导语
在程序性能的微观世界里,每一次函数调用都是一次精心编排的操作。当我们在追求极致性能时,不禁要问:一次函数调用的真实耗时究竟是多少?不同实现方式带来的性能差异有多大?这些差异背后隐藏着怎样的底层秘密?本文将通过四类场景的对比测试,从纳秒级时延追踪到汇编指令,为您揭开函数调用的性能真相。 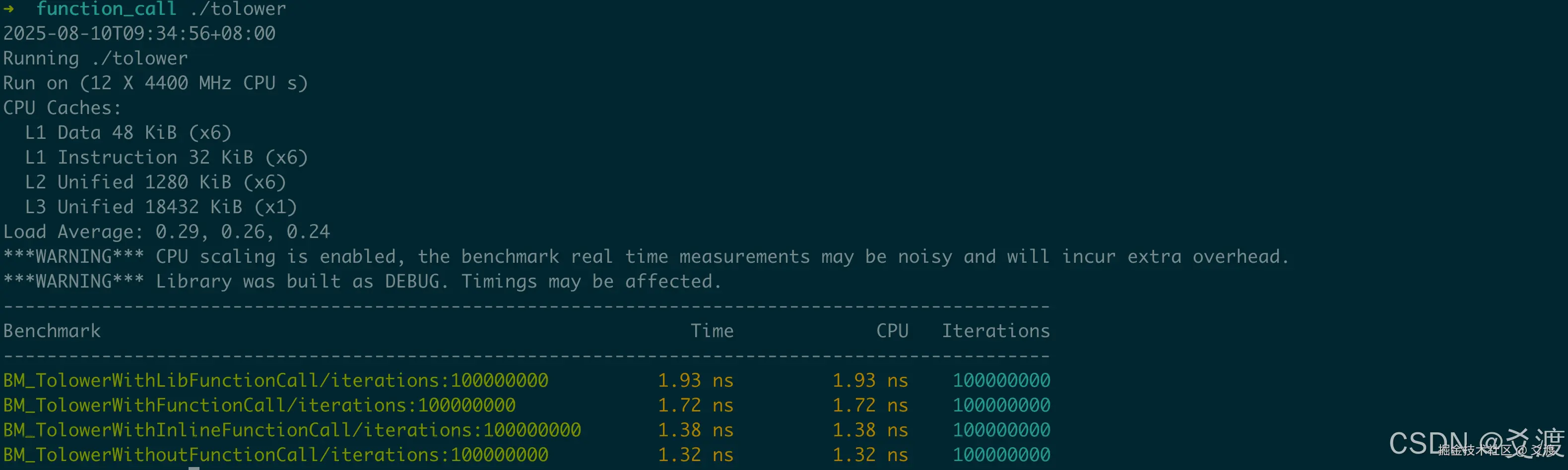
四类函数调用的耗时对比
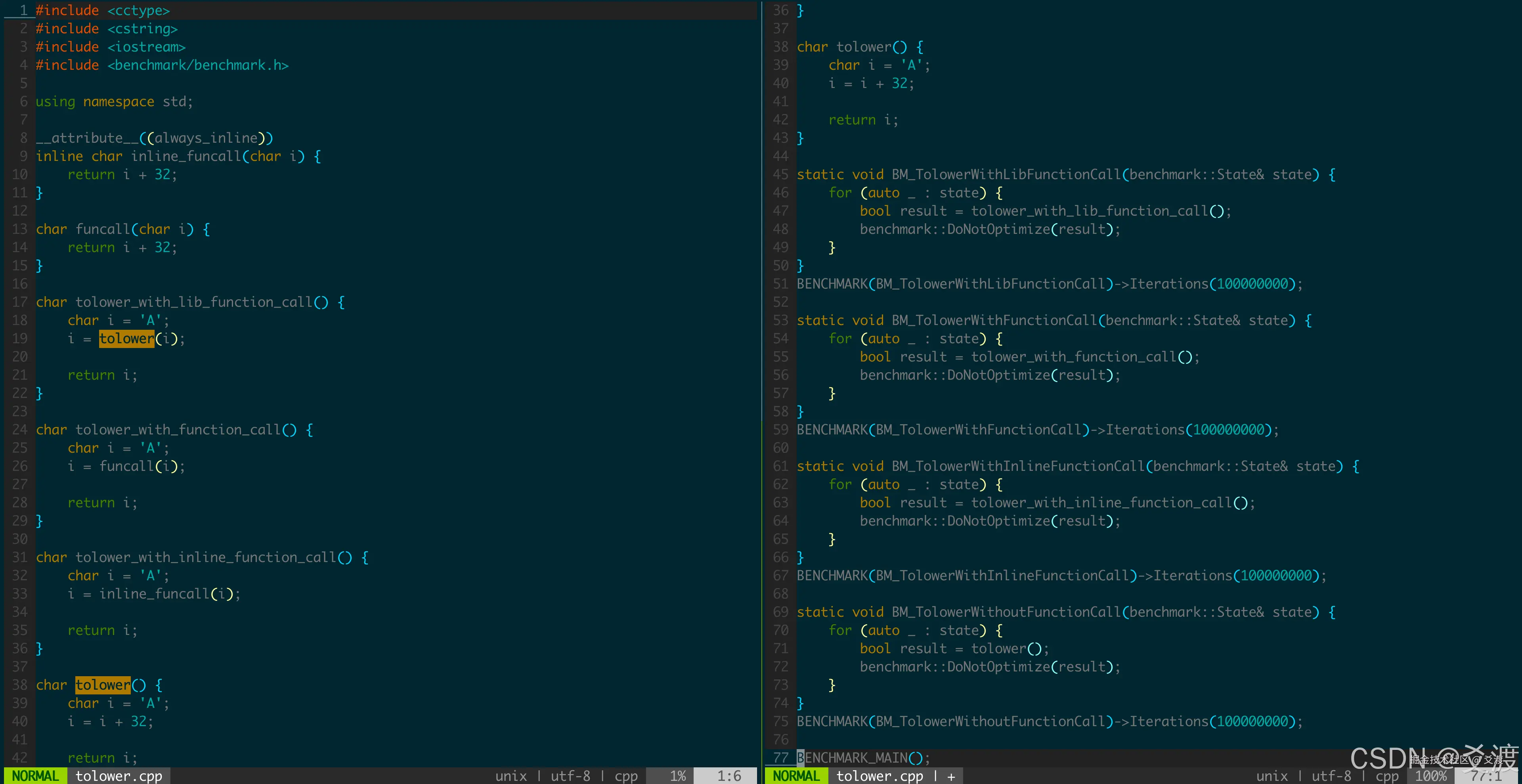 分别以不同方式实现
分别以不同方式实现tolower(),通过10000万次迭代基准测试,统计结果:
| 实现方式 | 平均耗时 | 指令数 | 时延增加 | 指令数增加 |
|---|---|---|---|---|
无函数调用(base) |
1.32 ns | 3,406,382,600 | - | - |
| 内联函数调用 | 1.38 ns | 3,606,421,074 | 0.06 ns | (3,606,421,074 - 3,406,382,600) / 100000000 = 2 |
| 自实现函数调用 | 1.72 ns | 4,406,514,894 | 0.4 ns | (4,406,514,894 - 3,406,382,600) / 100000000 = 10 |
| 标准库函数调用 | 1.93 ns | 4,706,627,542 | 0.61 ns | (4,706,627,542 - 3,406,382,600) / 100000000 = 13 |
关键发现:
- 函数调用必然引入开销:即便是最高效的内联调用,也比无调用多出0.06 ns(相当于4.5%性能损失)
- 不同函数调用存在性能差异:内联(+0.06 ns) < 自定义(+0.4 ns) < 标准库(+0.61 ns)
- 性能差异诱因是指令数增长:内联(+2) < 自定义(+10) < 标准库(+13)
耗时增加的底层溯源:以内联函数调用为例
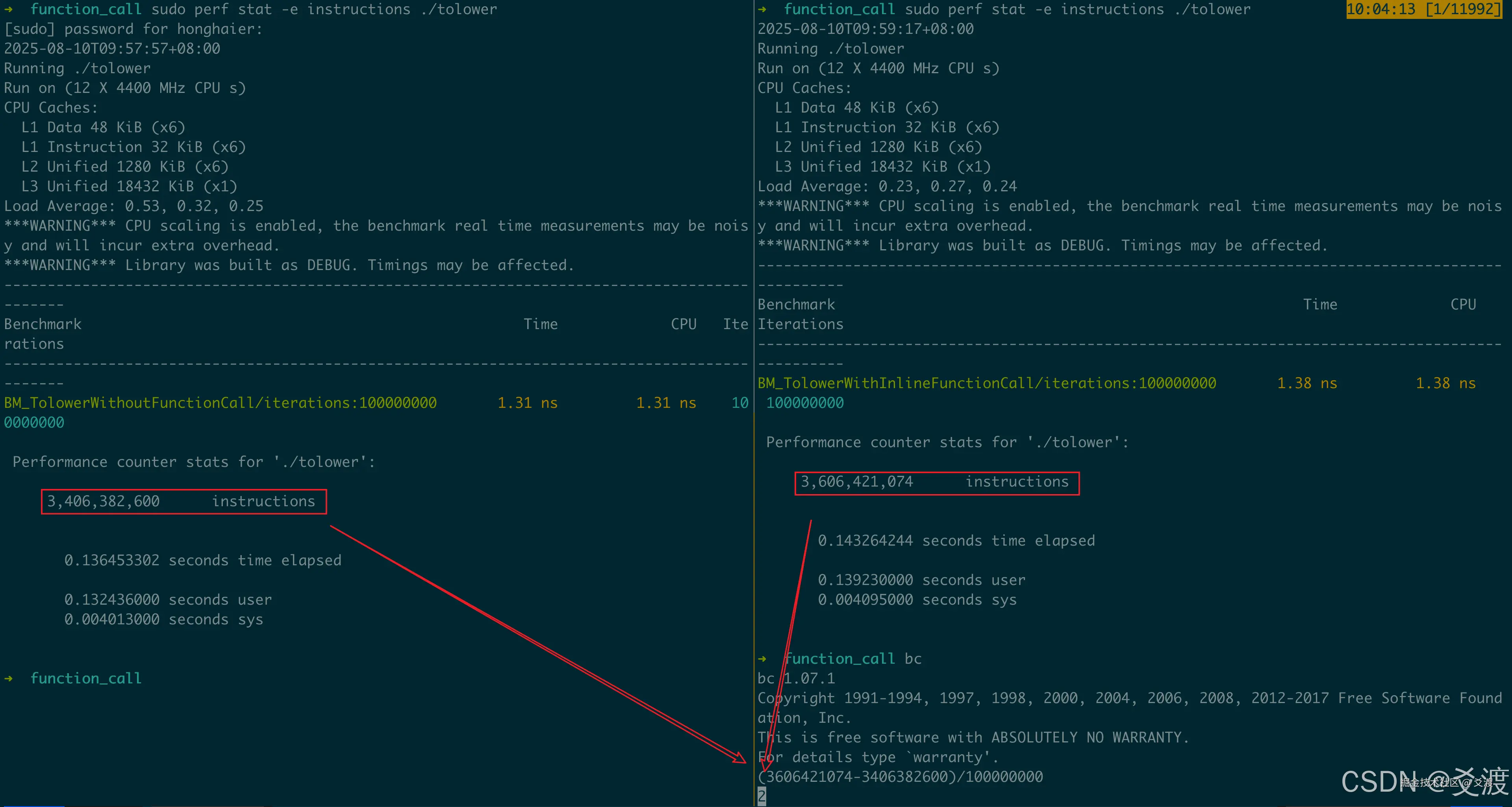
通过 perf stat 统计可见:无函数调用执行指令数:3,406,382,600,内联函数调用执行指令数:3,606,421,074,差值计算可得:(3,606,421,074 - 3,406,382,600) / 100000000 = 2条指令/次,发现关键结论:每次内联调用需额外执行2条指令。那么:具体是哪2条指令呢?
追踪汇编实现
为了找到内联函数实现额外执行的是哪2条指令,查看并对比反汇编代码
-
无函数调用实现
assembly00000000000012aa <_Z7tolowerv>: 12aa: 55 push %rbp 12ab: 48 89 e5 mov %rsp,%rbp 12ae: c6 45 ff 41 movb $0x41,-0x1(%rbp) 12b2: 0f b6 45 ff movzbl -0x1(%rbp),%eax 12b6: 83 c0 20 add $0x20,%eax 12b9: 88 45 ff mov %al,-0x1(%rbp) 12bc: 0f b6 45 ff movzbl -0x1(%rbp),%eax 12c0: 5d pop %rbp 12c1: c3 ret -
内联调用实现
assembly000000000000128b <_Z33tolower_with_inline_function_callv>: 128b: 55 push %rbp 128c: 48 89 e5 mov %rsp,%rbp 128f: c6 45 ff 41 movb $0x41,-0x1(%rbp) 1293: 0f be 45 ff movsbl -0x1(%rbp),%eax 1297: 88 45 fe mov %al,-0x2(%rbp) ; 额外指令1 129a: 0f b6 45 fe movzbl -0x2(%rbp),%eax ; 额外指令2 129e: 83 c0 20 add $0x20,%eax 12a1: 88 45 ff mov %al,-0x1(%rbp) 12a4: 0f b6 45 ff movzbl -0x1(%rbp),%eax 12a8: 5d pop %rbp 12a9: c3 ret
真相大白
内联函数虽避免了调用跳转,但仍需在栈帧中传递中间值,增加了2次内存操作,从而导致耗时增加。
同理可以发现,自实现函数调用需额外执行10条指令: 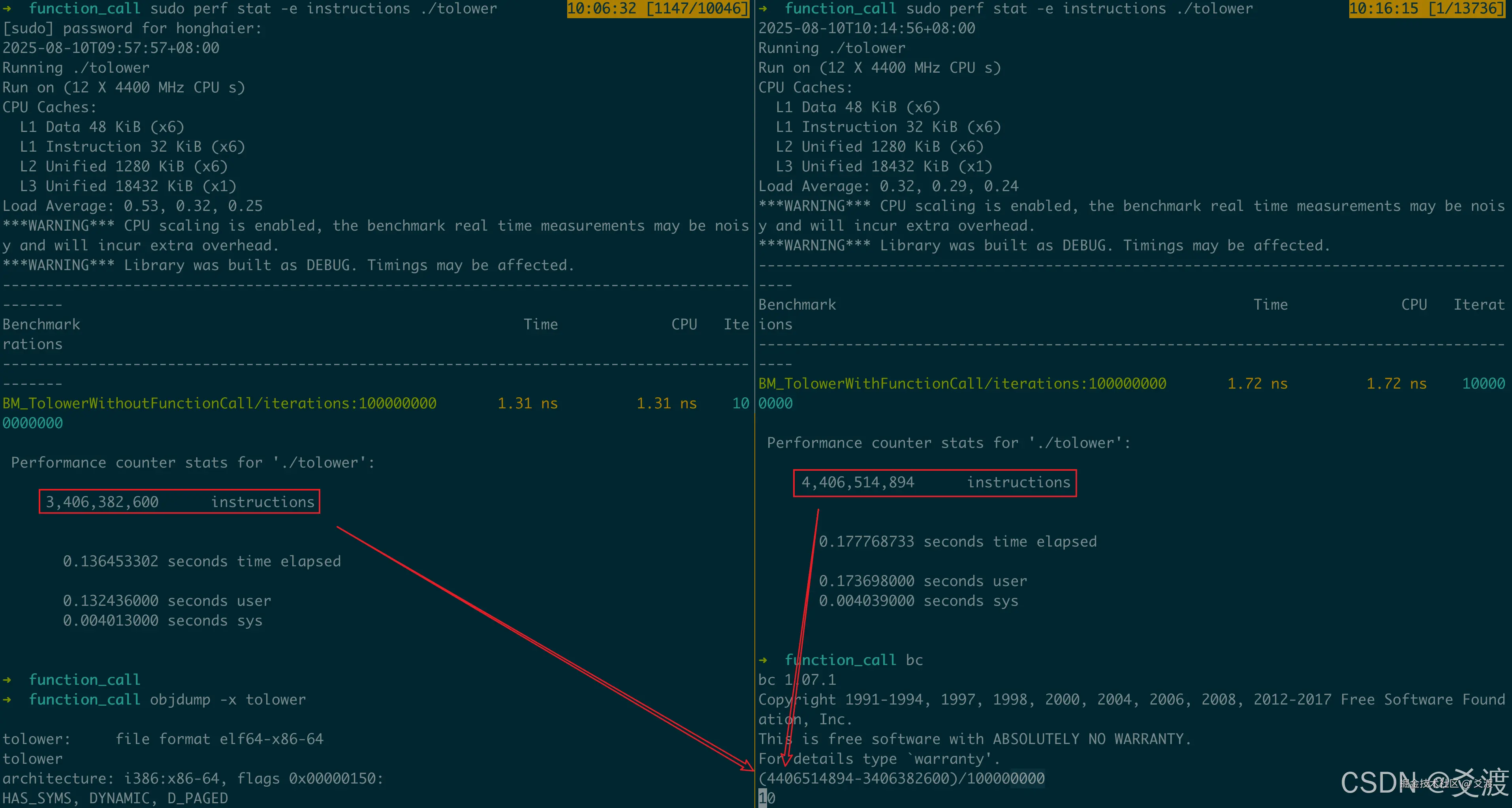 而标准库函数调用则需额外执行13条指令:
而标准库函数调用则需额外执行13条指令: 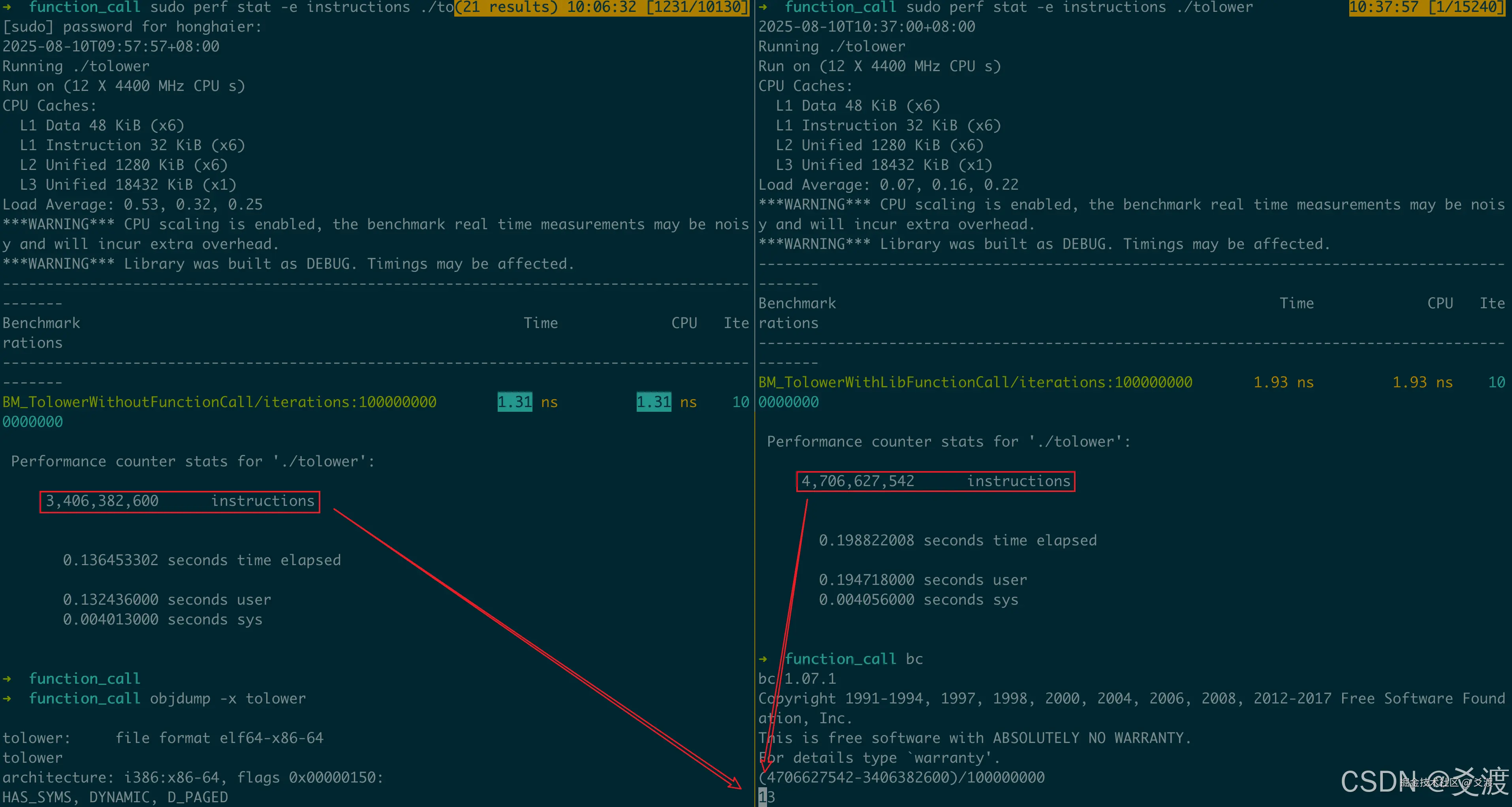
函数调用额外开销来源
- 额外的操作指令(如内联实现)
- 函数调用的栈帧构建
- 动态链接开销:PLT跳转表查询
- 安全与健壮性检查的代价:类型验证、边界检查、空指针检查......
后记:微观时延的宏观意义
一次仅0.4纳秒的函数调用差异看似微不足道,但在每秒处理百亿请求的系统中,这种差异将放大为数秒级延迟。这提醒我们,性能优化有时需从指令级视角切入,在安全与效率间寻找平衡:
- 当选择标准库时,我们选择安全与兼容
- 当选择内联时,我们选择效率与可控
- 当消除调用时,我们选择极致与风险
最终,这些微观决策汇聚成系统设计的宏观形态------每一次函数调用,都是对"效率、安全、可维护"三角平衡的重新定义。
更多精彩内容
微信公众号:爻渡