论文题目:Fast3R: Towards 3D Reconstruction of 1000+ Images in One Forward Pass(在一个向前通道中实现1000+图像的3D重建)
会议:CVPR2025
摘要:多视图3D重建仍然是计算机视觉的核心挑战,特别是在需要跨不同视角精确和可扩展表示的应用中。目前领先的方法,如DUSt3R,采用基本的成对方法,成对处理图像,需要昂贵的全局对齐程序来从多个视图重建。在这项工作中,我们提出了快速3D重建(Fast3R),这是对DUSt3R的一种新的多视图推广,通过并行处理多个视图来实现高效和可扩展的3D重建。Fast3R的基于transformer的架构在单个向前传递中转发N个图像,绕过了迭代校准的需要。通过对相机姿态估计和3D重建的大量实验,Fast3R展示了最先进的性能,在推理速度和减少误差积累方面有显着提高。这些结果使Fast3R成为多视图应用的鲁棒的替代方案,在不影响重建精度的情况下提供增强的可扩展性。
项目地址:https://fast3r-3d.github.io
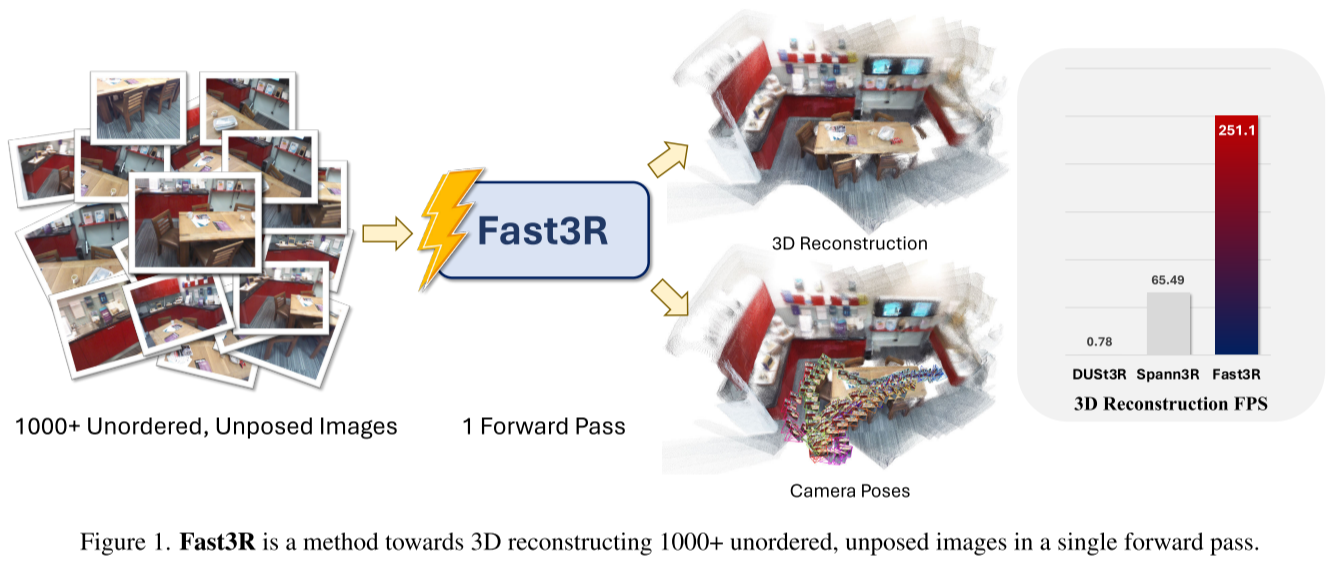
Fast3R:革命性的多视图3D重建方法
引言
多视图3D重建一直是计算机视觉的核心挑战,特别是在自动驾驶、增强现实和机器人等需要精确且可扩展表示的应用中。传统方法如Structure-from-Motion (SfM)和Multi-View Stereo (MVS)虽然有效,但需要复杂的工程设计来管理特征提取、对应匹配、三角测量和全局对齐等顺序阶段,限制了可扩展性和速度。
Meta FAIR和密歇根大学的研究团队在CVPR 2025上提出了Fast3R (Fast 3D Reconstruction),这是一种突破性的多视图3D重建方法,能够在单次前向传播中处理1000+张无序、无姿态的图像。
背景:DUSt3R的革新与局限
DUSt3R的贡献
DUSt3R最近挑战了传统"pipeline"范式,它直接从RGB图像预测3D结构,将成对重建问题转化为pointmap回归,放松了传统投影相机模型的硬约束。这代表了3D重建的根本性转变,端到端可学习的解决方案减少了pipeline错误累积,同时大幅简化了系统。
DUSt3R的根本限制
然而,DUSt3R的根本限制是只能接受两张图像输入。虽然图像对是重要的用例,但在对象扫描或场景扫描等应用中,通常需要从两个以上视图进行重建。为了处理两张以上的图像,DUSt3R需要计算O(N²)对pointmaps并执行全局对齐优化过程。
这个过程存在三大问题:
- 计算开销大:随着图像集合增长,扩展性很差,仅48个视图就会在A100 GPU上内存溢出
- 本质上仍是成对的:限制了模型的上下文,影响训练学习和推理精度
- 错误累积:顺序处理导致早期帧的错误无法修正
Fast3R:架构创新
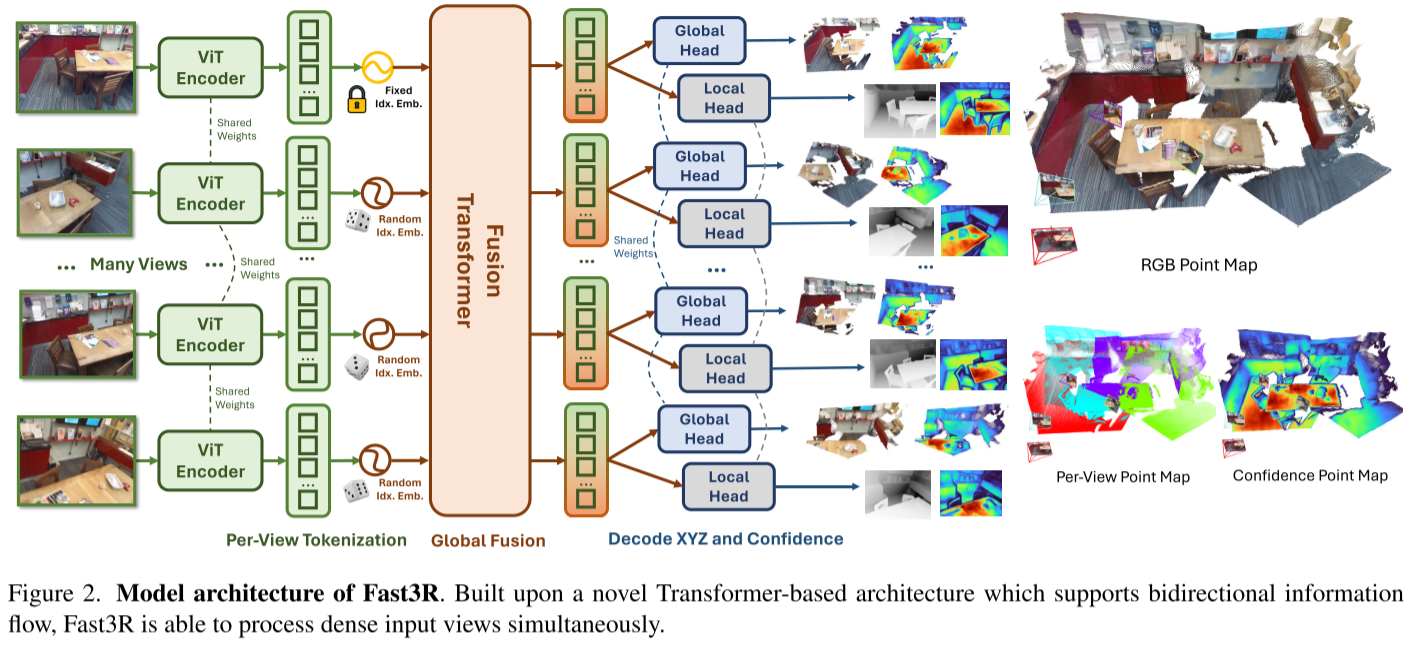

整体设计理念
Fast3R构建在DUSt3R基础上,利用基于Transformer的架构并行处理多个图像,允许N张图像在单次前向传播中重建。通过消除顺序或成对处理的需要,每一帧可以在重建过程中同时关注输入集中的所有其他帧,显著减少错误累积。
核心架构组件
Fast3R的架构包含三个主要组件:
1. 图像编码器(Image Encoder)
Fast3R使用特征提取器F独立地将每张图像Ii编码为一组patch特征Hi。采用CroCo ViT作为编码器,将图像转换为patch token序列。
关键创新:图像索引位置编码
在将patch特征传递给fusion transformer之前,添加一维图像索引位置编码。这些索引嵌入帮助fusion transformer确定哪些patches来自同一图像,是识别定义全局坐标系的I₁的机制。
2. Fusion Transformer
这是Fast3R计算量最大的部分。使用24层的类似ViT-L的transformer,它接收所有视图的拼接编码图像patches并执行all-to-all自注意力。
All-to-All注意力的优势:
- 提供来自所有视图的完整上下文
- 超越仅成对信息
- 允许模型同时和联合推理所有帧
- 无图像顺序假设
3. Pointmap解码头
Fast3R使用两个独立的DPT解码头将tokens映射到:
- 局部和全局pointmaps(XL, XG)
- 置信度图(ΣL, ΣG)
位置插值:突破视图数量限制
这是Fast3R最巧妙的设计之一。
问题:如何让模型在推理时处理比训练时更多的视图?
解决方案:采用来自大语言模型的Position Interpolation技术
训练时从更大的池子N'中随机抽取N个索引。对于transformer来说,这种策略看起来与遮蔽图像无异,N'/N控制遮蔽比率。这种策略使Fast3R能够在推理时处理N=1000张图像,即使仅用N=20张图像训练。
具体实现:
- 训练阶段:使用N'=1000的池子,随机抽取N=20个视图
- 推理阶段:可以处理最多1000张图像
- 第一张图像I₁的patches始终用p₁嵌入,因为它定义了全局头的坐标系
训练策略
损失函数
Fast3R使用DUSt3R的pointmap损失的广义版本:
L_total = L_XG + L_XL每个pointmap损失是置信度加权的归一化3D逐点回归损失:
L_X(Σ̂, X̂, X) = 1/|X| Σ(Σ̂_+ · ℓ_regr(X̂, X) + α log(Σ̂_+))
设计理由:
- 置信度加权帮助模型处理标签噪声
- 真实世界扫描通常包含系统性错误(如玻璃或薄结构)
- 相机配准错误会导致图像和pointmap标签之间的不对齐
训练细节
模型在512分辨率图像上训练,使用AdamW优化器,174K步,学习率0.0001,余弦退火调度。批量大小128,每个样本包含N=20个视图的元组,在128个Nvidia A100-80GB GPU上训练6.13天。
工程优化:
- FlashAttention提升时间和内存效率
- DeepSpeed ZeRO stage 2:将优化器状态、momentum估计和梯度分区到不同机器
- 最多可训练N=28个视图(批量大小为1)
高效推理实现
内存瓶颈分析
推理时的内存瓶颈在于生成pointmaps的DPT头:320个视图在单个A100 GPU上,超过60%的VRAM被DPT头的激活消耗,主要是因为每个头需要将1024个tokens上采样到高分辨率512×512图像。
Tensor Parallelism解决方案
实现简单的tensor parallelism版本:
- 将模型放在GPU 0
- 将DPT头复制到K-1个其他GPU
- 处理N≈1000张图像时:
- 整个批次通过ViT encoder和global fusion decoder
- 输出分割到K台机器进行并行DPT头推理
性能数据
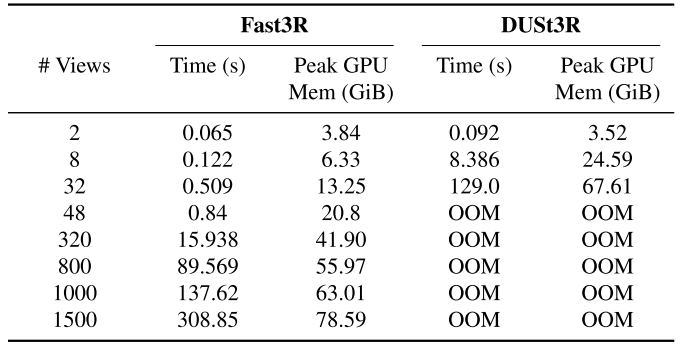
实验结果
相机姿态估计
在CO3Dv2数据集的41个物体类别上评估:
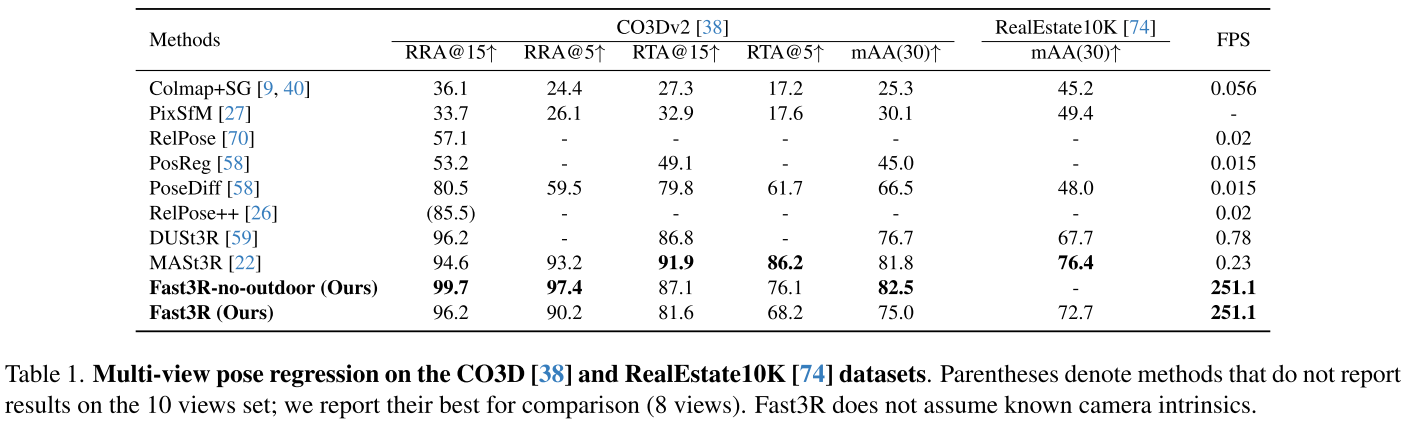
| 方法 | RRA@15° | RRA@5° | RTA@15° | RTA@5° | FPS |
|---|---|---|---|---|---|
| DUSt3R | 96.2 | - | 86.8 | - | 0.78 |
| MASt3R | 94.6 | 93.2 | 91.9 | 86.2 | 0.23 |
| Fast3R | 99.7 | 97.4 | 87.1 | 76.1 | 251.1 |
关键发现:
- Fast3R在CO3D上超越所有其他方法,实现接近完美的RRA,同时在RTA上保持竞争力。重要的是,它快了几个数量级:比DUSt3R快320倍,比MASt3R快1000倍
- 随着视图增加,性能持续提升
- 在3-5个视图时就饱和了方向估计基准
3D重建
在场景级和物体级基准上评估:
7-Scenes和Neural RGB-D(场景级):
| 方法 | FPS | 7-Scenes Acc↓ | 7-Scenes Comp↓ | NRGBD Acc↓ | NRGBD Comp↓ |
|---|---|---|---|---|---|
| DUSt3R | 0.78 | 1.23 | 0.91 | 2.51 | 1.03 |
| Spann3R | 65.4 | 1.48 | 0.85 | 3.15 | 1.10 |
| Fast3R | 251.1 | 1.58 | 0.93 | 3.40 | 1.01 |
DTU(物体级):
使用skip=5处理49帧的轨迹,Fast3R的精度为1.706,完整度为0.857,与DUSt3R竞争并在某些指标上更优。
消融研究
1. 视图数量缩放
训练阶段:在越来越多的视图上训练持续提高视觉里程计的RRA和RTA以及重建精度------即使评估时使用的视图数量保持恒定,模型最终评估的视图少于训练时看到的。
推理阶段:随着模型使用更多视图,平均每视图性能提高。模型使用50张图像时的每视图精度优于20张,即使它是用20张训练的。
2. 局部vs全局Pointmap
实验表明:
- 局部head产生更精确的pointmaps(更少的浮点、更少的拖尾、更少的扭曲)
- 全局head用于高级结构
- 最佳策略:使用ICP将局部pointmaps对齐到全局pointmap
原因分析:
- 局部head更具不变性:像素的3D XYZ位置不随锚点视图I₁选择而变化
- 全局head需要学习2D到3D几何和3D点的刚性变换
3. 位置插值的必要性
不使用位置插值技术,当测试视图数超过训练范围时,对应于图像索引的pointmap精度迅速下降。使用该技术,即使训练N=4个视图的Fast3R版本,仍能为slot 5到24的视图产生高质量pointmaps。
技术优势总结
1. 性能优势
- 速度:251 FPS,比DUSt3R快320倍
- 可扩展性:单次处理1500张图像
- 精度:相机姿态估计RRA@15°达99.7%
2. 架构优势
- 并行处理:消除顺序依赖
- 全局上下文:all-to-all attention
- 灵活性:训练20视图,推理1000+视图
3. 工程优势
- 内存高效:FlashAttention、ZeRO优化
- 易于扩展:支持模型并行和数据并行
- 持续改进:受益于Transformer基础设施的成熟
局限性与未来方向
当前限制
当前的限制因素可能是数据精度和数量。当重建区域非常大时,视图数量变得极端(如超过300张),某些视图(特别是置信度分数低的视图)的point map开始表现出漂移行为。
解决方案
- 短期:删除置信度分数低的帧
- 长期研究方向 :
- 纳入更多大场景数据提高泛化能力
- 设计更好的位置编码(借鉴长上下文语言模型)
- 利用有序图像序列的时间结构
数据扩展潜力
合成数据可能是解决方案,因为广义来说,为几何估计训练的模型似乎能很好地从模拟数据泛化。Fast3R可以成功使用模拟数据进行4D重建训练,在DAVIS上显示泛化结果。
结论
Fast3R代表了多视图3D重建领域的重大进步。通过将整个SfM pipeline替换为端到端训练的通用Transformer架构,Fast3R应该能从通常的transformer缩放规则中受益:通过更好的数据和增加的参数持续改进。
核心贡献:
- 架构创新:首个真正多视图的pointmap估计Transformer模型
- 性能突破:速度和可扩展性的巨大提升
- 实证验证:沿视图轴缩放提升模型性能
- 工程实践:展示如何高效实现大规模多视图重建
Fast3R为真实世界应用提供了可扩展且精确的替代方案,为高效多视图3D重建树立了新标准。随着Transformer基础设施的持续成熟和合成数据的应用,Fast3R有望继续改进,推动3D视觉领域的发展。