0、 背景
在工业自动化控制领域,预测某些变量是否关键。根据工厂的数据,训练好模型之后,将其转我通用的onnx 模型,并实现高效的推理。
模型训练
python
import numpy as np
from para import *
from data_utils import MyDataset
from data_utils import MyLoss
from torch import nn
import torch
import torch.optim as optim
from torch.utils.data import DataLoader
from lstm_src_get_data import load_data
device = 'cpu'
num_epochs = g_num_epochs
mod_dir = './'
delay =g_delay
class RegLSTM(nn.Module):
def __init__(self, inp_dim, out_dim, mid_dim, mid_layers):
super(RegLSTM, self).__init__()
self.rnn = nn.LSTM(inp_dim, mid_dim, mid_layers) # rnn
self.reg = nn.Sequential(
nn.Linear(mid_dim, mid_dim),
nn.Tanh(),
nn.Linear(mid_dim, out_dim),
) # regression
def forward(self, x):
y = self.rnn(x)[0] # y, (h, c) = self.rnn(x)
seq_len, batch_size, hid_dim = y.shape
y = y.view(-1, hid_dim)
y = self.reg(y)
y = y.view(seq_len, batch_size, -1)
return y
# print(g_delay)
model = RegLSTM(g_input_dim, g_output_dim, 100, 1).to(device)
if g_is_load_model:
model.load_state_dict(torch.load(g_Model_PATH))
criterion =MyLoss() # 均方误差损失,用于回归问题
optimizer = optim.Adam(model.parameters(), lr=g_learning_rate)
data_len = g_train_size+g_seq_len+g_delay*2
data = load_data(0, data_len, 1)
delay =g_delay
data_y_plt = data[delay:-(g_delay+g_seq_num),-1]
train_xs = None
train_ys = None
for i in range(0,g_seq_len*g_seq_num,1):
begin_x = i
begin_y = i + delay
end_x = i + g_seq_len
end_y = i + g_seq_len+delay
data_x = data[begin_x:end_x, :] # delay
data_y = data[begin_y:end_y, -1]
# print('data_y\n', data_y)
train_size = len(data_x)
train_x = data_x.reshape(-1, g_seq_len,g_input_dim)
train_y = data_y.reshape(-1, g_seq_len,g_output_dim)
# train_y = np.squeeze(train_y)
if train_xs is None:
train_xs = train_x
train_ys = train_y
else:
train_xs = np.concatenate((train_xs, train_x), axis=0)
train_ys = np.concatenate((train_ys, train_y), axis=0)
dataset = MyDataset(train_xs, train_ys)
# 把 dataset 放入 DataLoader
BATCH_SIZE = g_BATCH_SIZE
dataloader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)
for epoch in range(num_epochs):
loss = None
for batch_idx, (inputs, labels) in enumerate(dataloader):
outputs = model(inputs)
loss = criterion(outputs, labels.to(device))
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 更新参数
if (epoch + 1) % 2 == 0:
print(f'epoch [{epoch + 1}], Loss: {loss.item():.6f}')
torch.save(model.state_dict(), '{}/{}'.format(mod_dir,g_Model_PATH_s))
print("Save in:", '{}/{}'.format(mod_dir,g_Model_PATH_s))2、模型导出
python
from torch import nn
import torch
from para import *
from models import RegLSTM
# 一个单词向量长度为10,隐藏层节点数为40,LSTM有1层
model = RegLSTM(g_input_dim, g_output_dim, 100, 1).to(g_device)
model.load_state_dict(torch.load(g_Model_PATH, map_location=g_device,weights_only=True))
# 2个句子组成,每个句子由5个单词,单词向量长度为10
input_data = torch.randn(2, 3, g_input_dim)
# 1-> LSTM层数*方向 2->batch 40-> 隐藏层节点数
input_names = ["input"]
output_names = ["output"]
save_onnx_path= "./lstm_2_3.onnx"
torch.onnx.export(
model,
input_data,
save_onnx_path,
verbose=True,
input_names=input_names,
output_names=output_names,
opset_version=12
)3 onnx 与 .pt 模型精度比较
模型转换为onnx 之后,可能存在精度损失,我们简单测试比较一下onnx 与 .pt 模型的精度。
3.1 .pt 模型运行结果
测试代码
python
# .pt 模型运行结果
import os, sys
import torch
import numpy as np
sys.path.append(os.getcwd())
import onnxruntime
from para import *
from PIL import Image
from models import RegLSTM
def to_numpy(tensor):
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
# 推理的图片路径
a = np.arange(48).reshape(2, 3, 8)
print(a)
input_data = torch.tensor(a)
input_data=input_data.float()
model = RegLSTM(g_input_dim, g_output_dim, 100, 1).to(g_device)
model.load_state_dict(torch.load(g_Model_PATH, map_location=g_device,weights_only=True))
outputs = model(input_data)
print(outputs).pt 模型输出
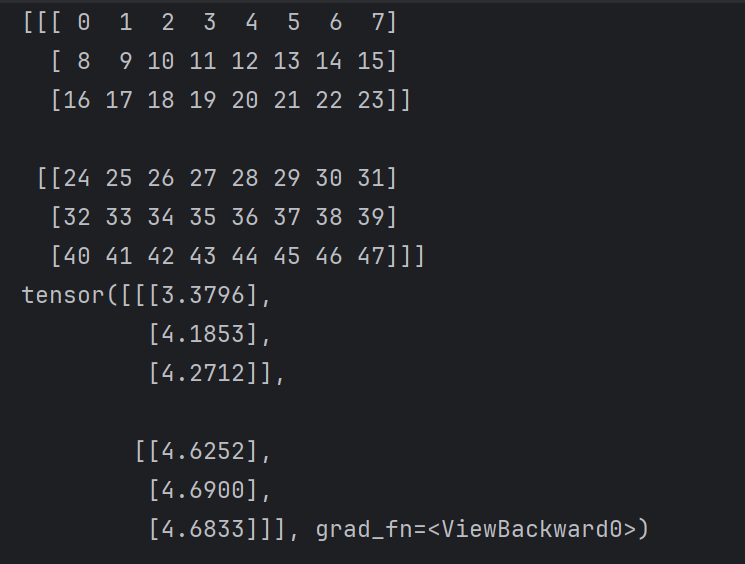
3.2 .onnx模型运行结果
测试代码
python
# onnx 模型运行结果
import os, sys
import torch
import numpy as np
sys.path.append(os.getcwd())
import onnxruntime
from para import *
from PIL import Image
def to_numpy(tensor):
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
# 推理的图片路径
a = np.arange(48).reshape(2, 3, 8)
print(a)
input_data = torch.tensor(a)
input_data=input_data.float()
# 模型加载
onnx_model_path = "lstm_5_8.onnx"
resnet_session = onnxruntime.InferenceSession(onnx_model_path)
inputs = {resnet_session.get_inputs()[0].name: to_numpy(input_data)}
outs = resnet_session.run(None, inputs)[0]
print(outs)onnx 模型输出
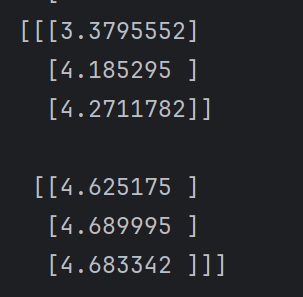
3.3.C++ 版本 onnx模型运行结果
测试代码
cpp
#include <iostream>
#include <iomanip>
using namespace std;
//#include <cuda_provider_factory.h>
#include <onnxruntime_cxx_api.h>
using namespace std;
using namespace Ort;
const int batch_size = 2;
const int input_size = 8;
const int seq_len = 3;
const int output_size = 1;
std::vector<float> testOnnxLSTM(std::vector<std::vector<std::vector<float>>>& inputs)
{
//设置为VERBOSE,方便控制台输出时看到是使用了cpu还是gpu执行
//Ort::Env env(ORT_LOGGING_LEVEL_VERBOSE, "test");
Ort::Env env(ORT_LOGGING_LEVEL_WARNING, "Default");
Ort::SessionOptions session_options;
session_options.SetIntraOpNumThreads(1); // 使用五个线程执行op,提升速度
// 第二个参数代表GPU device_id = 0,注释这行就是cpu执行
//OrtSessionOptionsAppendExecutionProvider_CUDA(session_options, 0);
session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL);
auto memory_info = Ort::MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeCPU);
// const char* model_path = "../lstm.onnx";
auto model_path = L"./lstm_2_3.onnx";
//std::cout << model_path << std::endl;
Ort::Session session(env, model_path, session_options);
const char* input_names[] = { "input" }; // 根据上节输入接口名称设置
const char* output_names[] = { "output" }; // 根据上节输出接口名称设置
std::array<float, batch_size* seq_len* input_size> input_matrix;
std::array<float, batch_size* seq_len* output_size> output_matrix;
std::array<int64_t, 3> input_shape{ batch_size, seq_len, input_size };
std::array<int64_t, 3> output_shape{ batch_size,seq_len, output_size };
for (int i = 0; i < batch_size; i++)
for (int j = 0; j < seq_len; j++)
for (int k = 0; k < input_size; k++)
input_matrix[i * seq_len * input_size + j * input_size + k] = inputs[i][j][k];
Ort::Value input_tensor = Ort::Value::CreateTensor<float>(memory_info, input_matrix.data(), input_matrix.size(), input_shape.data(), input_shape.size());
try
{
Ort::Value output_tensor = Ort::Value::CreateTensor<float>(memory_info, output_matrix.data(), output_matrix.size(), output_shape.data(), output_shape.size());
session.Run(Ort::RunOptions{ nullptr }, input_names, &input_tensor, 1, output_names, &output_tensor, 1);
}
catch (const std::exception& e)
{
std::cout << e.what() << std::endl;
}
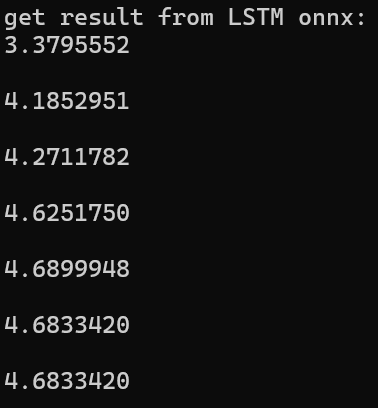
std::cout << "get result from LSTM onnx: \n";
std::vector<float> ret;
for (int i = 0; i < batch_size * seq_len * output_size; i++) {
ret.emplace_back(output_matrix[i]);
cout << setiosflags(ios::fixed) << setprecision(7) << output_matrix[i] << endl;
std::cout << "\n";
}
cout << setiosflags(ios::fixed) << setprecision(7) << ret.back()<< endl;
std::cout << "\n";
return ret;
}
int main()
{
std::vector<std::vector<std::vector<float>>> data;
int value = 0;
for (int i = 0; i < batch_size; i++) {
std::vector<std::vector<float>> t1;
for (int j = 0; j < seq_len; j++) {
std::vector<float> t2;
for (int k = 0; k < input_size; k++) {
t2.push_back(value++);
}
t1.push_back(t2);
t2.clear();
}
data.push_back(t1);
t1.clear();
}
std::cout << "data shape{batch ,seq dim}";
std::cout << data.size() << " " << data[0].size() << " " << data[0][0].size() << std::endl;
std::cout << "data" << std::endl;
for (auto& i : data) {
for (auto& j : i) {
for (auto& k : j) {
std::cout << k << "\t";
}
std::cout << "\n";
}
std::cout << "\n";
}
auto ret = testOnnxLSTM(data);
return 0;
}
4、结果比较
输入
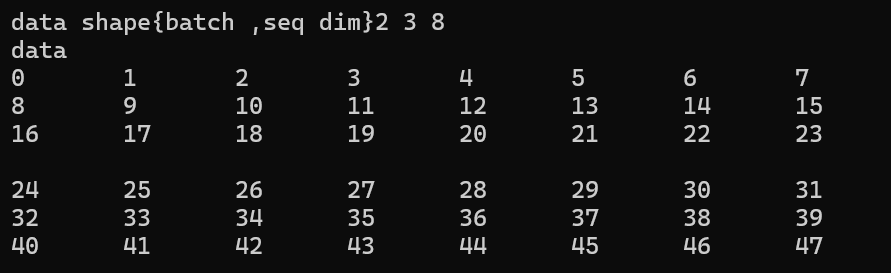
输出

可以看出 误差约为百万分之一