三种ADS模型。在生成的290个测试场景中,127个被识别为关键场景(引发车辆碰撞)。用户反馈表明,TRACE的场景重建准确率显著优于现有技术------77.5%的场景被评为"基本"或"完全"一致,而最佳基线方法SOTA-LCTGen仅达27%。
算法概览:
主要实验结果:
Generating OOD
- 标题:Generating Out-Of-Distribution Scenarios Using Language Models
- 链接:https://arxiv.org/abs/2411.16554
- 作者单位:麻省理工学院,马萨诸塞大学阿默斯特分校 ,丰田研究院
由机器学习技术驱动的自动驾驶汽车的部署,需要在多样化的现实世界环境中进行广泛测试,稳健处理边缘案例和分布外(Out-Of-Distribution, OOD)场景,并进行全面的安全验证,以确保这些系统在不可预测条件下能够安全有效地行驶。解决分布外(OOD)驾驶场景对于提升安全性至关重要,因为OOD场景有助于验证车辆自主系统技术栈中模型的可靠性。然而,由于OOD场景在长尾分布中的稀疏性及其在城市驾驶数据集中的罕见性,生成此类场景极具挑战性。近期,大语言模型(Large Language Models, LLMs)在自动驾驶领域展现出潜力,特别是在零样本泛化(zero-shot generalization)和常识推理(common-sense reasoning)能力方面。本文利用LLMs的这些优势,提出一个用于生成多样化OOD驾驶场景的框架。本文的方法利用LLMs构建一个分支树结构(branching tree),其中每条分支代表一个独特的OOD场景。这些场景随后通过一个自动化框架在CARLA仿真器中实现,该框架确保场景增强(scene augmentation)与相应的文本描述保持一致。本文通过广泛的仿真实验评估了该框架,并采用一个衡量场景丰富度的多样性指标(diversity metric)来评估其性能。此外,本文引入了一种新的"OOD偏离度"(OOD-ness)指标,用于量化所生成场景偏离典型城市驾驶条件的程度。进一步地,本文探索了现代视觉语言模型(Vision-Language Models, VLMs)在解读所仿真的OOD场景并实现安全导航方面的能力。本文的研究结果为语言模型在解决城市驾驶背景下OOD场景问题中的可靠性提供了有价值的见解。
算法概览:
主要实验结果:
From Dashcam Videos to Driving Simulations
- 标题:From Dashcam Videos to Driving Simulations: Stress Testing Automated Vehicles against Rare Events
- 链接:https://arxiv.org/abs/2411.16027
- 作者单位:丰田北美研究院,伊利诺伊大学厄巴纳 - 香槟分校
在仿真环境中使用真实的驾驶场景测试自动驾驶系统(ADS)对于验证其性能至关重要。然而,将真实世界的驾驶视频转化为仿真场景面临重大挑战,这源于高维视频数据解释的复杂性以及精确手动场景重建的耗时性。在本研究中,本文提出了一种新颖的框架,可自动将真实世界的车辆碰撞视频转换为用于ADS测试的详细仿真场景。本文的方法利用提示工程优化的视频语言模型(VLM),将行车记录仪(dashcam)视频片段转换为SCENIC脚本。这些脚本定义了CARLA仿真器中的环境和驾驶行为,从而能够生成逼真的仿真场景。重要的是,本文的框架并非单纯追求一对一的场景重建,而是侧重于从原始视频中捕捉核心驾驶行为,同时提供天气或道路条件等参数的灵活性,以支持基于搜索的测试。此外,本文引入了一种相似性度量指标,通过比较真实视频与仿真视频之间驾驶行为的关键特征来提供反馈,从而迭代地优化生成的场景。本文的初步结果表明,该方法具有显著的时间效率,可在数分钟内完成全自动、无需人工干预的真实到仿真(real-to-sim)转换,同时保持对原始驾驶事件的高保真度。
算法概览:
主要实验结果:
OmniTester
- 标题:Multimodal Large Language Model Driven Scenario Testing for Autonomous Vehicles
- 链接:https://arxiv.org/abs/2409.06450
- 作者单位:清华大学,公安部道路交通安全研究院
极端案例(corner cases)的生成对于自动驾驶车辆(AV)道路部署前的高效测试至关重要。然而,现有方法难以满足多样化的测试需求,且普遍缺乏对未知场景的泛化能力,从而降低了生成场景的实用性与可用性。本研究提出 OmniTester:一种基于多模态大语言模型(LLM)的框架,充分利用LLM的世界知识与推理能力,在仿真环境中生成高真实性与多样化的测试场景。除提示工程外,本文集成交通仿真工具SUMO以简化LLM生成的代码复杂度,并引入检索增强生成(RAG)与自改进机制,增强LLM对场景的理解能力,提升生成场景的真实性。实验证明,该方法在生成三类复杂挑战性场景时具备优异的可控性与真实性,同时依托LLM的泛化能力,成功实现了基于事故报告的新场景重建。
算法概览:
主要实验结果:
DriveGenVLM
- 标题:DriveGenVLM: Real-world Video Generation for Vision Language Model based Autonomous Driving
- 链接:https://ieeexplore.ieee.org/abstract/document/10786438
- 作者单位:哥伦比亚大学
自动驾驶技术的进步亟需更先进的方法来理解和预测现实场景。视觉语言模型(VLMs)作为革命性工具崭露头角,在自动驾驶领域展现出巨大潜力。本文提出DriveGenVLM框架,通过生成驾驶视频并利用VLMs进行场景理解。为实现这一目标,本文采用基于去噪扩散概率模型(DDPM)的视频生成框架,旨在预测真实世界视频序列。随后通过预训练模型"第一人称视角视频高效上下文学习"(EILEV)评估生成视频在VLMs中的适用性。该扩散模型基于Waymo开放数据集训练,并采用弗雷歇视频距离(FVD)指标评估生成视频的质量与真实性。EILEV为生成视频提供场景描述,这些描述在自动驾驶领域具有重要价值:可增强交通场景理解能力、辅助导航决策并提升路径规划能力。DriveGenVLM框架将视频生成与VLMs深度融合,标志着利用先进人工智能模型解决自动驾驶复杂挑战的重大突破。
WEDGE
- 标题:WEDGE: A multi-weather autonomous driving dataset built from generative vision-language models
- 链接:https://arxiv.org/pdf/2305.07528
- 项目主页:https://infernolia.github.io/WEDGE
- 作者单位:卡内基梅隆大学,印度共生国际大学
开放道路环境对自动驾驶感知提出了诸多挑战,其中极端天气条件导致的低能见度尤为突出。在良好天气数据集上训练的模型,在面对这些分布外(out-of-distribution)场景时,其检测性能往往显著下降。为增强感知系统的对抗鲁棒性(adversarial robustness),本文提出了 WEDGE(WEather images by DALL-E GEneration):一个通过提示(prompting)利用视觉语言生成模型构建的合成数据集。WEDGE 包含 3360 张图像,涵盖 16 种极端天气条件,并手工标注了 16513 个边界框,支持天气分类和 2D 目标检测任务的研究。本文从研究角度分析了 WEDGE,验证了其对于极端天气自动驾驶感知的有效性。本文为分类和检测任务建立了基线性能,测试准确率达到 53.87%,平均精度(mAP)达到 45.41。最重要的是,WEDGE 可用于微调(fine-tune) 最先进的检测器,在真实世界天气基准测试(如 DAWN)上,将 SOTA 性能提升了 4.48 AP(对于卡车等生成效果良好的类别)。WEDGE 的收集遵循 OpenAI 的使用条款,并以 CC BY-NC-SA 4.0 许可协议公开发布。
算法概览:
主要实验结果:
CBR-LLM
- 标题:Case-based Reasoning Augmented Large Language Model Framework for Decision Making in Realistic Safety-Critical Driving Scenarios
- 链接:https://arxiv.org/abs/2506.20531
- 作者单位:NICT
在安全关键场景中驾驶需要快速、具有情境感知的决策,这种决策既要基于情境理解,又要依托经验推理。大语言模型(LLMs)凭借其强大的通用推理能力,为这类决策提供了颇具前景的基础。然而,由于在领域适配、情境锚定以及缺乏在动态、高风险环境中做出可靠且可解释决策所需的经验知识等方面存在挑战,它们在自动驾驶中的直接应用仍受到限制。为填补这一空白,本文提出了一种基于案例推理增强的大语言模型(CBR-LLM)框架,用于复杂风险场景中的规避机动决策。我们的方法将行车记录仪视频输入中的语义场景理解与相关过往驾驶案例的检索相结合,使 LLMs 能够生成既符合情境又与人类行为一致的机动建议。在多个开源 LLMs 上进行的实验表明,我们的框架提高了决策准确性、推理合理性以及与人类专家行为的一致性。风险感知提示策略进一步提升了在不同风险类型下的性能,而基于相似度的案例检索在引导上下文学习方面始终优于随机抽样。案例研究进一步证明了该框架在具有挑战性的现实世界条件下的稳健性,突显了其作为智能驾驶系统中一种自适应且可信的决策支持工具的潜力。
算法概览:
主要实验结果:
FutureSightDrive
- 标题:FutureSightDrive: Thinking Visually with Spatio-Temporal CoT for Autonomous Driving
- 链接:https://arxiv.org/abs/2505.17685
- 项目主页:
- 作者单位:阿里巴巴集团高德,西安交通大学,阿里巴巴集团达摩院
视觉语言模型(VLMs)凭借其强大的推理能力在自动驾驶领域引起了越来越多的关注。然而,现有的视觉语言模型通常采用针对当前场景的离散文本思维链(CoT),这本质上是对视觉信息的高度抽象和符号化压缩,可能导致时空关系模糊和细粒度信息丢失。自动驾驶的建模是否更适合基于真实世界的模拟与想象,而非纯粹的符号逻辑。本文提出一种时空思维链推理方法,使模型能够进行视觉化思考。首先,视觉语言模型作为世界模型生成统一图像帧以预测未来世界状态:其中感知结果(如车道分隔线和 3D 检测结果)表征未来空间关系,普通未来帧表征时间演化关系。这种时空思维链随后作为中间推理步骤,使视觉语言模型能够作为逆动力学模型,基于当前观测和未来预测进行轨迹规划。为了在视觉语言模型中实现视觉生成,我们提出一种融合视觉生成与理解的统一预训练范式,以及一种增强自回归图像生成的渐进式视觉思维链。大量实验结果证明了所提方法的有效性,推动自动驾驶向视觉推理方向发展。
算法概览:
主要实验结果:
OpenLKA-Alert
- 标题:Bridging Human Oversight and Black-box Driver Assistance: Vision-Language Models for Predictive Alerting in Lane Keeping Assist systems
- 链接:https://arxiv.org/abs/2505.11535
- 作者单位:美国南佛罗里达大学
车道保持辅助(LKA)系统虽然日益普及,但在实际应用中常出现不可预测的失效情况,这在很大程度上归因于其不透明的黑箱特性,限制了驾驶员的预判能力和信任度。为弥合自动化辅助与有效人类监督之间的差距,我们提出了 LKAlert------ 一种新型监督警报系统,该系统利用视觉 - 语言模型(VLM)提前 1-3 秒预测潜在的 LKA 风险。LKAlert 处理行车记录仪视频和 CAN 数据,整合来自并行可解释模型的替代车道分割特征作为自动化引导注意力。与传统的二元分类器不同,LKAlert 不仅发出预测性警报,还提供简洁的自然语言解释,从而增强驾驶员的情境感知能力和信任度。为支持此类系统的开发和评估,我们引入了 OpenLKA-Alert,这是首个专为预测性和可解释性 LKA 失效预警设计的基准数据集。该数据集包含同步的多模态输入以及在带注释的时间窗口内由人工编写的解释。我们还贡献了一个可推广的基于 VLM 的黑箱行为预测方法框架,该框架将替代特征引导与 LoRA 相结合。此框架使 VLM 能够在不改变其视觉主干的情况下对结构化视觉上下文进行推理,使其广泛适用于其他需要可解释监督的复杂、不透明系统。实证结果显示,该系统对即将发生的 LKA 失效的预测准确率为 69.8%,F1 分数为 58.6%。该系统还能为驾驶员生成高质量的文本解释(ROUGE-L 得分为 71.7),且运行效率约为 2 Hz,证实其适用于实时车载场景。我们的研究结果表明,LKAlert 是提升现有先进驾驶辅助系统(ADAS)安全性和可用性的实用解决方案,并为将 VLM 应用于以人类为中心的黑箱自动化监督提供了可扩展的范式。
算法概览:
主要实验结果:
OpenLKA
- 标题:OpenLKA: An Open Dataset of Lane Keeping Assist from Recent Car Models under Real-world Driving Conditions
- 链接:https://arxiv.org/abs/2505.09092
- 项目主页:https://github.com/OpenLKA
- 作者单位:美国南佛罗里达大学
车道保持辅助(LKA)在现代量产车辆中得到广泛应用,但其实际性能仍不透明,这是由于该系统的专有控制栈导致研究人员无法对这项技术进行诊断或改进。为填补这一空白,本文提出了 OpenLKA,这是首个用于 LKA 评估和改进的开放式大规模数据集。该数据集包含来自 62 款量产车型的 389.1 小时 LKA 控制数据,这些数据通过在佛罗里达州坦帕市进行的广泛道路测试以及开源社区的全球贡献者收集而来。数据集涵盖了多种具有挑战性的场景,包括车道标记退化、复杂道路几何形状、恶劣天气、光照条件以及各种周边交通状况。该数据集是多模态的,包括:i)解码的车辆内部消息,其中包含关键的 LKA 信号(如系统退出、车道检测失败等);ii)来自车载 dash 摄像头的同步高分辨率视频;iii)由视觉语言模型生成的丰富场景标注,涵盖车道可见性、路面质量、天气、光照和交通状况等。总体而言,OpenLKA 提供了一个全面的平台,用于基准测试量产 LKA 系统的实际性能、识别安全关键操作场景以及评估当前道路基础设施对自动驾驶的就绪程度。
算法概览:
主要实验结果:
Vision Foundation Model
- 标题:Vision Foundation Model Embedding-Based Semantic Anomaly Detection
- 链接:https://arxiv.org/abs/2505.07998
- 作者单位:斯坦福大学,NVIDIA等
ICRA 2025中稿的工作,语义异常是熟悉视觉元素在语境中无效或不寻常的组合,可能导致自主系统在系统级推理中出现未定义行为和故障。本研究通过利用最先进的视觉基础模型的语义先验知识,直接对图像进行处理,探索语义异常检测。我们提出了一个框架,将运行时图像的局部视觉嵌入与自主系统被认为安全且性能良好的正常场景数据库进行比较。在本研究中,我们考虑了所提框架的两种变体:一种使用原始的基于网格的嵌入,另一种利用实例分割获取以对象为中心的表示。为进一步提高鲁棒性,我们引入了一种简单的过滤机制来抑制误报。我们在 CARLA 模拟异常上的评估表明,结合过滤的基于实例的方法性能可与 GPT-4o 媲美,同时能提供精确的异常定位。这些结果凸显了基础模型的视觉嵌入在自主系统实时异常检测中的潜在效用。
算法概览:
主要实验结果:
ORION
- 标题:ORION: A Holistic End-to-End Autonomous Driving Framework by Vision-Language Instructed Action Generation
- 链接:https://www.arxiv.org/abs/2503.19755
- 项目主页:https://xiaomi-mlab.github.io/Orion/
- 作者单位:华中科技大学,小米汽车
端到端(E2E)自动驾驶方法由于因果推理能力有限,在交互式闭环评估中仍难以做出正确决策。现有方法尝试利用视觉 - 语言模型(VLMs)强大的理解与推理能力来解决这一困境。然而,由于语义推理空间与动作空间中纯数值轨迹输出之间存在差距,很少有适用于端到端方法的 VLMs 能在闭环评估中表现良好,这一问题仍未得到解决。为解决该问题,我们提出 ORION------ 一种基于视觉 - 语言指令动作生成的整体端到端自动驾驶框架。ORION 独特地融合了用于聚合长期历史上下文的 QT-Former、用于驾驶场景推理的大语言模型(LLM)以及用于精确轨迹预测的生成式规划器。此外,ORION 通过对齐推理空间与动作空间,实现了视觉问答(VQA)和规划任务的统一端到端优化。我们的方法在 Bench2Drive 挑战数据集上取得了令人瞩目的闭环性能,驾驶得分(DS)达 77.74,成功率(SR)达 54.62%,大幅超越了最先进(SOTA)方法,领先 14.28 个驾驶得分和 19.61% 的成功率。
算法概览:
主要实验结果:
DriveLMM-o1
- 标题:DriveLMM-o1: A Step-by-Step Reasoning Dataset and Large Multimodal Model for Driving Scenario Understanding
- 链接:https://arxiv.org/abs/2503.10621
- 项目主页:https://github.com/ayesha-ishaq/DriveLMM-o1
- 作者单位:穆罕默德・本・扎耶德人工智能大学,澳大利亚国立大学
尽管大型多模态模型(LMMs)在各种视觉问答(VQA)任务中表现出了较强的性能,但某些挑战需要复杂的多步骤推理才能得出准确答案。自动驾驶就是一项极具挑战性的任务,在做出决策之前需要进行全面的认知处理。在这一领域,对视觉线索的顺序性和解释性理解对于有效的感知、预测和规划至关重要。然而,常见的 VQA 基准往往侧重于最终答案的准确性,却忽视了生成准确响应所依赖的推理过程。此外,现有方法缺乏一个全面的框架来评估真实驾驶场景中的逐步推理能力。为了填补这一空白,我们提出了 DriveLMM-o1,这是一个专门为推进自动驾驶领域的逐步视觉推理而设计的新数据集和基准。我们的基准在训练集中包含超过 18k 个 VQA 示例,在测试集中包含超过 4k 个,涵盖了关于感知、预测和规划的各种问题,每个问题都配有逐步推理过程,以确保在自动驾驶场景中的逻辑推理。我们进一步介绍了一个在我们的推理数据集上进行微调的大型多模态模型,该模型在复杂驾驶场景中表现出稳健的性能。此外,我们在提出的数据集上对各种开源和闭源方法进行了基准测试,系统地比较了它们在自动驾驶任务中的推理能力。我们的模型相较于之前最佳的开源模型,在最终答案准确性上提升了 7.49%,在推理得分上提升了 3.62%。
算法概览:
主要实验结果:
AutoDrive-QA
- 标题:AutoDrive-QA - Automated Generation of Multiple-Choice Questions for Autonomous Driving Datasets Using Large Vision-Language Models
- 链接:https://arxiv.org/abs/2503.15778
- 项目主页:https://github.com/Boshrakh/AutoDrive-QA
- 作者单位:哥伦比亚大学
在自动驾驶领域,开放式问答往往因自由形式的回答需要复杂的评估指标或主观的人工判断而面临评估不可靠的问题。为应对这一挑战,我们提出了 AutoDrive-QA ------ 一个自动流水线,可将现有的驾驶问答数据集(包括 DriveLM、NuScenes-QA 和 LingoQA)转换为结构化的多项选择题(MCQ)格式。该基准系统地评估感知、预测和规划任务,提供了一个标准化且客观的评估框架。AutoDrive-QA 采用自动流水线,利用大语言模型(LLMs),基于自动驾驶场景中常见的特定领域错误模式生成高质量、与上下文相关的干扰项。为评估模型的通用能力和泛化性能,我们在三个公开数据集上测试了该基准,并在一个未见过的数据集上进行了零样本实验。零样本评估显示,GPT-4V 以 69.57% 的准确率领先 ------ 在感知任务中达到 74.94%,预测任务中达到 65.33%,规划任务中达到 68.45%,这表明所有模型在感知任务中表现出色,但在预测任务中存在困难。因此,AutoDrive-QA 建立了一个严格、无偏的标准,用于整合和评估不同视觉语言模型在各种自动驾驶数据集上的表现,从而提高该领域的泛化能力。
算法概览:
主要实验结果:
NuGrounding
- 标题:NuGrounding: A Multi-View 3D Visual Grounding Framework in Autonomous Driving
- 链接:https://arxiv.org/abs/2503.22436
- 作者单位:清华大学,华为诺亚方舟实验室,香港大学
多视图 3D 视觉定位对于自动驾驶车辆在复杂环境中理解自然语言并定位目标物体至关重要。然而,现有数据集和方法存在语言指令粒度粗糙、3D 几何推理与语言理解融合不足等问题。为此,我们提出了 NuGrounding,这是首个面向自动驾驶多视图 3D 视觉定位的大规模基准数据集。我们设计了定位层次结构(HoG)方法来构建该数据集,生成具有层次结构的多级指令,确保全面覆盖人类指令模式。为应对这一具有挑战性的数据集,我们提出了一种新范式,将多模态大语言模型(MLLMs)的指令理解能力与专业检测模型的精确定位能力无缝结合。我们的方法引入了两个解耦的任务令牌和一个上下文查询,用于聚合 3D 几何信息和语义指令,随后通过融合解码器优化空间 - 语义特征融合以实现精确定位。大量实验表明,我们的方法显著优于从代表性 3D 场景理解方法改编而来的基线方法,精确率达到 0.59,召回率达到 0.64,分别提升了 50.8% 和 54.7%。
算法概览:
主要实验结果:
ViLA
- 标题:Evaluating Multimodal Vision-Language Model Prompting Strategies for Visual Question Answering in Road Scene Understanding
- HTML:https://openaccess.thecvf.com/content/WACV2025W/LLVMAD/html/Keskar_Evaluating_Multimodal_Vision-Language_Model_Prompting_Strategies_for_Visual_Question_Answering_WACVW_2025_paper.html
- 作者单位:加州大学默塞德分校
理解复杂交通场景是推动自动驾驶系统发展的关键挑战。视觉问答(VQA)任务作为一种新兴方法,能够从多模态交通数据中提取可操作信息,使车辆做出精准的实时决策。作为2025年WACV自动驾驶大语言视觉模型挑战赛(LLVM-AD)的重要组成部分,MAPLM-QA数据集为此任务提供了强有力的基准。该数据集包含14,000个多模态帧,融合了高分辨率全景图像与LiDAR三维点云渲染生成的鸟瞰图(BEV)。本研究探索了应用英伟达视觉语言模型(ViLA)解决MAPLM-QA中VQA任务的方法。通过针对数据集设计精细提示工程,我们系统评估了ViLA的性能:在质量评估等指标上展现出优势,同时揭示了其在车道计数、交叉路口识别及场景细微差异理解方面的挑战。研究结果证实了视觉语言模型(VLM)在增强交通场景分析与自动驾驶能力方面的潜力,为未来利用VLM和多模态数据集实现可扩展、鲁棒的交通场景理解奠定了坚实基础,并明确了技术局限性。
算法概览:
主要实验结果:
INSIGHT
- 标题:INSIGHT: Enhancing Autonomous Driving Safety through Vision-Language Models on Context-Aware Hazard Detection and Edge Case Evaluation
- 链接:https://www.arxiv.org/abs/2502.00262
- 作者单位:美国马里兰大学帕克分校,美国北卡罗来纳州立大学
自动驾驶系统在处理不可预测的边缘案例场景时面临重大挑战,例如具有对抗性的行人运动、危险的车辆操作以及突发的环境变化。当前的端到端驾驶模型由于传统检测和预测方法的局限性,在泛化到这些罕见事件时表现不佳。为解决这一问题,我们提出了 INSIGHT(用于广义危险跟踪的语义与视觉输入集成),这是一种分层视觉 - 语言模型(VLM)框架,旨在增强危险检测和边缘案例评估能力。通过多模态数据融合,我们的方法整合了语义和视觉表征,能够精确解读驾驶场景并准确预测潜在危险。通过对视觉 - 语言模型进行监督微调,我们利用基于注意力的机制和坐标回归技术优化了空间危险定位。在 BDD100K 数据集上的实验结果表明,与现有模型相比,该模型在危险预测的直观性和准确性方面有显著提升,泛化性能也得到了明显改善。这一进展增强了自动驾驶系统的鲁棒性和安全性,确保在复杂的现实世界场景中提升态势感知能力和潜在决策能力。
算法概览:
主要实验结果:
Scenario Understanding
- 标题:Scenario Understanding of Traffic Scenes Through Large Visual Language Models
- 链接:https://arxiv.org/pdf/2501.17131
- 作者单位:慕尼黑工业大学
WACV2025中稿的工作,深度学习模型在自动驾驶领域(包括感知、规划和控制)的高性能依赖于海量数据集。然而,由于特定领域的数据分布,这些模型的泛化能力往往受限,因此需要对样本进行有效的基于场景的分类,以提高其在不同领域的可靠性。人工标注虽有价值,但既耗费人力又耗时,成为数据标注过程中的瓶颈。大型视觉语言模型(LVLMs)通过上下文查询实现图像分析和分类的自动化,且通常无需为新类别重新训练,为解决这一问题提供了极具吸引力的方案。在本研究中,我们评估了包括 GPT-4 和 LLaVA 在内的大型视觉语言模型在内部数据集和 BDD100K 数据集上对城市交通场景的理解与分类能力。我们提出了一个可扩展的标注管道,整合了最先进的模型,能够灵活部署于新数据集。通过定量指标与定性分析相结合的方式,我们的研究证实了大型视觉语言模型在理解城市交通场景方面的有效性,并凸显了其作为自动驾驶领域数据驱动进展的高效工具的潜力。
算法概览:
主要实验结果:
DriveLM
- 标题:DriveLM: Driving with Graph Visual Question Answering
- 链接:https://arxiv.org/abs/2312.14150
- 项目主页:https://github.com/OpenDriveLab/DriveLM
- 作者单位:上海人工智能实验室,香港大学,图宾根大学
ECCV 2024中稿的工作,我们研究了如何将基于网络规模数据训练的视觉语言模型(VLMs)集成到端到端驾驶系统中,以增强泛化能力并实现与人类用户的交互。尽管近年来的方法通过单轮视觉问答(VQA)使 VLMs 适应驾驶场景,但人类驾驶员在做决策时会进行多步骤推理:从关键目标的定位开始,在采取行动前先估计目标间的交互。核心见解是,通过我们提出的图视觉问答(Graph VQA)任务 ------ 该任务通过感知、预测和规划问答对来建模图结构推理 ------ 我们获得了一个合适的代理任务,以模拟人类的推理过程。我们基于 nuScenes 和 CARLA 构建了数据集(DriveLM-Data),并提出了一种基于 VLM 的基线方法(DriveLM-Agent),用于联合执行图视觉问答和端到端驾驶。实验表明,图视觉问答为驾驶场景推理提供了一个简单、有原则的框架,而 DriveLM-Data 为该任务提供了一个具有挑战性的基准。我们的 DriveLM-Agent 基线在端到端自动驾驶方面的表现与最先进的特定驾驶架构相当。值得注意的是,在对未见过的传感器配置进行零样本评估时,其优势尤为明显。我们的逐问题消融研究表明,性能提升来自于图结构中预测和规划问答对的丰富标注。
算法概览:
主要实验结果:
POTGui
- 标题:Enhancing Large Vision Model in Street Scene Semantic Understanding through Leveraging Posterior Optimization Trajectory
- 链接:https://arxiv.org/abs/2501.01710
- 作者单位:香港大学,南方科技大学,中国科学院深圳先进技术研究院
为提高自动驾驶(AD)感知模型的泛化能力,车辆需要基于持续收集的数据随时间更新模型。随着时间推移,AD 模型拟合的数据量不断扩大,这显著有助于提升模型的泛化能力。然而,这种不断膨胀的数据对 AD 模型而言是把双刃剑。具体来说,当拟合的数据量超过 AD 模型的拟合能力时,模型容易出现欠拟合问题。为解决这一问题,我们提出采用预训练的大型视觉模型(LVMs)作为主干网络,结合下游感知头来理解 AD 语义信息。这种设计不仅能凭借 LVMs 强大的拟合能力克服上述欠拟合问题,还能借助 LVMs 海量且多样的训练数据增强感知泛化能力。另一方面,为减轻车辆在运行 LVM 主干网络时训练感知头的计算负担,我们引入后验优化轨迹(POT)引导的优化方案(POTGui)以加速收敛。具体而言,我们设计了 POT 生成器(POTGen),提前生成后验(未来)优化方向,用于指导当前的优化迭代,使模型通常能在 10 个 epoch 内收敛。大量实验表明,与现有的最先进方法相比,所提方法性能提升超过 66.48%,收敛速度加快 6 倍以上。
算法概览:
主要实验结果:
VLM综述
- 标题:Are VLMs Ready for Autonomous Driving? An Empirical Study from the Reliability, Data, and Metric Perspectives
- 链接:https://arxiv.org/abs/2501.04003
- 项目主页:https://drive-bench.github.io/
- 作者单位:加州大学欧文分校,上海人工智能实验室,南洋理工大学S-Lab等
近年来,视觉 - 语言模型(VLMs)的进步引发了将其应用于自动驾驶的兴趣,尤其是在通过自然语言生成可解释的驾驶决策方面。然而,VLMs 是否天生能为驾驶提供基于视觉的、可靠且可解释的解释这一假设在很大程度上尚未得到检验。为填补这一空白,我们引入了 DriveBench,这一基准数据集旨在评估 VLMs 在 17 种设置(清洁、受损和纯文本输入)下的可靠性,涵盖 19,200 帧、20,498 个问答对、三种问题类型、四项主流驾驶任务,以及共 12 个主流 VLMs。我们的研究发现,VLMs 往往会基于常识或文本线索生成看似合理的响应,而非真正基于视觉,尤其是在视觉输入退化或缺失的情况下。这种行为被数据集不平衡和评估指标不足所掩盖,在自动驾驶等安全关键场景中构成重大风险。我们还观察到,VLMs 在多模态推理方面存在困难,且对输入损坏高度敏感,导致性能不一致。为应对这些挑战,我们提出了改进的评估指标,优先考虑稳健的视觉接地和多模态理解。此外,我们强调了利用 VLMs 对损坏的感知来提高其可靠性的潜力,为开发更可信、可解释的现实世界自动驾驶决策系统提供了路线图。
算法概览:
主要实验结果:
VisionLLM
- 标题:SFF Rendering-Based Uncertainty Prediction using VisionLLM
- 链接:https://openreview.net/forum?id=q8ptjh1pDl
- 作者单位:韩国延世大学
本研究提出了一种基于VisionLLM的创新框架,用于自动驾驶中的不确定性预测。通过利用CARLA仿真平台采集的驾驶数据,我们生成了与后续驾驶动作及不确定性分值配对的BEV。为模拟真实驾驶挑战,我们在BEV中引入遮挡掩膜,以表征传感器局限导致的视野盲区。该模型通过融合额外图像输入,在遮挡严重的复杂场景中同步预测后续驾驶动作与不确定性分值,显著提升了推理能力。采用参数高效微调技术(PEFT)如LoRA对VisionLLM进行微调,实验结果证实了该方法在解决遮挡相关不确定性问题的效能,为高阶驾驶自动化系统实现更安全可靠的决策机制奠定了技术基础。
算法概览:
主要实验结果:
CODA-LM
- 标题:Automated Evaluation of Large Vision-Language Models on Self-driving Corner Cases
- 链接:https://arxiv.org/abs/2404.10595
- 项目主页:https://coda-dataset.github.io/coda-lm/
- 作者单位:香港科技大学,大连理工大学,香港中文大学,华为诺亚方舟实验室
WACV 2025中稿的工作,大型视觉语言模型(LVLMs)在推动可解释自动驾驶方面受到了广泛关注。现有的 LVLMs 评估主要集中于自然场景下的多方面能力,缺乏针对自动驾驶的自动化、可量化评估,更不用说对严峻的道路极端场景的评估了。在本研究中,我们提出了 CODA-LM,这是首个用于自动驾驶极端场景下 LVLMs 自动评估的基准。我们采用分层数据结构,提示强大的 LVLMs 分析复杂驾驶场景,并为人工标注者生成高质量的预标注;而在 LVLM 评估方面,我们发现使用纯文本大语言模型(LLMs)作为评判者,与人类偏好的一致性甚至优于 LVLM 评判者。此外,借助我们的 CODA-LM,我们构建了 CODA-VLM------ 一种新的驾驶 LVLM,其在 CODA-LM 上的表现超过了所有开源同类模型。CODA-VLM 的性能与 GPT-4V 相当,在区域感知任务上甚至超过 GPT-4V 达 21.42%。我们希望 CODA-LM 能成为推动 LVLMs 赋能的可解释自动驾驶发展的催化剂。
算法概览:
主要实验结果:
Think-Driver
- 标题:Think-Driver: From Driving-Scene Understanding to Decision-Making with Vision Language Models
- PDF:https://mllmav.github.io/papers/Think-Driver: From Driving-Scene Understanding to Decision-Making with Vision Language Models.pdf
- 作者单位:香港科技大学(广州),约翰斯・霍普金斯大学
自动驾驶近期在仿真环境与现实场景中的表现均取得了显著突破,端到端方法尤其令人瞩目。然而,这类模型往往如同黑盒般运作,缺乏可解释性。大语言模型(LLM)的出现为解决此问题提供了可能,它将模块化自动驾驶与语言解释能力相结合。目前主流的LLM方案将驾驶输入信息转化为语言描述,但这通常依赖人工设计的提示语,且可能导致信息效率不尽理想。视觉语言模型(VLM)虽可直接从图像中提取信息,但在涉及连续驾驶场景理解与上下文推理的任务中有时表现欠佳。
本文提出ThinkDriver模型,这是一种利用多视角图像生成理性驾驶决策及推理过程的视觉语言模型。该模型能够评估感知到的交通状况,并对当前驾驶行为的风险进行研判,从而助力形成理性决策。通过闭环实验验证,ThinkDriver的表现优于其他基于视觉语言模型的基线方案,其生成的驾驶决策具备可解释性,充分证明了该模型的有效性及其在未来应用中的潜力。
算法概览:
主要实验结果:
LLM-Augmented-MTR
- 标题:Large Language Models Powered Context-aware Motion Prediction in Autonomous Driving
- 链接:https://arxiv.org/abs/2403.11057
- 项目主页:https://github.com/AIR-DISCOVER/LLM-Augmented-MTR
- 作者单位:清华大学
运动预测是自动驾驶中最基础的任务之一。传统的运动预测方法主要对地图的向量信息和交通参与者的历史轨迹数据进行编码,缺乏对整体交通语义的全面理解,进而影响预测任务的性能。在本文中,我们利用大语言模型(LLMs)来增强运动预测任务中的全局交通上下文理解。我们首先进行了系统的提示词工程,将复杂的交通环境和交通参与者的历史轨迹信息可视化到图像提示 ------ 交通场景图(TC-Map)中,并辅以相应的文本提示。通过这种方法,我们从大语言模型中获取了丰富的交通上下文信息。将这些信息集成到运动预测模型中后,我们证明此类上下文能够提高运动预测的准确性。此外,考虑到大语言模型的成本,我们提出了一种经济高效的部署策略:使用 0.7% 的大语言模型增强数据集,大规模提升运动预测任务的准确性。我们的研究为增强大语言模型对交通场景的理解以及自动驾驶的运动预测性能提供了有价值的见解。
算法概览:
主要实验结果:
Reason2Drive
- 标题:Reason2Drive: Towards Interpretable and Chain-based Reasoning for Autonomous Driving
- 链接:https://arxiv.org/abs/2312.03661
- 项目主页:https://github.com/fudan-zvg/reason2drive
- 作者单位:复旦大学、华为诺亚方舟实验室
ECCV 2024中稿的工作,大型视觉 - 语言模型(VLMs)在自动驾驶领域引起了越来越多的关注,这得益于其在高度自主车辆行为所必需的复杂推理任务中展现出的先进能力。尽管潜力巨大,但自主系统领域的研究因缺乏带有标注推理链(用于解释驾驶决策过程)的数据集而受阻。为填补这一空白,我们提出了 Reason2Drive------ 一个包含超过 60 万对视频 - 文本对的基准数据集,旨在推动复杂驾驶环境中可解释推理的研究。我们将自动驾驶过程明确描述为感知、预测和推理步骤的顺序组合,其问答对自动从多种开源户外驾驶数据集(包括 nuScenes、Waymo 和 ONCE)中收集而来。此外,我们引入了一种新颖的聚合评估指标,用于评估自主系统中基于链的推理性能,以解决现有指标(如 BLEU 和 CIDEr)存在的推理模糊性问题。基于所提出的基准,我们开展实验评估了多种现有 VLMs,揭示了它们在推理能力方面的见解。另外,我们开发了一种高效方法,使 VLMs 能够在特征提取和预测中利用目标级感知元素,进一步提高了其推理准确性。可扩展实验表明,Reason2Drive 对视觉推理和下游规划任务具有支持作用。
算法概览:
主要实验结果:
OmniDrive
- 标题:OmniDrive: A Holistic Vision-Language Dataset for Autonomous Driving with Counterfactual Reasoning
- 链接:https://arxiv.org/abs/2405.01533
- 项目主页:https://github.com/NVlabs/OmniDrive
- 作者单位:NVIDIA,香港理工大学,北京理工大学
视觉语言模型(VLMs)的进步引发了人们在自动驾驶领域对其强大推理能力的关注。然而,将这些能力从 2D 扩展到全面的 3D 理解对于实际应用至关重要。为应对这一挑战,我们提出了 OmniDrive,这是一个全面的视觉语言数据集,通过反事实推理使智能体模型与 3D 驾驶任务相匹配。这种方法通过评估潜在场景及其结果来增强决策能力,类似于人类驾驶员考虑替代行动的方式。我们基于反事实的合成数据标注过程生成了大规模、高质量的数据集,提供了更密集的监督信号,连接了规划轨迹与基于语言的推理。此外,我们探索了两个先进的 OmniDrive-Agent 框架,即 Omni-L 和 Omni-Q,以评估视觉 - 语言对齐与 3D 感知的重要性,揭示了设计高效 LLM 智能体的关键见解。在 DriveLM 问答基准和 nuScenes 开环规划任务上的显著改进,证明了我们的数据集和方法的有效性。
算法概览:
主要实验结果:
LATTE
- 标题:LATTE: A Real-time Lightweight Attention-based Traffic Accident Anticipation Engine
- 链接:https://arxiv.org/abs/2504.04103
- 作者单位:澳门大学
准确预测交通事故是自动驾驶领域的一项关键挑战,尤其在资源受限环境中。现有解决方案往往存在计算开销大的问题,或无法充分应对交通场景演化的不确定性。本文提出了 LATTE(轻量级注意力基交通事故预测引擎),该引擎融合了计算效率与最先进性能。LATTE 采用高效多尺度空间聚合(EMSA)捕捉跨尺度空间特征,记忆注意力聚合(MAA)增强时序建模,辅助自注意力聚合(AAA)提取长序列潜在依赖关系。此外,LATTE 集成了火烈鸟警报辅助系统(FAA),利用视觉 - 语言模型提供实时、易于理解的语音危险警报,提升乘客情境感知能力。在基准数据集(DAD、CCD、A3D)上的评估表明,LATTE 具有卓越的预测能力和计算效率。在 DAD 基准上,LATTE 实现了 89.74% 的平均精度(AP),平均事故提前时间(mTTA)比第二好的模型高 5.4%,在召回率为 80% 时保持有竞争力的 mTTA(TTA@R80 为 4.04 秒),且在不同驾驶条件下均能稳健预测事故。其轻量级设计使浮点运算(FLOPs)减少 93.14%,参数数量(Params)减少 31.58%,可在资源有限的硬件上实现实时运行且不损失性能。消融研究证实了 LATTE 各架构组件的有效性,可视化和失败案例分析突显了其实用性及需改进的方向。
算法概览:
主要实验结果:
EM-VLM4AD
- 标题:Multi-Frame, Lightweight & Efficient Vision-Language Models for Question Answering in Autonomous Driving
- 链接:https://arxiv.org/abs/2403.19838
- 项目主页:https://github.com/akshaygopalkr/EM-VLM4AD/tree/main
- 作者单位:加利福尼亚大学圣迭戈分校
视觉 - 语言模型(VLMs)和多模态语言模型(MMLMs)在自动驾驶研究中已占据重要地位,这些模型能够利用交通场景图像和其他数据模态,为端到端自动驾驶安全任务提供可解释的文本推理和响应。然而,当前这些系统的实现方案采用了昂贵的大语言模型(LLM)骨干网络和图像编码器,使得这类系统不适用于存在严格内存限制且需要快速推理时间的实时自动驾驶系统。为解决上述问题,我们开发了 EM-VLM4AD,这是一种高效、轻量的多帧视觉 - 语言模型,用于执行自动驾驶领域的视觉问答任务。与现有方法相比,EM-VLM4AD 所需内存和浮点运算至少减少 10 倍,同时在 DriveLM 数据集上的 CIDEr 和 ROUGE 评分也高于现有基线。此外,EM-VLM4AD 还能够从与提示相关的交通视图中提取关键信息,并能回答各种自动驾驶子任务的相关问题。
算法概览:
主要实验结果:
Is it safe to cross
- 标题:Is it safe to cross? Interpretable Risk Assessment with GPT-4V for Safety-Aware Street Crossing
- 链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=10597464
- 作者单位:马萨诸塞大学阿默斯特分校
安全穿越街道交叉口对盲人而言是一项复杂挑战,这要求对周边环境进行精细感知------而该任务高度依赖视觉线索。传统的决策辅助方法往往存在局限,无法提供全面的场景分析与安全等级评估。本文提出一种创新方案,利用视觉语言模型解析复杂的过街场景,较之传统交通信号识别技术具有显著进步。通过生成自然语言描述的安全评分与场景解析,本方法可为视障群体提供安全决策支持。我们采集了包含四足机器人多视角第一人称图像的斑马线交叉口数据集,并依据预设的安全评分分级标准对图像进行标注评分。基于从图像和文本提示中提取的视觉知识,我们评估了视觉语言模型在安全评分预测与场景描述方面的性能。研究表明,该模型通过多样化的提示词激活的推理能力与安全评分预测机制,为开发可信赖决策支持系统提供了关键路径,这对需要高可靠性决策辅助的应用场景至关重要。
NuScenes-MQA
- 标题:NuScenes-MQA: Integrated Evaluation of Captions and QA for Autonomous Driving Datasets using Markup Annotations
- 链接:https://ieeexplore.ieee.org/abstract/document/10495633
- 数据集:https://github.com/turingmotors/NuScenes-MQA
- 作者单位:图灵
视觉问答(VQA)作为自动驾驶领域的关键技术,需实现精准环境识别与复杂场景评估。然而,目前尚缺乏基于行车场景构建的问答格式标注数据集,此类数据集对保证语言生成精确性与场景识别能力至关重要。本研究提出创新性标注技术Markup-QA------通过标记语言封装问答对,该框架可同步评估模型在语句生成与视觉问答的双重能力。基于此标注方法,我们构建了NuScenes-MQA数据集,聚焦描述能力与精准问答的双重特性,为自动驾驶任务的视觉语言模型开发提供新范本。
LLM Multimodal Traffic Accident Forecasting
- 标题:LLM Multimodal Traffic Accident Forecasting
- 链接:https://www.mdpi.com/1424-8220/23/22/9225
- 作者单位:歌德大学,瓦伦西亚理工大学等
随着城市中心交通拥堵日益加剧,交通事故预测对于城市规划和公共安全已变得至关重要。本文系统评估了现代深度学习(DL)方法在预测交通事故以及通过可操作的视听提示增强L4/L5级驾驶辅助系统方面的效能。基于详细记录交通事故发生情况的丰富数据集,我们对比验证了Transformer模型与传统时间序列模型(如ARIMA)及较新的Prophet模型的性能。此外,通过细致的分析,我们运用主成分分析(PCA)载荷深入探究了特征重要性,揭示了导致事故的关键因素。我们创新性地提出在自动驾驶中利用轻量级紧凑型大语言模型(LLM)(如LLaMA-2和Zephyr-7b-𝛼)进行实时干预的思路。我们的探索还延伸至多模态领域:通过结合大型语言视觉助手(LLaVA)------一种利用视觉语言模型(VLM)桥接视觉与语言提示的技术------与深度概率推理,提升了自动驾驶系统的实时响应能力。本研究阐明了在深度学习和深度概率编程中运用大型多模态模型,对于提升时间序列预测及特征权重重要性的性能和实用性的优势,尤其在自动驾驶场景中。此项工作为构建依托数据驱动决策的更安全、更智能的城市奠定了重要基础。
主要实验结果:
Talk2BEV
- 标题:Talk2BEV: Language-enhanced Bird's-eye View Maps for Autonomous Driving
- 链接:https://arxiv.org/abs/2310.02251
- 项目主页:https://llmbev.github.io/talk2bev/
- 作者单位:麻省理工学院,不列颠哥伦比亚大学、塔尔图大学等
本文介绍了 Talk2BEV,这是一种用于自动驾驶场景下BEV地图的大型视觉 - 语言模型(LVLM)接口。现有自动驾驶感知系统主要聚焦于预定义(封闭)的对象类别和驾驶场景,而 Talk2BEV 将通用语言和视觉模型的最新进展与 BEV 结构的地图表示相结合,无需特定任务模型。这使得单一系统能够应对多种自动驾驶任务,包括视觉与空间推理、预测交通参与者意图以及基于视觉线索的决策。我们在大量场景理解任务上对 Talk2BEV 进行了广泛评估,这些任务既依赖于解释自由形式自然语言查询的能力,也依赖于将这些查询与嵌入语言增强 BEV 地图中的视觉上下文相关联的能力。为了推动大型视觉 - 语言模型在自动驾驶场景中的进一步研究,我们开发并发布了 Talk2BEV-Bench 基准,该基准包含 1000 个人工标注的 BEV 场景,以及来自 NuScenes 数据集的 20000 多个问题和真实标注答案。
算法概览:
主要实验结果:
On the Road with GPT-4V
- 标题:On the Road with GPT-4V(ision): Early Explorations of Visual-Language Model on Autonomous Driving
- 链接:https://arxiv.org/abs/2311.05332
- 项目主页:https://github.com/PJLab-ADG/GPT4V-AD-Exploration
- 作者单位:上海人工智能实验室、华东师范大学、香港中文大学等
自动驾驶技术的追求取决于感知、决策和控制系统的复杂整合。无论是数据驱动还是基于规则的传统方法,都因无法把握复杂驾驶环境的细微差别以及其他道路使用者的意图而受阻。这一点已成为显著瓶颈,尤其体现在开发安全可靠的自动驾驶所需的常识推理和精细场景理解方面。视觉语言模型(VLM)的出现为实现完全自动驾驶开辟了新领域。本报告对最先进的 VLM------GPT-4V(视觉版)及其在自动驾驶场景中的应用进行了全面评估。我们探究了该模型理解和推理驾驶场景、做出决策并最终以驾驶员身份采取行动的能力。我们的综合测试涵盖了从基本场景识别到复杂因果推理,以及不同条件下的实时决策。研究结果表明,与现有自动驾驶系统相比,GPT-4V 在场景理解和因果推理方面表现更优。它展示出处理分布外场景、识别意图以及在真实驾驶环境中做出明智决策的潜力。然而,挑战依然存在,尤其在方向辨别、交通灯识别、视觉定位和空间推理任务中。这些局限性凸显了进一步研发的必要性。
OpenAnnotate3D
- 标题:OpenAnnotate3D: Open-Vocabulary Auto-Labeling System for Multi-modal 3D Data
- 链接:https://arxiv.org/abs/2310.13398
- 项目主页:https://github.com/Fudan-ProjectTitan/OpenAnnotate3D
- 作者单位:复旦大学,多伦多大学
在大数据和大模型时代,多模态数据的自动标注功能对于现实世界中人工智能驱动的应用(如自动驾驶和xx智能)具有重要意义。与传统的闭集标注不同,开放词汇标注是实现人类级认知能力的关键。然而,针对多模态 3D 数据的开放词汇自动标注系统较少。在本文中,我们介绍 OpenAnnotate3D,这是一个开源的开放词汇自动标注系统,能够为视觉和点云数据自动生成 2D 掩码、3D 掩码和 3D 边界框标注。该系统整合了大语言模型(LLMs)的思维链能力和视觉 - 语言模型(VLMs)的跨模态能力。据我们所知,OpenAnnotate3D 是开放词汇多模态 3D 自动标注领域的开创性工作之一。我们在公共数据集和内部真实世界数据集上进行了全面评估,结果表明,与人工标注相比,该系统显著提高了标注效率,同时提供了准确的开放词汇自动标注结果。
算法概览:
主要实验结果:
Unsupervised 3D Perception
- 标题:Unsupervised 3D Perception with 2D Vision-Language Distillation for Autonomous Driving
- 链接:https://arxiv.org/abs/2309.14491
- 项目主页:
- 作者单位:WaymoLLC
ICCV 2023中稿的工作,闭集3D感知模型仅在预定义的物体类别集上训练,对于自动驾驶等安全关键应用而言可能存在不足,因为部署后可能会遇到新的物体类型。本文提出了一种多模态自动标注流程,能够生成无模态 3D 边界框和轨迹片段,用于在无 3D 人工标注的情况下训练开放集类别的模型。我们的流程利用点云序列中固有的运动线索,结合可免费获取的 2D 图像 - 文本对,来识别和跟踪所有交通参与者。与该领域近期的研究相比,那些研究仅能提供限于移动物体的无类别自动标注,而我们的方法能够以无监督方式处理静态和动态物体,并且由于所提出的视觉 - 语言知识蒸馏,能够输出开放词汇语义标签。在 Waymo 开放数据集上的实验表明,我们的方法在各种无监督 3D 感知任务上显著优于先前的工作。
算法概览:
主要实验结果:
#喧嚣过后, 理想i8后续口碑会非常高
本文逻辑链与根基前提将很不常规,与主流观点有巨大非共识,预期大多数人会不同意。
本文经过非常深入的思考,由于现实世界的复杂性与多样性,深入思考后的观点依然不低可能是错误的,强烈不建议读者默认TOP2观点为真,强烈建议读者充分批判性阅读。
核心观点:
1.i8不会等太久,市场口碑与反应都会挺好,不会太久,具体多久不好说,但会明显短于MEGA口碑发酵时间。
2.i8会促进MEGA订单,会吃掉一部分L789订单。下一代增程车又会重新吃回一部分纯电订单。今年L系列订单会相当一般。
互联网上出现了海量的对i8 SKU设置或其他方面的吐槽,本质是没有满足相当多人认为i8应该一下子就让人立即想买,超短期立马爆单的预期。这个预期落空后,找的接口。超级多人认为是SKU设置或取消免息或其他各种原因导致这个预期落空。
即TOP2与超级多人在谁为因,谁为果上有巨大分歧。
本文结构:
1.描述根基前提,根基前提是全文所有判断的支撑点,建议读者阅读过程中着重留意。
2.i8公众舆论的底层运转链。
3.如何看待卡车事件?
4.i8后续口碑为什么会非常高。
根基前提:
人的决定由潜意识先决定,然后意识才知道这个决定,意识会为这个决定寻找一个合理的解释,这个过程是不自知的。
即人们以为做出决定的原因,其实只是为已有的决定寻找的答案。
例子1,通过监测志愿者大脑活动可以在测试任务中比志愿者更早预测到志愿者的选择,在前额叶兴奋之前就能准确预测,志愿者自己则是在前额叶活跃之后才给出选择。
例子2,左右脑被切开的裂脑人,右脑依然有意识指挥身体行动,左脑并不知道右脑的意图。左脑总会给身体的行动一个合理的解释。比如给他右脑(左侧视野)看一张写着走的牌子,他马上就往外走,然后问他干什么,可能会说,出去倒一杯水。1
i8公众舆论的底层运转链
基于3点原因,公众对i8超短期爆单有很大期待:
1.YU7发布会第一天锁单情况对汽车行业的感观冲击。
2.认为理想是一家之前在销量有过出色成绩的公司。
3.i8是一款整整延期一年的产品。
潜意识里对i8超短期爆单有很大期待,进而衍生出3点期待:
1.必须有让人希望尽快锁单,晚锁单会吃亏的理由。
2.亮点必须一两句话,不需要去体验就能让人有充分感知。
3.必须让人一下子就想买XX车型的冲动。
针对超短期爆单,YU7这三点做得非常出色,i8做得非常不出色。
YU7必须尽快锁单的氛围锚点是,超多人抢,晚一点就要明年才能提车,早锁单早提车,早提车可以靠这个车早赚钱。
i8在8月12号之前尽快锁单没有任何好处,因为8月12号前锁单,是按此前小定交付时间确定的,早锁单了不能早提车。故这个大定小定设计规则,是非常明确的指向谋求一个比较高的两周锁单数据,明确不谋求超短期爆单。
另外,理想锁单开始日期是周二,即在周五晚上前要先经历周二周三周四三个晚上,同样是非常明确的不谋求超短期爆单动作。
某友商的只有公布价格第一天才有的权益,对超短期爆单是非常有利的设计。
YU7亮点是非常符合一两句话就能说清楚的,全系标配激光雷达/Thor U 芯片,低配800以上的续航,颜值等,加很多人之前有的超高保值率预期(如果能持续做到,这是一个超级亮点,比其他所有亮点都更大的亮点)。
i8的亮点,非常需要多体验,一两句话冲击力小。少部分还没有现货,包括但不限于,同车长下,非常好的二三排空间,精致感,良好的动态体验,全系5C+四驱+双腔空悬,VLA,新一代卡片式交互体验,低风阻设计+对应的5C超充站体系等等。i8是一辆局部优于MEGA,整体性价比版MEGA的车。是一辆,对纯电党而言,i8顶配几乎全面大于等于L9的车。
i8究竟应该选什么车型,在设置上也是完全没谋求让人快速决定的,同样谋求的是花几天时间多对比对比,选择适合自己的。
故实际上是理想的种种刻意设计没迎合超短期快速爆单的期望,很多人感到不爽,不理解,然后需要为自己的不爽,不理解找理由(类比根基假设里提到的,左右脑被切开的裂脑人,右脑依然有意识指挥身体行动,左脑并不知道右脑的意图。左脑总会给身体的行动一个合理的解释。比如给他右脑(左侧视野)看一张写着走的牌子,他马上就往外走,然后问他干什么,可能会说,出去倒一杯水。)
即TOP2明确认为,各种吐槽实际是基于理想没有超短期快速爆单找的借口,超多人把借口当作原因了,然后基于觉得借口是原因的前提,各种认可i8的讨论基本无法深入交流。
理想为什么不迎合这种期望?底色源自李想24年3月21日认的错,认为当时过于关注销量和竞争,让欲望超越了价值。
要聚焦用户价值,聚焦经营效率,耐心控制节奏,通过脚踏实地的解决问题,长期健康的服务好我们的用户。
如何看待卡车事件?
理想表演了一个胸口碎大石,双方车其实都是安全的。这是实际可以共赢的基础。
出现了一些车主担心存在可能性卡车司机故意撞。
理想短期能否快速有效处理这种担心有一定的不确定性,中长期很难认为会持续处理不了。
毕竟这种担心的基础,是基于一些偶然因素被煽风点火了,潜在的显得卡车司机被冒犯了,但理想初心以及利益链完全不想冒犯,实际上理想实际生产运营中也需要大量卡车司机的辛勤付出。在这种利益链牵引下,这种情绪主导没有中长期持续存在的基础。
理想后续还会不断被黑是有存在基础的,因为智能车在产业变革期,涉及重大利益重新分配。在这个过程中基于利益链与市场环境,黑是有存在基础的。
与此同时,更大的主要矛盾是中国市场是全球毫无争议的最佳智能车市场,这件事完全不会因为有被黑存在基础而改变。一些人担心劣币驱逐良币,但实际上先进的就是会击败落后的,在这个过程里有大量舆情攻击是常态。先进的胜利,靠的是真心换真心,真的是好东西。
i8后续口碑为什么会非常高?
基于前文论述,这里默认短期来说,主要看担心被卡车故意撞这个事多久能平息,中长期这事自然会平息。
最近几天,TOP2在各种不同渠道看到不少人反馈,虽然心里有点不爽,但还是锁单了。
不爽一般指向觉得稍微有点亏,有些说觉得多加2万买电视有点亏,有的说没有零息有点亏。
再次cue一下本文的根基假设,实际上是因为这波人有i8延期一年多,理想应该会在很多方面设计的让人觉得一眼优惠,但这个期望落空了,是先有感受,然后再找各种借口。(再cue一下,给右脑(左侧视野)看一张写着走的牌子,他马上就往外走,然后问他干什么,可能会说,出去倒一杯水。)
实际上,当用户抱着有35万左右的预算,想买一辆舒适/车机/智驾/空间/精致/静谧性/良好操控这些要素的时候会发现,除了MEGA,其他车实际都是逊色的。
尤其是和L9比,对纯电党而言,i8顶配是降价升级版。
虽然嘴里说觉得i8顶配有点不值,真想买类似产品的时候,其他车真会被比下去。
二排电视这种显性指标其实反而更突显自己是顶配,这个内在面子加成挺大的。
L8顶配面子加成比i8顶配小多了,因为有L9削弱L8顶配的面子,i8上面只有MEGA,但是MEGA因为过于先锋,不买MEGA的理由可以不是自己钱不够,而是因为比如不想那么长,不需要那么大空间,不好停等理由。
即i8顶配的上不封顶感觉比L8强很多,这还是实际比L8顶配便宜的基础上实现的。
另外,i8顶配属于既显性,又低调,通过二排屏幕一眼就能知道是顶配。然后网上都在那边说XXX sku设置的不好,指向好像顶配不太值,在这个情况下还选顶配,会更显得比较有经济实力。(这是一个很细微的心理,表面上是多花2万多电视有点不值,背后是可以只多花2万,就有上限不止顶配的标签,并且别人一坐进来就知道是顶配)
对L7用户而言,之前如果想要L9的21.4寸的二排电视,在L7 Ultra基础上,要多交八九万。而现在如果买i8顶配,名义价格只用多1万(实际多2万3左右),同样显得i8顶配超值。
这里是在论述,消费者仔细对比下,会发觉i8顶配很值,用比L8顶配更低的价格,面子显著更高,对纯电党产品力还明显比更贵的L9更好。再往上探更高产品力,一下子就得加15万上MEGA Ultra,但真买Ultre,又会显得Home太值,这样一下子贵18万了。而i8在内饰精致感,操控,电动出风口,注意力检测传感器等方面还略胜MEGA Home一筹,这性价比实际是爆棚的。
对于i8 Max来说,首先有些人是本来就不想要电视,对这种人而言,少了一个自己本来就不想要的,然后就是再少一个铂金音响,就能少2万,本身很划算。
其次如果真想要二排电视,又不想多花2万,看其他车,会发现从20多万到四十多万的其他车企的车,几乎必然在舒适/车机/智驾/空间/精致/静谧性/良好操控一个或多个方面体验会明显降级。
喷i8不标配冰箱电视,内核与之前喷理想不过就是冰箱彩电大沙发而已是一致的。
冰箱彩电大沙发仅仅只是理想产品功底的一个具象化指标,理想产品功底还在其他非常多方面。
由于篇幅的原因,本文再举最后一个例子。
理想这次i8发布会有个期货其实非常厉害,但基本没有掀起什么讨论。
以下部分观点参考了和一位群友的交流:
新一代的理想同学,卡片大师与记忆能力的引入。
卡片大师基本做到了ai前沿的一部分人(包括但不限于软件2.0 3.0概念的提出者Andrej Karpathy,谷歌前CEO埃里克·施密特)的少数非共识:未来的交互界面是实时生成并个性化的,类似于 OenAI 现在做的 canvas 的感觉,理想的卡片大师做的更接近落地的产品形态。
这里最重要的两个理念,借助AI,将来可以实现实时生成与个性化。在前AI时代这是不可能。
前AI时代,虽然每个人可以选不同的APP,但APP必须要基于大多数人的需求来设计,比如一个人可能只需要买指定航空公司的机票,但携程设计的时候必须考虑其他用户不指定航空公司的需求。
这里一定对UI是有妥协的。
而AI的前进方向,可以完全不妥协,AI革命性提升了优质信息生产效率,互联网革命性提升了信息复制与转发效率。
理想的卡片大师符合如此有穿透力的设计理念。背后的内核与纯电正向设计+5C电池+5C超充站是一模一样,think different+产品化的能力。
记忆能力简单提一下,可以生命感非常强,承担很多情绪价值,背后用户价值巨大。
一个简单的场景理想同学上车主动问:你上周产品方案讨论的结果怎么样了?
理想具备首发做出低熵值产品的能力,熵值越低越意味着贴近最优设计,最优设计意味着只能这样设计,因为用户价值最大。
参考:
1在神经科学领域,有哪些反直觉的研究成果?
#Bench2ADVLM
快慢双系统评测!专为自动驾驶VLM设计(南洋理工)
视觉-语言模型(VLMs)最近已成为自动驾驶(AD)中一个有前景的范式。然而当前对基于VLM的自动驾驶系统(ADVLMs)的性能评估协议主要局限于具有静态输入的开环设置,忽略了更具现实性和信息性的闭环设置,后者能够捕捉交互行为、反馈弹性和真实世界的安全性。为了解决这一问题,我们引入了BENCH2ADVLM,这是一个统一的分层闭环评估框架,用于在仿真和物理平台上对ADVLMs进行实时、交互式评估。受认知的双过程理论启发,我们首先通过双系统适应架构将多种ADVLMs适配到仿真环境中。在此设计中,由目标ADVLMs(快速系统)生成的异构高级驾驶命令被通用VLM(慢速系统)解释为适合在仿真中执行的标准化中级控制动作。为了弥合仿真与现实之间的差距,我们设计了一个物理控制抽象层,将这些中级动作转换为低级执行信号,首次实现了在物理车辆上对ADVLMs的闭环测试。为了实现更全面的评估,BENCH2ADVLM引入了一个自我反思的场景生成模块,该模块自动探索模型行为并发现潜在的故障模式,以生成安全关键的场景。总体而言,BENCH2ADVLM建立了一个分层评估流水线,无缝集成了高级抽象推理、中级仿真动作和低级真实世界执行。在多个最先进的ADVLMs和物理平台上进行的多样化场景实验验证了我们框架的诊断能力,揭示了现有ADVLMs在闭环条件下的性能仍然有限。据我们所知,这是首次建立ADVLMs的闭环评估基准,为ADVLMs的可扩展、可靠部署提供了一条原则性路径。
简介
随着深度学习的快速发展,自动驾驶(AD)技术已从模块化流水线发展到端到端系统,最近更是发展到视觉-语言模型(VLMs)。由于其强大的泛化能力和增强的可解释性,VLMs已成为当代自动驾驶研究中一个有前景的范式。
尽管前景广阔,但基于VLM的自动驾驶系统(ADVLMs)的评估仍受到严重限制,因为它们主要集中在开环设置上,其中模型输出不会在仿真环境中反馈给AD系统,导致静态输入无法反映模型行为的后果。然而,更可靠且更困难的闭环评估尚未被探索,这种评估通过持续将输出纳入未来输入,实现与环境的动态和实时反馈。与开环评估相比,闭环测试可以有效缓解由错误预测积累引起的分布偏移和级联错误等问题,这有助于揭示AD系统更多的缺陷。
当前ADVLMs在闭环评估中的一个根本挑战在于它们无法直接与物理环境互动。与传统的端到端驾驶模型相比,ADVLMs在较高层次的抽象上运行,生成语义驾驶命令而不是可执行的控制信号。这种架构上的断开阻止了与执行系统的直接接口,需要一个额外的解释层来将抽象决策转化为控制信号。因此,闭环反馈循环被中断,限制了基于仿真和现实世界评估的保真度和有效性。此外,现有研究主要集中在虚拟环境上,对物理世界验证的努力有限。物理部署在很大程度上未被探索,即使小规模的真实车辆测试也很少进行,尽管这对于评估现实世界的可靠性和安全性是必要的。
为了解决这一问题,我们提出了BENCH2ADVLM,这是一个统一的闭环框架,用于在虚拟和物理环境中对ADVLMs进行实时和交互式评估。受心理学中快速和慢速认知的双系统理论启发,BENCH2ADVLM采用了一种双系统适应架构,模拟"快系统"和"慢系统"的角色。快系统(即正在评估的目标ADVLMs)生成高层驾驶命令,而慢系统(即通用VLMs)充当语义执行器,将这些命令转化为可在仿真环境中执行的中层控制动作。此外,我们建立了一个物理控制抽象层,将中层控制动作映射到低层现实世界执行信号,首次实现了在物理车辆上对ADVLMs的闭环测试。总之,BENCH2ADVLM提供了第一个统一的测试平台,分层连接基于语言的抽象推理与仿真控制和物理执行,实现了AD评估所有层面的闭环。此外,为了支持对目标模型的定制化评估,BENCH2ADVLM结合了基于Bench2Drive提供的路线的自反性场景生成模块,自主生成220个威胁场景,使ADVLMs能够暴露在更广泛的对抗性、长尾和安全关键条件下。最后,我们讨论了基于我们的见解设计先进ADVLMs的潜在方向。我们将持续为社区开发这一生态系统。主要贡献如下:
- 双系统适应架构。我们提出了一种受快速和慢速认知启发的双系统适应架构,其中目标ADVLMs生成高层驾驶命令,通用VLMs将其转化为中层控制动作,实现在仿真器中对ADVLMs的闭环测试。
- 物理控制抽象层。我们构建了一个物理控制抽象层,将中层控制动作映射到现实世界的执行信号,实现对物理车辆上ADVLMs的闭环测试。
- 自反性场景生成。我们引入了一个自反性场景生成模块,基于220条标准路线,自主创建220个安全关键场景,实现更广泛和有针对性的评估。
相关工作回顾
基于视觉-语言模型的自动驾驶。近期的研究探索了多种基于视觉-语言模型的自动驾驶系统(ADVLMs)。EM-VLM4AD通过一种轻量级架构在不牺牲视觉问答(VQA)性能的情况下提高了效率。Dolphins通过接地的思维链(GCoT)和上下文内指令调优进一步实现了类人交互。GPT-Driver将运动规划重新定义为一个语言建模任务。LLM-driver引入了一种多模态架构,将向量化的目标级表示与大语言模型(LLMs)融合。MTD-GPT结合了强化学习与基于GPT的序列建模,以支持多任务决策。进一步的工作,如LanguageMPC、DriveVLM和DriveMLM探讨了将视觉-语言模型作为决策者和规划者。Senna提出了不同类型的问答以提高规划性能,而DriveLM在一个图视觉问答(GVQA)框架内统一了这两个方面,使模型能够输出对驾驶相关查询的文本答案以及未来的轨迹航点。OmniDrive通过反事实监督将3D驾驶感知与基于语言的推理联系起来。ORION在闭环设置中探索了视觉-语言指导的动作生成;然而,其底层决策过程仍然基于一个通用的生成模型,而不是ADVLMs。
尽管取得了进展,大多数ADVLMs仅在开环设置中进行评估。为了捕捉决策与环境的交互,我们专注于规划场景中的闭环评估。
自动驾驶基准测试。1)面向ADVLMs的开环基准测试:大多数现有的ADVLMs基准测试侧重于开环评估,强调多模态推理和特定任务性能,特别是在视觉问答(VQA)方面。LingoQA引入了一个大规模数据集以及Lingo-Judge,这是一种学习度量,超越了传统的基于文本的评分,如BLEU、METEOR、CIDEr和GPT-4。Reason2Drive提供了来自Waymo、nuScenes和ONCE的超过60万对视频-文本对,旨在通过ADRScore评估可解释的、基于链条的推理。NuScenes-QA增加了3.4万个场景和46万个问答对。AutoTrust基于多样化的数据收集构建,以从多个方面评估ADVLMs。同时,DriveBench建立了一个综合基准测试,以精细的评估指标在多样化设置和任务中评估可靠性。除了VQA,像DriveLM和Dolphins这样的基准测试扩展到了规划任务,但仍然是开环的,限制了在动态设置中的实际相关性。2)面向端到端自动驾驶的闭环基准测试:在闭环评估中,现有基准测试主要为传统的端到端自动驾驶模型设计。CARLA是最广泛使用的开源模拟器,促进了多个代表性闭环基准测试的开发。CARLA排行榜v1作为一项算法竞赛被引入,评估基本导航和简单的交互行为。其继任者,CARLA排行榜v2,通过更复杂的场景和额外的城镇扩展了环境集。在CARLA的基础上,Bench2Drive提出了一个更细致和全面的闭环基准测试,专为端到端自动驾驶模型定制。
然而,现有基准测试假设直接的低级控制信号,与ADVLMs不兼容。这一差距凸显了对专用闭环ADVLMs基准测试的需求。
Bench2ADVLM 设计
BENCH2ADVLM 是一个用于对 ADVLMs 进行实时和交互式评估的统一闭环评估框架。BENCH2ADVLM 的框架如图 1 所示。
双系统适应架构
受心理学中认知的双系统理论的启发,我们设计了一种双系统适应架构,模拟快速和慢速认知过程之间的交互。
在我们的框架中,快系统对应于目标 ADVLMs,负责根据视觉-语言输入生成高层、目标导向的驾驶命令。慢系统,使用通用视觉-语言模型(GVLMs)实现,充当语义执行器,将这些高层驾驶命令转换为可执行的中层控制动作。
我们首先介绍快系统,它对应于目标 ADVLMs。不同 ADVLMs 的输出表现出显著的异质性,包括结构化命令、轨迹预测和自由形式的文本推理。这种多样性使得应用统一的模式识别方法进行解释变得具有挑战性。为了解决这个问题,我们对输出进行抽象,并利用大模型的泛化能力进行下游处理。给定输入图像序列和特定任务提示集,ADVLMs 生成任务条件的文本输出:
其中是输入图像序列,是任务 的提示, 是预定义任务集(例如,动作预测、轨迹预测、语义推理)。 是共享的推理函数, 收集时间 的任务特定文本输出。
慢系统充当语义解释器,将异质的高层驾驶命令转换为可执行的中层控制动作。给定快系统生成的文本输出 ,慢系统弥合了语义意图与物理动作之间的差距。
具体来说,对于每个与动作相关的任务 ,相应的文本描述 被转换为与 CARLA 模拟器接口兼容的控制命令。在自动驾驶控制中,关键的执行信号包括转向、油门和刹车值,对应于车辆的横向和纵向操作。为了将异质的高层驾驶命令转换为可执行的中层控制动作,我们基于 GVLMs 设计了一个语义到控制的转换模块,该模块针对 CARLA 控制协议进行了定制。给定任务特定的文本输出 和当前的观测图像序列,慢系统通过以下方式预测控制命令 :
其中 是预定义的控制提示模板, 表示候选控制集。控制向量 由三个部分组成:转向命令 ,油门命令 ,和刹车命令 。这些信号对应于 CARLA 中车辆控制接口的执行原语,其中 控制转向角, 分别调节加速度和制动强度。
对于视觉-语言模型,原始图像序列直接作为视觉输入与提示一起提供。对于纯语言模型,图像序列首先被编码为文本描述,然后附加到提示模板 中的任务特定输出 内。
我们在两种操作模式下实例化 :1) 连续数值生成(CNG)模式, 为空,视觉-语言模型直接回归连续控制值。每个输出分量在 CARLA 的规范范围内进行约束(例如,转向角在,油门和刹车在)。2) 离散分类选择(DCS)模式, 被预定义为从领域知识派生的候选控制向量的离散集。视觉-语言模型根据高层驾驶命令选择语义上最一致的候选。在这两种模式下,生成的控制动作 被输入到 CARLA 的车辆接口,实现基于高层语义决策的实时执行。提示构造 和候选集 的细节在附录中提供。
物理控制抽象层
为了在物理世界中实现闭环评估,我们将测试范式从模型在环(MIL)模拟扩展到硬件在环(HIL)部署。具体来说,我们开发了一个物理控制抽象层,将中层控制动作映射到低层真实世界执行信号。在每个控制周期,系统将生成的控制信号传输到物理车辆,车辆执行运动持续 0.5 秒,捕获更新的车载观测,并将其反馈给下一个推理步骤。这在物理环境中形成了一个实时反馈循环,涵盖了感知、决策和执行。
物理控制抽象层在 AGILE·X 模拟沙箱中使用两个自动驾驶平台进行验证:Jetbot和 LIMO。这两个平台都配备了车载传感器,包括摄像头、激光雷达和惯性测量单元(IMU),并能够进行标准运动控制。Jetbot 具有更强的车载计算资源,适合 AI 密集型工作负载,而 LIMO 强调执行稳定性,并支持多种驾驶模式,包括差速、阿克曼、履带和麦克纳姆配置。两个平台都采用 ROS 作为内部通信和控制框架。为了克服边缘设备的计算限制,我们采用客户端-服务器架构。服务器托管视觉-语言规划器和决策到控制的解析模块,而客户端部署在车辆上,负责实时传感器采集和低层执行信号。双方之间的通信通过 SSH 隧道保护的 TCP 套接字建立,确保低延迟和可靠的反馈。
值得注意的是,虽然我们当前的部署是在 Jetbot 和 LIMO 上的 AGILE·X sandbox中进行的,但抽象层的模块化和客户端-服务器分离设计使其能够无缝扩展到更广泛的测试场景,支持从 MIL 到 HIL 设置的可扩展过渡。
自反性场景生成
闭环评估需要一个交互式环境和一系列多样化的安全关键场景,以挑战目标模型。
现有基准测试通常依赖预定义模式或基于规则的扰动来构建测试用例,这可能无法捕捉不同 ADVLMs 的特定脆弱性。这限制了它们支持有针对性、诊断性评估的能力。
为了解决这个问题,我们引入了一种自反性场景生成机制,主动让目标 ADVLMs 参与到以威胁为中心的测试场景的构建中,如图 3 所示。
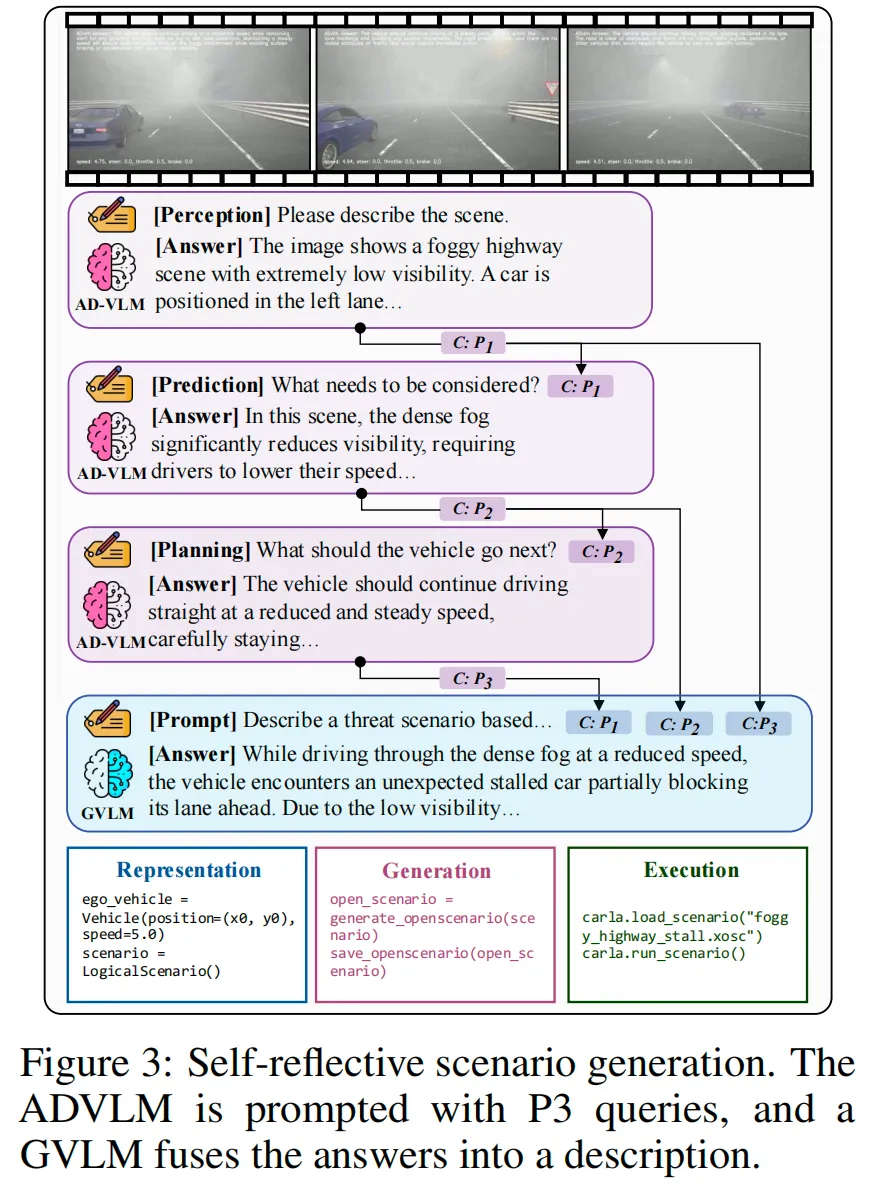
与被动应用静态模板不同,我们让被测试的模型来阐述它对场景的理解以及它认为对决策至关重要的上下文。
生成过程围绕一个结构化的三阶段推理框架组织,该框架受到自动驾驶中广泛使用的感知-预测-规划(P3)范式的启发。从基本场景开始,系统在三个认知阶段向 ADVLMs 提出查询:1) 感知,描述当前正在发生的事情;2)预测,识别影响近期演化的关键因素;3)规划,确定适当的下一步行动。每个回答捕捉了模型内部推理的一个独特方面。由于 ADVLMs 专注于特定任务的输出,它们难以统一跨任务信号。我们通过使用 GVLM 将中间输出融合成一个连贯的威胁场景描述来解决这个问题。生成的描述被传递到一个可控的场景构建管道,并用作实例化模拟环境的提示。基于 Bench2Drive提供的 220 条标准路线,我们使用自反性生成方法生成了相应的一组 220 个威胁关键场景。
实验结果分析
实验设置
模型。作为快系统,我们评估了四种常用的ADVLMs:Dolphins、DriveLM、EM-VLM4AD和OmniDrive。对于慢系统,我们通过使用LLaMA-3-8B和LLaVA-1.5-13B来比较一个大语言模型(LLM)和一个视觉-语言模型(VLM)。解析模式。每个模型在两种解析模式下进行测试,即连续数值生成(CNG)和离散分类选择(DCS),如第3节所述。硬件配置。服务器配备了一个128核的Intel Xeon 8358 CPU(2.60GHz)、1TB内存和8块NVIDIA A800 80GB PCIe GPU。评估指标。我们通过整合CARLA排行榜和Bench2Drive中的指标,构建了一个渐进式评估框架,涵盖了三个维度:基本性能,通过成功率↑(无违规完成的路线百分比)和驾驶分数↑(完成分数加权违规惩罚)来衡量;行为质量,通过效率↑(每5%路线采样的相对速度)和舒适度↑(具有稳定控制信号的平滑20帧段的比例)来评估;以及专门能力,通过平均五个交互技能(车道合并、超车、紧急制动、让行和交通标志识别)的技能分数↑来评估。每个实验重复10次,报告平均结果。
主要结果
表1展示了BENCH2ADVLM上的主要结果,从中我们得出以下见解:
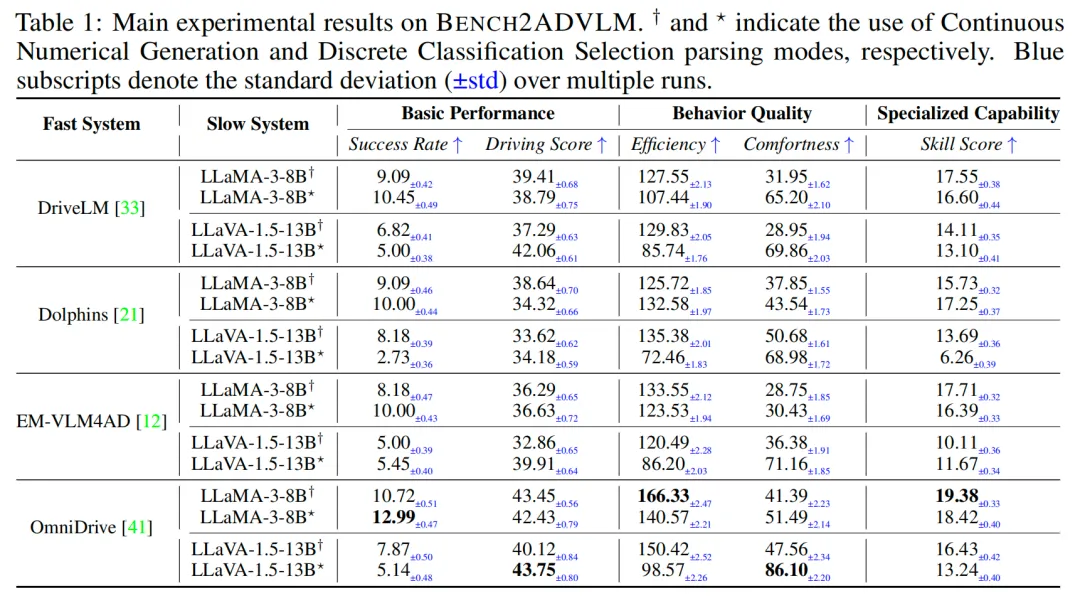
- 不同ADVLMs之间的比较。所有ADVLMs的整体性能仍然相对较低,表明当前模型仍然面临显著的局限性。OmniDrive在所有指标上始终获得最高分,最高成功率为12.99%,驾驶分数为43.75,技能分数为19.38,表明其在闭环设置中具有更好的鲁棒性和泛化能力。相比之下,DriveLM和Dolphins表现较弱,平均驾驶分数约为39.39,技能分数低于18,反映出其规划可靠性有限。EM-VLM4AD表现具有竞争力,舒适度达到71.16,表明其轻量级设计保留了特定任务的能力。在所有模型中,标准差保持相对较小,通常低于相应指标的5%,表明在多次试验中表现一致且可靠。
- 不同解析模型之间的比较。LLaMA和LLaVA的侧重点不同,LLaMA的成功率相对较高,而LLaVA的驾驶分数相对较高。例如,在DriveLM使用DCS的情况下,LLaMA的成功率为10.45,驾驶分数为38.79,而LLaVA分别为5.00和42.06。
- 不同解析模式之间的比较。使用CNG的模型通常获得更高的驾驶分数(43.45 vs. 42.43),如OmniDrive与LLaMA的组合所示,这反映了细粒度控制的优势。另一方面,DCS显著提高了舒适度,特别是对于使用LLaMA的DriveLM(31.95 vs. 65.20)和使用LLaMA的Dolphins(37.85 vs. 43.54),表明在延长轨迹中更好地抑制了不稳定行为。(CNG vs. DCS)。不同模式的详细分析见补充材料。
- 微观行为分析。在相同的系统配置下(例如,LLaMA-3-8B与DCS),Dolphins的效率(132.58 vs. 107.44)高于DriveLM,尽管其驾驶分数略低(34.32 vs. 38.79)。这表明,尽管DriveLM更注重完成路线,但Dolphins优先考虑更平滑和更稳定的控制。这些结果反映了不同的行为倾向:DriveLM强调最终任务的成功,而Dolphins表现出更精细的控制。可视化和失败分析见补充材料。 见解1:ADVLMs缺乏细粒度控制,闭环性能有限,低成功率和驾驶分数突显了与部署准备之间的差距。
威胁场景评估
表2报告了在威胁场景下的结果,部分与主实验的对比可视化如图4所示。
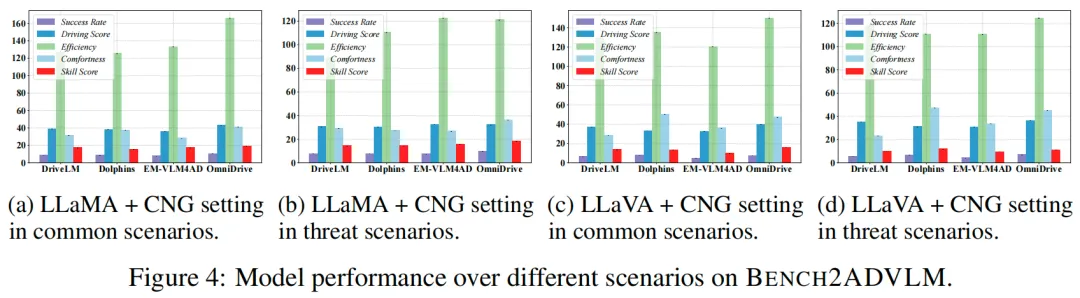
- 威胁场景下的鲁棒性下降。整体性能趋势与主结果一致,但所有模型均观察到显著的性能下降。例如,Dolphins的成功率从9.09%下降到7.91%(下降1.18%),EM-VLM4AD在CNG模式和LLaMA下从8.18%下降到7.61%(下降0.57%)。平均而言,驾驶分数下降了26.1%,技能分数最多下降了3.59%,尤其是OmniDrive。
- 通过标准差进行稳定性分析。除了平均性能下降外,我们还检查了多次运行的方差,以评估模型在威胁场景下的稳定性。尽管OmniDrive在清洁条件下所有指标上领先,但在关键指标上的标准差明显增加。其驾驶分数方差从±0.56增加到±0.80,技能分数方差从±0.33增加到±0.47。这表明在对抗性扰动下行为不一致。相比之下,EM-VLM4AD在所有指标上保持了相对较低且稳定的方差。例如,其驾驶分数标准差保持在±0.65到±0.59的紧密范围内,技能分数方差保持在±0.32左右,波动最小。这种一致性凸显了EM-VLM4AD在不确定环境中的鲁棒性和可靠性。
- 威胁下的任务特定敏感性。威胁场景对所有任务维度的影响并不相同。与平滑度和舒适度相关的指标(如效率和舒适度)倾向于更急剧地下降。例如,OmniDrive的舒适度平均下降了12.16,而其成功率仅下降了约1.44%。类似地,DriveLM和Dolphins在效率和舒适度上的下降不成比例地大于成功率,表明威胁对细粒度行为的影响大于对整体任务成功的影响。
见解2:LLaVA在行为质量指标(如效率)上的下降比LLaMA更温和,而LLaMA在基本性能(如成功率)上表现更好。
真实世界评估
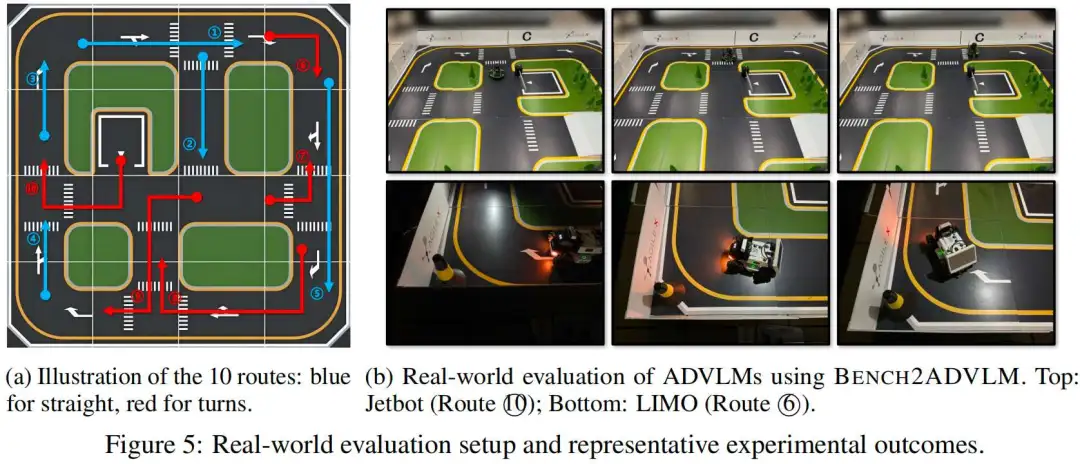
评估策略。为了定量评估真实世界的驾驶性能,我们设计了一种以车道跟随任务为中心的结构化评估策略。驾驶沙箱被划分为十个不同的路线段,每个段落反映了不同的几何和交通复杂性,如图5a所示。对于每条路线,每辆自动驾驶车辆运行三次,我们报告平均结果以确保统计可靠性。主要评估指标是路线完成率,定义为车辆成功穿越计划轨迹的百分比,且不跨越黄色边界线或与障碍物发生碰撞。
结果分析。如表3所示,所有部署的模型都表现出完成基本车道跟随任务的能力。特别是,JetBot平台在所有模型上始终优于LIMO车辆,平均路线完成率达到55.5%,而LIMO为54.5%。这种改进部分源于评估路线的简单性。然而,即使在这些条件下,仍然发生了大量失败,突显了真实世界部署中的持续挑战。

潜在路径
基于上述见解,我们进行了初步实验,以探索推进稳健且实用的ADVLMs的潜在路径。详细信息见补充材料。
细粒度控制。见解1揭示了当前ADVLMs缺乏细粒度控制,表现出显著的局限性。在此,我们旨在使模型输出细粒度的控制信息,以在闭环环境中实现更好的执行。具体来说,我们通过从预定义后缀中选择,使ADVLMs模拟细粒度控制(例如,将"继续直行"扩展为"速度=0.5")。选择规则见补充材料。我们使用DriveLM与LLaMA,在BENCH2ADVLM的220条标准路线上,成功率从9.09提高到12.52。这表明即使是简单的细粒度控制也能提升性能。更根本的解决方案是构建包含控制信号(例如,历史和当前控制动作)的精确数据集并训练整个模型,这将作为未来工作。
混合模式切换。见解2表明,不同模式在不同任务上表现出不同的优势(LLaMA侧重于基本性能,而LLaVA侧重于行为质量)。为了利用它们的优势,我们提出了一种混合模式切换策略,其中ADVLMs识别高风险场景,并在风险情况下选择LLaVA,否则选择LLaMA。具体来说,我们简单地提示ADVLMs"前方场景是否存在安全威胁?",并根据其响应(即,是/否对应LLaMA/LLaVA)选择模式。在BENCH2ADVLM的220条标准路线上对DriveLM进行的实验展示了其有效性,同时提高了成功率和效率(LLaMA:9.09,127.55;LLaVA:6.82,129.83;混合:9.23,131.29)。这些结果表明,混合模式切换有效地结合了模型优势,实现了更自适应和更稳健的ADVLMs。
结论与未来工作
本文介绍了BENCH2ADVLM,一个用于ADVLMs闭环评估的统一基准测试。BENCH2ADVLM通过双系统适应架构将高层驾驶命令转换为中层控制动作,实现了动态、实时的交互。统一的控制抽象层进一步将这些中层动作与物理车辆上的低层执行联系起来。BENCH2ADVLM进一步结合了针对威胁场景的自反性场景生成。大量实验验证了其有效性,为未来ADVLMs的研究提供了见解。
局限性:1)真实世界评估缺少商业自动驾驶车辆的复杂性。2)单智能体实验缺乏交互,限制了协调性评估。
伦理声明与更广泛的影响。本研究未使用人类受试者或敏感数据。所有实验均在仿真或受控环境中进行。BENCH2ADVLM旨在用于研究以提高自动驾驶性能,没有可预见的伦理或社会问题。
#基于开源Qwen2.5-VL实现自动驾驶VLM微调
简单介绍
本次实现GPU 3090, 显存24G, 只用到了400张图片对话(很小的数据集)
参考 https://docs.alayanew.com/docs/documents/useGuide/LLaMAFactory/mutiple/?utm_source=LLaMA-Factory
LLaMA Factory
LLaMA Factory是一款开源低代码大模型微调框架, 以下是对它的详细介绍:LLaMA Factory集成了业界广泛使用的微调技术,目前已经成为开源社区内最受欢迎的微调框架之一,GitHub星标超过4万。本示例将基于Qwen2.5-VL-7B-Instruct模型,介绍如何LLaMA Factory训练框架得到适用于VLM场景的自动驾驶辅助器:给出车辆所处的交通状况,通过自然语言(以对话形式)触发自动驾驶辅助器的功能,并以特定格式返回。
Qwen2.5-VL Technical Report
在本项目中, 模型底座使用Qwen2.5-VL , 以下是对它的详细介绍:Qwen2.5-VL 是 Qwen 视觉 - 语言系列的旗舰模型。它在视觉识别、物体定位、文档解析和长视频理解等方面实现了重大突破,能够使用边界框或点准确地定位物体,还能从发票、表单等中提取结构化数据。该模型引入了动态分辨率处理和绝对时间编码,可处理不同大小的图像和长达数小时的视频。Qwen2.5-VL 提供三种不同大小的模型,旗舰型号 Qwen2.5-VL-72B 的性能与 GPT-4o 和 Claude 3.5 Sonnet 等最先进模型相当,较小的 Qwen2.5-VL-7B 和 Qwen2.5-VL-3B 在资源受限环境中表现出色。
CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving
在本项目中使用了数据集CoVLA(Comprehensive Vision-Language-Action)以下是对它的详细介绍:CoVLA 是用于自动驾驶的综合视觉 - 语言 - 动作数据集。它包含 10,000 个真实驾驶场景,总计超过 80 小时的视频。该数据集利用基于自动数据处理和描述生成流程的可扩展方法,从原始车载传感器数据生成精确驾驶轨迹,并配以详细的自然语言描述,能准确匹配驾驶环境和操作。其在规模和标注丰富性方面超越了现有数据集,为训练和评估视觉 - 语言 - 动作模型提供了全面平台,有助于构建更安全、可靠的自动驾驶系统。基于该数据集还开发了 CoVLA - Agent 模型,用于可解释的端到端自动驾驶。
下载模型及数据集
下载并安装LLaMA-Factory
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]" --no-build-isolation输入命令看下是否安装成功
llamafactory-cli安装huggingface_hub
pip install -U huggingface_hub -i https://pypi.tuna.tsinghua.edu.cn/simple下载Qwen2.5-VL模型 https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct
export HF_ENDPOINT="https://hf-mirror.com" # 配置清华源来加速下载Hugging Face资源
huggingface-cli download --resume-download Qwen/Qwen2.5-VL-7B-Instruct --local-dir ./model/Qwen2.5-VL-7B-Instruct --max-workers=3上面下载似乎很慢,可以在浏览器上直接手动下载模型
下载CoVLA数据集 https://huggingface.co/datasets/AlayaNeW/QA_from_CoVLA_zh
export HF_ENDPOINT="https://hf-mirror.com" # 配置清华源来加速下载Hugging Face资源
huggingface-cli download AlayaNeW/QA_from_CoVLA_zh --repo-type dataset --local-dir ./QA_from_CoVLA_zh**图片:基于CoVLA数据集中的images,过滤筛选出400张图片。 QA问答对:基于QA_from_CoVLA数据集进行整理翻译。因为只有400张图片, 所以实际数据并不太大.**下面是图片 2022-07-14--14-32-55--11_first/0553.png 的一些对话. 对话内容在QA_from_CoVLA_zh.json
{
"conversations": [
{
"from": "human",
"value": "<image>\n图片中的天气如何?"
},
{
"from": "gpt",
"value": "天气多雨,置信度为0.978。"
},
{
"from": "human",
"value": "<image>\n车辆真正行驶在哪种道路?"
},
{
"from": "gpt",
"value": "该车辆行驶在宽阔的道路上,置信度为0.659。"
}
],
"images": [
"/dev/shm/llamafactory/dataset/qa_images/images/2022-07-14--14-32-55--11_first/0553.png",
"/dev/shm/llamafactory/dataset/qa_images/images/2022-07-14--14-32-55--11_first/0553.png"
]
},
{
"conversations": [
{
"from": "human",
"value": "<image>\n自动驾驶汽车应该关注哪些风险?"
},
{
"from": "gpt",
"value": "风险是:注意交通信号灯和道路上的其他车辆,置信度为0.656。"
},
{
"from": "human",
"value": "<image>\n您可以在图片中看到行人或车辆吗?"
},
{
"from": "gpt",
"value": "没有行人的概率为0.130。存在其他车辆的概率为43.064%。"
}
],
"images": [
"/dev/shm/llamafactory/dataset/qa_images/images/2022-07-14--14-32-55--11_first/0553.png",
"/dev/shm/llamafactory/dataset/qa_images/images/2022-07-14--14-32-55--11_first/0553.png"
]
},QA_from_CoVLA_zh.json文件是一些对image的描述性对话, 而"images"的路径名和实际本地存放image的路径应该是不一致的, 这时需要全局替换成本地实际image存放的路径.
LLaMA Factory的Web UI
SwanLab是一款开源且轻量级的AI模型训练可视化追踪工具。在本次微调任务中,我们将使用SwanLab记录整个微调过程。安装SwanLab的命令行(不安装也行)
pip install swanlab -i https://pypi.tuna.tsinghua.edu.cn/simple/copy备份一份模型和数据集, 以免操作失误导致损坏.
cp -r /home/hy/data/QA_from_CoVLA_zh /home/hy/source/code/transformer/LLaMA-Factory/info
cp -r /home/hy/data/model/Qwen2.5-VL-7B-Instruct /home/hy/source/code/transformer/LLaMA-Factory/info记得将对话中的images字段路径也要跟着改动一下.
在LLaMA-Factory路径下输入:
llamafactory-cli webui # 启动web ui界面通过http://localhost:7860启动web ui界面并设置配置参数. 截断长度应该设置的大一些,否则会报错.
各项参数配置完成后,单击"开始"按钮,执行大模型的微调任务。开始微调后,页面最下方会显示微调过程的日志。微调后的模型被保存在 /home/hy/source/code/transformer/LLaMA-Factory/saves/Qwen2.5-VL-7B-Instruct/lora/train_2025-07-27-12-30-16 中, ui会显示loss进度和进度条。
可能会显示CUDA out of memory, 修改"批处理大小"和"梯度累积"的参数应该可以缓解.
测试VLM
训练完成后在Web UI界面,配置检查点路径中选择微调模型的路径,示例如下图高亮所示。
单击"加载模型"按钮,加载微调后的模型,使用加载好的微调模型进行对话,下载素材图片,然后上传图片,如下图高亮所示。输入问题"自动驾驶车辆应该关注哪些风险?",观察模型回答,如下图高亮所示。
清空"检查点路径"LoRa配置,单击"加载模型"按钮,使用原生的Qwen2.5-VL-7B-Instruct模型进行对话,输入同一个问题:"自动驾驶车辆应该关注哪些风险?",观察模型回答,示例如下图所示。
综合看来通过使用微调后的模型进行对话,可以获得更具参考价值的回答。原始模型虽然回答内容很多,但有些答非所问。
#自动驾驶中常提的VLM是个啥?与VLA有什么区别?
自动驾驶车辆要在复杂多变的道路环境中安全行驶,不仅需要"看见"前方的车辆、行人和路面标志,还需要"读懂"交通标识上的文字提示、施工告示牌和乘客的语言指令。之前和大家讨论过VLA,了解到视觉-语言-动作模型,但在很多场景中,大家还会提到VLM,看起来与VLA非常类似,那VLM又是个啥?与VLA(Vision-Language-Action,视觉-语言-动作)又有什么区别?
什么是VLM?
VLM即视觉-语言模型(Vision--LanguageModel),是一类让计算机"看懂"图像和"读懂"文字能力合二为一的人工智能系统,它通过在同一个模型中联合处理视觉特征和语言信息,实现对图片或视频内容的深度理解与自然语言互动。VLM可以抽取图像中的物体形状、颜色、位置甚至动作,然后将这些视觉嵌入与文本嵌入在多模态 Transformer 中融合,让模型学会把"画面"映射成语义概念,再通过语言解码器生成符合人类表达习惯的文字描述、回答问题或创作故事。通俗来说,VLM 就像拥有视觉和语言双重感官的"大脑",能够在看到一张照片后,不仅识别出里面的猫狗、车辆或建筑,还能用一句话或一段话把它们生动地说出来,大大提升了 AI 在图文检索、辅助写作、智能客服和机器人导航等场景中的实用价值。
如何让VLM高效工作?
VLM可以将一帧原始的道路图像转换为计算机能处理的特征表示。这一过程通常由视觉编码器完成,主流方案包括卷积神经网络(CNN)和近年来兴起的视觉Transformer(ViT)。它们会对图像进行分层处理,提取出道路纹理、车辆轮廓、行人形状以及路牌文字等多种视觉特征,并将它们编码为向量形式。语言编码器和语言解码器则负责处理自然语言的输入与输出,也采用基于Transformer的架构,将文字拆分为Token,然后学习各个Token之间的语义关联,并能够根据给定的向量特征生成连贯的语言描述。
将视觉编码器得到的图像特征和语言模块进行对齐是VLM的关键所在。常见的做法是通过跨模态注意力(cross-attention)机制,让语言解码器在生成每个文字Token时,能够自动关注到图像中与该文字最相关的区域。比如在识别"前方施工,请减速慢行"这句话时,模型会在图像中着重关注黄色施工标志、交通锥或挖掘机等显著区域,从而保证生成的文字与实际场景高度一致。整个系统可以端到端联合训练,也就是说模型的损失函数会同时考虑视觉特征提取的准确性和语言生成的流畅性,通过不断迭代,将两者的性能共同提升。
为了让VLM更好地适应自动驾驶的特殊场景,训练过程通常分为预训练和微调两个阶段。在预训练阶段,会利用海量的网络图文,比如从互联网收集的大规模图片和对应的标题、说明文字,让模型先掌握通用的视觉-语言对应关系。这一阶段的目标是让模型具备跨领域的基本能力,能识别多种物体、理解常见场景、生成自然表达。随后,进入微调阶段,需要采集自动驾驶专属的数据集,这其中包括各种道路类型(城市道路、高速公路、乡村公路)、多种天气条件(晴天、雨雪、夜晚)、不同交通设施(施工区域、隧道、十字路口)等场景下的图像,并配以专业标注的文字描述。通过这种有针对性的训练,模型才能在实际行驶中精准识别交通标志上的文字信息,并及时生成符合交通法规和行驶安全的提示语。
在实际应用中,VLM能够支持多种智能化功能。首先是实时场景提示。当车辆行驶在突遇施工、积水、落石等危险区域时,VLM会识别路面状况,结合图像中出现的施工标志、警示牌或水坑轮廓,自动生成"前方道路施工,请提前减速"或"前方积水较深,请绕行"的自然语言提示,并将该提示通过仪表盘或车载语音播报给驾驶员。其次是交互式语义问答。乘客可通过语音助手询问"前方哪条车道最快?"、"我还能在下一个路口右转吗?"等问题,系统会将语音转文字后,结合当前图像和地图数据,利用VLM回答"从左侧车道行驶可避开前方拥堵,请注意车距"或"前方禁止右转,请继续直行"之类的文字回复。再者,VLM还可对路标与路牌文字识别,它不仅对交通标志的图形进行分类,还能识别标志牌上的文字信息,将"限高3.5米""禁止掉头""施工中"等信息结构化地传递给决策模块。
为了让VLM在车载环境中实时运行,通常会采用"边缘-云协同"架构。在云端完成大规模预训练和定期微调,将性能最优的模型权重通过OTA(Over-The-Air)下发到车载单元;车载单元部署经过剪枝、量化和蒸馏等技术优化后的轻量级推理模型,依托车载GPU或NPU在毫秒级别内完成图像与语言的联合推理。对于对时延要求极高的安全提示,优先使用本地推理结果;对于更加复杂的非安全场景分析,如行程总结或高级报告,则可异步将数据上传云端进行深度处理。
数据标注与质量保障是VLM部署的另一大关键。标注团队需要在不同光照、天气、道路类型条件下采集多视角、多样本图像,并为每张图像配备详尽的文字描述。如对一张高速路施工场景的图像,不仅要框选出施工车辆、路障和交通锥,还要撰写"前方高速公路正在施工,左侧车道封闭,请向右变道并减速至60公里/小时以内"的自然语言说明。为了保证标注一致性,通常会进行多轮审核和校验,并引入弱监督策略对大量未标注图像生成伪标签,降低人工成本的同时保持数据多样性与标注质量。
安全性与鲁棒性是自动驾驶的核心要求。当VLM在雨雪、雾霾或复杂光照条件下出现识别错误时,系统必须迅速评估其不确定性,并及时采取冗余措施。常见做法有利用模型集成(Ensemble)或贝叶斯深度学习(BayesianDL)计算输出置信度,当置信度低于阈值时,系统退回至传统多传感器融合感知结果,或提示驾驶员手动接管。与此同时,跨模态注意力的可解释性工具能够帮助在事故复盘时追踪模型的决策过程,明确模型为何在某一帧图像中生成特定提示,从而为系统迭代和责任认定提供依据。
随着大语言模型(LLM)和大视觉模型(LVM)的持续发展,VLM将在多模态融合、知识更新和人机协同方面取得更大突破。系统不仅能处理摄像头图像,还会整合雷达、LiDAR和V2X(Vehicle-to-Everything)数据,使得对车辆周边环境的感知更为全面;同时将实时获取的交通法规更新、路政公告和气象预报输入语言模型,为车辆决策和提示提供最新背景知识;在交互方式上,乘客可通过语音、手势和触摸屏多模态联合输入,获取更加自然、有效的行驶建议。
VLA与VLM有何差别?
VLA与VLM都是大模型的重要技术,那两者又有何区别?VLA和VLM虽然都属于多模态大模型体系,但在模型架构、目标任务、输出类型和应用场景上其实存在根本差异。VLM主要解决的是图像与语言之间的关联问题,其核心能力是对图像进行语义理解,并通过语言表达这种理解,输出形式通常是自然语言,例如图像描述、视觉问答、图文匹配、图文生成等,代表任务包括"这张图里有什么?""这个图和这段话是否匹配?"等,广泛应用于AI助手、搜索引擎、内容生成和信息提取等领域。
VLA则是VLM的进一步扩展,它不仅需要理解图像中的视觉信息和语言指令,还要将两者融合后生成可执行的动作决策,输出不再是文本,而是物理控制信号或动作计划,例如加速、刹车、转弯等。因此,VLA模型不仅承担感知和理解任务,还需要完成行为决策和动作控制,是面向真实世界"感知---认知---执行"闭环系统的关键技术,其典型应用包括自动驾驶、机器人导航、智能操作臂等。可以说,VLM是"看懂+说清楚",而VLA是"看懂+听懂+做对",前者更偏向信息理解与表达,后者则更聚焦智能体的自主行为能力和决策执行能力。
最后的话
视觉-语言模型通过将图像感知与自然语言处理相结合,为自动驾驶系统提供了更丰富、更灵活的语义层面支持。它不仅能帮助车辆"看懂"复杂的道路场景,还能用"看得懂"的自然语言与人类驾驶员或乘客进行高效交互。尽管在模型体积、实时性、数据标注与安全保障等方面仍面临挑战,但随着算法优化、边缘计算与车联网技术的不断进步,VLM定将成为推动智能驾驶进入"感知-理解-决策"一体化时代的关键引擎,为未来出行带来更高的安全性和舒适性。
#自动驾驶论文速递 | 端到端、分割、轨迹规划、仿真等~
DRIVE
约束感知自动驾驶的动态规则推断与验证评估框架
斯坦福大学和微软提出了 DRIVE 框架,通过动态规则推断和验证评估技术,实现了自动驾驶中概率软约束的学习与规划集成,在 inD、highD 和 RoundD 数据集上达成 0.0% 软约束违反率,并显著提升轨迹平滑性与泛化能力。
- 论文标题:DRIVE: Dynamic Rule Inference and Verified Evaluation for Constraint-Aware Autonomous Driving
- 论文链接:https://arxiv.org/abs/2508.04066
- 代码:https://github.com/genglongling/DRIVE
主要贡献:
- 提出 DRIVE 框架,通过指数族似然建模从专家驾驶演示中学习概率性软约束,克服了传统方法依赖固定约束形式或纯奖励建模的局限,实现了动态规则推理与轨迹级决策的紧密耦合。
- 将学习到的约束分布嵌入凸优化规划模块,生成兼具动态可行性和人类偏好兼容性的轨迹,支持数据驱动的约束泛化与系统性可行性验证。
- 在 inD、highD、RoundD 等大规模自然驾驶数据集上验证了其优势:软约束违反率为 0%,轨迹更平滑,在多样场景中泛化能力更强,且框架具备高效性、可解释性和鲁棒性。
算法框架:
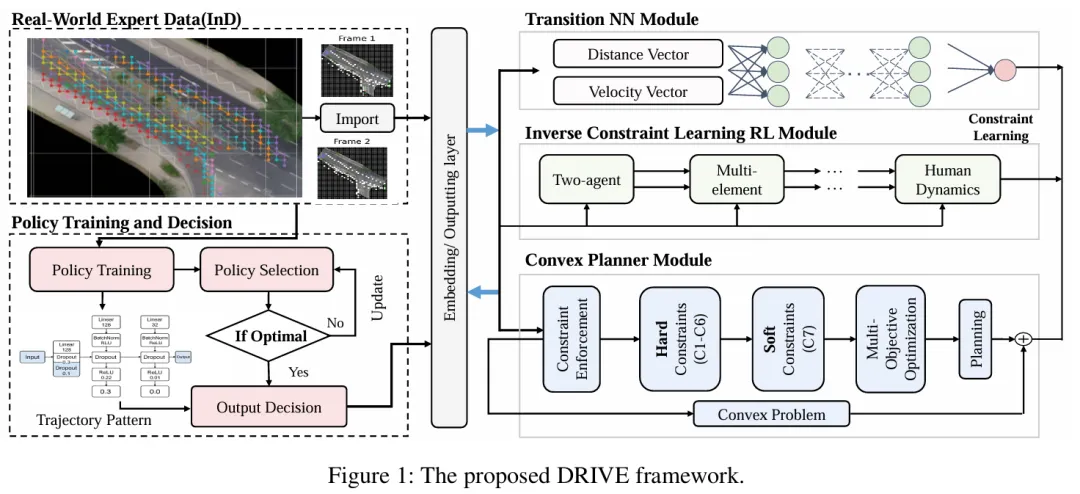
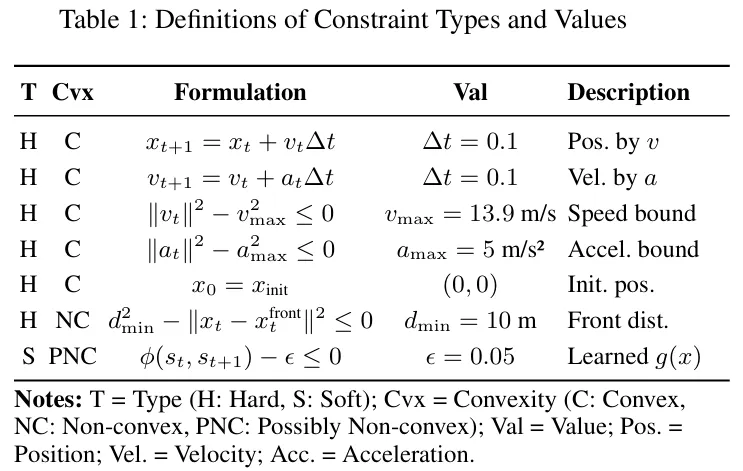
实验结果:
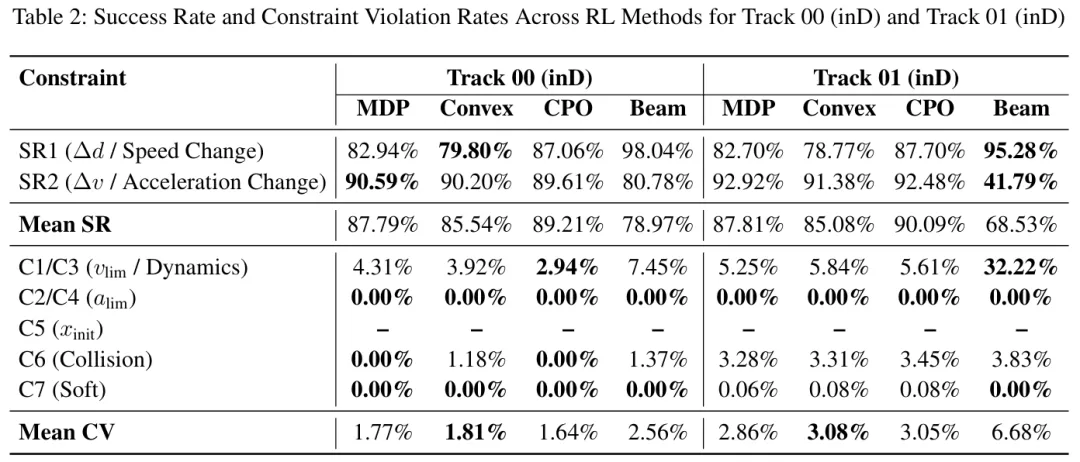
可视化:

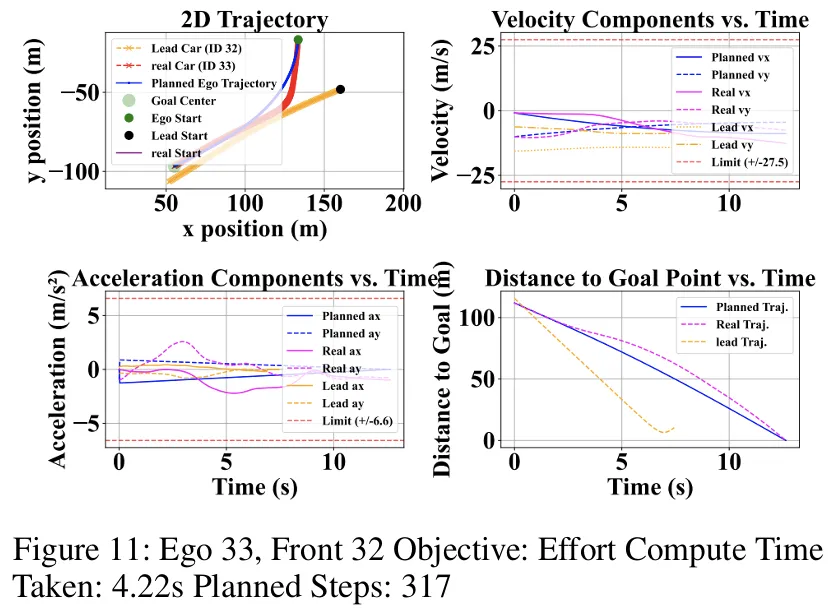
基于混合学习-优化框架的可靠实时高速公路轨迹规划
北京交通大学与海南大学提出混合学习-优化轨迹规划框架,在高速公路场景中实现97%成功率和54ms实时规划性能。
- 论文标题:Reliable and Real-Time Highway Trajectory Planning via Hybrid Learning-Optimization Frameworks
- 论文链接:https://arxiv.org/abs/2508.04436
主要贡献:
- 提出一种混合轨迹规划框架,融合学习方法的适应性与优化方法的形式化安全保证,采用两层架构:上层基于图神经网络(GNN)预测类人纵向速度剖面,下层通过混合整数二次规划(MIQP)进行路径优化。
- 下层路径优化模型创新性地引入车辆几何离散化的线性近似,显著降低计算复杂度;同时施加严格的时空不重叠约束,在整个规划时域内形式化保证避撞。
- 实验验证该框架在复杂真实紧急场景中能生成平滑无碰撞轨迹,成功率超 97%,平均规划时间 54 ms,证实其实时性。
算法框架:
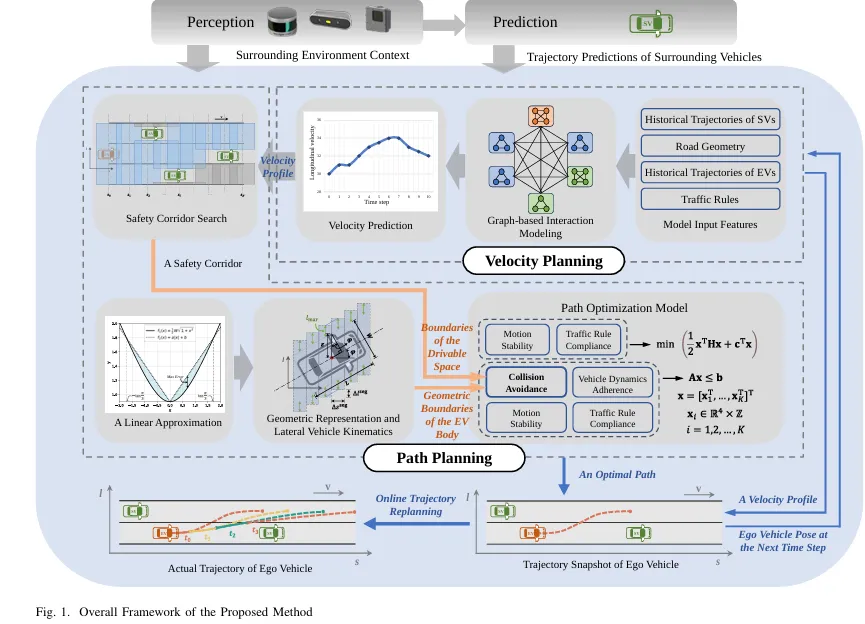
实验结果:
可视化:
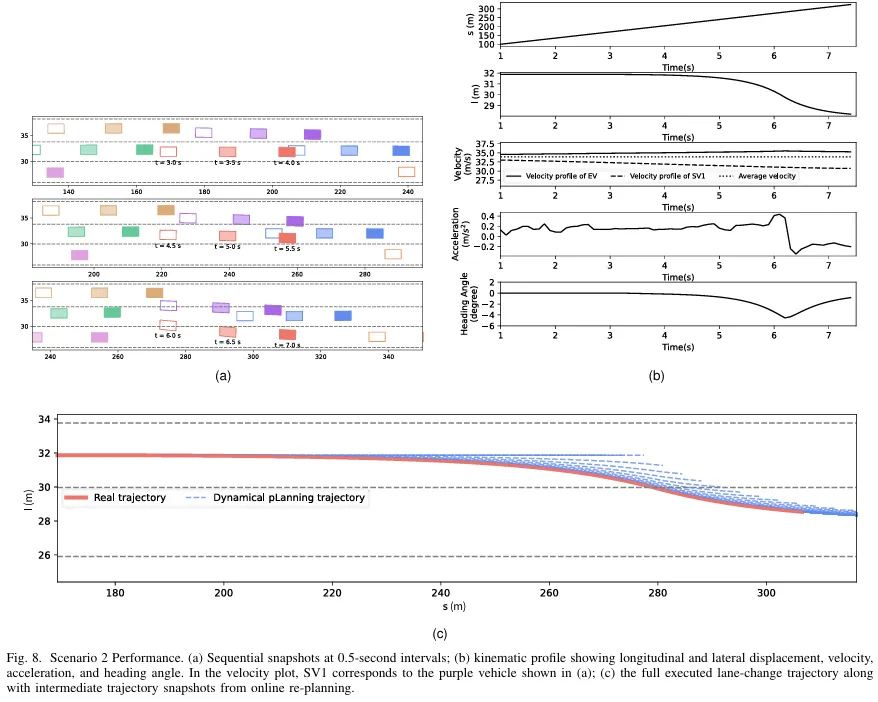
RoboTron-Sim
基于模拟困难场景增强的真实世界驾驶性能优化
美团与中山大学团队ICCV 2025中稿的工作,本文通过模拟硬案例增强技术(RoboTron-Sim),显著提升自动驾驶在极端场景的鲁棒性,在 nuScenes 测试中实现困难场景碰撞率降低 51.3%、轨迹精度提升 51.5%(表 3/4/5),且仅需 20% 真实数据即可达到全量数据性能(图 6)。
- 论文标题:RoboTron-Sim: Improving Real-World Driving via Simulated Hard-Case
- 论文链接:https://arxiv.org/abs/2508.04642
主要贡献:
- 首次深入研究多模态大语言模型(MLLMs)在自动驾驶中的模拟到现实(Sim2Real)迁移限制,并提出一种简单有效的框架,通过策略性利用合成硬案例数据增强真实世界驾驶能力。
- 针对模拟与真实世界数据的关键领域差异,提出场景感知提示工程(SPE)和几何感知的图像到自车编码器(I2E Encoder),前者动态建模数据来源和地理语境,后者解耦传感器特定参数。
- 在 nuScenes 数据集上的实验表明,RoboTron-Sim 实现了最先进的规划性能,尤其在硬场景中,L2 距离提升 48.1%,碰撞率降低 45.8%。
算法框架:


实验结果:
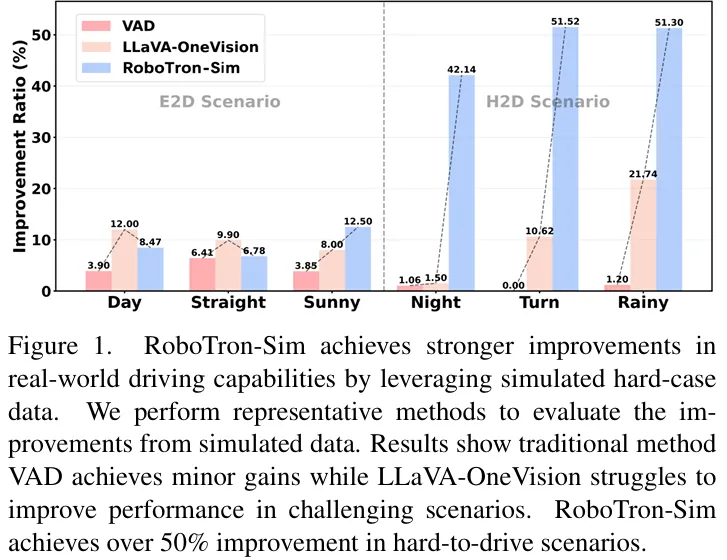
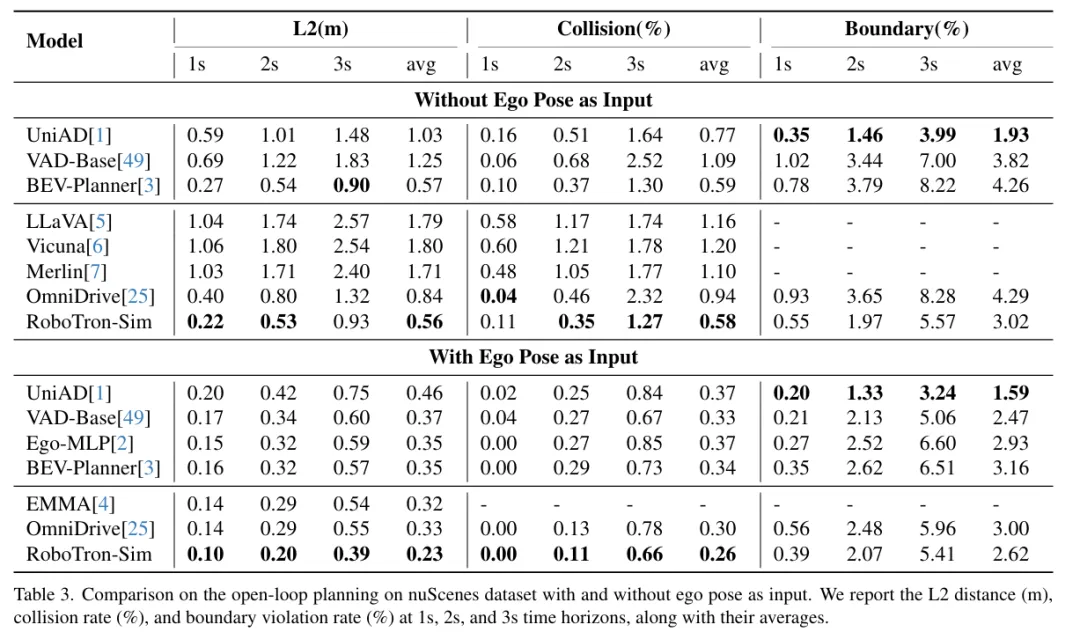
可视化:
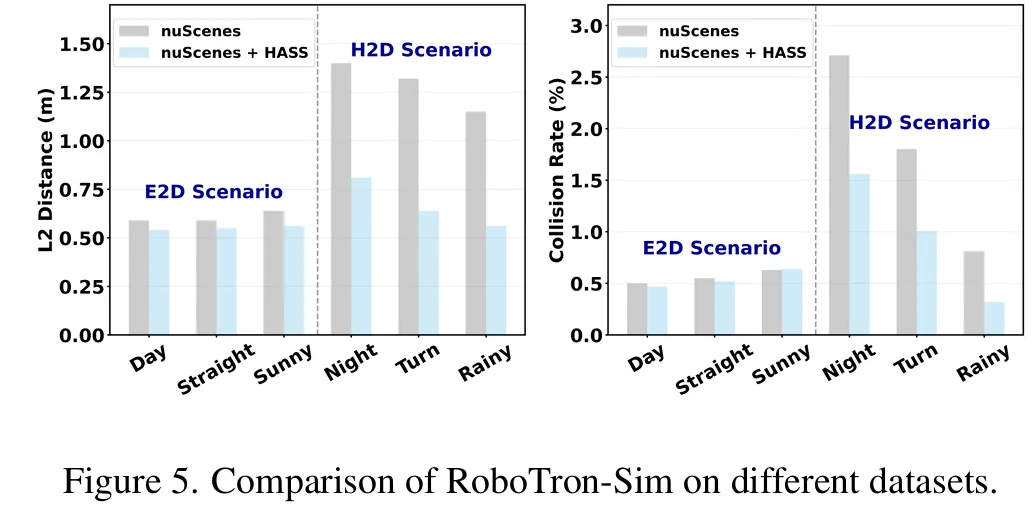

语义与视觉上下文驱动的车辆部件分割
基于SAM的框架及VehicleSeg10K基准数据集
安徽大学团队 提出了 SAV 框架,通过集成车辆部件知识图谱和视觉上下文样本增强,实现了无提示的高精度车辆部件分割,在自建的 VehicleSeg10K 数据集上达到 81.23% mIoU,显著超越之前最佳方法 4.33% mIoU。
- 论文标题:Segment Any Vehicle: Semantic and Visual Context Driven SAM and A Benchmark
- 论文链接:https://arxiv.org/abs/2508.04260
- 项目主页:https://github.com/Event-AHU/SAV
主要贡献:
- 提出了一种基于预训练基础模型的车辆部件分割框架 SAV(Segment Anything Vehicle),该框架整合了车辆部件知识图谱(建模部件间空间几何关系)和视觉上下文样本增强策略(利用相似视角车辆图像优化分割)。
- 构建了大规模车辆部件分割基准数据集 VehicleSeg10K,包含 11,665 张图像(13 个部件类别),覆盖多样场景,并在其上评估了 18 种主流算法,为相关研究提供了基础。
- 在多个车辆分割数据集上的实验表明,SAV 在分割精度和部件级语义一致性上显著优于现有方法。
算法框架:
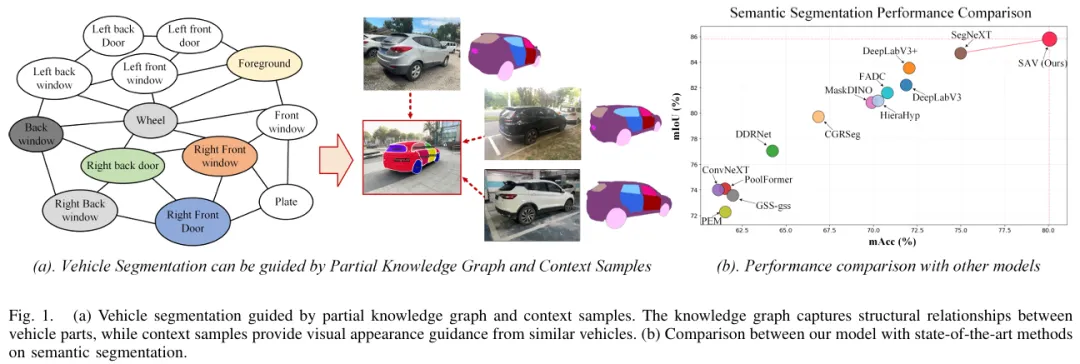
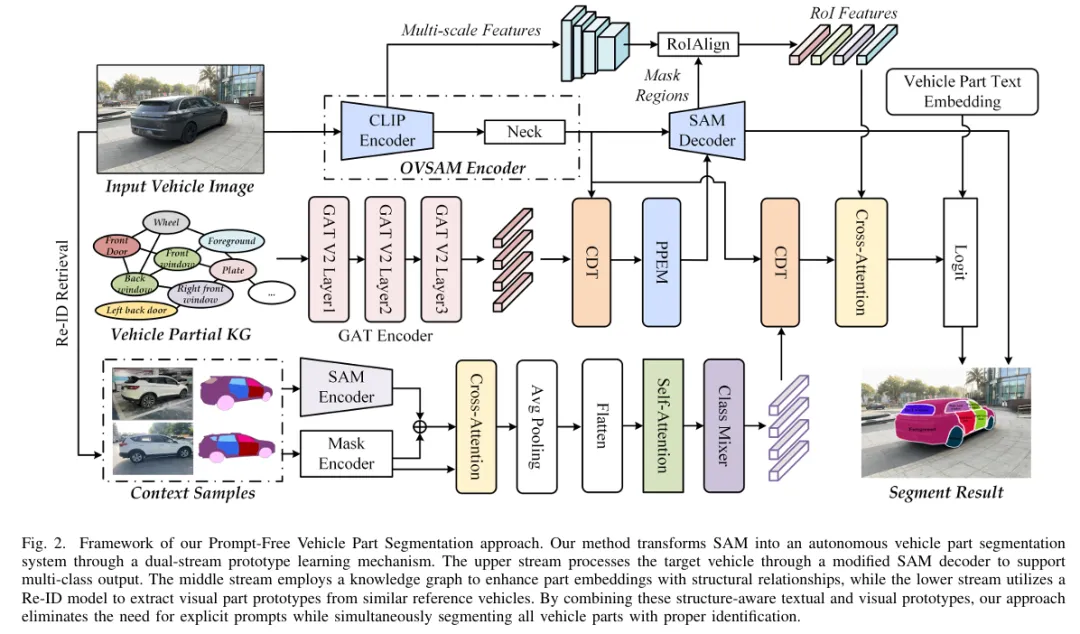
实验结果:
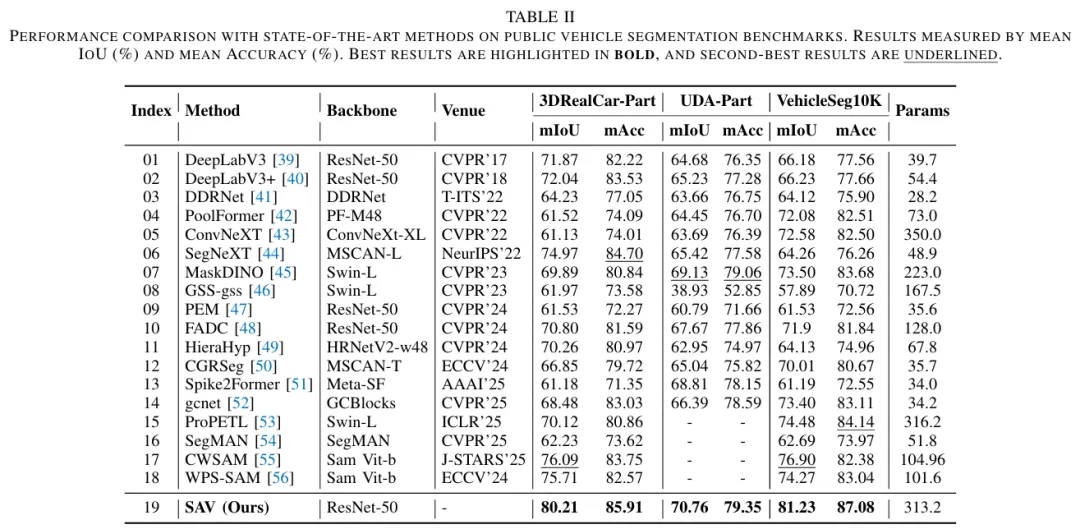
可视化:

.
#FiM
港科大:从Planning的角度重新思考轨迹预测
预测行驶中的交通参与者的轨迹运动,对于确保自动驾驶系统的安全性而言,既是一项重大挑战,也是一项至关重要的需求。与大多数现有的、直接预测未来轨迹的数据驱动方法不同,我们从规划(planning)的视角 重新思考这一任务,提出一种"先推理,后预测(First Reasoning, Then Forecasting) "的策略,该策略显式地将行为意图作为轨迹预测的空间引导。为实现这一目标,进一步引入了一种可解释的、基于奖励的意图推理器(intention reasoner),其建立在一种新颖的以查询为中心的逆强化学习(query-centric Inverse Reinforcement Learning, IRL) 框架之上。我们的方法首先将交通参与者和场景元素编码为统一的向量化表示,然后通过以查询为中心的范式聚合上下文特征。进而推导出一个奖励分布(reward distribution) ------一种紧凑但信息丰富的表示,用于刻画目标参与者在给定场景上下文中的行为。在该奖励启发式(reward heuristic)的引导下,我们进行策略 rollout,以推理多种可能的意图,从而为后续的轨迹生成提供有价值的先验信息。最后开发了一种集成**双向选择性状态空间模型(bidirectional selective state space models)**的分层DETR-like解码器,以生成精确的未来轨迹及其对应的概率。在大规模的Argoverse和nuScenes运动预测数据集上进行的大量实验表明,我们的方法显著提升了轨迹预测的置信度,在性能上达到了与当前最先进方法相当甚至更优的水平。
简介
轨迹预测是自动驾驶系统的关键组成部分,它连接了上游的感知模块和下游的规划模块。准确预测周围交通参与者未来的运动,需要对未知的意图进行推理,因为驾驶行为本质上具有不确定性和多模态特性。
大多数现有的数据驱动运动预测模型采用模仿学习(imitative)方法,要么直接回归轨迹,要么基于训练数据集中的数据分布对终点进行分类。然而,这些方法通常对驾驶行为的考虑不足,限制了其可解释性和可靠性。尽管许多方法在基准测试指标上表现出色,但很少有方法能显式地对未来的意图进行推理,这在现实应用中生成可解释且鲁棒的多模态预测时,形成了一个关键瓶颈。
相比之下,人类驾驶员通常以分层的方式操控车辆,先做出高层次决策(例如变道或超车),再执行具体的运动策略。我们可以将自车(ego vehicle)的预测模块视为在为其他参与者进行规划,前提是假设道路使用者的行为是理性的。尽管轨迹预测与规划之间存在内在联系,但很少有研究探索来自规划领域的洞见。受这些观察的启发,我们提出了一个关键问题:能否从规划的视角来处理轨迹预测任务,并通过引入意图推理能力来加以增强?
为此,我们提出一种"先推理,后预测(First Reasoning, Then Forecasting)"的策略,其中行为意图推理为准确且可信的多模态运动预测提供了关键的先验指导。以超车场景为例:一个能够提前显式推理出"超车"和"保持车道"两种意图的模型,相比没有进行推理而直接预测的模型,能够生成更可靠的预测结果,如图1所示。
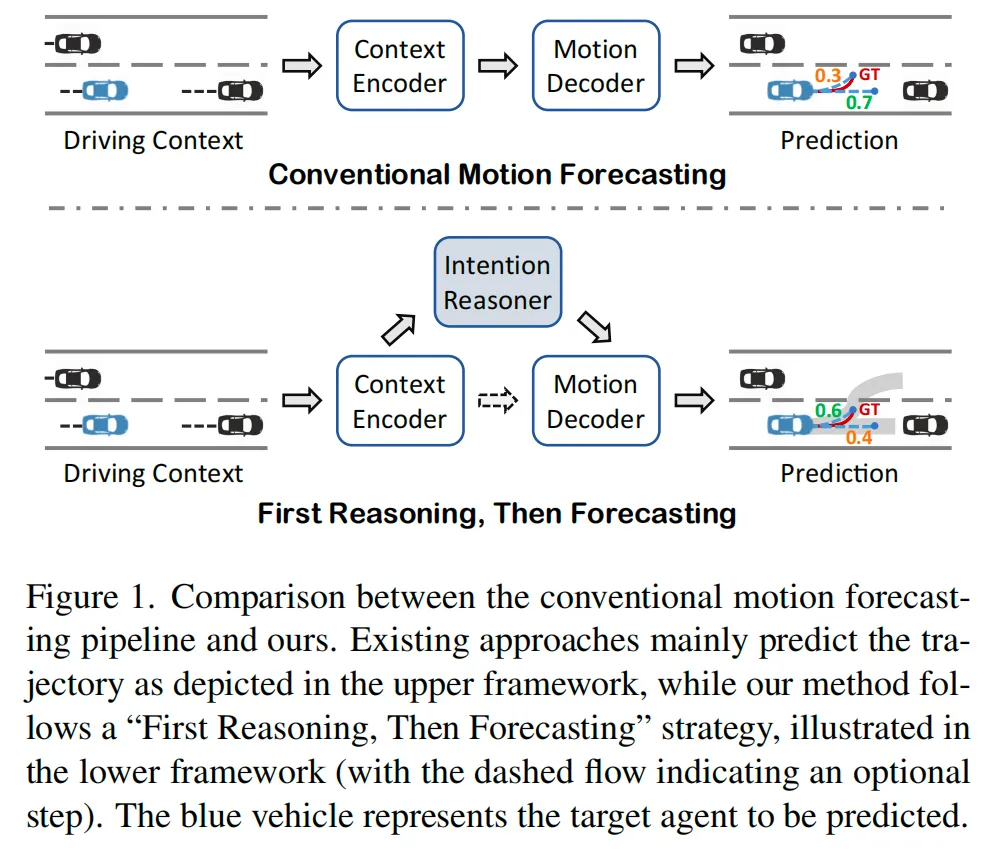
此外,结合更长期的意图推理可以进一步提升预测的置信度(见表2)。
然而,由于驾驶场景固有的复杂性,仅依赖手工设计的规则或预定义的规划器来进行未来意图推理仍然具有挑战性。一种有前景的替代方案是利用大型推理模型(Large Reasoning Models, LRMs) (如OpenAI-o1)在轨迹预测器中实现意图推理。然而,它们巨大的计算需求使其在车载驾驶系统中不切实际。幸运的是,LRMs的最新进展表明,强化学习(RL)技术在数学和编程等领域展现了卓越的推理能力,这引发了一个有趣的问题:能否利用基于RL的范式来推理轨迹预测中参与者的未来意图?
在这方面,我们探索了将RL范式应用于建模自动驾驶场景中参与者行为推理的可行性。我们将任务形式化为一个马尔可夫决策过程(Markov Decision Process, MDP) ,并据此定义目标参与者的行为意图。为了在性能和计算效率之间取得平衡,我们构建了一个网格级图(grid-level graph) 来表示场景布局,其中意图被定义为在离散网格世界中的一系列决策,类似于传统RL语境中的"规划"。本文将这种意图序列称为基于网格的推理遍历(Grid-based Reasoning Traversal, GRT)。
然而,将RL应用于轨迹预测的一个根本性挑战在于如何建模奖励(reward),因为参与者的意图是未知的。
为克服这一挑战,我们提出了一种基于最大熵逆强化学习(Maximum Entropy Inverse Reinforcement Learning, MaxEnt IRL) 的奖励驱动意图推理器。该框架首先通过IRL,从专家示范(demonstrations)和相关驾驶上下文中学习参与者特定的奖励分布。所学习到的奖励作为一种紧凑的表示,捕捉了参与者的可观测行为及其潜在意图。利用这些推断出的奖励作为启发式信息,我们随后进行策略rollout,以采样多种可能的GRT,并提取其对应的、以意图为指导的特征,从而为轨迹预测提供先验指导,进而提高预测的准确性和置信度。
此外,为了进一步增强从场景上下文中提取特征的能力,提出了一种新颖的以查询为中心的IRL框架(Query-centric IRL, QIRL),该框架将IRL与一种基于查询的编码机制相结合。QIRL能够高效且灵活地将向量化场景上下文特征聚合到类似空间网格的token中,便于进行结构化推理。
通过这种密集的网格表示,我们在模型中增加了一个辅助的**占用网格图(Occupancy Grid Map, OGM)**预测头,该模块能够对场景中每个参与者未来的时空占用进行密集预测。这一辅助任务通过捕捉参与者之间的未来交互,有效增强了特征融合过程,从而提升了整体预测性能(见表7)。
最后为了充分利用意图推理器提供的特征,开发了一种分层的DETR-like轨迹解码器。一个无锚点(anchor-free)的轨迹token首先基于GRT推导出的特征生成初始提议(proposals),这些提议随后作为最终轨迹解码的初始化锚点。考虑到轨迹状态固有的序列性质,以及选择性状态空间模型(Mamba) 在长时程、结构化动态建模方面的最新进展,引入了一种双向变体------Bi-Mamba,以有效捕捉轨迹状态的序列依赖关系。这一增强显著提升了预测的准确性和置信度(见表6)。
总结来说,本文的主要贡献如下:
- 提出了一种"先推理,后预测"的策略,从规划的视角重新思考轨迹预测任务。
- 为运动预测提出了一种全新的奖励驱动意图推理器,其中QIRL模块在以查询为中心的框架下,集成了MaxEnt IRL范式和向量化上下文表示。
- 开发了一种集成双向选择性状态空间模型(Bi-Mamba)的分层DETR-like解码器,以提高预测的准确性和置信度。
- 的方法显著提升了预测置信度,并在Argoverse和nuScenes运动预测基准测试上取得了极具竞争力的性能,超越了其他最先进的模型。
相关工作回顾
自动驾驶轨迹预测
自动驾驶的轨迹预测已研究数十年。该领域的早期工作主要依赖于手工设计的基于规则或基于物理的方法,这些方法难以处理复杂场景,且缺乏进行长期预测的能力。近年来,研究方法已转向基于学习的框架,该框架利用深度神经网络来编码交通参与者的运动历史,同时整合高精地图(HD maps)的拓扑和语义信息。这些地图通常以光栅化(rasterized)或向量化(vectorized)格式表示。光栅化表示通常使用鸟瞰图(Bird's-Eye-View, BEV)图像作为输入,而向量化表示则依赖于参与者和地图的折线(polylines)作为输入。卷积神经网络(CNNs)和图神经网络(GNNs)被广泛用作这些格式的特征提取器,在编码场景上下文方面发挥着关键作用。最近,基于Transformer的架构因其能够提升整体预测性能而受到广泛关注。顺应这一趋势,我们的工作采用了向量化表示,并利用基于查询的Transformer编码器-解码器结构来进行特征聚合和轨迹生成。
尽管取得了这些进展,但在使轨迹预测对分布外(out-of-distribution)场景具有鲁棒性,以及对未见过的环境具有可泛化性方面,挑战依然存在。我们的工作通过从规划的视角 重新思考轨迹预测任务,引入了一种基于奖励的意图推理器,以提供行为指导和上下文丰富的先验信息,从而推进轨迹预测,来解决这些不足。
奖励(Reward)
奖励是规划(planning)和强化学习(RL)中的一个基础概念,它作为一种引导信号,塑造了智能体的行为和决策过程。在规划中,奖励通常被设计为与高层目标对齐,例如在避开障碍物的同时到达目标点。通常,奖励函数是手工设计的,或通过分层框架进行塑造,其中高层规划器为低层控制器提供策略指导。关于奖励塑造(reward shaping)的研究表明,通过修改奖励结构来强调特定行为或里程碑,可以加速学习过程并提高策略的鲁棒性。
在强化学习(RL)中,奖励函数扮演着核心角色,它定义了智能体的目标,并引导其执行能够随时间最大化累积奖励的动作。奖励函数的设计在规划和RL中都至关重要;然而,为复杂任务(如自动驾驶)设计有效的奖励函数极具挑战性。为了解决这一挑战,逆强化学习(Inverse RL, IRL)被提出。IRL专注于从观察到的专家示范(expert demonstrations)中推断出奖励函数,这在直接定义奖励函数不可行的场景中尤其有价值。例如,最大熵逆强化学习(MaxEnt IRL)已被广泛应用于学习能够捕捉专家行为潜在意图的奖励函数,从而使智能体能够在规划任务中复制细致入微、类似人类的决策。
尽管IRL非常有用,但现有的高效IRL算法通常针对结构化和网格状环境进行定制,这限制了它们在更复杂领域中的灵活性。为了克服这一局限性,我们提出了一种新颖的以查询为中心的框架 (query-centric framework),该框架增强了MaxEnt IRL在我们基于奖励的意图推理器中的适用性和灵活性。通过利用这一范式,我们的方法提供了有价值的奖励启发式信息,能够有效推理未来行为的意图,为解决运动预测任务固有的复杂性提供了信息丰富的先验。
算法详解
问题定义
标准轨迹预测任务的目标是,在给定驾驶上下文的情况下,预测目标参与者在未来时间范围 内的位置。我们采用向量化表示作为场景输入,包括历史观测状态 ,其中 表示场景中的参与者数量, 表示过去的时间戳数量, 捕捉位置、速度、航向等运动特征,以及高精地图(HD map)信息 ,其中 和 分别对应车道中心线和车道段的数量, 表示相关的车道属性。
我们的方法采用以目标为中心的坐标系,通过平移和旋转操作,将所有输入元素归一化到目标参与者当前的状态。鉴于运动意图的内在不确定性,预测器的任务是提供 条未来的轨迹 ,以及对应的概率 。
框架概述
如图2所示,我们的运动预测方法采用了一种编码器-解码器结构,该结构包含一个以查询为中心的场景上下文编码器、一个由Mamba增强的分层轨迹解码器,以及一个奖励驱动的意图推理器。
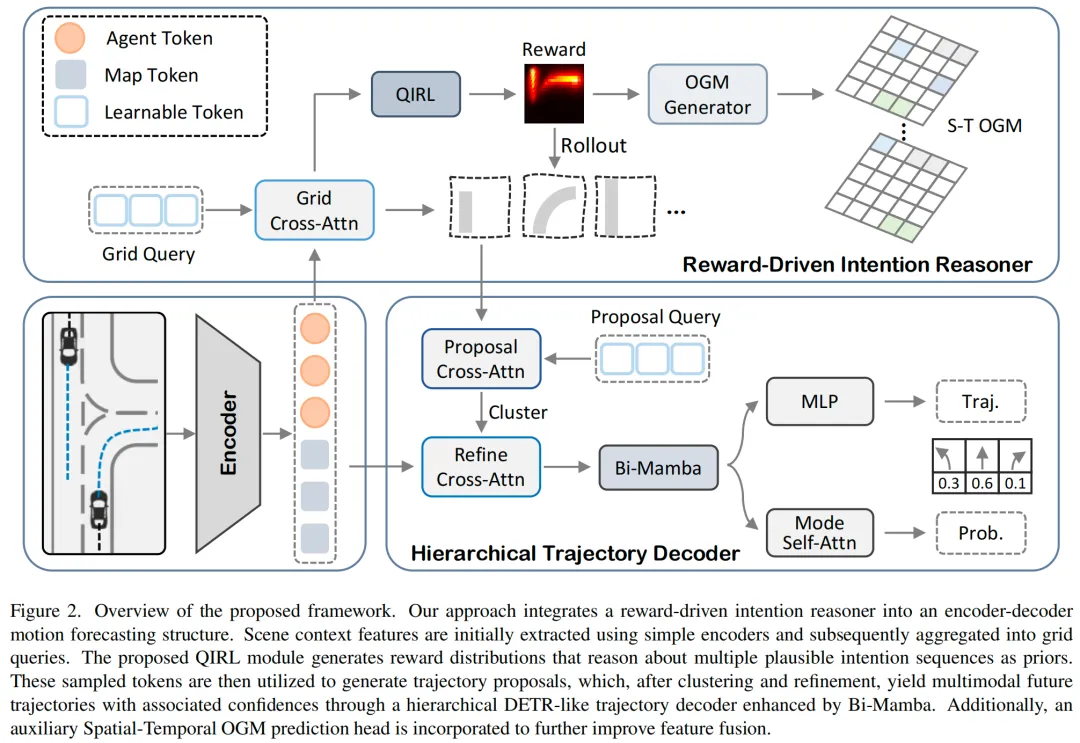
首先以向量化格式表示驾驶上下文,并利用参与者和地图编码器提取场景特征。然后,通过交叉注意力机制将这些融合后的特征聚合到空间网格token中。接着,在QIRL模块中,利用一种基于网格的MaxEnt IRL算法推断奖励分布,从而通过策略rollout在2D网格地图上推理出多种可能的意图序列(即GRTs)。此外,我们引入了一个用于时空占用网格图(S-T OGM)的密集预测头,以建模参与者之间的未来交互。最后,我们引入了一种分层的DETR-like轨迹解码器,该解码器生成轨迹提议,这些提议经过进一步的聚类和优化,最终生成由Bi-Mamba架构增强的多模态未来轨迹。
以查询为中心的上下文编码
给定向量化的参与者表示 和地图表示 ,我们首先将它们分别标记化为独立的特征集。具体来说,我们使用一个参与者编码器------一个简单的1D CNN模型------来获得参与者特征 。对于地图编码器,我们采用类似PointNet的网络来提取静态地图特征 。
然后,将得到的参与者和地图特征连接起来,形成上下文token ,并随后通过一个自注意力块来增强特征融合。
由于推理过程依赖于网格级图表示,我们引入了可学习的网格状查询 来整合场景特征,其中 和 定义了鸟瞰图(BEV)平面的空间维度。每个位于网格位置 的查询 对应现实世界中的一个特定区域,分辨率为 。然后,我们使用带有2D空间可学习相对位置编码的展平网格查询,通过交叉注意力机制来聚合上下文token。
奖励驱动的意图推理
在用上下文特征更新了网格token之后,我们首先通过我们的QIRL框架生成奖励分布,该框架在以查询为中心的范式下,调整了传统的基于网格的MaxEnt IRL算法。MaxEnt IRL通常被定义为一个有限的马尔可夫决策过程(MDP)模型,包含状态空间、动作空间和转移模型。其目标是恢复环境的奖励分布,以生成一种策略,该策略通过最大化示范数据的对数似然,同时遵循最大熵原则,来模仿专家示范。示范由离散状态序列组成,奖励通常被公式化为环境特征的组合。学习过程涉及在每次奖励迭代内进行内循环的前向RL过程,直到损失 收敛。
QIRL。 在我们的QIRL框架中,每个网格 充当一个状态,其对应的查询 表示上下文特征。我们使用1×1 CNN层的堆叠从网格token中聚合特征,以建立从驾驶上下文到奖励 的非线性映射。未来的轨迹被量化到分辨率 以形成专家示范状态,如果可用,还可以包含路径以捕捉长期信息。随后,应用MaxEnt IRL算法来推导出收敛的奖励分布以及一个最优策略。
然后基于由奖励启发式诱导的策略执行rollout。我们在网格地图上并行执行 次rollout,产生多个可能的GRTs作为意图序列,,其中 表示规划范围。为了更好地捕捉多模态未来分布,我们设置 。然后根据采样的GRT提取网格token:对于采样GRT中与网格单元状态 关联的每个位置 ,在 步中依次选择对应的网格token 。这些网格token构成了推理token 。GRT位置 及其相关的推理token 作为有价值的行为意图先验,用于指导后续的运动预测。
辅助的S-T OGM预测头。 利用网格状的密集表示,我们引入了一个辅助的S-T OGM预测头来建模参与者之间的未来交互,从而增强场景上下文特征的融合和聚合。我们将占用图以二进制形式表示,其中在未来的 个时间戳上鸟瞰图(BEV)中被占据的网格单元被设为1,未被占据的单元被设为0。我们的OGM生成器以融合后的网格token 和奖励 作为输入,并使用类似U-Net的架构生成 个未来时间戳上的OGM。
Mamba增强的轨迹解码
给定 个可能的推理先验,我们首先使用一个DETR-like的轨迹生成器生成 条轨迹作为提议。我们分别通过简单的MLP块对GRT位置 和推理token 进行编码,然后通过基于MLP的特征融合网络进行连接和处理,形成最终的推理token 。
接下来,我们引入一个anchor-free的可学习轨迹提议查询 ,使其通过交叉注意力机制关注来自意图推理器的先验特征 。然后,该提议查询通过一个由MLP块组成的回归头被解码为 个轨迹提议。我们应用K-means算法将这些提议聚类为 个多模态轨迹提议 。随后,我们使用一种基于锚点的轨迹优化方法(如许多现有的运动预测器中所用),以进一步提升轨迹查询的预测性能。每个轨迹提议作为显式的锚点先验,被重新编码为轨迹查询 ,该查询通过类似DETR的架构检索原始上下文特征,该架构与轨迹提议生成中使用的架构类似。这种分层的无锚点提议生成与基于锚点的优化过程相结合,最终得到一个轨迹查询,该查询集成了奖励驱动的意图和详细的场景上下文。
Bi-Mamba解码器。 由于轨迹token 在时间和空间域都具有显著的序列特性,我们采用一种选择性状态空间模型来捕捉轨迹查询序列内的耦合关系,这受到Mamba架构在序列建模方面近期成功的启发。具体来说,我们采用一个Bi-Mamba模型来处理轨迹token,利用其双向扫描机制来实现更全面的信息捕获。在这个由Bi-Mamba增强的解码过程中,我们预测轨迹偏移量 和每个假设的概率 。
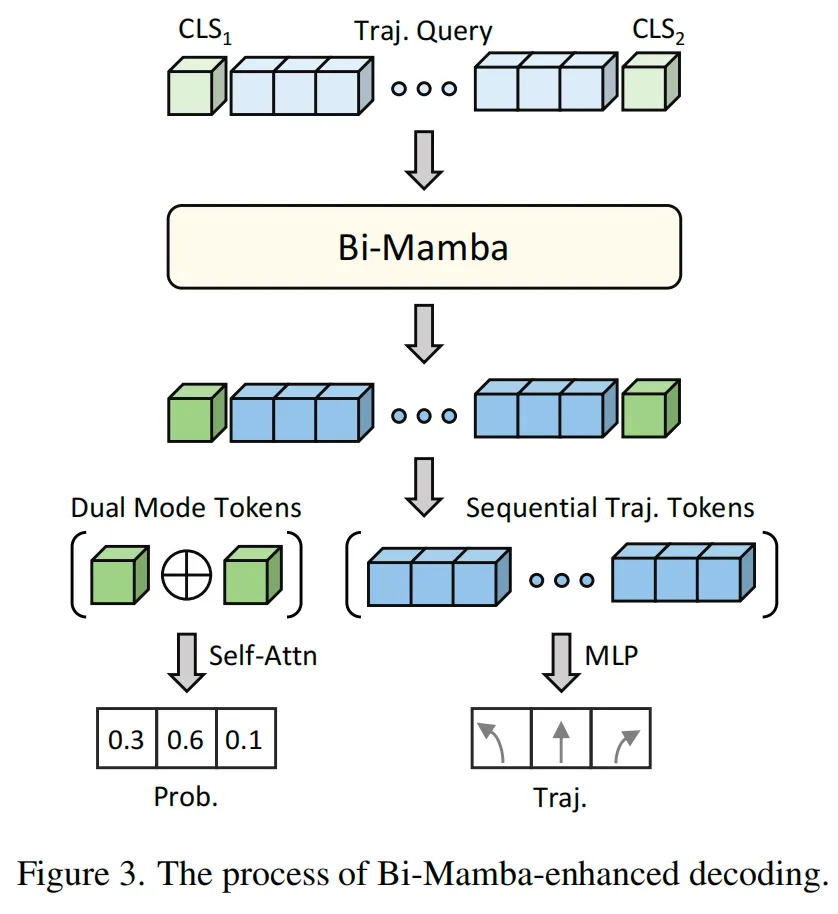
为了更好地利用Bi-Mamba结构的双向能力,我们设计了一个可学习的双模态查询 ,其中包含两个分类(CLS)token。如图3所示,这两个token(CLS1和CLS2)分别被附加在轨迹查询 的前面和后面。这两个token分别聚合了后向和前向特征,与使用单个分类token的单向Mamba相比,实现了更全面的融合,这一点在我们的消融实验结果中得到了验证(见表7)。在Bi-Mamba处理之后,两个CLS token通过逐元素相加进行特征融合。然后,一个模态自注意力模块使不同模态之间能够交互,进一步增强了预测的多模态性。最后,模态token通过softmax函数进行分类以生成概率,而序列轨迹token则通过回归头解码以生成轨迹偏移量。
最终的预测轨迹 通过将轨迹提议 与其对应的偏移量 相加得到,如下所示:
训练目标
我们的整个流程包含多个训练目标。奖励驱动的意图推理器包括两个子任务目标:QIRL和OGM生成器。QIRL目标采用 ,而OGM生成器(记为 )则使用focal BCE损失。
对于轨迹解码器,训练目标包括回归损失 和分类损失 。为了优化轨迹回归,我们对轨迹提议和优化后的轨迹都应用Huber损失。此外,为了解决模态坍塌(mode collapse)问题,我们采用了一种"胜者通吃"(winner-takes-all)策略(在类似工作中常用),其中仅选择位移误差最小的候选者进行反向传播。对于模态分类,我们采用最大间隔损失(max-margin loss),遵循的方法。
整体损失 集成了这些组件,可以进行端到端的优化:
其中 、 和 是用于平衡每个训练目标的超参数。
实验结果分析
数据集(Datasets:Argoverse 1、Argoverse 2和nuScenes。
与SOTA对比
我们在Argoverse 1、Argoverse 2和nuScenes运动预测数据集上,对我们的方法与最先进的方法进行了全面的比较。为简洁起见,我们将我们的方法简称为FiM(Foresight in Motion)。
Argoverse 1。表1展示了在Argoverse 1测试集上的定量结果。我们将我们的FiM与在此具有挑战性的基准上评估的几个代表性已发表方法进行了比较。根据单模型结果(上半部分),FiM相较于强大的基线方法(包括直接轨迹预测模型如HiVT和SceneTransformer,以及基于目标的模型如DSP和DenseTNT)都取得了极具竞争力的性能。FiM在Brier分数、brier-minFDE6和MR6方面表现尤为出色,突显了其强大的预测能力。
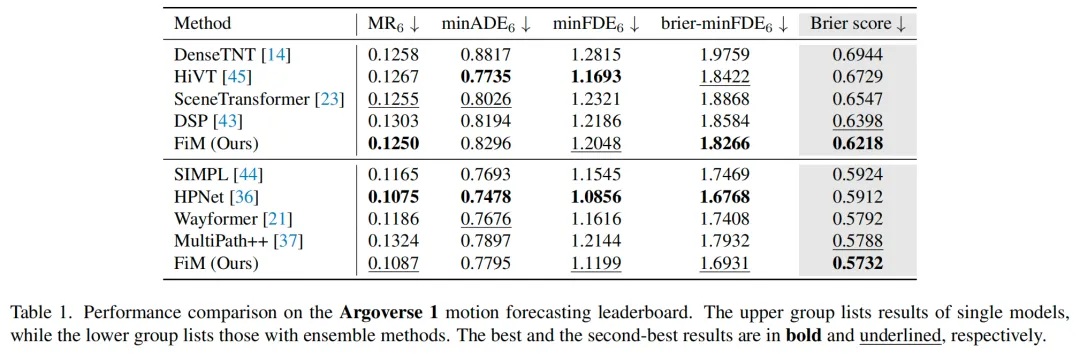
我们还应用了模型集成技术来进一步提升整体性能。集成结果(下半部分)显示出显著的性能提升,表明了我们所提出框架的巨大潜力和上限能力。与HPNet和Wayformer等其他领先的已发表方法相比,FiM在各项评估指标上均保持了有竞争力的性能,尤其是在Brier分数上表现突出。这一结果强调了我们通过推理增强的预测器能够有效地生成更可靠、更自信的预测。
Argoverse 2 。为了进一步验证我们意图推理策略的有效性,我们基于Argoverse 2的验证集构建了一个定制的评估基准。具体来说,任务要求预测前30个未来位置,而在训练期间,模型可以将后续的30个位置专门用作辅助的意图监督信号。值得注意的是,所有模型在训练轨迹生成时,其监督信号都严格限定在前30个未来位置。这种设置模拟了实际应用中长期路径可用于意图学习的场景。鉴于我们提出的QIRL模块对监督格式(无论是轨迹还是路径)是无感的,我们开发了三个模型变体,它们在GRT训练中引入了不同时间范围的未来监督。这些变体分别记为GRT-S、GRT-M和GRT-L,对应的推理模块分别使用30、45和60个未来时间戳进行训练。
我们将我们的FiM与Argoverse 2排行榜上表现最好的两个开源模型DeMo和QCNet进行了比较。如表2所示,所有FiM变体都超越了这两个强大的基线模型,证明了意图推理模块带来的显著增益。此外,结果进一步表明,更长期的意图监督能显著增强预测置信度,从而促进更可靠的轨迹预测。
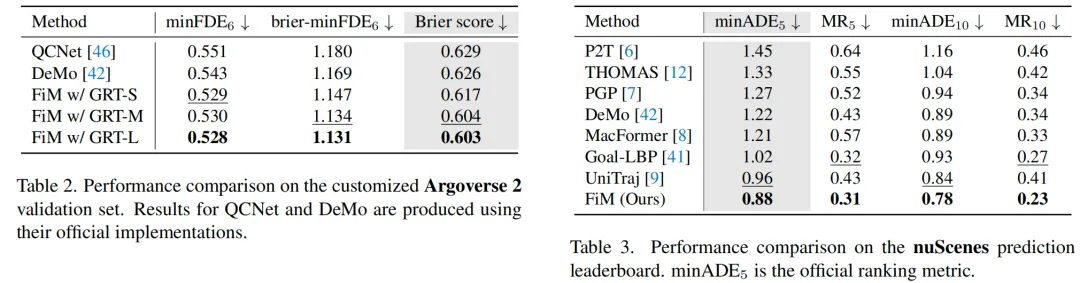
nuScenes 。我们还在nuScenes数据集上评估了FiM,结果如表3所示。我们的模型在此预测基准上表现出顶级性能,超越了排行榜上所有当前的条目,进一步验证了我们所提出框架在应对复杂运动预测挑战方面的鲁棒性和先进能力。
消融实验
我们在Argoverse验证集上进行了深入的消融研究,以评估我们方法中关键组件的有效性,所有实验设置保持一致以确保公平比较。
奖励启发式的效果(Effects of Reward Heuristics)。我们首先通过从流程中移除推理分支来检验奖励驱动意图推理器的有效性。如表4所示,与我们的完整模型相比,基础架构(Vanilla)的性能显著下降,这突显了推理过程对整体性能的关键贡献。此外,我们通过用交叉注意力块替换QIRL模块来探究其特定影响。表4的结果显示,我们的QIRL模块远优于这种替代方案,证明了QIRL能够有效收集关键的意图先验,并为后续的运动预测提供有益的指导。
OGM与优化模块的效果(Effects of the OGM & Refinement)。我们进一步通过分别消融辅助的时空占用网格图(S-T OGM)模块和优化模块来评估其影响,如表5所示。这两个模块都对最终性能做出了显著贡献。特别是,OGM带来的性能提升证实了建模未来交互能够增强预测质量,突显了意图推理对于改进轨迹预测的重要性。
Mamba解码器组件的效果(Effects of Components in Mamba-Based Decoder) 。我们对各种解码器组件进行了消融分析,以检验Mamba-like结构相对于传统方法的优势。此分析有助于确定该设计是否为轨迹解码带来了有意义的特征提取增强,还是构成了过度设计。表6的结果突显了这一设计的优势。与使用MLP作为回归和分类头相比,Bi-Mamba架构和不同模态间的自注意力机制都显著提升了预测性能和置信度。此外,我们研究了为分类提出的双模态token的效果,并将其与一个使用单个模态token来聚合轨迹查询特征的单向Mamba模型进行比较。如表7所示,Bi-Mamba模型表现更优,得益于其前向-后向扫描机制,该机制能有效地将轨迹特征融合到两个分类(CLS)token中,验证了该设计的好处。我们还考察了不同Mamba层数深度的影响,如表8所示。结果表明,更深的层数可能会引入不必要的计算开销,并且由于过拟合也可能导致性能下降,这凸显了选择最优层数配置以实现强大性能的重要性。
定性结果
我们在Argoverse验证集的多种交通场景中展示了我们所提出方法的可视化结果,如图4所示。这些定性结果强调了我们的模型在各种条件下(包括复杂路口和长距离预测场景)生成准确、可行且多模态的未来轨迹的强大能力,这些轨迹与场景布局保持了良好的对齐。
结论
在本研究中,我们从规划的视角重新构想了轨迹预测任务,并提出了一种"先推理,后预测"的策略。我们提出了一种新颖且可解释的奖励驱动意图推理器,该推理器设计于一个以查询为中心的逆强化学习(QIRL)框架之内。该框架通过以查询为中心的流程,将最大熵逆强化学习(MaxEnt IRL)范式与向量化上下文表示相结合,从而为后续的轨迹生成有效地提供了信息丰富的意图先验。
此外,我们引入了一种集成了**双向选择性状态空间模型(Bi-Mamba)**的分层DETR-like轨迹解码器。该解码器能够捕捉轨迹状态的序列依赖关系,显著提升了预测的准确性和置信度。实验结果表明,我们的推理增强型预测器具备强大的能力,能够生成与场景布局高度吻合的、自信且可靠的未来轨迹,并在性能上达到了与现有最先进模型相当甚至更优的水平。此外,我们的工作强调了意图推理在运动预测中的关键作用,证实了强化学习(RL)范式在建模驾驶行为方面的可行性,并为未来在轨迹预测领域的研究建立了一个极具前景的基线模型。