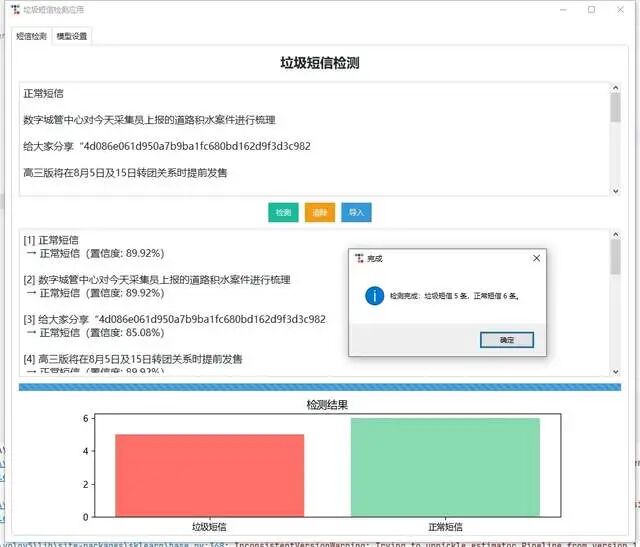
项目概述
随着移动通信的普及,垃圾短信已成为影响用户日常生活和信息安全的重要问题。本项目旨在开发一款高效、准确的智能垃圾短信检测系统,利用机器学习技术自动识别和过滤垃圾短信,保护用户的隐私和安全。
系统架构
本垃圾短信检测系统基于 Python 语言开发,主要依赖 `scikit-learn` 机器学习库,结合文本处理和模型训练技术,实现垃圾短信的自动分类与识别。
核心功能模块
数据加载与预处理
本文项目使用的是飞浆平台提供的公开数据集,数据集中包含70万条数据,该数据数据集已经被分词处理好,采用的是jieba分词工具。数据集中每条字段包含三个字段message, msg_new, label, 其中message表示短信的内容,msg_new表示短信分词后的结果,label表示短信的类别,其中0表示正常短信,1表示垃圾短信。

数据加载与预处理是系统的基础步骤,主要包括以下功能:
-
停用词加载:通过 `read_stopwords` 函数加载自定义中文停用词表,过滤无意义的常用词,提升模型准确率。
-
文本向量化:支持两种向量化方式:
-
CountVectorizer:将文本转换为词频矩阵。
-
TfidfVectorizer:将文本转换为 TF-IDF 特征矩阵,适用于不同文本处理需求。

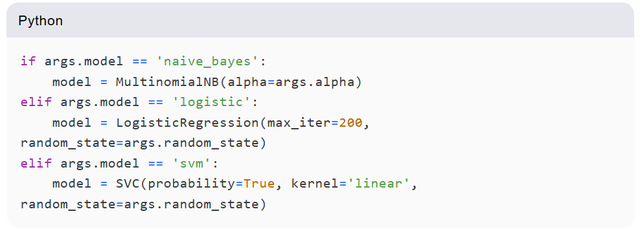
模型选择与训练
系统提供了三种经典的机器学习模型供用户选择:
-
朴素贝叶斯 (MultinomialNB)
-
逻辑回归 (Logistic Regression)
-
支持向量机 (SVM)
用户可以通过命令行参数灵活切换模型,并自定义超参数(如 `alpha`、`ngram`)。模型训练通过 `Pipeline` 实现:
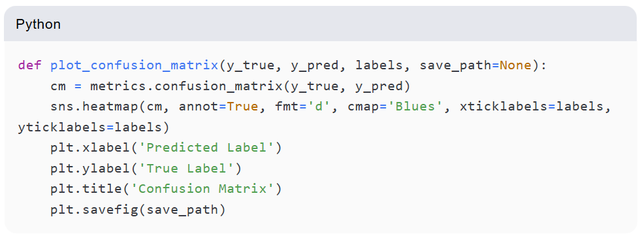
模型评估与可视化
训练完成后,系统自动评估模型性能,并通过混淆矩阵进行可视化展示:
模型保存与批量预测
完成训练后,系统自动保存模型,便于后续快速调用进行批量短信检测:

系统优势
-
高效准确:使用经典机器学习算法搭配优化的超参数,提供高效且准确的垃圾短信检测能力。
-
灵活可配置:支持多种模型与文本向量化方式,用户可自由调整超参数以适应不同数据集。
-
可视化支持:自动生成混淆矩阵与性能报告,帮助用户直观理解模型表现。
-
批量检测:保存模型后可直接用于批量检测,适用于企业短信网关或反欺诈系统。
-
易用性强:命令行友好,仅需一行命令即可完成训练与预测。
应用场景
-
短信防骚扰服务:集成到手机或运营商平台,自动过滤垃圾短信。
-
企业内部邮件过滤:可用于邮件服务器端的恶意邮件检测。
-
智能客服系统:在客户服务系统中识别潜在的恶意消息。
使用方法
安装依赖

训练模型

预测测试

模型保存与加载
训练完成后,模型会自动保存为 `sms_spam_pipeline.pkl`,方便后续直接加载进行预测。
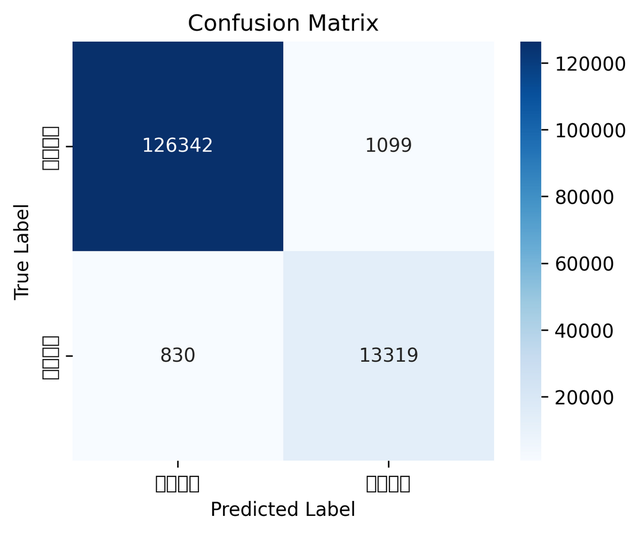
效果展示
在测试集上的混淆矩阵:
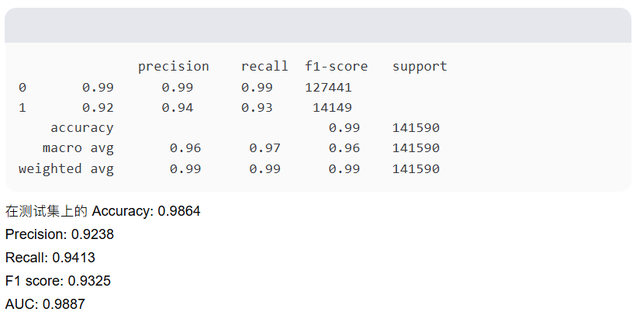
在测试集上的分类结果报告:
日志记录与错误处理
系统自动记录训练过程,包括模型选择、超参数、测试结果等。发生异常时自动记录错误日志,方便后续排查问题。
总结
本智能垃圾短信检测系统基于机器学习技术,具备高效准确的检测能力、灵活的配置选项和直观的可视化分析。通过简单的命令行操作,用户可以快速完成模型训练、评估和预测,适用于多种应用场景,有效帮助用户抵御垃圾短信的骚扰。

总结
机器学习课程设计报告

