欢迎关注微信公众号:科技洞察者 📌
近日,全球 AI 前沿技术浪潮汹涌,从 OpenAI 的旗舰级模型发布,到国内科技巨头在多模态、小尺寸模型和创新生成架构上的突破,AI 的未来正以前所未有的速度加速到来。
OpenAI GPT-5:口袋里的"博士级专家团队"
OpenAI 正式发布了其迄今为止最智能、最快速、最实用的下一代大语言模型------GPT-5。这款被首席执行官 Sam Altman 誉为"口袋里的博士级专家团队"的统一多模态智能系统,其核心亮点在于能够根据对话上下文动态切换内部模型,例如在"智能高效模型"与"深度推理模型(GPT-5 Thinking)"之间无缝切换,由"实时路由器"智能调配。

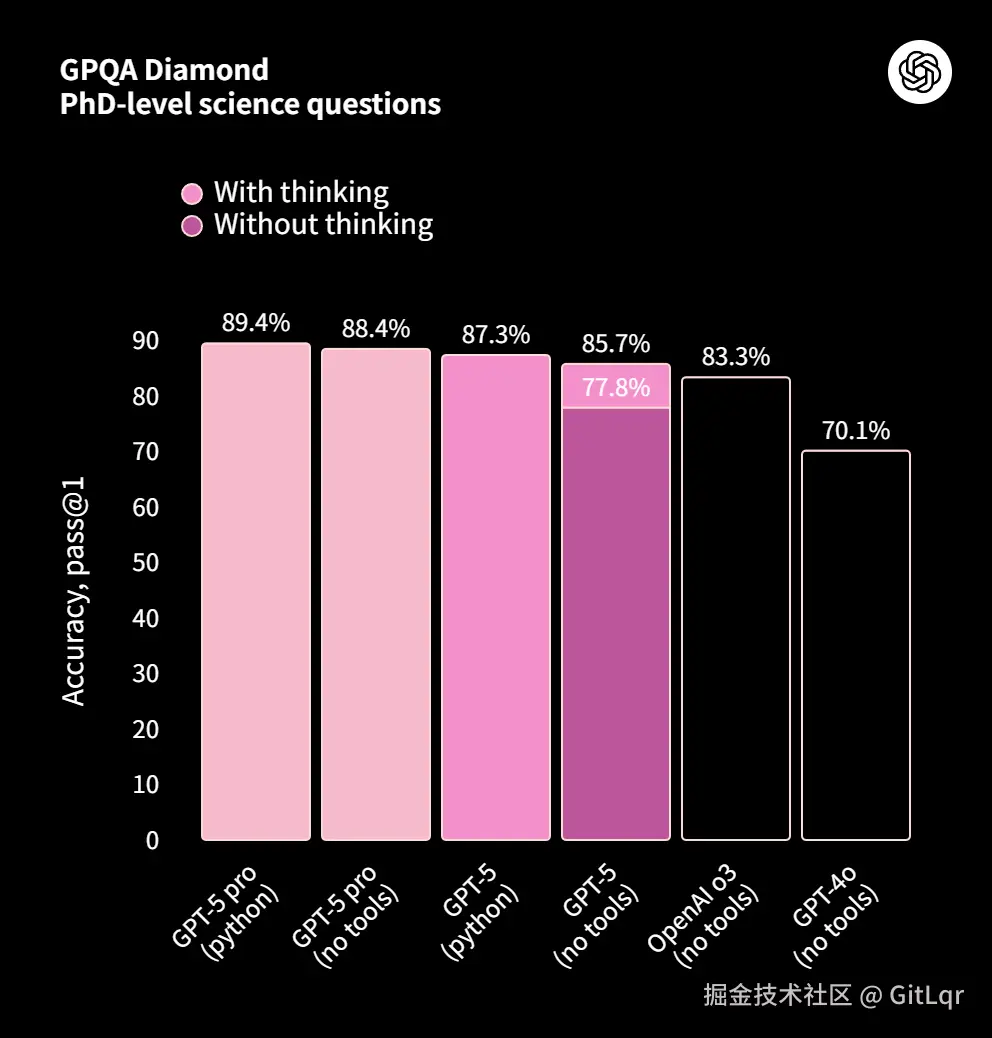
GPT-5 提供了标准版、轻量级的 mini 和 nano 版本,以及专为复杂任务设计的高级推理模型 GPT-5 Pro。其中,GPT-5 Pro 在 GPQA 基准测试中取得了惊人的 88.4%得分,再次刷新了行业标准。
在 API 层面,GPT-5 支持高达 272,000 个输入 Token 和 128,000 个输出 Token,并提供四种推理等级,为开发者提供了极大的灵活性。
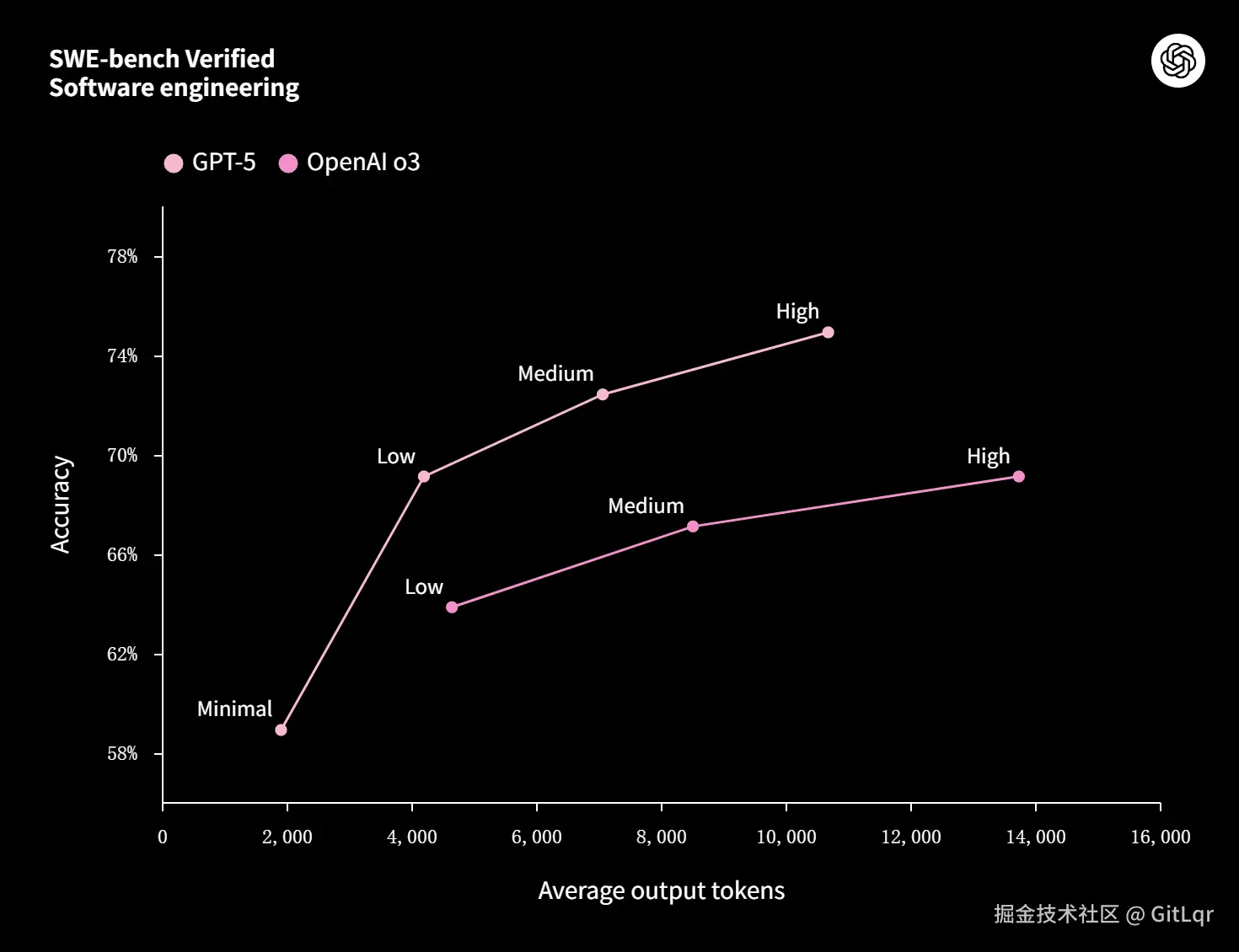
性能与能力:全方位跃升
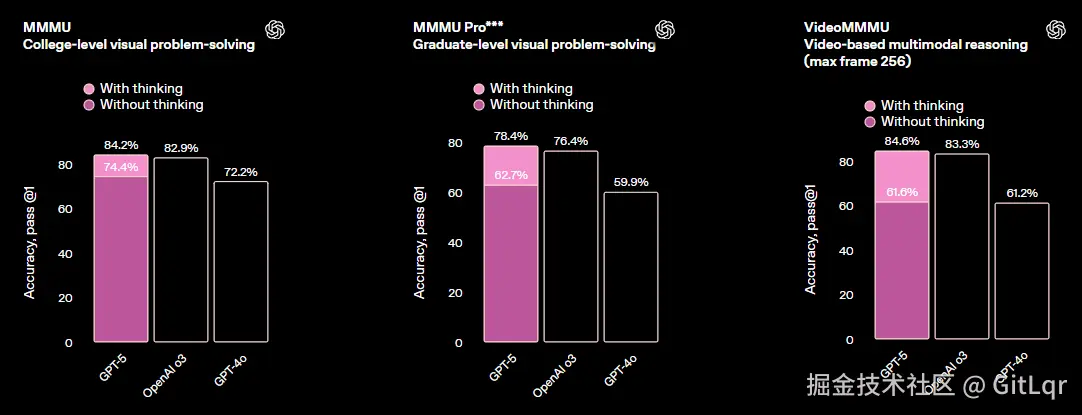
GPT-5 在多项基准测试中树立了新标杆,包括数学(AIME 94.6%)、编码(SWE-bench 74.9%)、多模态理解(MMMU 84.2%)和健康(HealthBench Hard 46.2%)。其在核心任务领域表现卓越:写作更精准、编程前端生成能力和代码调试显著增强、健康领域能作为主动思考的顾问。
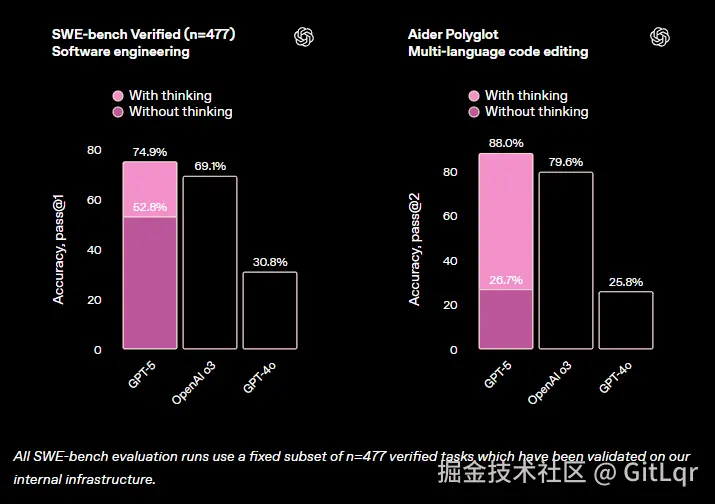
多模态能力也大幅提升,能准确分析图片、视频、图表等非文本输入。在推理与工具使用方面,GPT-5 能稳定执行多步任务拆解,指令跟随能力更强,"Thinking"模式以更少输出 Token 实现更优表现。
可靠性与安全性:行业新标杆
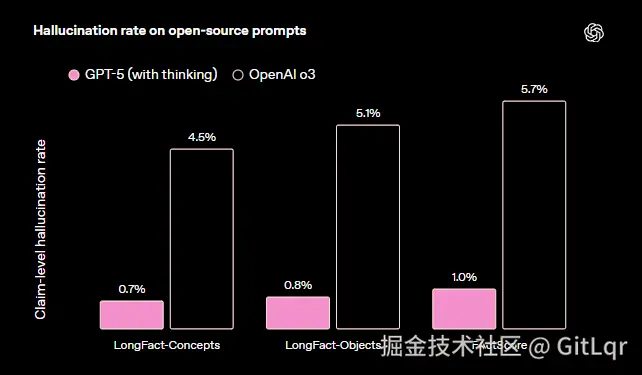
可靠性和安全性是 GPT-5 的重点改进方向。其幻觉率大幅下降(比 GPT-4o 约低 45%),"自信乱答"率也显著降低。模型引入了"Safe-Completions"安全训练机制,在安全范围内尽可能回答用户问题,并在拒绝时提供解释和替代方案。
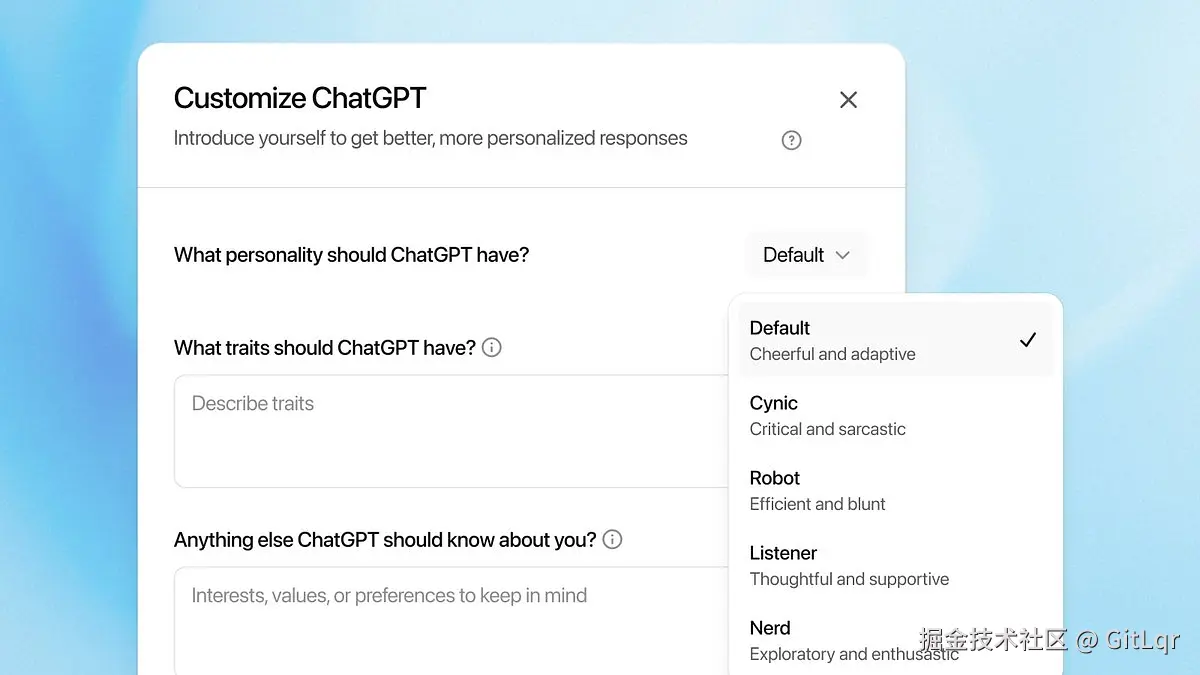
此外,模型行为也得到优化,降低了"讨好用户"的倾向,并提供四种预设人格,让交互更自然。
成本与普及:触手可及的智能
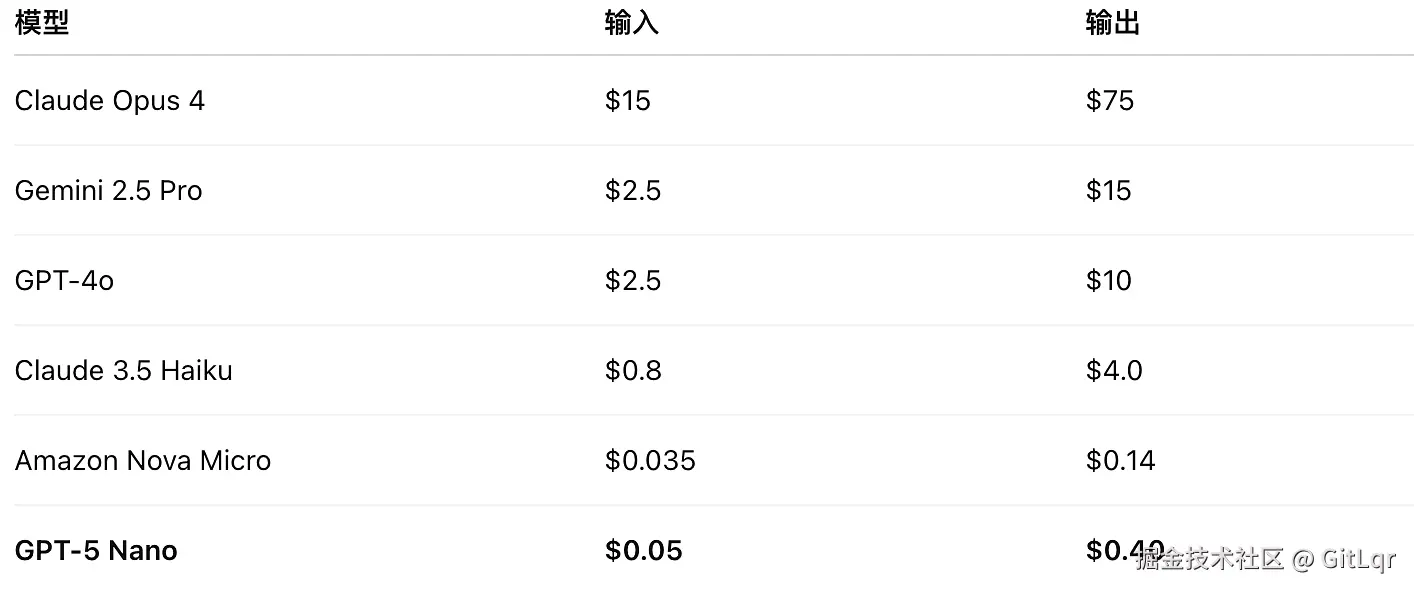
GPT-5 的定价极具竞争力,输入费用仅为 GPT-4o 的一半,并创新性地引入 Token 缓存机制,对几分钟内重复使用的输入 Token 提供 90%的折扣。

它支持并行工具调用、内置工具(如网络搜索、文件搜索、图像生成)和流式处理等多种 API 功能。目前,GPT-5 已成为 ChatGPT 的默认模型,根据用户订阅级别提供不同的使用配额和功能访问权限,"GPT-5 Thinking"模式可通过特定提示词激活。
AI 竞技场:lmarena.ai/leaderboard
官方介绍:openai.com/index/intro...
面向开发者:openai.com/index/intro...
"GPT-5 Thinking" 激活提示词:
Please think step-by-step或者Think deeply before answering
国内大模型:开源与创新并驾齐驱
中国科技力量在大模型领域持续发力,开源与创新成为两大主旋律。
小米 MiMo-VL-7B-2508:多模态的深度探索
小米大模型团队开源了其最新一代多模态大模型 Xiaomi MiMo-VL-7B-2508,包含 RL(强化学习)和 SFT(监督微调)两个版本。
该模型在学科推理、文档理解、图形界面定位和视频理解四项核心能力上表现显著提升,特别是在 MMMU 基准上首次突破 70 分。
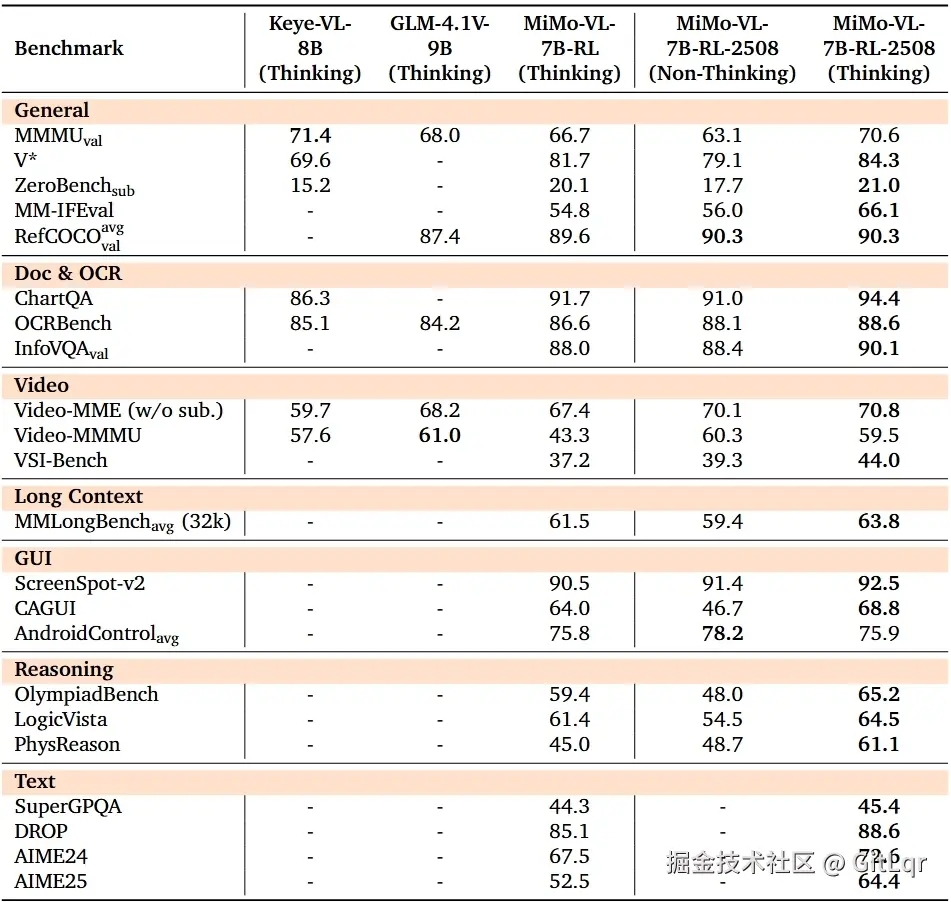
模型引入了独特的"/no_think"指令,允许用户在提问时自由切换"思考"(展示推理链条)与"非思考"(直接生成答案,响应更快)模式,为用户提供了更灵活的交互体验。
HuggingFace:
腾讯混元小尺寸模型:赋能终端与 Agent 能力
腾讯混元宣布开源发布了四款参数分别为 0.5B、1.8B、4B、7B 的小尺寸模型。
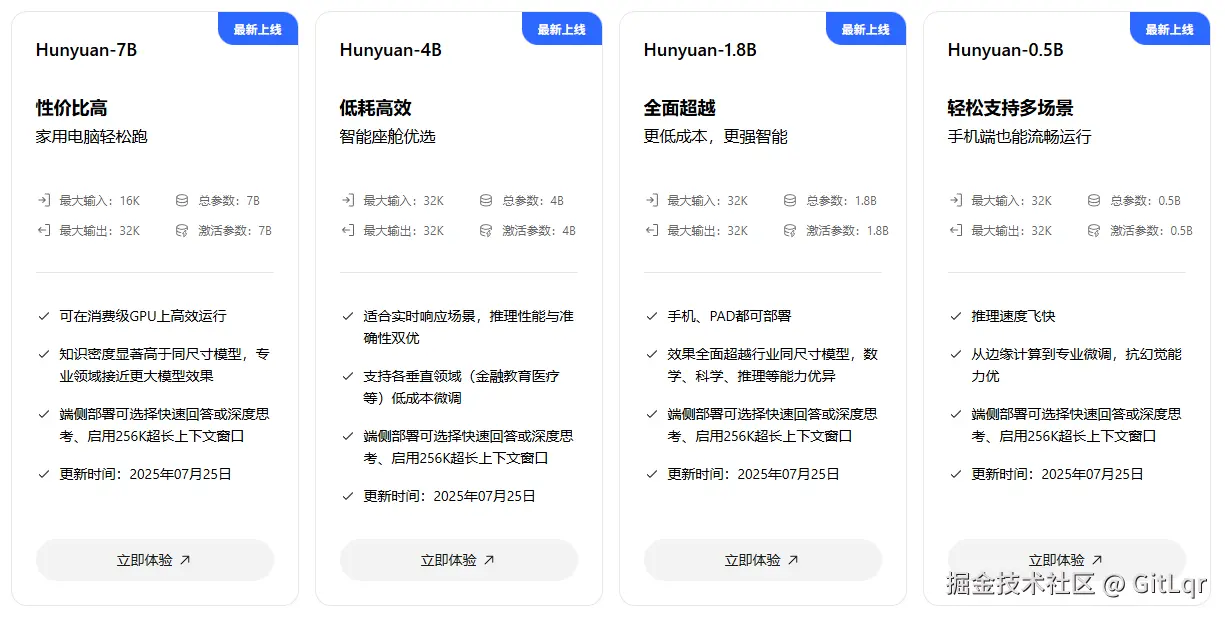
这些模型专为消费级显卡设计,可在笔记本、手机、智能座舱等低功耗场景运行,并支持垂直领域低成本微调。它们属于融合推理模型,具备推理速度快、性价比高的特点,同样提供"快思考"和"慢思考"模式。
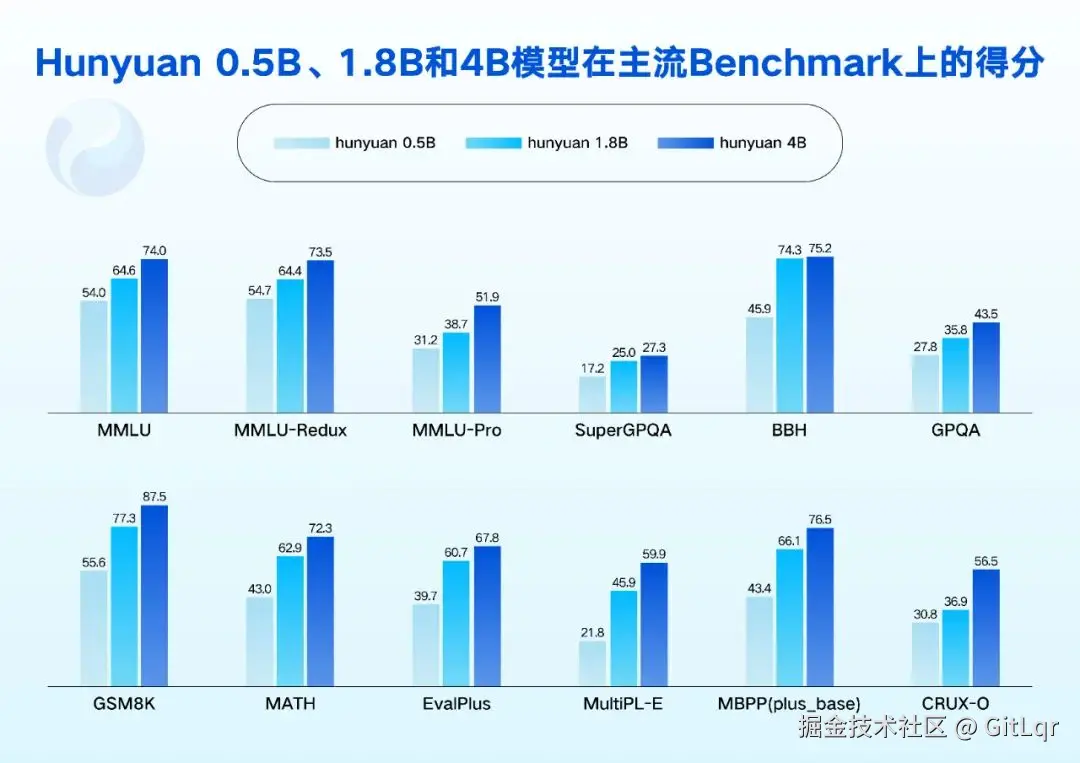
值得关注的是,这些小尺寸模型在 Agent 能力和长文本处理能力上表现出色。通过精心的数据构建和强化学习,它们提升了任务规划、工具调用、复杂决策和反思能力,能够胜任深度搜索、Excel 操作、旅行攻略规划等复杂任务。此外,模型原生支持 256k 的超长上下文窗口,能一次性处理相当于 40 万中文汉字或 50 万英文单词的内容。这些模型已在腾讯会议 AI 小助手、微信读书 AI 问书、腾讯手机管家等多个腾讯业务中得到实践应用。
Github
Hunyuan-0.5B:github.com/Tencent-Hun...
Hunyuan-1.8B:github.com/Tencent-Hun...
Hunyuan-4B:github.com/Tencent-Hun...
Hunyuan-7B:github.com/Tencent-Hun...
HuggingFace
Hunyuan-0.5B:huggingface.co/tencent/Hun...
Hunyuan-1.8B:huggingface.co/tencent/Hun...
Hunyuan-4B:huggingface.co/tencent/Hun...
Hunyuan-7B:huggingface.co/tencent/Hun...
字节跳动 Seed Diffusion:代码生成的新范式
字节跳动 SEED 团队发布了实验性离散状态扩散语言模型 Seed Diffusion Preview,专注于代码生成任务。这款模型旨在验证离散扩散方法作为下一代语言模型基础架构的可行性。
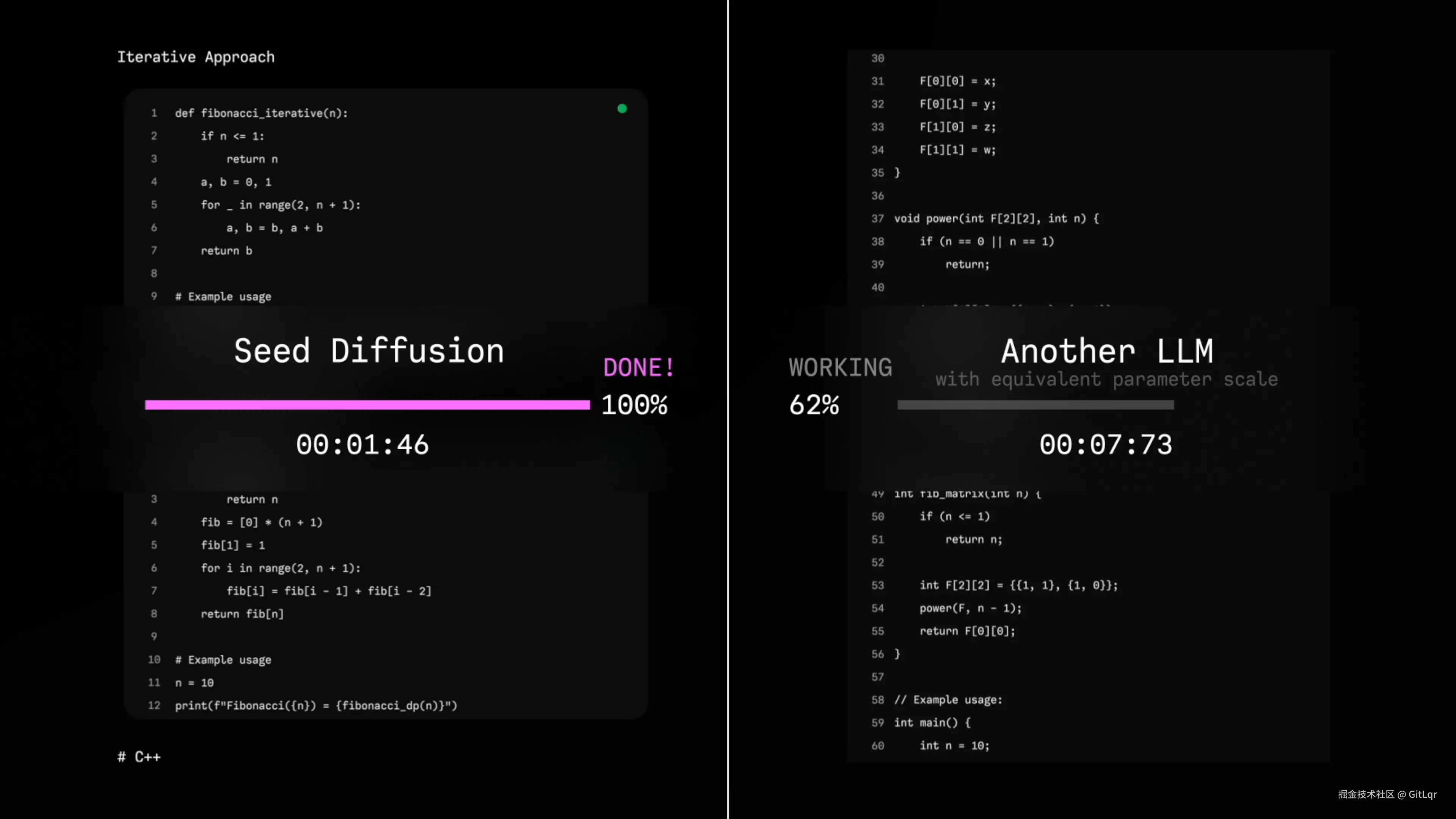
与传统的自回归模型(如 GPT)逐字生成不同,Seed Diffusion 能够并行生成,生成速度高达 2146 token/s,是同规模自回归模型的 5.4 倍。
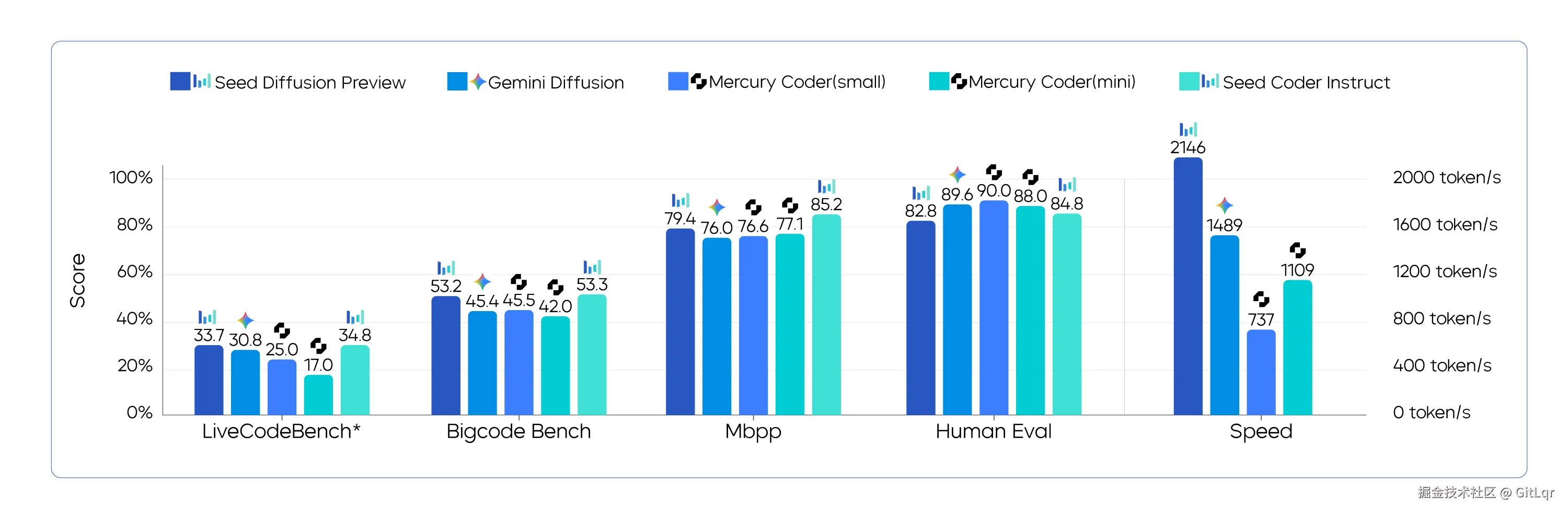
在多个代码生成基准测试中,它保持了相似甚至更优的质量,并在速度-质量帕累托边界上实现了新的 SOTA。尤其在代码编辑任务上,它能一次性并行生成整段代码并自动纠错。
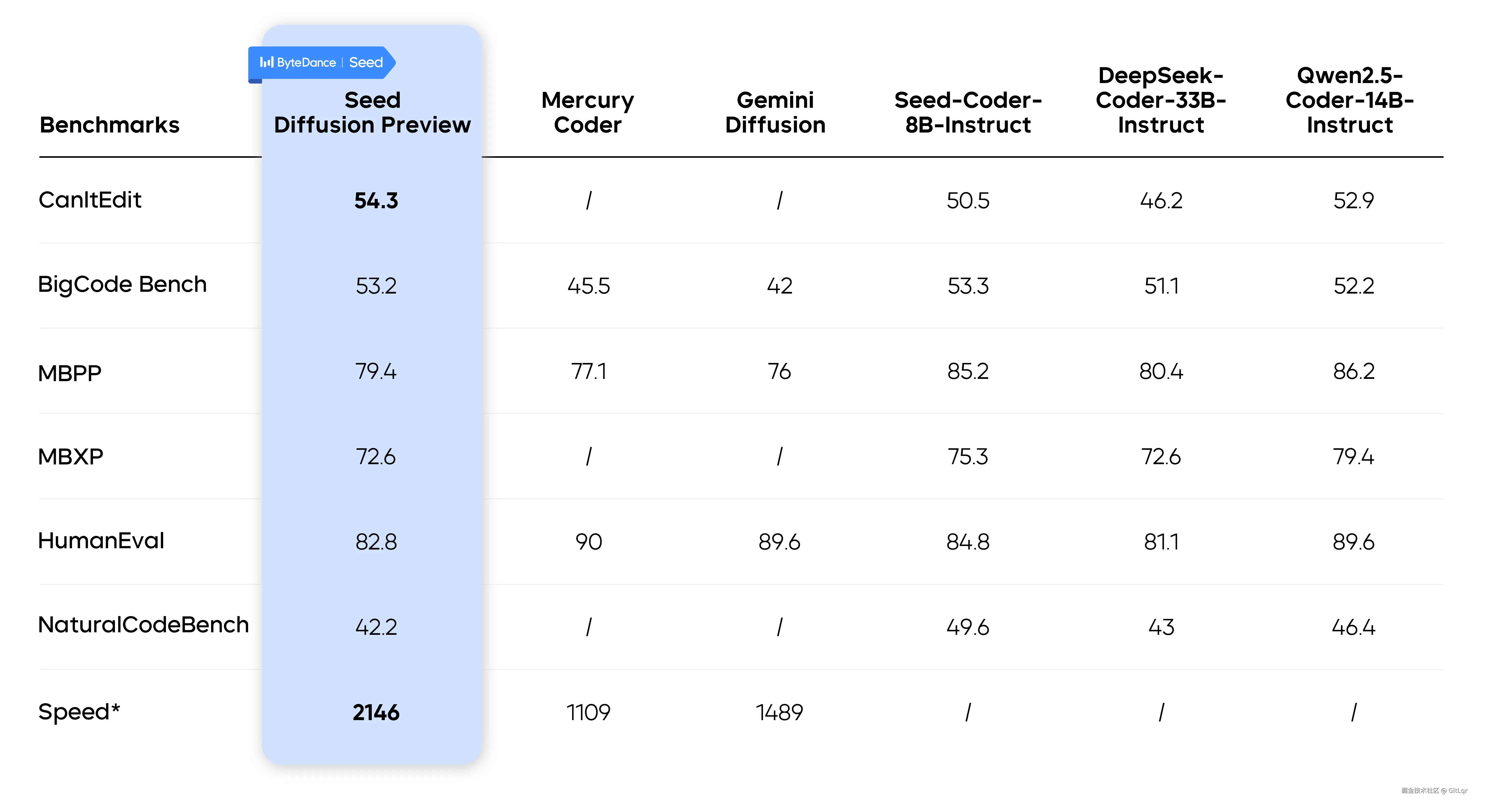
该模型的核心技术包括两阶段训练策略(掩码填空训练与编辑驱动训练)、学习"合理顺序"生成以确保代码正确性、以及引入"审查器"机制优化生成流程。工程层面上,它通过"块式"并行生成和缓存机制,实现了比传统模型更快的推理速度,预示着其在"结构性内容生成"领域的广阔应用前景。
官网:seed.bytedance.com/en/seed_dif...
体验:studio.seed.ai/exp/seed_di...
论文:arxiv.org/pdf/2508.02...
如果对你有帮助的话,请点赞、分享。关注微信公众号 科技洞察者,第一时间获取 前沿科技讯息,还有 数字人播客、演示视频 等丰富内容,我们下期再见。